[GitHub] [incubator-tvm] 652994331 commented on issue #4464: [RFC] Add TVMDSOOp to integrate any TVM operator with TensorFlow
652994331 commented on issue #4464:
URL: https://github.com/apache/incubator-tvm/issues/4464#issuecomment-673897424
@tobegit3hub Hi guys, i built tvm before and i built tvmsoop separately(not
from USE_TF_TVMSOOP=ON) follow
this:https://github.com/tobegit3hub/tftvm/tree/master/examples .
After i got libxx.so and link them to my tvm home, i run the test
import tensorflow as tf
from tvm.contrib import tf_op
mod = tf_op.Module("tvm_addone_dll.so")
addone = mod.func("addone", output_shape=[4])
with tf.Session() as sess:
a = tf.constant([10.1, 20.0, 11.2, -30.3])
b = addone(a)
print(sess.run(b))
and i got this error:
Traceback (most recent call last):
File "test_python.py", line 5, in
addone = mod.func("add_one, output_shape=[4]")
File
"/opt/cephfs1/asr/users/qizhou.huang/.local/lib/python3.6/site-packages/tvm-0.7.dev1-py3.6-linux-x86_64.egg/tvm/contrib/tf_op/module.py",
line 27, in func
return Func(self.lib_path, name, output_dtype, output_shape)
File
"/opt/cephfs1/asr/users/qizhou.huang/.local/lib/python3.6/site-packages/tvm-0.7.dev1-py3.6-linux-x86_64.egg/tvm/contrib/tf_op/module.py",
line 55, in __init__
self.module = load_library.load_op_library('tvm_dso_op.so')
File
"/opt/cephfs1/asr/users/qizhou.huang/anaconda3/envs/tvm/lib/python3.6/site-packages/tensorflow_core/python/framework/load_library.py",
line 61, in load_op_library
lib_handle = py_tf.TF_LoadLibrary(library_filename)
tensorflow.python.framework.errors_impl.NotFoundError:
/opt/cephfs1/asr/users/qizhou.huang/qizhou/PycharmProjects/incubator-tvm/build/tvm_dso_op.so:
undefined symbol: _ZN10tensorflow12OpDefBuilder4AttrESs
my gcc is 6.4.0,my tensorflow flow is tf-1.15.0 i use bazel build it from
source and set -D_GLIBCXX_CXX11_ABI=1.
Btw, i also tried the pip install tensorflow,-1.13.1, same error. Couild you
please help me out, thanks
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [incubator-tvm] jcf94 opened a new pull request #6275: [Support] Add parallel_for support to run a loop in parallel
jcf94 opened a new pull request #6275: URL: https://github.com/apache/incubator-tvm/pull/6275 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] masahi closed issue #4962: Support dilation in x86 NCHWc depthwise conv
masahi closed issue #4962: URL: https://github.com/apache/incubator-tvm/issues/4962 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] masahi merged pull request #6267: add dilation in x86 NCHWc depthwise conv support
masahi merged pull request #6267: URL: https://github.com/apache/incubator-tvm/pull/6267 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] masahi commented on pull request #6267: add dilation in x86 NCHWc depthwise conv support
masahi commented on pull request #6267: URL: https://github.com/apache/incubator-tvm/pull/6267#issuecomment-673889169 Thanks @wjliu1998 @leandron This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[incubator-tvm] branch master updated: add dilation in x86 NCHWc depthwise conv support (#4962) (#6267)
This is an automated email from the ASF dual-hosted git repository.
masahi pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/incubator-tvm.git
The following commit(s) were added to refs/heads/master by this push:
new ad0dbe0 add dilation in x86 NCHWc depthwise conv support (#4962)
(#6267)
ad0dbe0 is described below
commit ad0dbe0332c05c80152aa1eb274aad591229231a
Author: wjliu
AuthorDate: Fri Aug 14 13:17:38 2020 +0800
add dilation in x86 NCHWc depthwise conv support (#4962) (#6267)
---
python/tvm/topi/x86/depthwise_conv2d.py| 18 --
tests/python/frontend/pytorch/test_forward.py | 7 +--
tests/python/topi/python/test_topi_depthwise_conv2d.py | 7 ---
3 files changed, 17 insertions(+), 15 deletions(-)
diff --git a/python/tvm/topi/x86/depthwise_conv2d.py
b/python/tvm/topi/x86/depthwise_conv2d.py
index 0976c33..acbe0f7 100644
--- a/python/tvm/topi/x86/depthwise_conv2d.py
+++ b/python/tvm/topi/x86/depthwise_conv2d.py
@@ -122,13 +122,18 @@ def depthwise_conv2d_NCHWc(cfg, data, kernel, strides,
padding, dilation,
strides = strides if isinstance(strides, (tuple, list)) else (strides,
strides)
HSTR, WSTR = strides
-pad_top, pad_left, pad_down, pad_right = get_pad_tuple(padding,
(filter_height, filter_width))
dh, dw = dilation if isinstance(dilation, (tuple, list)) else (dilation,
dilation)
-assert (dh, dw) == (1, 1), "Does not support dilation"
-out_height = (in_height - filter_height + pad_top + pad_down) // HSTR + 1
-out_width = (in_width - filter_width + pad_left + pad_right) // WSTR + 1
+dilated_kernel_h = (filter_height - 1) * dh + 1
+dilated_kernel_w = (filter_width - 1) * dw + 1
+pad_top, pad_left, pad_down, pad_right = get_pad_tuple(
+padding, (dilated_kernel_h, dilated_kernel_w))
+HPAD = pad_top + pad_down
+WPAD = pad_left + pad_right
+
+out_height = (in_height + HPAD - dilated_kernel_h) // HSTR + 1
+out_width = (in_width + WPAD - dilated_kernel_w) // WSTR + 1
cfg.define_split("tile_ic", in_channel, num_outputs=2)
cfg.define_split("tile_oc", out_channel, num_outputs=2)
@@ -140,7 +145,7 @@ def depthwise_conv2d_NCHWc(cfg, data, kernel, strides,
padding, dilation,
te.placeholder((batch, in_channel, in_height, in_width),
dtype=data.dtype),
te.placeholder((out_channel, channel_multiplier, filter_height,
filter_width),
dtype=kernel.dtype),
-strides, padding, out_dtype)
+strides, (pad_top, pad_down), out_dtype)
if cfg.is_fallback:
_fallback_schedule(cfg, wkl)
@@ -172,6 +177,7 @@ def depthwise_conv2d_NCHWc(cfg, data, kernel, strides,
padding, dilation,
else:
data_pad = data
+
# depthconv stage
idxdiv = tvm.tir.indexdiv
idxmod = tvm.tir.indexmod
@@ -184,7 +190,7 @@ def depthwise_conv2d_NCHWc(cfg, data, kernel, strides,
padding, dilation,
(data_pad[
b,
idxdiv(idxdiv(oco * out_channel_block + oci,
channel_multiplier), in_channel_block),
-oh*HSTR+kh, ow*WSTR+kw,
+oh*HSTR+kh*dh, ow*WSTR+kw*dw,
idxmod(idxdiv(oco * out_channel_block + oci,
channel_multiplier), in_channel_block)]
.astype(out_dtype) *
kernel[oco, 0, kh, kw, 0, oci].astype(out_dtype)),
diff --git a/tests/python/frontend/pytorch/test_forward.py
b/tests/python/frontend/pytorch/test_forward.py
index ae03a70..88203f5 100644
--- a/tests/python/frontend/pytorch/test_forward.py
+++ b/tests/python/frontend/pytorch/test_forward.py
@@ -1552,12 +1552,7 @@ def test_segmentaton_models():
inp = [torch.rand((1, 3, 300, 300), dtype=torch.float)]
verify_model(SegmentationModelWrapper(fcn.eval()), inp, atol=1e-4,
rtol=1e-4)
-
-# depthwise + dilated covolution not supported on x86
-# see https://github.com/apache/incubator-tvm/issues/4962
-cuda_ctx = ("cuda", tvm.gpu(0))
-if cuda_ctx[1].exist:
-verify_model(SegmentationModelWrapper(deeplab.eval()), inp,
[cuda_ctx], atol=1e-4, rtol=1e-4)
+verify_model(SegmentationModelWrapper(deeplab.eval()), inp, atol=1e-4,
rtol=1e-4)
def test_3d_models():
diff --git a/tests/python/topi/python/test_topi_depthwise_conv2d.py
b/tests/python/topi/python/test_topi_depthwise_conv2d.py
index 93a166d..5497e11 100644
--- a/tests/python/topi/python/test_topi_depthwise_conv2d.py
+++ b/tests/python/topi/python/test_topi_depthwise_conv2d.py
@@ -269,7 +269,6 @@ def depthwise_conv2d_with_workload_NCHWc(batch, in_channel,
in_height, channel_m
filter_width = filter_height
stride_h = stride_w = stride
-assert dilation == 1, "depthwise_conv2d_NCHWc currently does not support
dilation."
assert channel_multiplier == 1, "depthwise_conv2d_NCHWc currently does not
support channel multiplier > 1."
pad_h, pad_w, _, _ = get_pad_tuple(padding, (filter_height,
[GitHub] [incubator-tvm] hypercubestart commented on a change in pull request #5812: Bring Your Own Datatypes
hypercubestart commented on a change in pull request #5812:
URL: https://github.com/apache/incubator-tvm/pull/5812#discussion_r470398943
##
File path: tests/python/unittest/test_custom_datatypes.py
##
@@ -0,0 +1,407 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+"""Utilities for changing datatypes of models."""
