[jira] [Updated] (HIVE-26131) Incorrect OutputFormat when describing jdbc connector table
[
https://issues.apache.org/jira/browse/HIVE-26131?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated HIVE-26131:
--
Labels: pull-request-available (was: )
> Incorrect OutputFormat when describing jdbc connector table
>
>
> Key: HIVE-26131
> URL: https://issues.apache.org/jira/browse/HIVE-26131
> Project: Hive
> Issue Type: Bug
> Components: JDBC storage handler
>Affects Versions: 4.0.0-alpha-1, 4.0.0-alpha-2
>Reporter: zhangbutao
>Assignee: zhangbutao
>Priority: Minor
> Labels: pull-request-available
> Fix For: 4.0.0-alpha-2
>
> Attachments: image-2022-04-12-13-07-09-647.png
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> Step to repro:
> {code:java}
> CREATE CONNECTOR mysql_qtest
> TYPE 'mysql'
> URL 'jdbc:mysql://localhost:3306/testdb'
> WITH DCPROPERTIES (
> "hive.sql.dbcp.username"="root",
> "hive.sql.dbcp.password"="");
> CREATE REMOTE DATABASE db_mysql USING mysql_qtest with
> DBPROPERTIES("connector.remoteDbName"="testdb");
> describe formatted db_mysql.test;{code}
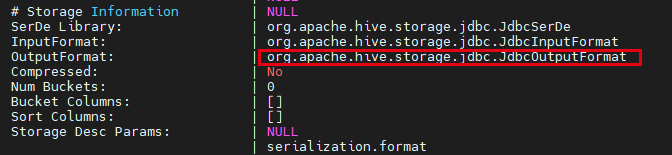
> You can see incorrect OuptputFormat info:
> !image-2022-04-12-13-07-09-647.png!
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Work logged] (HIVE-26131) Incorrect OutputFormat when describing jdbc connector table
[
https://issues.apache.org/jira/browse/HIVE-26131?focusedWorklogId=755609=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755609
]
ASF GitHub Bot logged work on HIVE-26131:
-
Author: ASF GitHub Bot
Created on: 12/Apr/22 05:33
Start Date: 12/Apr/22 05:33
Worklog Time Spent: 10m
Work Description: zhangbutao opened a new pull request, #3200:
URL: https://github.com/apache/hive/pull/3200
### What changes were proposed in this pull request?
Use correct OutputFormat when describing jdbc connector table
### Why are the changes needed?
Incorrect OutputFormat when describing jdbc connector table
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Small fix, just local cluster test.
After the fixing:
Issue Time Tracking
---
Worklog Id: (was: 755609)
Remaining Estimate: 0h
Time Spent: 10m
> Incorrect OutputFormat when describing jdbc connector table
>
>
> Key: HIVE-26131
> URL: https://issues.apache.org/jira/browse/HIVE-26131
> Project: Hive
> Issue Type: Bug
> Components: JDBC storage handler
>Affects Versions: 4.0.0-alpha-1, 4.0.0-alpha-2
>Reporter: zhangbutao
>Assignee: zhangbutao
>Priority: Minor
> Fix For: 4.0.0-alpha-2
>
> Attachments: image-2022-04-12-13-07-09-647.png
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> Step to repro:
> {code:java}
> CREATE CONNECTOR mysql_qtest
> TYPE 'mysql'
> URL 'jdbc:mysql://localhost:3306/testdb'
> WITH DCPROPERTIES (
> "hive.sql.dbcp.username"="root",
> "hive.sql.dbcp.password"="");
> CREATE REMOTE DATABASE db_mysql USING mysql_qtest with
> DBPROPERTIES("connector.remoteDbName"="testdb");
> describe formatted db_mysql.test;{code}
> You can see incorrect OuptputFormat info:
> !image-2022-04-12-13-07-09-647.png!
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (HIVE-26131) Incorrect OutputFormat when describing jdbc connector table
[
https://issues.apache.org/jira/browse/HIVE-26131?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
zhangbutao updated HIVE-26131:
--
Attachment: (was: image-2022-04-12-13-07-36-876.png)
> Incorrect OutputFormat when describing jdbc connector table
>
>
> Key: HIVE-26131
> URL: https://issues.apache.org/jira/browse/HIVE-26131
> Project: Hive
> Issue Type: Bug
> Components: JDBC storage handler
>Affects Versions: 4.0.0-alpha-1, 4.0.0-alpha-2
>Reporter: zhangbutao
>Assignee: zhangbutao
>Priority: Minor
> Fix For: 4.0.0-alpha-2
>
> Attachments: image-2022-04-12-13-07-09-647.png
>
>
> Step to repro:
> {code:java}
> CREATE CONNECTOR mysql_qtest
> TYPE 'mysql'
> URL 'jdbc:mysql://localhost:3306/testdb'
> WITH DCPROPERTIES (
> "hive.sql.dbcp.username"="root",
> "hive.sql.dbcp.password"="");
> CREATE REMOTE DATABASE db_mysql USING mysql_qtest with
> DBPROPERTIES("connector.remoteDbName"="testdb");
> describe formatted db_mysql.test;{code}
> You can see incorrect OuptputFormat info:
> !image-2022-04-12-13-07-09-647.png!
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Work started] (HIVE-26131) Incorrect OutputFormat when describing jdbc connector table
[
https://issues.apache.org/jira/browse/HIVE-26131?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Work on HIVE-26131 started by zhangbutao.
-
> Incorrect OutputFormat when describing jdbc connector table
>
>
> Key: HIVE-26131
> URL: https://issues.apache.org/jira/browse/HIVE-26131
> Project: Hive
> Issue Type: Bug
> Components: JDBC storage handler
>Affects Versions: 4.0.0-alpha-1, 4.0.0-alpha-2
>Reporter: zhangbutao
>Assignee: zhangbutao
>Priority: Minor
> Attachments: image-2022-04-12-13-07-09-647.png,
> image-2022-04-12-13-07-36-876.png
>
>
> Step to repro:
> {code:java}
> CREATE CONNECTOR mysql_qtest
> TYPE 'mysql'
> URL 'jdbc:mysql://localhost:3306/testdb'
> WITH DCPROPERTIES (
> "hive.sql.dbcp.username"="root",
> "hive.sql.dbcp.password"="");
> CREATE REMOTE DATABASE db_mysql USING mysql_qtest with
> DBPROPERTIES("connector.remoteDbName"="testdb");
> describe formatted db_mysql.test;{code}
> You can see incorrect OuptputFormat info:
> !image-2022-04-12-13-07-09-647.png!
