Kwafoor commented on a change in pull request #34862:
URL: https://github.com/apache/spark/pull/34862#discussion_r767382412
##########
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Cast.scala
##########
@@ -652,7 +652,13 @@ abstract class CastBase extends UnaryExpression with
TimeZoneAwareExpression wit
buildCast[UTF8String](_, UTF8StringUtils.toIntExact)
case StringType =>
val result = new IntWrapper()
- buildCast[UTF8String](_, s => if (s.toInt(result)) result.value else
null)
+ buildCast[UTF8String](_, s => {
+ if (s.toInt(result)) {
+ result.value}
Review comment:
In sparkSQL

and

For in Hive

When user comparing String and IntegerType in sparkSQL with
spark.sql.ansi.enabled=false, and the default value of spark.sql.ansi.enabled
is false, user didn't get any remind but get a wrong result.
User runs a big and complex sql, it is very hard to find where the result is
wrong,So they is hard to fix the wrong sql.
Actually I think may be there is some problem without any check to cast
String to int when user comparing String and AtomicType.

And with spark.sql.ansi.enabled=true, SparkSQL disallowed compare String
and DecimalType, user from hive to SparkSQL unwilling to change their code.


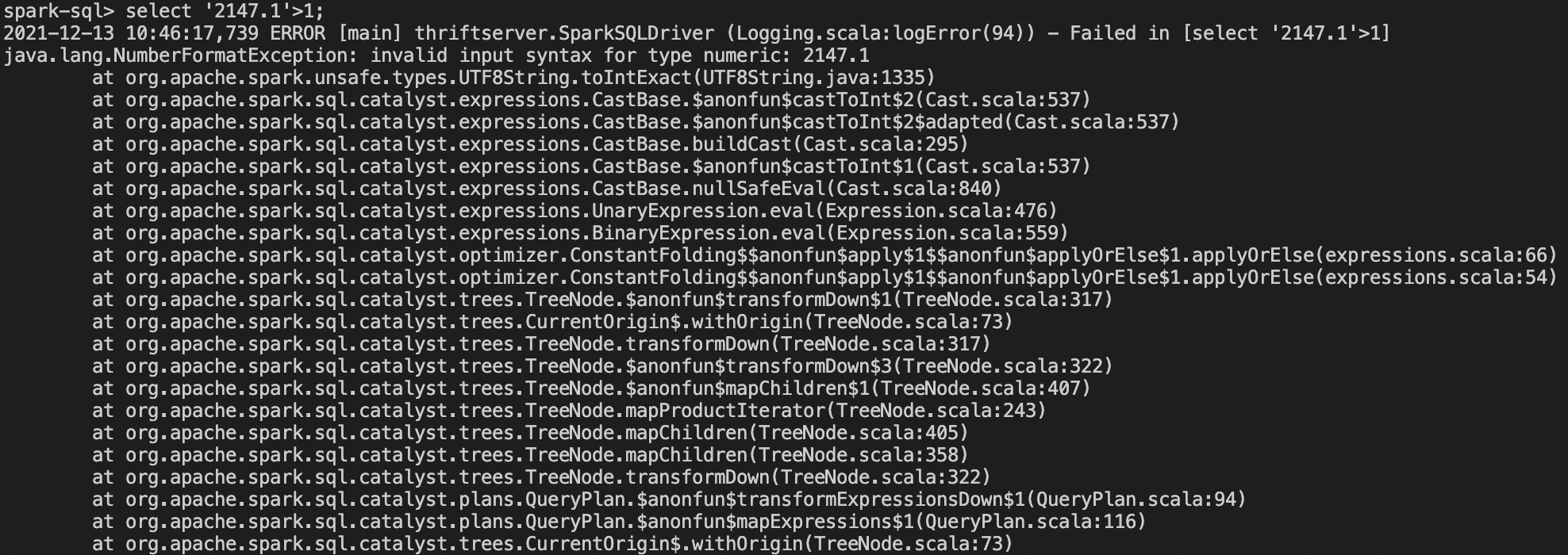

So I think It should remind User where your sql is not support in SparkSQL
even without ansi mode, Because this case is exception, and user should to be
reminded.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}