+import tvm
+import topi.testing
+import numpy as np
+from numpy.random import MT19937, RandomState, SeedSequence
+from tvm import relay
+from tvm.relay.testing.inception_v3 import get_workload as get_inception
+from tvm.relay.testing.resnet import get_workload as get_resnet
+from tvm.relay.testing.mobilenet import get_workload as get_mobilenet
+from tvm.target.datatype import register, register_min_func, register_op,
create_lower_func, lower_ite
+from nose.tools import nottest
+
+tgt = "llvm"
+# we use a random seed to generate input_data
+# to guarantee stable tests
+rs = RandomState(MT19937(SeedSequence(123456789)))
+
+def convert_ndarray(dst_dtype, *arrays):
+"""Converts NDArray(s) into the specified datatype"""
+def convert(array):
+x = relay.var('x', shape=array.shape, dtype=str(array.dtype))
+cast = relay.Function([x], x.astype(dst_dtype))
+with tvm.transform.PassContext(config={"tir.disable_vectorize": True}):
+return relay.create_executor('graph').evaluate(cast)(array)
+
+return tuple([convert(x) for x in arrays])
+
+
+def change_dtype(src, dst, module, params):
+module = relay.frontend.ChangeDatatype(src, dst)(module)
+module = relay.transform.InferType()(module)
+params = dict((p, convert_ndarray(dst, params[p])) for p in params)
+return module, params
+
+def compare(module, input, src_dtype, dst_dtype, rtol, atol, params = {}):
+ex = relay.create_executor("graph", mod=module)
+
+correct = ex.evaluate()(*input, **params)
+
+module, _ = change_dtype(src_dtype, dst_dtype, module, [])
+ex = relay.create_executor("graph", mod=module)
+# converts all inputs to dst_dtype
+x_converted = convert_ndarray(dst_dtype, *input)
+
+# Vectorization is not implemented with custom datatypes
+with tvm.transform.PassContext(config={"tir.disable_vectorize": True}):
+maybe_correct = ex.evaluate()(*x_converted, **params)
+# TODO(andrew) this only works on single output
+maybe_correct_converted = convert_ndarray(src_dtype, maybe_correct)[0]
+np.testing.assert_allclose(maybe_correct_converted.asnumpy(),
+correct.asnumpy(),
+rtol=rtol,
+atol=atol)
+
+def setup():
+"""Set up tests
+
+Currently, this registers some custom datatypes using the Bring Your
+Own Datatypes framework.
+"""
+
+# To use datatype operations in an external library, you should first load
+# the library containing the datatype implementation:
+# CDLL("libposit.so", RTLD_GLOBAL)
+# In this case, the datatype library we are using is built right into TVM,
+# so we do not need to explicitly load any library.
+
+# You can pick a code for your datatype arbitrarily, as long as it is
+# greater than 128 and has not already been chosen.
+
+register("posites2", 131)
+
+register_op(create_lower_func(
+{
+(32, 32): "FloatToPosit32es2",
+(32, 16): "FloatToPosit16es2",
+(32, 8): 'FloatToPosit8es2',
+}),
+"Cast", "llvm", "float", "posites2")
+register_op(create_lower_func(
+{
+(32, 32): "Posit32es2ToFloat",
+(16, 32): 'Posit16es2ToFloat',
+(8, 32): 'Posit8es2ToFloat',
+}),
+"Cast", "llvm", "posites2", "float")
+register_op(create_lower_func(
+{
+(4, 32): 'IntToPosit32es2',
+(4, 16): 'IntToPosit16es2',
+(4, 8): 'IntToPosit8es2'
+}),
+"Cast", "llvm", "int", "posites2")
+register_op(create_lower_func({
+32: 'Posit32es2Add',
+16: 'Posit16es2Add',
+8: 'Posit8es2Add'
+}), "Add", "llvm", "posites2")
+register_op(create_lower_func({
+32: 'Posit32es2Sub',
+16: 'Posit16es2Sub',
+8:
[GitHub] [incubator-tvm] FrozenGene commented on pull request #5913: [random] support random fill
FrozenGene commented on pull request #5913: URL: https://github.com/apache/incubator-tvm/pull/5913#issuecomment-673871333 @tqchen @merrymercy gental ping. Code has been updated. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] shalushajan95 commented on issue #6265: KeyError: ‘InceptionResnetV1/Logits/Flatten/flatten/Reshape/shape/1’
shalushajan95 commented on issue #6265: URL: https://github.com/apache/incubator-tvm/issues/6265#issuecomment-673869168 Hi @bwang1991 is there any way to solve this issue. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] domin1985 closed pull request #6271: [Frontend][Relay] Keras frontend prelu bug fix
domin1985 closed pull request #6271: URL: https://github.com/apache/incubator-tvm/pull/6271 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] wjliu1998 commented on pull request #6267: add dilation in x86 NCHWc depthwise conv support
wjliu1998 commented on pull request #6267: URL: https://github.com/apache/incubator-tvm/pull/6267#issuecomment-673830644 > @wjliu1998 Thanks, please update the PyTorch frontend test below that has been disabled due to the lack of dilation support in x86: > > https://github.com/apache/incubator-tvm/blob/master/tests/python/frontend/pytorch/test_forward.py#L1556-L1560 > > (Remove `[cuda_ctx]`, do the test in the same way as `fcn` above) Thanks for the comment! The x86 frontend has been enabled! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] bwang1991 commented on issue #6265: KeyError: ‘InceptionResnetV1/Logits/Flatten/flatten/Reshape/shape/1’
bwang1991 commented on issue #6265: URL: https://github.com/apache/incubator-tvm/issues/6265#issuecomment-673778817 I got a similar error. It looks like hat keys that contain "shape" can cause KeyErrors. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] jroesch opened a new pull request #6274: [Diagnostics][Relay][InferType] Refactor InferType to work on whole module, and use new diagnostics.
jroesch opened a new pull request #6274: URL: https://github.com/apache/incubator-tvm/pull/6274 This is currently a draft PR on the 3rd stage of my parser/diagnostics refactoring. I will update this with more details as I go. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] masahi commented on issue #6268: TVMError: Check failed: it != type_definitions.end(): There is no definition of static_tensor_float32_*
masahi commented on issue #6268: URL: https://github.com/apache/incubator-tvm/issues/6268#issuecomment-673729436 I can see why this error is happening. We need to pass the Prelude module to `infer_shape`, `mod` argument here https://github.com/apache/incubator-tvm/blob/master/python/tvm/relay/frontend/common.py#L484 See below for how we pass the Prelude mod to `infer_type`. Basically we need a similar function, like `infer_shape_with_prelude`. https://github.com/apache/incubator-tvm/blob/master/python/tvm/relay/frontend/pytorch.py#L48 A PR welcome. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] masahi commented on pull request #6267: add dilation in x86 NCHWc depthwise conv support
masahi commented on pull request #6267: URL: https://github.com/apache/incubator-tvm/pull/6267#issuecomment-673727099 @wjliu1998 Thanks, please update the PyTorch frontend test below that has been disabled due to the lack of dilation support in x86: https://github.com/apache/incubator-tvm/blob/master/tests/python/frontend/pytorch/test_forward.py#L1556-L1560 (Remove `[cuda_ctx]`, do the test in the same way as `fcn` above) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] electriclilies opened a new pull request #6273: [RELAY][DYN] Dynamic upsampling relay op
electriclilies opened a new pull request #6273: URL: https://github.com/apache/incubator-tvm/pull/6273 Implements the dynamic version of the upsampling op This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] mbrookhart opened a new pull request #6272: Update precision in the ONNX strided_slice, update precision of ToScalar
mbrookhart opened a new pull request #6272: URL: https://github.com/apache/incubator-tvm/pull/6272 Fixes #6263 ToScalar was casting a 64 bit Int to a 64 bit float, which reduced precision too much. I switched things to use int64_t/long double where needed to keep precision. Thanks! cc: @kevinthesun @zhiics @yongwww @lixiaoquan This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] mbrookhart removed a comment on issue #6263: #4312 broke Huggingface BERT ONNX import