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (HIVE-26131) Incorrect OutputFormat when describing jdbc connector table
[
https://issues.apache.org/jira/browse/HIVE-26131?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
zhangbutao updated HIVE-26131:
--
Fix Version/s: 4.0.0-alpha-2
> Incorrect OutputFormat when describing jdbc connector table
>
>
> Key: HIVE-26131
> URL: https://issues.apache.org/jira/browse/HIVE-26131
> Project: Hive
> Issue Type: Bug
> Components: JDBC storage handler
>Affects Versions: 4.0.0-alpha-1, 4.0.0-alpha-2
>Reporter: zhangbutao
>Assignee: zhangbutao
>Priority: Minor
> Fix For: 4.0.0-alpha-2
>
> Attachments: image-2022-04-12-13-07-09-647.png,
> image-2022-04-12-13-07-36-876.png
>
>
> Step to repro:
> {code:java}
> CREATE CONNECTOR mysql_qtest
> TYPE 'mysql'
> URL 'jdbc:mysql://localhost:3306/testdb'
> WITH DCPROPERTIES (
> "hive.sql.dbcp.username"="root",
> "hive.sql.dbcp.password"="");
> CREATE REMOTE DATABASE db_mysql USING mysql_qtest with
> DBPROPERTIES("connector.remoteDbName"="testdb");
> describe formatted db_mysql.test;{code}
> You can see incorrect OuptputFormat info:
> !image-2022-04-12-13-07-09-647.png!
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (HIVE-26131) Incorrect OutputFormat when describing jdbc connector table
[
https://issues.apache.org/jira/browse/HIVE-26131?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
zhangbutao updated HIVE-26131:
--
Description:
Step to repro:
{code:java}
CREATE CONNECTOR mysql_qtest
TYPE 'mysql'
URL 'jdbc:mysql://localhost:3306/testdb'
WITH DCPROPERTIES (
"hive.sql.dbcp.username"="root",
"hive.sql.dbcp.password"="");
CREATE REMOTE DATABASE db_mysql USING mysql_qtest with
DBPROPERTIES("connector.remoteDbName"="testdb");
describe formatted db_mysql.test;{code}
You can see incorrect OuptputFormat info:
!image-2022-04-12-13-07-09-647.png!
was:
Step to repro:
{code:java}
CREATE CONNECTOR mysql_qtest
TYPE 'mysql'
URL 'jdbc:mysql://localhost:3306/testdb'
WITH DCPROPERTIES (
"hive.sql.dbcp.username"="root",
"hive.sql.dbcp.password"="");
CREATE REMOTE DATABASE db_mysql USING mysql_qtest with
DBPROPERTIES("connector.remoteDbName"="testdb");
describe formatted db_mysql.test;{code}
You can see incorrect
!image-2022-04-12-13-07-09-647.png!
> Incorrect OutputFormat when describing jdbc connector table
>
>
> Key: HIVE-26131
> URL: https://issues.apache.org/jira/browse/HIVE-26131
> Project: Hive
> Issue Type: Bug
> Components: JDBC storage handler
>Affects Versions: 4.0.0-alpha-1, 4.0.0-alpha-2
>Reporter: zhangbutao
>Assignee: zhangbutao
>Priority: Minor
> Attachments: image-2022-04-12-13-07-09-647.png,
> image-2022-04-12-13-07-36-876.png
>
>
> Step to repro:
> {code:java}
> CREATE CONNECTOR mysql_qtest
> TYPE 'mysql'
> URL 'jdbc:mysql://localhost:3306/testdb'
> WITH DCPROPERTIES (
> "hive.sql.dbcp.username"="root",
> "hive.sql.dbcp.password"="");
> CREATE REMOTE DATABASE db_mysql USING mysql_qtest with
> DBPROPERTIES("connector.remoteDbName"="testdb");
> describe formatted db_mysql.test;{code}
> You can see incorrect OuptputFormat info:
> !image-2022-04-12-13-07-09-647.png!
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (HIVE-26131) Incorrect OutputFormat when describing jdbc connector table
[
https://issues.apache.org/jira/browse/HIVE-26131?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
zhangbutao updated HIVE-26131:
--
Description:
Step to repro:
{code:java}
CREATE CONNECTOR mysql_qtest
TYPE 'mysql'
URL 'jdbc:mysql://localhost:3306/testdb'
WITH DCPROPERTIES (
"hive.sql.dbcp.username"="root",
"hive.sql.dbcp.password"="");
CREATE REMOTE DATABASE db_mysql USING mysql_qtest with
DBPROPERTIES("connector.remoteDbName"="testdb");
describe formatted db_mysql.test;{code}
You can see incorrect
!image-2022-04-12-13-07-09-647.png!
was:
Step to repro:
{code:java}
CREATE CONNECTOR mysql_qtest
TYPE 'mysql'
URL 'jdbc:mysql://localhost:3306/testdb'
WITH DCPROPERTIES (
"hive.sql.dbcp.username"="root",
"hive.sql.dbcp.password"="");
CREATE REMOTE DATABASE db_mysql USING mysql_qtest with
DBPROPERTIES("connector.remoteDbName"="testdb");
describe formatted db_mysql.test;{code}
> Incorrect OutputFormat when describing jdbc connector table
>
>
> Key: HIVE-26131
> URL: https://issues.apache.org/jira/browse/HIVE-26131
> Project: Hive
> Issue Type: Bug
> Components: JDBC storage handler
>Affects Versions: 4.0.0-alpha-1, 4.0.0-alpha-2
>Reporter: zhangbutao
>Assignee: zhangbutao
>Priority: Minor
> Attachments: image-2022-04-12-13-07-09-647.png,
> image-2022-04-12-13-07-36-876.png
>
>
> Step to repro:
> {code:java}
> CREATE CONNECTOR mysql_qtest
> TYPE 'mysql'
> URL 'jdbc:mysql://localhost:3306/testdb'
> WITH DCPROPERTIES (
> "hive.sql.dbcp.username"="root",
> "hive.sql.dbcp.password"="");
> CREATE REMOTE DATABASE db_mysql USING mysql_qtest with
> DBPROPERTIES("connector.remoteDbName"="testdb");
> describe formatted db_mysql.test;{code}
> You can see incorrect
> !image-2022-04-12-13-07-09-647.png!