mbrookhart removed a comment on issue #6263: URL: https://github.com/apache/incubator-tvm/issues/6263#issuecomment-673671138 The onnx importer was casting the value to int32_t, leading to the -1 through overflow. If I change the importer to use int64_t, it rounds to zero when we convert the constant int64 input into an Array. There's an intermediate double value that can't properly represent int64_t max. @lixiaoquan I think I just need to split this op into static and dynamic cases. This is very much related to some of the work you're doing in #6024. Would you prefer I wait until that is merged? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] comaniac commented on a change in pull request #6218: [Target] Creating Target from JSON-like Configuration
comaniac commented on a change in pull request #6218:
URL: https://github.com/apache/incubator-tvm/pull/6218#discussion_r470212475
##
File path: src/target/target.cc
##
@@ -162,14 +314,164 @@ Target Target::Create(const String& target_str) {
return CreateTarget(splits[0], {splits.begin() + 1, splits.end()});
}
+ObjectRef TargetNode::ParseAttr(const ObjectRef& obj,
+const TargetKindNode::ValueTypeInfo& info)
const {
+ if (info.type_index ==
Integer::ContainerType::_GetOrAllocRuntimeTypeIndex()) {
+const auto* v = obj.as();
+CHECK(v != nullptr) << "Expect type 'int', but get: " << obj->GetTypeKey();
+return GetRef(v);
+ }
+ if (info.type_index == String::ContainerType::_GetOrAllocRuntimeTypeIndex())
{
+const auto* v = obj.as();
+CHECK(v != nullptr) << "Expect type 'str', but get: " << obj->GetTypeKey();
+return GetRef(v);
+ }
+ if (info.type_index == Target::ContainerType::_GetOrAllocRuntimeTypeIndex())
{
+CHECK(obj->IsInstance())
+<< "Expect type 'dict' to construct Target, but get: " <<
obj->GetTypeKey();
+return Target::FromConfig(Downcast>(obj));
+ }
+ if (info.type_index == ArrayNode::_GetOrAllocRuntimeTypeIndex()) {
+CHECK(obj->IsInstance()) << "Expect type 'list', but get: " <<
obj->GetTypeKey();
+Array array = Downcast>(obj);
+std::vector result;
+int i = 0;
+for (const ObjectRef& e : array) {
+ ++i;
+ try {
+result.push_back(TargetNode::ParseAttr(e, *info.key));
+ } catch (const dmlc::Error& e) {
+LOG(FATAL) << "Error occurred when parsing element " << i << " of the
array: " << array
+ << ". Details:\n"
+ << e.what();
+ }
+}
+return Array(result);
+ }
+ if (info.type_index == MapNode::_GetOrAllocRuntimeTypeIndex()) {
+CHECK(obj->IsInstance()) << "Expect type 'dict', but get: " <<
obj->GetTypeKey();
+std::unordered_map result;
+for (const auto& kv : Downcast>(obj)) {
+ ObjectRef key, val;
+ try {
+key = TargetNode::ParseAttr(kv.first, *info.key);
+ } catch (const tvm::Error& e) {
+LOG(FATAL) << "Error occurred when parsing a key of the dict: " <<
kv.first
+ << ". Details:\n"
+ << e.what();
+ }
+ try {
+val = TargetNode::ParseAttr(kv.second, *info.val);
+ } catch (const tvm::Error& e) {
+LOG(FATAL) << "Error occurred when parsing a value of the dict: " <<
kv.second
+ << ". Details:\n"
+ << e.what();
+ }
+ result[key] = val;
+}
+return Map(result);
+ }
+ LOG(FATAL) << "Unsupported type registered: \"" << info.type_key
+ << "\", and the type given is: " << obj->GetTypeKey();
+ throw;
+}
+
+Target Target::FromConfig(const Map& config_dict) {
+ const String kKind = "kind";
+ const String kTag = "tag";
+ const String kKeys = "keys";
+ std::unordered_map config(config_dict.begin(),
config_dict.end());
+ ObjectPtr target = make_object();
+ // parse 'kind'
+ if (config.count(kKind)) {
+const auto* kind = config[kKind].as();
+CHECK(kind != nullptr) << "AttributeError: Expect type of field 'kind' is
string, but get: "
+ << config[kKind]->GetTypeKey();
+target->kind = TargetKind::Get(GetRef(kind));
+config.erase(kKind);
+ } else {
+LOG(FATAL) << "AttributeError: Field 'kind' is not found";
+ }
+ // parse "tag"
+ if (config.count(kTag)) {
+const auto* tag = config[kTag].as();
+CHECK(tag != nullptr) << "AttributeError: Expect type of field 'tag' is
string, but get: "
+ << config[kTag]->GetTypeKey();
+target->tag = GetRef(tag);
+config.erase(kTag);
+ } else {
+target->tag = "";
+ }
+ // parse "keys"
+ if (config.count(kKeys)) {
+std::vector keys;
+// user provided keys
+const auto* cfg_keys = config[kKeys].as();
+CHECK(cfg_keys != nullptr)
+<< "AttributeError: Expect type of field 'keys' is an Array, but get: "
+<< config[kTag]->GetTypeKey();
+for (const ObjectRef& e : *cfg_keys) {
+ const auto* key = e.as();
+ CHECK(key != nullptr) << "AttributeError: Expect 'keys' to be an array
of strings, but it "
+ "contains an element of type: "
+<< e->GetTypeKey();
+ keys.push_back(GetRef(key));
+}
+// add device name
+if (config_dict.count("device") &&
config_dict.at("device")->IsInstance()) {
+ keys.push_back(Downcast(config_dict.at("device")));
+}
+// add default keys
+for (const auto& key : target->kind->default_keys) {
+ keys.push_back(key);
+}
+// de-duplicate keys
+target->keys = DeduplicateKeys(keys);
Review comment:
Then are the first two examples valid? While I'm not 100% for sure about
the first one, I think the second one is definitely invalid, as its
[GitHub] [incubator-tvm] junrushao1994 commented on a change in pull request #6218: [Target] Creating Target from JSON-like Configuration
junrushao1994 commented on a change in pull request #6218:
URL: https://github.com/apache/incubator-tvm/pull/6218#discussion_r470201050
##
File path: src/target/target.cc
##
@@ -162,14 +314,164 @@ Target Target::Create(const String& target_str) {
return CreateTarget(splits[0], {splits.begin() + 1, splits.end()});
}
+ObjectRef TargetNode::ParseAttr(const ObjectRef& obj,
+const TargetKindNode::ValueTypeInfo& info)
const {
+ if (info.type_index ==
Integer::ContainerType::_GetOrAllocRuntimeTypeIndex()) {
+const auto* v = obj.as();
+CHECK(v != nullptr) << "Expect type 'int', but get: " << obj->GetTypeKey();
+return GetRef(v);
+ }
+ if (info.type_index == String::ContainerType::_GetOrAllocRuntimeTypeIndex())
{
+const auto* v = obj.as();
+CHECK(v != nullptr) << "Expect type 'str', but get: " << obj->GetTypeKey();
+return GetRef(v);
+ }
+ if (info.type_index == Target::ContainerType::_GetOrAllocRuntimeTypeIndex())
{
+CHECK(obj->IsInstance())
+<< "Expect type 'dict' to construct Target, but get: " <<
obj->GetTypeKey();
+return Target::FromConfig(Downcast>(obj));
+ }
+ if (info.type_index == ArrayNode::_GetOrAllocRuntimeTypeIndex()) {
+CHECK(obj->IsInstance()) << "Expect type 'list', but get: " <<
obj->GetTypeKey();
+Array array = Downcast>(obj);
+std::vector result;
+int i = 0;
+for (const ObjectRef& e : array) {
+ ++i;
+ try {
+result.push_back(TargetNode::ParseAttr(e, *info.key));
+ } catch (const dmlc::Error& e) {
+LOG(FATAL) << "Error occurred when parsing element " << i << " of the
array: " << array
+ << ". Details:\n"
+ << e.what();
+ }
+}
+return Array(result);
+ }
+ if (info.type_index == MapNode::_GetOrAllocRuntimeTypeIndex()) {
+CHECK(obj->IsInstance()) << "Expect type 'dict', but get: " <<
obj->GetTypeKey();
+std::unordered_map result;
+for (const auto& kv : Downcast>(obj)) {
+ ObjectRef key, val;
+ try {
+key = TargetNode::ParseAttr(kv.first, *info.key);
+ } catch (const tvm::Error& e) {
+LOG(FATAL) << "Error occurred when parsing a key of the dict: " <<
kv.first
+ << ". Details:\n"
+ << e.what();
+ }
+ try {
+val = TargetNode::ParseAttr(kv.second, *info.val);
+ } catch (const tvm::Error& e) {
+LOG(FATAL) << "Error occurred when parsing a value of the dict: " <<
kv.second
+ << ". Details:\n"
+ << e.what();
+ }
+ result[key] = val;
+}
+return Map(result);
+ }
+ LOG(FATAL) << "Unsupported type registered: \"" << info.type_key
+ << "\", and the type given is: " << obj->GetTypeKey();
+ throw;
+}
+
+Target Target::FromConfig(const Map& config_dict) {
+ const String kKind = "kind";
+ const String kTag = "tag";
+ const String kKeys = "keys";
+ std::unordered_map config(config_dict.begin(),
config_dict.end());
+ ObjectPtr target = make_object();
+ // parse 'kind'
+ if (config.count(kKind)) {
+const auto* kind = config[kKind].as();
+CHECK(kind != nullptr) << "AttributeError: Expect type of field 'kind' is
string, but get: "
+ << config[kKind]->GetTypeKey();
+target->kind = TargetKind::Get(GetRef(kind));
+config.erase(kKind);
+ } else {
+LOG(FATAL) << "AttributeError: Field 'kind' is not found";
+ }
+ // parse "tag"
+ if (config.count(kTag)) {
+const auto* tag = config[kTag].as();
+CHECK(tag != nullptr) << "AttributeError: Expect type of field 'tag' is
string, but get: "
+ << config[kTag]->GetTypeKey();
+target->tag = GetRef(tag);
+config.erase(kTag);
+ } else {
+target->tag = "";
+ }
+ // parse "keys"
+ if (config.count(kKeys)) {
+std::vector keys;
+// user provided keys
+const auto* cfg_keys = config[kKeys].as();
+CHECK(cfg_keys != nullptr)
+<< "AttributeError: Expect type of field 'keys' is an Array, but get: "
+<< config[kTag]->GetTypeKey();
+for (const ObjectRef& e : *cfg_keys) {
+ const auto* key = e.as();
+ CHECK(key != nullptr) << "AttributeError: Expect 'keys' to be an array
of strings, but it "
+ "contains an element of type: "
+<< e->GetTypeKey();
+ keys.push_back(GetRef(key));
+}
+// add device name
+if (config_dict.count("device") &&
config_dict.at("device")->IsInstance()) {
+ keys.push_back(Downcast(config_dict.at("device")));
+}
+// add default keys
+for (const auto& key : target->kind->default_keys) {
+ keys.push_back(key);
+}
+// de-duplicate keys
+target->keys = DeduplicateKeys(keys);
Review comment:
The original design of "-keys" semantic is that:
1) user provided keys comes first
2) add `device_name` if given
3) add
[GitHub] [incubator-tvm] junrushao1994 commented on a change in pull request #6218: [Target] Creating Target from JSON-like Configuration
junrushao1994 commented on a change in pull request #6218:
URL: https://github.com/apache/incubator-tvm/pull/6218#discussion_r470201050
##
File path: src/target/target.cc
##
@@ -162,14 +314,164 @@ Target Target::Create(const String& target_str) {
return CreateTarget(splits[0], {splits.begin() + 1, splits.end()});
}
+ObjectRef TargetNode::ParseAttr(const ObjectRef& obj,
+const TargetKindNode::ValueTypeInfo& info)
const {
+ if (info.type_index ==
Integer::ContainerType::_GetOrAllocRuntimeTypeIndex()) {
+const auto* v = obj.as();
+CHECK(v != nullptr) << "Expect type 'int', but get: " << obj->GetTypeKey();
+return GetRef(v);
+ }
+ if (info.type_index == String::ContainerType::_GetOrAllocRuntimeTypeIndex())
{
+const auto* v = obj.as();
+CHECK(v != nullptr) << "Expect type 'str', but get: " << obj->GetTypeKey();
+return GetRef(v);
+ }
+ if (info.type_index == Target::ContainerType::_GetOrAllocRuntimeTypeIndex())
{
+CHECK(obj->IsInstance())
+<< "Expect type 'dict' to construct Target, but get: " <<
obj->GetTypeKey();
+return Target::FromConfig(Downcast>(obj));
+ }
+ if (info.type_index == ArrayNode::_GetOrAllocRuntimeTypeIndex()) {
+CHECK(obj->IsInstance()) << "Expect type 'list', but get: " <<
obj->GetTypeKey();
+Array array = Downcast>(obj);
+std::vector result;
+int i = 0;
+for (const ObjectRef& e : array) {
+ ++i;
+ try {
+result.push_back(TargetNode::ParseAttr(e, *info.key));
+ } catch (const dmlc::Error& e) {
+LOG(FATAL) << "Error occurred when parsing element " << i << " of the
array: " << array
+ << ". Details:\n"
+ << e.what();
+ }
+}
+return Array(result);
+ }
+ if (info.type_index == MapNode::_GetOrAllocRuntimeTypeIndex()) {
+CHECK(obj->IsInstance()) << "Expect type 'dict', but get: " <<
obj->GetTypeKey();
+std::unordered_map result;
+for (const auto& kv : Downcast>(obj)) {
+ ObjectRef key, val;
+ try {
+key = TargetNode::ParseAttr(kv.first, *info.key);
+ } catch (const tvm::Error& e) {
+LOG(FATAL) << "Error occurred when parsing a key of the dict: " <<
kv.first
+ << ". Details:\n"
+ << e.what();
+ }
+ try {
+val = TargetNode::ParseAttr(kv.second, *info.val);
+ } catch (const tvm::Error& e) {
+LOG(FATAL) << "Error occurred when parsing a value of the dict: " <<
kv.second
+ << ". Details:\n"
+ << e.what();
+ }
+ result[key] = val;
+}
+return Map(result);
+ }
+ LOG(FATAL) << "Unsupported type registered: \"" << info.type_key
+ << "\", and the type given is: " << obj->GetTypeKey();
+ throw;
+}
+
+Target Target::FromConfig(const Map& config_dict) {
+ const String kKind = "kind";
+ const String kTag = "tag";
+ const String kKeys = "keys";
+ std::unordered_map config(config_dict.begin(),
config_dict.end());
+ ObjectPtr target = make_object();
+ // parse 'kind'
+ if (config.count(kKind)) {
+const auto* kind = config[kKind].as();
+CHECK(kind != nullptr) << "AttributeError: Expect type of field 'kind' is
string, but get: "
+ << config[kKind]->GetTypeKey();
+target->kind = TargetKind::Get(GetRef(kind));
+config.erase(kKind);
+ } else {
+LOG(FATAL) << "AttributeError: Field 'kind' is not found";
+ }
+ // parse "tag"
+ if (config.count(kTag)) {
+const auto* tag = config[kTag].as();
+CHECK(tag != nullptr) << "AttributeError: Expect type of field 'tag' is
string, but get: "
+ << config[kTag]->GetTypeKey();
+target->tag = GetRef(tag);
+config.erase(kTag);
+ } else {
+target->tag = "";
+ }
+ // parse "keys"
+ if (config.count(kKeys)) {
+std::vector keys;
+// user provided keys
+const auto* cfg_keys = config[kKeys].as();
+CHECK(cfg_keys != nullptr)
+<< "AttributeError: Expect type of field 'keys' is an Array, but get: "
+<< config[kTag]->GetTypeKey();
+for (const ObjectRef& e : *cfg_keys) {
+ const auto* key = e.as();
+ CHECK(key != nullptr) << "AttributeError: Expect 'keys' to be an array
of strings, but it "
+ "contains an element of type: "
+<< e->GetTypeKey();
+ keys.push_back(GetRef(key));
+}
+// add device name
+if (config_dict.count("device") &&
config_dict.at("device")->IsInstance()) {
+ keys.push_back(Downcast(config_dict.at("device")));
+}
+// add default keys
+for (const auto& key : target->kind->default_keys) {
+ keys.push_back(key);
+}
+// de-duplicate keys
+target->keys = DeduplicateKeys(keys);
Review comment:
The original design of "-keys" semantic is that:
1) user provided keys comes first
2) add `device_name` if given
3) add
[GitHub] [incubator-tvm] mbrookhart commented on issue #6263: #4312 broke Huggingface BERT ONNX import
mbrookhart commented on issue #6263: URL: https://github.com/apache/incubator-tvm/issues/6263#issuecomment-673671138 The onnx importer was casting the value to int32_t, leading to the -1 through overflow. If I change the importer to use int64_t, it rounds to zero when we convert the constant int64 input into an Array. There's an intermediate double value that can't properly represent int64_t max. @lixiaoquan I think I just need to split this op into static and dynamic cases. This is very much related to some of the work you're doing in #6024. Would you prefer I wait until that is merged? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] yzhliu commented on a change in pull request #6078: [Autodiff] Optimize and eliminate the Jacobian tensor for te.autodiff
yzhliu commented on a change in pull request #6078:
URL: https://github.com/apache/incubator-tvm/pull/6078#discussion_r470193800
##
File path: include/tvm/node/container.h
##
@@ -1439,6 +1427,22 @@ class Map : public ObjectRef {
MapNode* GetMapNode() const { return static_cast(data_.get()); }
};
+/*!
+ * \brief Merge two Maps.
+ * \param lhs the first Map to merge.
+ * \param rhs the second Map to merge.
+ * @return The merged Array. Original Maps are kept unchanged.
+ */
+template ::value>::type,
+ typename = typename std::enable_if::value>::type>
+static Map Merge(Map lhs, const Map& rhs) {
Review comment:
@tqchen my bad I forgot to when copy-pasting. modified.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [incubator-tvm] comaniac commented on a change in pull request #6270: [Ansor][AutoTVM v2.0] Phase 1: XGBoost Cost Model
comaniac commented on a change in pull request #6270:
URL: https://github.com/apache/incubator-tvm/pull/6270#discussion_r470071293
##
File path: python/tvm/auto_scheduler/auto_schedule.py
##
@@ -161,7 +161,7 @@ def __init__(self, task, schedule_cost_model=RandomModel(),
params=None, seed=No
seed or random.randint(1, 1 << 30), verbose, init_search_callbacks)
def generate_sketches(self, print_for_debug=False):
-""" Generate the sketches, this is mainly used for debug.
+""" Generate the sketches. This is mainly used for debugging and
testing.
Review comment:
I know the meaning of this description, but it may confuse people. Maybe
we can either don't say this is mainly for debugging and testing, or explicitly
say this is mainly for debugging and testing because auto scheduler uses them
in the C++ side?