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (HIVE-26131) Incorrect OutputFormat when describing jdbc connector table
[
https://issues.apache.org/jira/browse/HIVE-26131?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
zhangbutao updated HIVE-26131:
--
Attachment: image-2022-04-12-13-07-09-647.png
> Incorrect OutputFormat when describing jdbc connector table
>
>
> Key: HIVE-26131
> URL: https://issues.apache.org/jira/browse/HIVE-26131
> Project: Hive
> Issue Type: Bug
> Components: JDBC storage handler
>Affects Versions: 4.0.0-alpha-1, 4.0.0-alpha-2
>Reporter: zhangbutao
>Assignee: zhangbutao
>Priority: Minor
> Attachments: image-2022-04-12-13-07-09-647.png,
> image-2022-04-12-13-07-36-876.png
>
>
> Step to repro:
> {code:java}
> CREATE CONNECTOR mysql_qtest
> TYPE 'mysql'
> URL 'jdbc:mysql://localhost:3306/testdb'
> WITH DCPROPERTIES (
> "hive.sql.dbcp.username"="root",
> "hive.sql.dbcp.password"="");
> CREATE REMOTE DATABASE db_mysql USING mysql_qtest with
> DBPROPERTIES("connector.remoteDbName"="testdb");
> describe formatted db_mysql.test;{code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (HIVE-26131) Incorrect OutputFormat when describing jdbc connector table
[
https://issues.apache.org/jira/browse/HIVE-26131?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
zhangbutao updated HIVE-26131:
--
Attachment: image-2022-04-12-13-07-36-876.png
> Incorrect OutputFormat when describing jdbc connector table
>
>
> Key: HIVE-26131
> URL: https://issues.apache.org/jira/browse/HIVE-26131
> Project: Hive
> Issue Type: Bug
> Components: JDBC storage handler
>Affects Versions: 4.0.0-alpha-1, 4.0.0-alpha-2
>Reporter: zhangbutao
>Assignee: zhangbutao
>Priority: Minor
> Attachments: image-2022-04-12-13-07-09-647.png,
> image-2022-04-12-13-07-36-876.png
>
>
> Step to repro:
> {code:java}
> CREATE CONNECTOR mysql_qtest
> TYPE 'mysql'
> URL 'jdbc:mysql://localhost:3306/testdb'
> WITH DCPROPERTIES (
> "hive.sql.dbcp.username"="root",
> "hive.sql.dbcp.password"="");
> CREATE REMOTE DATABASE db_mysql USING mysql_qtest with
> DBPROPERTIES("connector.remoteDbName"="testdb");
> describe formatted db_mysql.test;{code}
> You can see incorrect
> !image-2022-04-12-13-07-09-647.png!
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Assigned] (HIVE-26131) Incorrect OutputFormat when describing jdbc connector table
[
https://issues.apache.org/jira/browse/HIVE-26131?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
zhangbutao reassigned HIVE-26131:
-
Assignee: zhangbutao
> Incorrect OutputFormat when describing jdbc connector table
>
>
> Key: HIVE-26131
> URL: https://issues.apache.org/jira/browse/HIVE-26131
> Project: Hive
> Issue Type: Bug
> Components: JDBC storage handler
>Affects Versions: 4.0.0-alpha-1, 4.0.0-alpha-2
>Reporter: zhangbutao
>Assignee: zhangbutao
>Priority: Minor
>
> Step to repro:
> {code:java}
> CREATE CONNECTOR mysql_qtest
> TYPE 'mysql'
> URL 'jdbc:mysql://localhost:3306/testdb'
> WITH DCPROPERTIES (
> "hive.sql.dbcp.username"="root",
> "hive.sql.dbcp.password"="");
> CREATE REMOTE DATABASE db_mysql USING mysql_qtest with
> DBPROPERTIES("connector.remoteDbName"="testdb");
> describe formatted db_mysql.test;{code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (HIVE-26131) Incorrect OutputFormat when describing jdbc connector table
[
https://issues.apache.org/jira/browse/HIVE-26131?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
zhangbutao updated HIVE-26131:
--
Description:
Step to repro:
{code:java}
CREATE CONNECTOR mysql_qtest
TYPE 'mysql'
URL 'jdbc:mysql://localhost:3306/testdb'
WITH DCPROPERTIES (
"hive.sql.dbcp.username"="root",
"hive.sql.dbcp.password"="");
CREATE REMOTE DATABASE db_mysql USING mysql_qtest with
DBPROPERTIES("connector.remoteDbName"="testdb");
describe formatted db_mysql.test;{code}
> Incorrect OutputFormat when describing jdbc connector table
>
>
> Key: HIVE-26131
> URL: https://issues.apache.org/jira/browse/HIVE-26131
> Project: Hive
> Issue Type: Bug
> Components: JDBC storage handler
>Affects Versions: 4.0.0-alpha-1, 4.0.0-alpha-2
>Reporter: zhangbutao
>Priority: Minor
>
> Step to repro:
> {code:java}
> CREATE CONNECTOR mysql_qtest
> TYPE 'mysql'
> URL 'jdbc:mysql://localhost:3306/testdb'
> WITH DCPROPERTIES (
> "hive.sql.dbcp.username"="root",
> "hive.sql.dbcp.password"="");
> CREATE REMOTE DATABASE db_mysql USING mysql_qtest with
> DBPROPERTIES("connector.remoteDbName"="testdb");
> describe formatted db_mysql.test;{code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Work logged] (HIVE-21456) Hive Metastore Thrift over HTTP
[ https://issues.apache.org/jira/browse/HIVE-21456?focusedWorklogId=755376=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755376 ] ASF GitHub Bot logged work on HIVE-21456: - Author: ASF GitHub Bot Created on: 11/Apr/22 18:49 Start Date: 11/Apr/22 18:49 Worklog Time Spent: 10m Work Description: sourabh912 commented on code in PR #3105: URL: https://github.com/apache/hive/pull/3105#discussion_r847635937 ## standalone-metastore/pom.xml: ## @@ -361,6 +362,12 @@ runtime true + Hive Metastore Thrift over HTTP > --- > > Key: HIVE-21456 > URL: https://issues.apache.org/jira/browse/HIVE-21456 > Project: Hive > Issue Type: New Feature > Components: Metastore, Standalone Metastore >Reporter: Amit Khanna >Assignee: Sourabh Goyal >Priority: Major > Labels: pull-request-available > Attachments: HIVE-21456.2.patch, HIVE-21456.3.patch, > HIVE-21456.4.patch, HIVE-21456.patch > > Time Spent: 5h > Remaining Estimate: 0h > > Hive Metastore currently doesn't have support for HTTP transport because of > which it is not possible to access it via Knox. Adding support for Thrift > over HTTP transport will allow the clients to access via Knox -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Work logged] (HIVE-21456) Hive Metastore Thrift over HTTP
[
https://issues.apache.org/jira/browse/HIVE-21456?focusedWorklogId=755368=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755368
]
ASF GitHub Bot logged work on HIVE-21456:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 18:20
Start Date: 11/Apr/22 18:20
Worklog Time Spent: 10m
Work Description: sourabh912 commented on code in PR #3105:
URL: https://github.com/apache/hive/pull/3105#discussion_r847613439
##
standalone-metastore/metastore-server/src/main/java/org/apache/hadoop/hive/metastore/HiveMetaStore.java:
##
@@ -343,21 +366,162 @@ public static void startMetaStore(int port,
HadoopThriftAuthBridge bridge,
startMetaStore(port, bridge, conf, false, null);
}
- /**
- * Start Metastore based on a passed {@link HadoopThriftAuthBridge}.
- *
- * @param port The port on which the Thrift server will start to serve
- * @param bridge
- * @param conf Configuration overrides
- * @param startMetaStoreThreads Start the background threads (initiator,
cleaner, statsupdater, etc.)
- * @param startedBackgroundThreads If startMetaStoreThreads is true, this
AtomicBoolean will be switched to true,
- * when all of the background threads are scheduled. Useful for testing
purposes to wait
- * until the MetaStore is fully initialized.
- * @throws Throwable
- */
- public static void startMetaStore(int port, HadoopThriftAuthBridge bridge,
- Configuration conf, boolean startMetaStoreThreads, AtomicBoolean
startedBackgroundThreads) throws Throwable {
-isMetaStoreRemote = true;
+ public static boolean isThriftServerRunning() {
+return thriftServer != null && thriftServer.isRunning();
+ }
+
+ // TODO: Is it worth trying to use a server that supports HTTP/2?
+ // Does the Thrift http client support this?
+
+ public static ThriftServer startHttpMetastore(int port, Configuration conf)
+ throws Exception {
+LOG.info("Attempting to start http metastore server on port: {}", port);
Review Comment:
@pvary : Thanks for the pointers. I have addressed disabling TRACE for HMS
http server.
Issue Time Tracking
---
Worklog Id: (was: 755368)
Time Spent: 4h 50m (was: 4h 40m)
> Hive Metastore Thrift over HTTP
> ---
>
> Key: HIVE-21456
> URL: https://issues.apache.org/jira/browse/HIVE-21456
> Project: Hive
> Issue Type: New Feature
> Components: Metastore, Standalone Metastore
>Reporter: Amit Khanna
>Assignee: Sourabh Goyal
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-21456.2.patch, HIVE-21456.3.patch,
> HIVE-21456.4.patch, HIVE-21456.patch
>
> Time Spent: 4h 50m
> Remaining Estimate: 0h
>
> Hive Metastore currently doesn't have support for HTTP transport because of
> which it is not possible to access it via Knox. Adding support for Thrift
> over HTTP transport will allow the clients to access via Knox
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Work logged] (HIVE-21456) Hive Metastore Thrift over HTTP
[
https://issues.apache.org/jira/browse/HIVE-21456?focusedWorklogId=755367=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755367
]
ASF GitHub Bot logged work on HIVE-21456:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 18:19
Start Date: 11/Apr/22 18:19
Worklog Time Spent: 10m
Work Description: sourabh912 commented on code in PR #3105:
URL: https://github.com/apache/hive/pull/3105#discussion_r847612658
##
standalone-metastore/metastore-server/src/main/java/org/apache/hadoop/hive/metastore/HmsThriftHttpServlet.java:
##
@@ -0,0 +1,116 @@
+/* * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hadoop.hive.metastore;
+
+import java.io.IOException;
+import java.security.PrivilegedExceptionAction;
+import java.util.Enumeration;
+
+import javax.servlet.ServletException;
+import javax.servlet.http.HttpServletRequest;
+import javax.servlet.http.HttpServletResponse;
+import org.apache.hadoop.hive.metastore.utils.MetaStoreUtils;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import org.apache.hadoop.security.UserGroupInformation;
+import org.apache.thrift.TProcessor;
+import org.apache.thrift.protocol.TProtocolFactory;
+import org.apache.thrift.server.TServlet;
+
+public class HmsThriftHttpServlet extends TServlet {
+
+ private static final Logger LOG = LoggerFactory
+ .getLogger(HmsThriftHttpServlet.class);
+
+ private static final String X_USER = MetaStoreUtils.USER_NAME_HTTP_HEADER;
+
+ private final boolean isSecurityEnabled;
+
+ public HmsThriftHttpServlet(TProcessor processor,
+ TProtocolFactory inProtocolFactory, TProtocolFactory outProtocolFactory)
{
+super(processor, inProtocolFactory, outProtocolFactory);
+// This should ideally be reveiving an instance of the Configuration which
is used for the check
+isSecurityEnabled = UserGroupInformation.isSecurityEnabled();
+ }
+
+ public HmsThriftHttpServlet(TProcessor processor,
+ TProtocolFactory protocolFactory) {
+super(processor, protocolFactory);
+isSecurityEnabled = UserGroupInformation.isSecurityEnabled();
+ }
+
+ @Override
+ protected void doPost(HttpServletRequest request,
+ HttpServletResponse response) throws ServletException, IOException {
+
+Enumeration headerNames = request.getHeaderNames();
+if (LOG.isDebugEnabled()) {
+ LOG.debug("Logging headers in request");
+ while (headerNames.hasMoreElements()) {
+String headerName = headerNames.nextElement();
+LOG.debug("Header: [{}], Value: [{}]", headerName,
+request.getHeader(headerName));
+ }
+}
+String userFromHeader = request.getHeader(X_USER);
+if (userFromHeader == null || userFromHeader.isEmpty()) {
+ LOG.error("No user header: {} found", X_USER);
+ response.sendError(HttpServletResponse.SC_FORBIDDEN,
+ "User Header missing");
+ return;
+}
+
+// TODO: These should ideally be in some kind of a Cache with Weak
referencse.
+// If HMS were to set up some kind of a session, this would go into the
session by having
+// this filter work with a custom Processor / or set the username into the
session
+// as is done for HS2.
+// In case of HMS, it looks like each request is independent, and there is
no session
+// information, so the UGI needs to be set up in the Connection layer
itself.
+UserGroupInformation clientUgi;
+// Temporary, and useless for now. Here only to allow this to work on an
otherwise kerberized
+// server.