##
File path: python/tvm/auto_scheduler/cost_model/xgb_model.py
##
@@ -0,0 +1,590 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+# pylint: disable=invalid-name
+
+"""Cost model based on xgboost"""
+import multiprocessing
+import logging
+from collections import defaultdict
+
+import numpy as np
+import xgboost as xgb
+from xgboost.core import EarlyStopException
+from xgboost.callback import _fmt_metric
+from xgboost.training import aggcv
+
+from tvm.autotvm.tuner.metric import max_curve
+from .cost_model import PythonBasedModel
+from ..feature import get_per_store_features_from_measure_pairs,
get_per_store_features_from_states
+from ..measure_record import RecordReader
+
+logger = logging.getLogger('auto_scheduler')
+
+class XGBDMatrixContext:
+"""A global context to hold additional attributes of xgb.DMatrix"""
+def __init__(self):
+self.context_dict = defaultdict(dict)
+
+def get(self, key, matrix, default=None):
+"""
+Get an attribute of a xgb.DMatrix
+
+Parameters
+--
+key: str
+The name of the attribute
+matrix: xgb.DMatrix
+The matrix
+default: Optional
Review comment:
```suggestion
default: Optional[Any]
```
##
File path: python/tvm/auto_scheduler/cost_model/xgb_model.py
##
@@ -0,0 +1,590 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+# pylint: disable=invalid-name
+
+"""Cost model based on xgboost"""
+import multiprocessing
+import logging
+from collections import defaultdict
+
+import numpy as np
+import xgboost as xgb
+from xgboost.core import EarlyStopException
+from xgboost.callback import _fmt_metric
+from xgboost.training import aggcv
+
+from tvm.autotvm.tuner.metric import max_curve
+from .cost_model import PythonBasedModel
+from ..feature import get_per_store_features_from_measure_pairs,
get_per_store_features_from_states
+from ..measure_record import RecordReader
+
+logger = logging.getLogger('auto_scheduler')
+
+class XGBDMatrixContext:
+"""A global context to hold additional attributes of xgb.DMatrix"""
+def __init__(self):
+self.context_dict = defaultdict(dict)
+
+def get(self, key, matrix, default=None):
+"""
+Get an attribute of a xgb.DMatrix
+
+Parameters
+--
+key: str
+The name of the attribute
+matrix: xgb.DMatrix
+The matrix
+default: Optional
+The default value if the item does not exist
+"""
+return
[GitHub] [incubator-tvm] weberlo edited a comment on pull request #5940: Add Quantize/Dequantize Partitioning
weberlo edited a comment on pull request #5940: URL: https://github.com/apache/incubator-tvm/pull/5940#issuecomment-673580414 > @weberlo I believe we would like a general approach to achieve the partitioning in the future, but I am fine with the PR in the current stage. I will approve it after it pass the tests. @ZihengJiang I agree the current implementation is suboptimal, and it would be much better to integrate it more closely with the quantization pass itself. I went with the approach in this PR, because you're in the process of making significant changes to quantization, and this approach should be robust to those changes. We should certainly revisit this feature once your changes land though. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] weberlo commented on pull request #5940: Add Quantize/Dequantize Partitioning
weberlo commented on pull request #5940: URL: https://github.com/apache/incubator-tvm/pull/5940#issuecomment-673580414 > @weberlo I believe we would like a general approach to achieve the partitioning in the future, but I am fine with the PR in the current stage. I will approve it after it pass the tests. I agree the current implementation is suboptimal, and it would be much better to integrate it more closely with the quantization pass itself. I went with the approach in this PR, because you're in the process of making significant changes to quantization, and this approach should be robust to those changes. We should certainly revisit this feature once your changes land though. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] zhiics merged pull request #6254: [BYOC][ACL] Add support for dense (fully connected) layer
zhiics merged pull request #6254: URL: https://github.com/apache/incubator-tvm/pull/6254 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] zhiics commented on pull request #6254: [BYOC][ACL] Add support for dense (fully connected) layer
zhiics commented on pull request #6254: URL: https://github.com/apache/incubator-tvm/pull/6254#issuecomment-673574279 Thanks @lhutton1 @comaniac This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[incubator-tvm] branch master updated (16b2a4b -> 15eef5c)
This is an automated email from the ASF dual-hosted git repository. zhic pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/incubator-tvm.git. from 16b2a4b [Relay][Dyn] Dynamic full operator (#6260) add 15eef5c [BYOC][ACL] Add support for dense (fully connected) layer (#6254) No new revisions were added by this update. Summary of changes: docs/deploy/arm_compute_lib.rst| 7 + python/tvm/relay/op/contrib/arm_compute_lib.py | 74 - .../backend/contrib/arm_compute_lib/codegen.cc | 77 + src/runtime/contrib/arm_compute_lib/acl_runtime.cc | 48 .../contrib/test_arm_compute_lib/test_conv2d.py| 2 +- .../contrib/test_arm_compute_lib/test_dense.py | 319 + .../contrib/test_arm_compute_lib/test_network.py | 2 +- .../contrib/test_arm_compute_lib/test_pooling.py | 2 +- 8 files changed, 527 insertions(+), 4 deletions(-) create mode 100644 tests/python/contrib/test_arm_compute_lib/test_dense.py
[GitHub] [incubator-tvm] zhiics merged pull request #6260: [Relay][Dyn] Dynamic full operator
zhiics merged pull request #6260: URL: https://github.com/apache/incubator-tvm/pull/6260 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[incubator-tvm] branch master updated (c0d11fd -> 16b2a4b)
This is an automated email from the ASF dual-hosted git repository. zhic pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/incubator-tvm.git. from c0d11fd fix cuda half math function is undefined: hpow, htanh (#6253) add 16b2a4b [Relay][Dyn] Dynamic full operator (#6260) No new revisions were added by this update. Summary of changes: python/tvm/relay/op/_tensor.py| 6 +-- python/tvm/relay/op/dyn/_tensor.py| 1 + python/tvm/relay/op/dyn/_transform.py | 2 +- python/tvm/relay/op/transform.py | 6 ++- src/relay/op/dyn/tensor/transform.cc | 56 +++ src/relay/op/make_op.h| 2 +- src/relay/op/tensor/transform.cc | 41 ++--- src/relay/transforms/dynamic_to_static.cc | 10 src/relay/transforms/pattern_util.h | 2 +- tests/python/relay/dyn/test_dynamic_op_level3.py | 24 ++ tests/python/relay/dyn/test_dynamic_op_level6.py | 2 +- tests/python/relay/test_op_level3.py | 1 + tests/python/relay/test_pass_dynamic_to_static.py | 20 13 files changed, 130 insertions(+), 43 deletions(-)
[GitHub] [incubator-tvm] zhiics commented on pull request #6260: [Relay][Dyn] Dynamic full operator
zhiics commented on pull request #6260: URL: https://github.com/apache/incubator-tvm/pull/6260#issuecomment-673567688 Thanks @electriclilies @mbrookhart This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[incubator-tvm] branch master updated (889d3b6 -> c0d11fd)
This is an automated email from the ASF dual-hosted git repository. tqchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/incubator-tvm.git. from 889d3b6 Trivial fix, up the rodata section for the discovery board to 512 bytes. (#6259) add c0d11fd fix cuda half math function is undefined: hpow, htanh (#6253) No new revisions were added by this update. Summary of changes: src/target/source/literal/cuda_half_t.h | 16 1 file changed, 16 insertions(+)
[GitHub] [incubator-tvm] tqchen merged pull request #6253: fix cuda half math function is undefined: hpow, htanh
tqchen merged pull request #6253: URL: https://github.com/apache/incubator-tvm/pull/6253 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] tqchen merged pull request #6264: [LINT] Fix clang-format
tqchen merged pull request #6264: URL: https://github.com/apache/incubator-tvm/pull/6264 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] tqchen merged pull request #6259: Trivial fix, up the rodata section for the discovery board to 512 bytes.
tqchen merged pull request #6259: URL: https://github.com/apache/incubator-tvm/pull/6259 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] tqchen commented on pull request #6259: Trivial fix, up the rodata section for the discovery board to 512 bytes.