+if (isSecurityEnabled) {
+ LOG.info("Creating proxy user for: {}", userFromHeader);
+ clientUgi = UserGroupInformation.createProxyUser(userFromHeader,
UserGroupInformation.getLoginUser());
+} else {
+ LOG.info("Creating remote user for: {}", userFromHeader);
+ clientUgi = UserGroupInformation.createRemoteUser(userFromHeader);
+}
+
+
+PrivilegedExceptionAction action = new
PrivilegedExceptionAction() {
+ @Override
+ public Void run() throws Exception {
+HmsThriftHttpServlet.super.doPost(request, response);
+return
[jira] [Work logged] (HIVE-21456) Hive Metastore Thrift over HTTP
[
https://issues.apache.org/jira/browse/HIVE-21456?focusedWorklogId=755363=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755363
]
ASF GitHub Bot logged work on HIVE-21456:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 18:15
Start Date: 11/Apr/22 18:15
Worklog Time Spent: 10m
Work Description: sourabh912 commented on code in PR #3105:
URL: https://github.com/apache/hive/pull/3105#discussion_r847609721
##
standalone-metastore/metastore-server/src/test/java/org/apache/hadoop/hive/metastore/TestRemoteHiveHttpMetaStore.java:
##
@@ -0,0 +1,47 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.hadoop.hive.metastore;
+
+import org.apache.hadoop.hive.metastore.annotation.MetastoreUnitTest;
+import org.junit.experimental.categories.Category;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import org.apache.hadoop.hive.metastore.annotation.MetastoreCheckinTest;
+import org.apache.hadoop.hive.metastore.conf.MetastoreConf;
+import org.apache.hadoop.hive.metastore.conf.MetastoreConf.ConfVars;
+
+@Category(MetastoreCheckinTest.class)
+public class TestRemoteHiveHttpMetaStore extends TestRemoteHiveMetaStore {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(TestRemoteHiveHttpMetaStore.class);
+
+ @Override
+ public void start() throws Exception {
+MetastoreConf.setVar(conf, ConfVars.THRIFT_TRANSPORT_MODE, "http");
+LOG.info("Attempting to start test remote metastore in http mode");
+super.start();
+LOG.info("Successfully started test remote metastore in http mode");
+ }
+
+ @Override
+ protected HiveMetaStoreClient createClient() throws Exception {
+MetastoreConf.setVar(conf,
ConfVars.METASTORE_CLIENT_THRIFT_TRANSPORT_MODE, "http");
+return super.createClient();
+ }
+}
Review Comment:
Done
##
standalone-metastore/metastore-server/src/main/java/org/apache/hadoop/hive/metastore/HmsThriftHttpServlet.java:
##
@@ -0,0 +1,116 @@
+/* * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hadoop.hive.metastore;
+
+import java.io.IOException;
+import java.security.PrivilegedExceptionAction;
+import java.util.Enumeration;
+
+import javax.servlet.ServletException;
+import javax.servlet.http.HttpServletRequest;
+import javax.servlet.http.HttpServletResponse;
+import org.apache.hadoop.hive.metastore.utils.MetaStoreUtils;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import org.apache.hadoop.security.UserGroupInformation;
+import org.apache.thrift.TProcessor;
+import org.apache.thrift.protocol.TProtocolFactory;
+import org.apache.thrift.server.TServlet;
+
+public class HmsThriftHttpServlet extends TServlet {
+
+ private static final Logger LOG = LoggerFactory
+ .getLogger(HmsThriftHttpServlet.class);
+
+ private static final String X_USER = MetaStoreUtils.USER_NAME_HTTP_HEADER;
+
+ private final boolean isSecurityEnabled;
+
+ public HmsThriftHttpServlet(TProcessor processor,
+ TProtocolFactory inProtocolFactory, TProtocolFactory outProtocolFactory)
{
+super(processor, inProtocolFactory, outProtocolFactory);
+// This should ideally be reveiving an instance of the Configuration which
is used for the check
+isSecurityEnabled = UserGroupInformation.isSecurityEnabled();
+ }
+
+ public HmsThriftHttpServlet(TProcessor
[jira] [Work logged] (HIVE-21456) Hive Metastore Thrift over HTTP
[ https://issues.apache.org/jira/browse/HIVE-21456?focusedWorklogId=755362=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755362 ] ASF GitHub Bot logged work on HIVE-21456: - Author: ASF GitHub Bot Created on: 11/Apr/22 18:14 Start Date: 11/Apr/22 18:14 Worklog Time Spent: 10m Work Description: sourabh912 commented on code in PR #3105: URL: https://github.com/apache/hive/pull/3105#discussion_r847609041 ## standalone-metastore/pom.xml: ## @@ -361,6 +362,12 @@ runtime true + Hive Metastore Thrift over HTTP > --- > > Key: HIVE-21456 > URL: https://issues.apache.org/jira/browse/HIVE-21456 > Project: Hive > Issue Type: New Feature > Components: Metastore, Standalone Metastore >Reporter: Amit Khanna >Assignee: Sourabh Goyal >Priority: Major > Labels: pull-request-available > Attachments: HIVE-21456.2.patch, HIVE-21456.3.patch, > HIVE-21456.4.patch, HIVE-21456.patch > > Time Spent: 4h 20m > Remaining Estimate: 0h > > Hive Metastore currently doesn't have support for HTTP transport because of > which it is not possible to access it via Knox. Adding support for Thrift > over HTTP transport will allow the clients to access via Knox -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Work logged] (HIVE-21456) Hive Metastore Thrift over HTTP
[
https://issues.apache.org/jira/browse/HIVE-21456?focusedWorklogId=755360=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755360
]
ASF GitHub Bot logged work on HIVE-21456:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 18:14
Start Date: 11/Apr/22 18:14
Worklog Time Spent: 10m
Work Description: sourabh912 commented on code in PR #3105:
URL: https://github.com/apache/hive/pull/3105#discussion_r847608730
##
itests/hive-unit/src/test/java/org/apache/hive/jdbc/TestSSL.java:
##
@@ -437,15 +439,36 @@ public void testConnectionWrongCertCN() throws Exception {
* Test HMS server with SSL
* @throws Exception
*/
+ @Ignore
@Test
public void testMetastoreWithSSL() throws Exception {
testSSLHMS(true);
}
+ /**
+ * Test HMS server with Http + SSL
+ * @throws Exception
+ */
+ @Test
+ public void testMetastoreWithHttps() throws Exception {
+// MetastoreConf.setBoolVar(conf,
MetastoreConf.ConfVars.EVENT_DB_NOTIFICATION_API_AUTH, false);
+//MetastoreConf.setVar(conf,
MetastoreConf.ConfVars.METASTORE_CLIENT_TRANSPORT_MODE, "http");
+SSLTestUtils.setMetastoreHttpsConf(conf);
+MetastoreConf.setVar(conf,
MetastoreConf.ConfVars.SSL_TRUSTMANAGERFACTORY_ALGORITHM,
+KEY_MANAGER_FACTORY_ALGORITHM);
+MetastoreConf.setVar(conf, MetastoreConf.ConfVars.SSL_TRUSTSTORE_TYPE,
KEY_STORE_TRUST_STORE_TYPE);
+MetastoreConf.setVar(conf, MetastoreConf.ConfVars.SSL_KEYSTORE_TYPE,
KEY_STORE_TRUST_STORE_TYPE);
+MetastoreConf.setVar(conf,
MetastoreConf.ConfVars.SSL_KEYMANAGERFACTORY_ALGORITHM,
+KEY_MANAGER_FACTORY_ALGORITHM);
+
+testSSLHMS(false);
Review Comment:
Thanks for pointing it out. I am setting the conf
`MetastoreConf.ConfVars.SSL_KEYSTORE_TYPE` in testSSLHMS(false) now.
Issue Time Tracking
---
Worklog Id: (was: 755360)
Time Spent: 4h 10m (was: 4h)
> Hive Metastore Thrift over HTTP
> ---
>
> Key: HIVE-21456
> URL: https://issues.apache.org/jira/browse/HIVE-21456
> Project: Hive
> Issue Type: New Feature
> Components: Metastore, Standalone Metastore
>Reporter: Amit Khanna
>Assignee: Sourabh Goyal
>Priority: Major
> Labels: pull-request-available
> Attachments: HIVE-21456.2.patch, HIVE-21456.3.patch,
> HIVE-21456.4.patch, HIVE-21456.patch
>
> Time Spent: 4h 10m
> Remaining Estimate: 0h
>
> Hive Metastore currently doesn't have support for HTTP transport because of
> which it is not possible to access it via Knox. Adding support for Thrift
> over HTTP transport will allow the clients to access via Knox
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Work logged] (HIVE-26102) Implement DELETE statements for Iceberg tables
[
https://issues.apache.org/jira/browse/HIVE-26102?focusedWorklogId=755303=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755303
]
ASF GitHub Bot logged work on HIVE-26102:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 16:37
Start Date: 11/Apr/22 16:37
Worklog Time Spent: 10m
Work Description: pvary commented on code in PR #3131:
URL: https://github.com/apache/hive/pull/3131#discussion_r847528556
##
ql/src/java/org/apache/hadoop/hive/ql/io/IOContext.java:
##
@@ -187,6 +188,14 @@ public void parseRecordIdentifier(Configuration
configuration) {
}
}
+ public void parsePositionDeleteInfo(Configuration configuration) {
+this.pdi = PositionDeleteInfo.parseFromConf(configuration);
Review Comment:
Would it worth to set the `pdi` fields one-by-one instead of creating a new
object for every row?
Issue Time Tracking
---
Worklog Id: (was: 755303)
Time Spent: 17.5h (was: 17h 20m)
> Implement DELETE statements for Iceberg tables
> --
>
> Key: HIVE-26102
> URL: https://issues.apache.org/jira/browse/HIVE-26102
> Project: Hive
> Issue Type: New Feature
>Reporter: Marton Bod
>Assignee: Marton Bod
>Priority: Major
> Labels: pull-request-available
> Time Spent: 17.5h
> Remaining Estimate: 0h
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Work logged] (HIVE-26102) Implement DELETE statements for Iceberg tables
[ https://issues.apache.org/jira/browse/HIVE-26102?focusedWorklogId=755302=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755302 ] ASF GitHub Bot logged work on HIVE-26102: - Author: ASF GitHub Bot Created on: 11/Apr/22 16:34 Start Date: 11/Apr/22 16:34 Worklog Time Spent: 10m Work Description: pvary commented on code in PR #3131: URL: https://github.com/apache/hive/pull/3131#discussion_r847525880 ## ql/src/java/org/apache/hadoop/hive/ql/exec/MapOperator.java: ## @@ -673,7 +674,31 @@ private String toErrorMessage(Writable value, Object row, ObjectInspector inspec ctx.getIoCxt().setRecordIdentifier(null);//so we don't accidentally cache the value; shouldn't //happen since IO layer either knows how to produce ROW__ID or not - but to be safe } - break; + break; +case PARTITION_SPEC_ID: Review Comment: Ok.. I would have accepted the change in the `Deserializer` for this, but I do not see how can we extend the `VirtualColumn` to allow columns from the Deserializer... Any ideas are welcome, until then we will work with this Issue Time Tracking --- Worklog Id: (was: 755302) Time Spent: 17h 20m (was: 17h 10m) > Implement DELETE statements for Iceberg tables > -- > > Key: HIVE-26102 > URL: https://issues.apache.org/jira/browse/HIVE-26102 > Project: Hive > Issue Type: New Feature >Reporter: Marton Bod >Assignee: Marton Bod >Priority: Major > Labels: pull-request-available > Time Spent: 17h 20m > Remaining Estimate: 0h > -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Work logged] (HIVE-26102) Implement DELETE statements for Iceberg tables
[
https://issues.apache.org/jira/browse/HIVE-26102?focusedWorklogId=755298=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755298
]
ASF GitHub Bot logged work on HIVE-26102:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 16:23
Start Date: 11/Apr/22 16:23
Worklog Time Spent: 10m
Work Description: pvary commented on code in PR #3131:
URL: https://github.com/apache/hive/pull/3131#discussion_r847515950
##
iceberg/iceberg-handler/src/main/java/org/apache/iceberg/mr/mapreduce/IcebergInputFormat.java:
##
@@ -468,14 +475,17 @@ private CloseableIterable newOrcIterable(InputFile
inputFile, FileScanTask ta
Set idColumns = spec.identitySourceIds();
Schema partitionSchema = TypeUtil.select(expectedSchema, idColumns);
boolean projectsIdentityPartitionColumns =
!partitionSchema.columns().isEmpty();
- if (projectsIdentityPartitionColumns) {
+ if (expectedSchema.findField(MetadataColumns.PARTITION_COLUMN_ID) !=
null) {
Review Comment:
Why is this change needed?