tqchen commented on pull request #6259: URL: https://github.com/apache/incubator-tvm/pull/6259#issuecomment-673549135 Thanks @tom-gall ! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[incubator-tvm] branch master updated (2247a2e -> 889d3b6)
This is an automated email from the ASF dual-hosted git repository. tqchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/incubator-tvm.git. from 2247a2e [LINT] Fix clang-format (#6264) add 889d3b6 Trivial fix, up the rodata section for the discovery board to 512 bytes. (#6259) No new revisions were added by this update. Summary of changes: python/tvm/micro/device/arm/stm32f746xx.py | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-)
[GitHub] [incubator-tvm] tqchen closed issue #6246: new --runtime=c fails for uTVM
tqchen closed issue #6246: URL: https://github.com/apache/incubator-tvm/issues/6246 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[incubator-tvm] branch master updated (b6b5ace -> 2247a2e)
This is an automated email from the ASF dual-hosted git repository. tqchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/incubator-tvm.git. from b6b5ace Improve NHWC depthwise convolution for AArch64 (#6095) add 2247a2e [LINT] Fix clang-format (#6264) No new revisions were added by this update. Summary of changes: include/tvm/runtime/packed_func.h | 4 ++-- 1 file changed, 2 insertions(+), 2 deletions(-)
[incubator-tvm] branch master updated (abfa79d -> b6b5ace)
This is an automated email from the ASF dual-hosted git repository. zhaowu pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/incubator-tvm.git. from abfa79d update tutorial to new TARGET as micro_dev is no more (#6262) add b6b5ace Improve NHWC depthwise convolution for AArch64 (#6095) No new revisions were added by this update. Summary of changes: python/tvm/relay/op/strategy/arm_cpu.py| 7 +- python/tvm/relay/qnn/op/legalizations.py | 8 +- python/tvm/topi/arm_cpu/depthwise_conv2d.py| 167 - .../topi/python/test_topi_depthwise_conv2d.py | 1 + 4 files changed, 177 insertions(+), 6 deletions(-)
[GitHub] [incubator-tvm] FrozenGene commented on pull request #6095: Improve NHWC depthwise convolution for AArch64
FrozenGene commented on pull request #6095: URL: https://github.com/apache/incubator-tvm/pull/6095#issuecomment-673519634 Thanks @giuseros Merged now This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] FrozenGene merged pull request #6095: Improve NHWC depthwise convolution for AArch64
FrozenGene merged pull request #6095: URL: https://github.com/apache/incubator-tvm/pull/6095 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] giuseros commented on pull request #6095: Improve NHWC depthwise convolution for AArch64
giuseros commented on pull request #6095: URL: https://github.com/apache/incubator-tvm/pull/6095#issuecomment-673507098 Hi @FrozenGene , @anijain2305 , This PR finally passed the CI. Would it be possible to merge it? Thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] leandron commented on a change in pull request #6267: add dilation in x86 NCHWc depthwise conv support
leandron commented on a change in pull request #6267: URL: https://github.com/apache/incubator-tvm/pull/6267#discussion_r469978920 ## File path: tests/python/topi/python/test_topi_depthwise_conv2d.py ## @@ -268,7 +268,7 @@ def depthwise_conv2d_with_workload_NCHWc(batch, in_channel, in_height, channel_m filter_width = filter_height stride_h = stride_w = stride -assert dilation == 1, "depthwise_conv2d_NCHWc currently does not support dilation." +#assert dilation == 1, "depthwise_conv2d_NCHWc currently does not support dilation." Review comment: Sure, thanks for accepting the suggestions. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] d-smirnov commented on a change in pull request #6018: Added support for tflite quantized maximum and minimum
d-smirnov commented on a change in pull request #6018: URL: https://github.com/apache/incubator-tvm/pull/6018#discussion_r469979193 ## File path: python/tvm/relay/frontend/tflite.py ## @@ -1089,7 +1093,7 @@ def convert_square(self, op): return out -def _convert_elemwise(self, relay_op, op): +def _convert_elemwise(self, relay_op, op, use_real_qnn=True): Review comment: renamed This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] domin1985 opened a new pull request #6271: [Frontend][Relay] Keras frontend prelu bug fix
domin1985 opened a new pull request #6271: URL: https://github.com/apache/incubator-tvm/pull/6271 Hi, A tvm error occurred when I imported a pre-trained keras model: 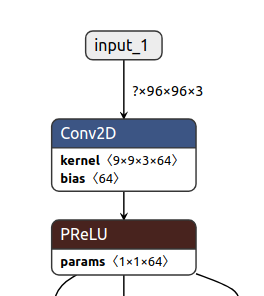 TVMError: Error(s) have occurred. The program has been annotated with them: In `main`: %0 = negative(%v_param_3); %1 = nn.conv2d(%input_1, %v_param_1, padding=[4, 4], channels=64, kernel_size=[9, 9], data_layout="NHWC", kernel_layout="HWIO"); %2 = nn.bias_add(%1, %v_param_2, axis=-1); %3 = negative(%2); %4 = nn.relu(%3); %5 = multiply(%0, %4) Incompatible broadcast type TensorType([64, 1, 1], float32) and TensorType([1, (int64)96, (int64)96, 64], float32); ; %6 = nn.relu(%2); There is something wrong with the prelu convert function in Keras frontend which would result in this shape inferred mis-match error. We would better use relay.nn.prelu op directly. Tests passed using tests/python/frontend/keras/test_forward.py. @siju-samuel @yongwww This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] jcf94 commented on pull request #6269: [Ansor][AutoTVM v2.0] Phase 2: Basic GPU Sketch Search Policy
jcf94 commented on pull request #6269: URL: https://github.com/apache/incubator-tvm/pull/6269#issuecomment-673434269 > Please remove the tutorial. It is better to make the tutorials as a single PR, so people can review it easily and give more suggestions on the API design. It is not good to leave "todo" in the tutorial. > > I think the current API still has room for improvement and I will work on it later. Fine, these modifications are removed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6269: [Ansor][AutoTVM v2.0] Phase 2: Basic GPU Sketch Search Policy
merrymercy edited a comment on pull request #6269: URL: https://github.com/apache/incubator-tvm/pull/6269#issuecomment-673430973 Please remove the tutorial. It is better to make the tutorials as a single PR, so people can review it easily and give more suggestions on the API design. It is not good to leave "todo" in the tutorial. I think the current API still has room for improvement and I will work on it later. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] merrymercy edited a comment on pull request #6269: [Ansor][AutoTVM v2.0] Phase 2: Basic GPU Sketch Search Policy
merrymercy edited a comment on pull request #6269: URL: https://github.com/apache/incubator-tvm/pull/6269#issuecomment-673430973 Please remove the tutorial. It is better to make the tutorials as a single PR, so people can review it easily and give more suggestions on the API design. I think the current API still has room for improvement and I will work on it later. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] merrymercy commented on pull request #6269: [Ansor][AutoTVM v2.0] Phase 2: Basic GPU Sketch Search Policy
merrymercy commented on pull request #6269: URL: https://github.com/apache/incubator-tvm/pull/6269#issuecomment-673430973 Please remove the tutorial. It is better to make the tutorials as a single PR, so people can review it easilly and give more suggestions on the API design. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] merrymercy opened a new pull request #6270: [Ansor][AutoTVM v2.0] Phase 1: XGBoost Cost Model
merrymercy opened a new pull request #6270: URL: https://github.com/apache/incubator-tvm/pull/6270 For the full upstream plan, see [Ansor RFC](https://discuss.tvm.ai/t/rfc-ansor-an-auto-scheduler-for-tvm-autotvm-v2-0/7005/32). This PR adds a xgboost-based cost model. It is similar to the existing xgboost model in autotvm but works on the more general feature representation introduced by #6190 . RMSE is used as the loss function, but the general feature representation needs slightly modification to the loss function. This PR implements a custom loss function "pack-sum-rmse" to support this. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] merrymercy commented on pull request #6270: [Ansor][AutoTVM v2.0] Phase 1: XGBoost Cost Model
merrymercy commented on pull request #6270: URL: https://github.com/apache/incubator-tvm/pull/6270#issuecomment-673430091 cc @jcf94 @comaniac @junrushao1994 @tqchen This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] d-smirnov commented on a change in pull request #6168: Gather operation with indices as tensor expr in TFLite frontend
d-smirnov commented on a change in pull request #6168: URL: https://github.com/apache/incubator-tvm/pull/6168#discussion_r469886837 ## File path: python/tvm/relay/frontend/tflite.py ## @@ -1321,14 +1321,15 @@ def convert_gather(self, op): input_tensors = self.get_input_tensors(op) assert len(input_tensors) == 2, "input tensors length should be 2" -data = self.get_expr(input_tensors[0].tensor_idx) - +if self.has_expr(input_tensors[0].tensor_idx): +data = self.get_expr(input_tensors[0].tensor_idx) +else: +data = self.exp_tab.new_const(self.get_tensor_value(input_tensors[0]), + dtype=self.get_tensor_type_str(input_tensors[0]\ + .tensor.Type())) Review comment: Done This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] lhutton1 commented on a change in pull request #6254: [BYOC][ACL] Add support for dense (fully connected) layer
lhutton1 commented on a change in pull request #6254: URL: https://github.com/apache/incubator-tvm/pull/6254#discussion_r469832156 ## File path: python/tvm/relay/op/contrib/arm_compute_lib.py ## @@ -114,8 +141,26 @@ def check_qnn_conv(extract): call = call.args[0] return qnn_conv2d(call.attrs, call.args) +def check_dense(extract): +"""Check conv pattern is supported by ACL.""" +call = extract Review comment: The out_dtype attribute check is actually on the requantize node. The first node in the extract for fp32 would be nn.bias_add which doesn't have the out_dtype attribute. The out_dtype is checked though in the dense function below. Hope that makes sense :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] mbaret commented on pull request #6228: Constant input attr added to fully connected operation in TFLite frontend
mbaret commented on pull request #6228: URL: https://github.com/apache/incubator-tvm/pull/6228#issuecomment-673392927 I'm still not really sure what's meant by the 'wrap' and can't find anything in the tensorflow/tflite docs named that. It appears to just control whether the input is a constant, in which case could we make it something more explicit like 'const_input'? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] d-smirnov commented on a change in pull request #6228: Constant input attr added to fully connected operation in TFLite frontend
d-smirnov commented on a change in pull request #6228:
URL: https://github.com/apache/incubator-tvm/pull/6228#discussion_r469846267
##
File path: python/tvm/relay/frontend/tflite.py
##
@@ -1695,10 +1695,9 @@ def convert_fully_connected(self, op):
raise ImportError("The tflite package must be installed")
input_tensors = self.get_input_tensors(op)
-assert len(input_tensors) >= 2, "input tensors length should be >= 2"
+assert len(input_tensors) in (2, 3), "input tensors length should be
two or three"
Review comment:
Providing that assertion was made stricter, this is a small improvement.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [incubator-tvm] mbaret commented on a change in pull request #6228: Constant input attr added to fully connected operation in TFLite frontend
mbaret commented on a change in pull request #6228:
URL: https://github.com/apache/incubator-tvm/pull/6228#discussion_r469842573
##
File path: python/tvm/relay/frontend/tflite.py
##
@@ -1695,10 +1695,9 @@ def convert_fully_connected(self, op):
raise ImportError("The tflite package must be installed")
input_tensors = self.get_input_tensors(op)
-assert len(input_tensors) >= 2, "input tensors length should be >= 2"
+assert len(input_tensors) in (2, 3), "input tensors length should be
two or three"
Review comment:
So is this a fix, or is it related to adding support for constant input?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [incubator-tvm] lhutton1 commented on a change in pull request #6254: [BYOC][ACL] Add support for dense (fully connected) layer
lhutton1 commented on a change in pull request #6254: URL: https://github.com/apache/incubator-tvm/pull/6254#discussion_r469832156 ## File path: python/tvm/relay/op/contrib/arm_compute_lib.py ## @@ -114,8 +141,26 @@ def check_qnn_conv(extract): call = call.args[0] return qnn_conv2d(call.attrs, call.args) +def check_dense(extract): +"""Check conv pattern is supported by ACL.""" +call = extract Review comment: Good catch, thanks This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] lhutton1 commented on a change in pull request #6248: [BYOC][ACL] Improved pooling support
lhutton1 commented on a change in pull request #6248:
URL: https://github.com/apache/incubator-tvm/pull/6248#discussion_r469831401
##
File path: tests/python/contrib/test_arm_compute_lib/test_pooling.py
##
@@ -74,53 +142,133 @@ def test_pooling():
device = Device()
np.random.seed(0)
-for dtype, low, high, atol, rtol in [("float32", -127, 128, 0.001, 0.001),
("uint8", 0, 255, 0, 0)]:
-for size in [(2, 2), (3, 3)]:
-for stride in [(2, 2)]:
-shape = (1, size[0] + stride[0] * 5,
- size[1] + stride[1] * 5, 16)
-pad = (0, 0)
-
-inputs = {
-"a": tvm.nd.array(np.random.uniform(low, high,
shape).astype(dtype)),
-}
-
-outputs = []
-func = _get_model(shape, dtype, relay.nn.max_pool2d, size,
- stride, pad, True, iter(inputs))
-for acl in [False, True]:
-outputs.append(build_and_run(func, inputs, 1, None, device,
- enable_acl=acl)[0])
-
-params = {
-"size": size,
-"stride": stride,
-"shape": shape,
-"pooling type": "max",
-"dtype": dtype,
-"padding": pad
-}
-verify(outputs, atol=atol, rtol=rtol, params=params)
+typef = ["nn.max_pool2d", "nn.avg_pool2d", "nn.l2_pool2d"]
+dtype = [("float32", -127, 128, 0.001, 0.001), ("uint8", 0, 255, 1, 0)]
+size = [(2, 2), (3, 3)]
+stride = [(2, 2)]
+pad = [(0, 0), (1, 1), (0, 1)]
+ceil_mode = [False, True]
+count_include_pad = [False, True]
+input_shapes = [(8, 8, 16), (9, 9, 16)]
+trials = generate_trials([typef, dtype, size, stride, pad, ceil_mode,
count_include_pad, input_shapes], 3)
Review comment:
Hmm maybe there was some misunderstanding here, I was simply trying to
align with the convolution tests. I think enumerating all possible combinations
and pruning invalid ones here would lead could lead to too many tests. For
example, pruning uint8 and l2 pooling, a combination of the above trials would
lead to 240 tests. I can simply list a series of trials although I think this
should be communicated across the rest of the tests including convolution.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [incubator-tvm] wjliu1998 commented on a change in pull request #6267: add dilation in x86 NCHWc depthwise conv support
wjliu1998 commented on a change in pull request #6267: URL: https://github.com/apache/incubator-tvm/pull/6267#discussion_r469813115 ## File path: tests/python/topi/python/test_topi_depthwise_conv2d.py ## @@ -268,7 +268,7 @@ def depthwise_conv2d_with_workload_NCHWc(batch, in_channel, in_height, channel_m filter_width = filter_height stride_h = stride_w = stride -assert dilation == 1, "depthwise_conv2d_NCHWc currently does not support dilation." +#assert dilation == 1, "depthwise_conv2d_NCHWc currently does not support dilation." Review comment: Thanks for the review! The comments and logging have been removed! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] leandron commented on a change in pull request #6267: add dilation in x86 NCHWc depthwise conv support
leandron commented on a change in pull request #6267:
URL: https://github.com/apache/incubator-tvm/pull/6267#discussion_r469791300
##
File path: python/tvm/topi/x86/depthwise_conv2d.py
##
@@ -122,13 +122,24 @@ def depthwise_conv2d_NCHWc(cfg, data, kernel, strides,
padding, dilation,
strides = strides if isinstance(strides, (tuple, list)) else (strides,
strides)
HSTR, WSTR = strides
-pad_top, pad_left, pad_down, pad_right = get_pad_tuple(padding,
(filter_height, filter_width))
+#pad_top, pad_left, pad_down, pad_right = get_pad_tuple(padding,
(filter_height, filter_width))
dh, dw = dilation if isinstance(dilation, (tuple, list)) else (dilation,
dilation)
-assert (dh, dw) == (1, 1), "Does not support dilation"
-
-out_height = (in_height - filter_height + pad_top + pad_down) // HSTR + 1
-out_width = (in_width - filter_width + pad_left + pad_right) // WSTR + 1
+#assert (dh, dw) == (1, 1), "Does not support dilation"
+
+dilated_kernel_h = (filter_height - 1) * dh + 1
+dilated_kernel_w = (filter_width - 1) * dw + 1
+pad_top, pad_left, pad_down, pad_right = get_pad_tuple(
+padding, (dilated_kernel_h, dilated_kernel_w))
+print("padding", pad_top, pad_left, pad_down, pad_right, dilated_kernel_h,
padding)
Review comment:
To output messages, it is better to make usage of the logging
functionality. See the `logger` object, created in the beginning of this file.
Same comment applies for other `print` statements below.
##
File path: python/tvm/topi/x86/depthwise_conv2d.py
##
@@ -122,13 +122,24 @@ def depthwise_conv2d_NCHWc(cfg, data, kernel, strides,
padding, dilation,
strides = strides if isinstance(strides, (tuple, list)) else (strides,
strides)
HSTR, WSTR = strides
-pad_top, pad_left, pad_down, pad_right = get_pad_tuple(padding,
(filter_height, filter_width))
+#pad_top, pad_left, pad_down, pad_right = get_pad_tuple(padding,
(filter_height, filter_width))
Review comment:
If this is not useful anymore, please remove it rather than keeping it
commented out here. Same for other commented lines below.
##
File path: tests/python/topi/python/test_topi_depthwise_conv2d.py
##
@@ -268,7 +268,7 @@ def depthwise_conv2d_with_workload_NCHWc(batch, in_channel,
in_height, channel_m
filter_width = filter_height
stride_h = stride_w = stride
-assert dilation == 1, "depthwise_conv2d_NCHWc currently does not support
dilation."
+#assert dilation == 1, "depthwise_conv2d_NCHWc currently does not support
dilation."
Review comment:
If this is not useful anymore, please remove it rather than keeping it
commented out here.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [incubator-tvm] jcf94 opened a new pull request #6269: [Ansor][AutoTVM v2.0] Phase 2: Basic GPU Sketch Search Policy
jcf94 opened a new pull request #6269: URL: https://github.com/apache/incubator-tvm/pull/6269 For full upstream plan, see [Ansor RFC](https://discuss.tvm.ai/t/rfc-ansor-an-auto-scheduler-for-tvm-autotvm-v2-0/7005/32). In this PR, we bring the basic Sketch search policy which is proposed in our [paper](https://arxiv.org/abs/2006.06762) on GPU ops/subgraphs. The complete search policy still waits for the feature extraction & cost model support, so this will be a basic search policy using random cost model. We'll continue to work on the upstreaming process to bring the complete auto schedule support for various workloads on CPU/GPU with some reproducible performance results, a custom sketch rule support to work like the AutoTVM, as well as the tutorials of how to play with AutoScheduler. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] nolanliou opened a new issue #6268: TVMError: Check failed: it != type_definitions.end(): There is no definition of static_tensor_float32_*