Issue Time Tracking
---
Worklog Id: (was: 755298)
Time Spent: 17h 10m (was: 17h)
> Implement DELETE statements for Iceberg tables
> --
>
> Key: HIVE-26102
> URL: https://issues.apache.org/jira/browse/HIVE-26102
> Project: Hive
> Issue Type: New Feature
>Reporter: Marton Bod
>Assignee: Marton Bod
>Priority: Major
> Labels: pull-request-available
> Time Spent: 17h 10m
> Remaining Estimate: 0h
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Work logged] (HIVE-26102) Implement DELETE statements for Iceberg tables
[
https://issues.apache.org/jira/browse/HIVE-26102?focusedWorklogId=755280=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755280
]
ASF GitHub Bot logged work on HIVE-26102:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 15:44
Start Date: 11/Apr/22 15:44
Worklog Time Spent: 10m
Work Description: marton-bod commented on code in PR #3131:
URL: https://github.com/apache/hive/pull/3131#discussion_r847473881
##
iceberg/iceberg-handler/src/main/java/org/apache/iceberg/mr/hive/HiveIcebergOutputCommitter.java:
##
@@ -325,9 +327,40 @@ private void commitTable(FileIO io, ExecutorService
executor, JobContext jobCont
"numReduceTasks/numMapTasks", jobContext.getJobID(), name);
return conf.getNumReduceTasks() > 0 ? conf.getNumReduceTasks() :
conf.getNumMapTasks();
});
-Collection dataFiles = dataFiles(numTasks, executor, location,
jobContext, io, true);
-boolean isOverwrite = conf.getBoolean(InputFormatConfig.IS_OVERWRITE,
false);
+if (HiveIcebergStorageHandler.isDelete(conf, name)) {
+ Collection writeResults = collectResults(numTasks,
executor, location, jobContext, io, true);
+ commitDelete(jobContext, table, startTime, writeResults);
+} else if (HiveIcebergStorageHandler.isWrite(conf, name)) {
+ Collection writeResults = collectResults(numTasks,
executor, location, jobContext, io, true);
+ boolean isOverwrite = conf.getBoolean(InputFormatConfig.IS_OVERWRITE,
false);
+ commitInsert(jobContext, table, startTime, writeResults, isOverwrite);
+} else {
+ LOG.info("Unable to determine commit operation type for table: {},
jobID: {}. Will not create a commit.",
+ table, jobContext.getJobID());
+}
+ }
+
+ private void commitDelete(JobContext jobContext, Table table, long
startTime, Collection results) {
Review Comment:
That should allow you to do something like:
```
// update
Transaction transaction = table.newTransaction();
commitDelete(table, Optional.of(transaction), startTime, deleteWriteResults);
commitInsert(table, Optional.of(transaction), startTime, insertWriteResults,
isOverwrite);
transaction.commitTransaction();
```
Issue Time Tracking
---
Worklog Id: (was: 755280)
Time Spent: 17h (was: 16h 50m)
> Implement DELETE statements for Iceberg tables
> --
>
> Key: HIVE-26102
> URL: https://issues.apache.org/jira/browse/HIVE-26102
> Project: Hive
> Issue Type: New Feature
>Reporter: Marton Bod
>Assignee: Marton Bod
>Priority: Major
> Labels: pull-request-available
> Time Spent: 17h
> Remaining Estimate: 0h
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Work logged] (HIVE-26102) Implement DELETE statements for Iceberg tables
[
https://issues.apache.org/jira/browse/HIVE-26102?focusedWorklogId=755279=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755279
]
ASF GitHub Bot logged work on HIVE-26102:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 15:44
Start Date: 11/Apr/22 15:44
Worklog Time Spent: 10m
Work Description: marton-bod commented on code in PR #3131:
URL: https://github.com/apache/hive/pull/3131#discussion_r847473881
##
iceberg/iceberg-handler/src/main/java/org/apache/iceberg/mr/hive/HiveIcebergOutputCommitter.java:
##
@@ -325,9 +327,40 @@ private void commitTable(FileIO io, ExecutorService
executor, JobContext jobCont
"numReduceTasks/numMapTasks", jobContext.getJobID(), name);
return conf.getNumReduceTasks() > 0 ? conf.getNumReduceTasks() :
conf.getNumMapTasks();
});
-Collection dataFiles = dataFiles(numTasks, executor, location,
jobContext, io, true);
-boolean isOverwrite = conf.getBoolean(InputFormatConfig.IS_OVERWRITE,
false);
+if (HiveIcebergStorageHandler.isDelete(conf, name)) {
+ Collection writeResults = collectResults(numTasks,
executor, location, jobContext, io, true);
+ commitDelete(jobContext, table, startTime, writeResults);
+} else if (HiveIcebergStorageHandler.isWrite(conf, name)) {
+ Collection writeResults = collectResults(numTasks,
executor, location, jobContext, io, true);
+ boolean isOverwrite = conf.getBoolean(InputFormatConfig.IS_OVERWRITE,
false);
+ commitInsert(jobContext, table, startTime, writeResults, isOverwrite);
+} else {
+ LOG.info("Unable to determine commit operation type for table: {},
jobID: {}. Will not create a commit.",
+ table, jobContext.getJobID());
+}
+ }
+
+ private void commitDelete(JobContext jobContext, Table table, long
startTime, Collection results) {
Review Comment:
That should allow you to do something like:
```
// update
Transaction transaction = table.newTransaction();
commitDelete(table, Optional.of(transaction), startTime, deleteWriteResults);
commitInsert(table, Optional.of(transaction), startTime, insertWriteResults);
transaction.commitTransaction();
```
Issue Time Tracking
---
Worklog Id: (was: 755279)
Time Spent: 16h 50m (was: 16h 40m)
> Implement DELETE statements for Iceberg tables
> --
>
> Key: HIVE-26102
> URL: https://issues.apache.org/jira/browse/HIVE-26102
> Project: Hive
> Issue Type: New Feature
>Reporter: Marton Bod
>Assignee: Marton Bod
>Priority: Major
> Labels: pull-request-available
> Time Spent: 16h 50m
> Remaining Estimate: 0h
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (HIVE-26129) Non blocking DROP CONNECTOR
[ https://issues.apache.org/jira/browse/HIVE-26129?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HIVE-26129: -- Labels: pull-request-available (was: ) > Non blocking DROP CONNECTOR > --- > > Key: HIVE-26129 > URL: https://issues.apache.org/jira/browse/HIVE-26129 > Project: Hive > Issue Type: Task >Reporter: Denys Kuzmenko >Priority: Major > Labels: pull-request-available > Time Spent: 10m > Remaining Estimate: 0h > > Use a less restrictive lock for data connectors, they do not have any > dependencies on other tables. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Work logged] (HIVE-26129) Non blocking DROP CONNECTOR