nolanliou opened a new issue #6268: URL: https://github.com/apache/incubator-tvm/issues/6268 When I convert a PyTorch Bert model to TVM, there is a problem blow ``` File "tvm/python/tvm/relay/frontend/pytorch.py", line 2673, in from_pytorch default_dtype=default_dtype) File "/tvm/python/tvm/relay/frontend/pytorch.py", line 2580, in convert_operators relay_out = relay_op(inputs, _get_input_types(op_node, default_dtype=default_dtype)) File "tvm/python/tvm/relay/frontend/pytorch.py", line 255, in _impl inferred_shape = _infer_shape(data) File "tvm/python/tvm/relay/frontend/common.py", line 486, in infer_shape out_type = infer_type(inputs, mod=mod) File "tvm/python/tvm/relay/frontend/common.py", line 465, in infer_type new_mod = IRModule.from_expr(node) File "tvm/python/tvm/ir/module.py", line 222, in from_expr return _ffi_api.Module_FromExpr(expr, funcs, defs) File "tvm/python/tvm/_ffi/_ctypes/packed_func.py", line 225, in __call__ raise get_last_ffi_error() tvm._ffi.base.TVMError: Traceback (most recent call last): [bt] (8) tvm/build/libtvm.so(tvm::relay::ExprVisitor::VisitExpr_(tvm::relay::CallNode const*)+0x13c) [0x7f21a6454bdc] [bt] (7) tvm/build/libtvm.so(tvm::relay::ExprVisitor::VisitExpr(tvm::RelayExpr const&)+0x71) [0x7f21a6457711] [bt] (6) tvm/build/libtvm.so(tvm::relay::ExprFunctor::VisitExpr(tvm::RelayExpr const&)+0x5b) [0x7f21a64153eb] [bt] (5) tvm/build/libtvm.so(tvm::relay::ExprVisitor::VisitExpr_(tvm::relay::CallNode const*)+0x13c) [0x7f21a6454bdc] [bt] (4) tvm/build/libtvm.so(tvm::relay::ExprVisitor::VisitExpr(tvm::RelayExpr const&)+0x71) [0x7f21a6457711] [bt] (3) tvm/build/libtvm.so(tvm::relay::ExprFunctor::VisitExpr(tvm::RelayExpr const&)+0x5b) [0x7f21a64153eb] [bt] (2) tvm/build/libtvm.so(tvm::relay::TypeVarEVisitor::VisitExpr_(tvm::ConstructorNode const*)+0x35) [0x7f21a6266505] [bt] (1) tvm/build/libtvm.so(tvm::IRModuleNode::LookupTypeDef(tvm::GlobalTypeVar const&) const+0x14a) [0x7f21a5c34a4a] [bt] (0) tvm/build/libtvm.so(+0xdc19e7) [0x7f21a5c329e7] File "tvm/src/ir/module.cc", line 299 TVMError: Check failed: it != type_definitions.end(): There is no definition of static_tensor_float32_1_4_768_t ``` Part of graph code list below: ``` _234 = torch.transpose(torch.matmul(scores22, v10), 1, 2) h10 = torch.contiguous(_234, memory_format=0) _235 = ops.prim.NumToTensor(torch.size(h10, 0)) _236 = ops.prim.NumToTensor(torch.size(h10, 1)) input114 = torch.view(h10, [int(_235), int(_236), 768]) output68 = torch.matmul(input114, torch.t(CONSTANTS.c143)) input115 = torch.add_(output68, CONSTANTS.c150, alpha=1) _237 = torch.dropout(input115, 0.10001, False) input116 = torch.add(input111, _237, alpha=1) input117 = torch.layer_norm(input116, [768], CONSTANTS.c3, CONSTANTS.c4, 9.9998e-13, True) output69 = torch.matmul(input117, torch.t(CONSTANTS.c151)) x94 = torch.add_(output69, CONSTANTS.c152, alpha=1) _238 = torch.mul(torch.pow(x94, 3), CONSTANTS.c17) _239 = torch.mul(torch.add(x94, _238, alpha=1), CONSTANTS.c18) _240 = torch.mul(x94, CONSTANTS.c19) _241 = torch.add(torch.tanh(_239), CONSTANTS.c20, alpha=1) input118 = torch.mul(_240, _241) output70 = torch.matmul(input118, torch.t(CONSTANTS.c153)) input119 = torch.add_(output70, CONSTANTS.c154, alpha=1) _242 = torch.dropout(input119, 0.10001, False) input120 = torch.add(input117, _242, alpha=1) encoder_out = torch.layer_norm(input120, [768], CONSTANTS.c3, CONSTANTS.c4, 9.9998e-13, True) _243 = torch.slice(encoder_out, 0, 0, 9223372036854775807, 1) input121 = torch.select(_243, 1, 0) input122 = torch.addmm(CONSTANTS.c156, input121, torch.t(CONSTANTS.c155), beta=1, alpha=1) input123 = torch.tanh(input122) input124 = torch.dropout(input123, 0.10001, False) input125 = torch.addmm(CONSTANTS.c158, input124, torch.t(CONSTANTS.c157), beta=1, alpha=1) r = torch.softmax(input125, 1, None) return torch.to(r, 6, False, False) ``` It failed when converting `slice` OP. Has anybody seen this question before? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] wjliu1998 opened a new pull request #6267: add dilation in x86 NCHWc depthwise conv support
wjliu1998 opened a new pull request #6267: URL: https://github.com/apache/incubator-tvm/pull/6267 as mentioned in #4962 (https://github.com/apache/incubator-tvm/issues/4962), the NCHWc depthwise convolution does not support dilation > 1. The problem has been fixed This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] vadimsightx commented on issue #6258: unable to import tvm python
vadimsightx commented on issue #6258: URL: https://github.com/apache/incubator-tvm/issues/6258#issuecomment-673302594 rebuild and works now thanks This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [incubator-tvm] vadimsightx commented on issue #6258: unable to import tvm python
vadimsightx commented on issue #6258: URL: https://github.com/apache/incubator-tvm/issues/6258#issuecomment-673290080 > Hi @vadimsightx. Can you provide a bit more context on how you built TVM, in terms of CMake flags, etc? # Licensed to the Apache Software Foundation (ASF) under one # or more contributor license agreements. See the NOTICE file # distributed with this work for additional information # regarding copyright ownership. The ASF licenses this file # to you under the Apache License, Version 2.0 (the # "License"); you may not use this file except in compliance # with the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, # software distributed under the License is distributed on an # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY # KIND, either express or implied. See the License for the # specific language governing permissions and limitations # under the License. # # Template custom cmake configuration for compiling # # This file is used to override the build options in build. # If you want to change the configuration, please use the following # steps. Assume you are on the root directory. First copy the this # file so that any local changes will be ignored by git # # $ mkdir build # $ cp cmake/config.cmake build # # Next modify the according entries, and then compile by # # $ cd build # $ cmake .. # # Then build in parallel with 8 threads # # $ make -j8 # #- # Backend runtimes. #- # Whether enable CUDA during compile, # # Possible values: # - ON: enable CUDA with cmake's auto search # - OFF: disable CUDA # - /path/to/cuda: use specific path to cuda toolkit set(USE_CUDA OFF) # Whether enable ROCM runtime # # Possible values: # - ON: enable ROCM with cmake's auto search # - OFF: disable ROCM # - /path/to/rocm: use specific path to rocm set(USE_ROCM OFF) # Whether enable SDAccel runtime set(USE_SDACCEL OFF) # Whether enable Intel FPGA SDK for OpenCL (AOCL) runtime set(USE_AOCL OFF) # Whether enable OpenCL runtime set(USE_OPENCL ON) # Whether enable Metal runtime set(USE_METAL OFF) # Whether enable Vulkan runtime # # Possible values: # - ON: enable Vulkan with cmake's auto search # - OFF: disable vulkan # - /path/to/vulkan-sdk: use specific path to vulkan-sdk set(USE_VULKAN OFF) # Whether enable OpenGL runtime set(USE_OPENGL OFF) # Whether enable MicroTVM runtime set(USE_MICRO OFF) # Whether to enable SGX runtime # # Possible values for USE_SGX: # - /path/to/sgxsdk: path to Intel SGX SDK # - OFF: disable SGX # # SGX_MODE := HW|SIM set(USE_SGX OFF) set(SGX_MODE "SIM") set(RUST_SGX_SDK "/path/to/rust-sgx-sdk") # Whether enable RPC runtime set(USE_RPC ON) # Whether embed stackvm into the runtime set(USE_STACKVM_RUNTIME OFF) # Whether enable tiny embedded graph runtime. set(USE_GRAPH_RUNTIME ON) # Whether enable additional graph debug functions set(USE_GRAPH_RUNTIME_DEBUG OFF) # Whether enable additional vm profiler functions set(USE_VM_PROFILER OFF) # Whether enable uTVM standalone runtime set(USE_MICRO_STANDALONE_RUNTIME OFF) # Whether build with LLVM support # Requires LLVM version >= 4.0 # # Possible values: # - ON: enable llvm with cmake's find search # - OFF: disable llvm # - /path/to/llvm-config: enable specific LLVM when multiple llvm-dev is available. set(USE_LLVM ON) #- # Contrib libraries #- # Whether use BLAS, choices: openblas, mkl, atlas, apple set(USE_BLAS none) # /path/to/mkl: mkl root path when use mkl blas library # set(USE_MKL_PATH /opt/intel/mkl) for UNIX # set(USE_MKL_PATH ../IntelSWTools/compilers_and_libraries_2018/windows/mkl) for WIN32 # set(USE_MKL_PATH ) if using `pip install mkl` set(USE_MKL_PATH none) # Whether use MKLDNN library, choices: ON, OFF, path to mkldnn library set(USE_MKLDNN OFF) # Whether use OpenMP thread pool, choices: gnu, intel # Note: "gnu" uses gomp library, "intel" uses iomp5 library set(USE_OPENMP none) # Whether use contrib.random in runtime set(USE_RANDOM OFF) # Whether use NNPack set(USE_NNPACK OFF) # Possible values: # - ON: enable tflite with cmake's find search # - OFF: disable tflite # - /path/to/libtensorflow-lite.a: use
[GitHub] [incubator-tvm] SmallHedgehog opened a new issue #6266: Why is the inference time obtained with module.time_evaluator method less, but the inference time obtained with the method defined by m
SmallHedgehog opened a new issue #6266:
URL: https://github.com/apache/incubator-tvm/issues/6266
# using module.time_evaluator
`
print("Evaluate inference time cost...")
ftimer = module.module.time_evaluator("run", ctx, number=1, repeat=600)
prof_res = np.array(ftimer().results) * 1000 # convert to millisecond
print("Mean inference time (std dev): %.2f ms (%.2f ms)"
%(np.mean(prof_res), np.std(prof_res)))
`
# 27.6ms
# using myself method
`
with tvm.target.cuda():
with autotvm.apply_history_best(log_file):
print("Compile...")
with relay.build_config(opt_level=3):
graph, lib, params = relay.build(mod, 'cuda', 'llvm',
params=params)
tvm_model = graph_runtime.create(graph, lib, ctx)
tvm_model.set_input(**params)
tvm_model.set_input(input_name, tvm.nd.array(image))
times = 0.0
for i in range(600):
s = time.time()
tvm_model.run()
pred = tvm_model.get_output(0).asnumpy()
tvm_out = pred[0]
times += time.time() - s
print(times / 600)
`
# about 72ms
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org