[ https://issues.apache.org/jira/browse/HIVE-26129?focusedWorklogId=755238=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755238 ] ASF GitHub Bot logged work on HIVE-26129: - Author: ASF GitHub Bot Created on: 11/Apr/22 13:59 Start Date: 11/Apr/22 13:59 Worklog Time Spent: 10m Work Description: nrg4878 commented on code in PR #3173: URL: https://github.com/apache/hive/pull/3173#discussion_r847360100 ## ql/src/java/org/apache/hadoop/hive/ql/ddl/dataconnector/drop/DropDataConnectorAnalyzer.java: ## @@ -18,13 +18,15 @@ package org.apache.hadoop.hive.ql.ddl.dataconnector.drop; +import org.apache.hadoop.hive.conf.HiveConf; import org.apache.hadoop.hive.metastore.api.DataConnector; import org.apache.hadoop.hive.ql.QueryState; import org.apache.hadoop.hive.ql.exec.TaskFactory; import org.apache.hadoop.hive.ql.ddl.DDLSemanticAnalyzerFactory.DDLType; import org.apache.hadoop.hive.ql.ddl.DDLWork; import org.apache.hadoop.hive.ql.hooks.ReadEntity; import org.apache.hadoop.hive.ql.hooks.WriteEntity; +import org.apache.hadoop.hive.ql.io.AcidUtils; Review Comment: nit: Appears to be unnecessary import ## ql/src/java/org/apache/hadoop/hive/ql/ddl/dataconnector/drop/DropDataConnectorAnalyzer.java: ## @@ -18,13 +18,15 @@ package org.apache.hadoop.hive.ql.ddl.dataconnector.drop; +import org.apache.hadoop.hive.conf.HiveConf; Review Comment: nit: Appears to be unnecessary import. Issue Time Tracking --- Worklog Id: (was: 755238) Remaining Estimate: 0h Time Spent: 10m > Non blocking DROP CONNECTOR > --- > > Key: HIVE-26129 > URL: https://issues.apache.org/jira/browse/HIVE-26129 > Project: Hive > Issue Type: Task >Reporter: Denys Kuzmenko >Priority: Major > Time Spent: 10m > Remaining Estimate: 0h > > Use a less restrictive lock for data connectors, they do not have any > dependencies on other tables. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Work logged] (HIVE-25941) Long compilation time of complex query due to analysis for materialized view rewrite
[
https://issues.apache.org/jira/browse/HIVE-25941?focusedWorklogId=755236=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755236
]
ASF GitHub Bot logged work on HIVE-25941:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 13:58
Start Date: 11/Apr/22 13:58
Worklog Time Spent: 10m
Work Description: kasakrisz commented on code in PR #3014:
URL: https://github.com/apache/hive/pull/3014#discussion_r847360214
##
ql/src/java/org/apache/hadoop/hive/ql/optimizer/calcite/HiveMaterializedViewASTSubQueryRewriteShuttle.java:
##
@@ -0,0 +1,189 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.hadoop.hive.ql.optimizer.calcite;
+
+import org.apache.calcite.plan.RelOptCluster;
+import org.apache.calcite.rel.RelNode;
+import org.apache.calcite.rex.RexNode;
+import org.apache.calcite.tools.RelBuilder;
+import org.apache.hadoop.hive.common.TableName;
+import org.apache.hadoop.hive.ql.lockmgr.HiveTxnManager;
+import org.apache.hadoop.hive.ql.metadata.Hive;
+import org.apache.hadoop.hive.ql.metadata.HiveException;
+import org.apache.hadoop.hive.ql.metadata.HiveRelOptMaterialization;
+import org.apache.hadoop.hive.ql.metadata.Table;
+import org.apache.hadoop.hive.ql.optimizer.calcite.reloperators.HiveFilter;
+import org.apache.hadoop.hive.ql.optimizer.calcite.reloperators.HiveProject;
+import
org.apache.hadoop.hive.ql.optimizer.calcite.rules.views.HiveMaterializedViewUtils;
+import org.apache.hadoop.hive.ql.parse.ASTNode;
+import org.apache.hadoop.hive.ql.parse.CalcitePlanner;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.util.EnumSet;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.Stack;
+import java.util.function.Predicate;
+
+import static java.util.Collections.singletonList;
+import static java.util.Collections.unmodifiableMap;
+import static java.util.Collections.unmodifiableSet;
+import static
org.apache.hadoop.hive.ql.metadata.HiveRelOptMaterialization.RewriteAlgorithm.NON_CALCITE;
+import static
org.apache.hadoop.hive.ql.optimizer.calcite.rules.views.HiveMaterializedViewUtils.extractTable;
+
+/**
+ * Traverse the plan and tries to rewrite subtrees of the plan to materialized
view scans.
+ *
+ * The rewrite depends on whether the subtree's corresponding AST match with
any materialized view
+ * definitions AST.
+ */
+public class HiveMaterializedViewASTSubQueryRewriteShuttle extends
HiveRelShuttleImpl {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(HiveMaterializedViewASTSubQueryRewriteShuttle.class);
+
+ private final Map subQueryMap;
+ private final ASTNode originalAST;
+ private final ASTNode expandedAST;
+ private final RelBuilder relBuilder;
+ private final Hive db;
+ private final Set tablesUsedByOriginalPlan;
+ private final HiveTxnManager txnManager;
+
+ public HiveMaterializedViewASTSubQueryRewriteShuttle(
+ Map subQueryMap,
+ ASTNode originalAST,
+ ASTNode expandedAST,
+ RelBuilder relBuilder,
+ Hive db,
+ Set tablesUsedByOriginalPlan,
+ HiveTxnManager txnManager) {
+this.subQueryMap = unmodifiableMap(subQueryMap);
+this.originalAST = originalAST;
+this.expandedAST = expandedAST;
+this.relBuilder = relBuilder;
+this.db = db;
+this.tablesUsedByOriginalPlan = unmodifiableSet(tablesUsedByOriginalPlan);
+this.txnManager = txnManager;
+ }
+
+ public RelNode rewrite(RelNode relNode) {
+return relNode.accept(this);
+ }
+
+ @Override
+ public RelNode visit(HiveProject project) {
+if (!subQueryMap.containsKey(project)) {
+ // No AST is found for this subtree
+ return super.visit(project);
+}
+
+// The AST associated to the RelNode is part of the original AST, but we
need the expanded one
+// 1. Collect the path elements of this node in the original AST
+Stack path = new Stack<>();
+ASTNode curr = subQueryMap.get(project);
+while (curr != null && curr != originalAST) {
+ path.push(curr.getType());
+ curr = (ASTNode)
[jira] [Work logged] (HIVE-25941) Long compilation time of complex query due to analysis for materialized view rewrite
[
https://issues.apache.org/jira/browse/HIVE-25941?focusedWorklogId=755235=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755235
]
ASF GitHub Bot logged work on HIVE-25941:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 13:58
Start Date: 11/Apr/22 13:58
Worklog Time Spent: 10m
Work Description: kasakrisz commented on code in PR #3014:
URL: https://github.com/apache/hive/pull/3014#discussion_r847359651
##
ql/src/java/org/apache/hadoop/hive/ql/optimizer/calcite/HiveMaterializedViewASTSubQueryRewriteShuttle.java:
##
@@ -0,0 +1,189 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.hadoop.hive.ql.optimizer.calcite;
+
+import org.apache.calcite.plan.RelOptCluster;
+import org.apache.calcite.rel.RelNode;
+import org.apache.calcite.rex.RexNode;
+import org.apache.calcite.tools.RelBuilder;
+import org.apache.hadoop.hive.common.TableName;
+import org.apache.hadoop.hive.ql.lockmgr.HiveTxnManager;
+import org.apache.hadoop.hive.ql.metadata.Hive;
+import org.apache.hadoop.hive.ql.metadata.HiveException;
+import org.apache.hadoop.hive.ql.metadata.HiveRelOptMaterialization;
+import org.apache.hadoop.hive.ql.metadata.Table;
+import org.apache.hadoop.hive.ql.optimizer.calcite.reloperators.HiveFilter;
+import org.apache.hadoop.hive.ql.optimizer.calcite.reloperators.HiveProject;
+import
org.apache.hadoop.hive.ql.optimizer.calcite.rules.views.HiveMaterializedViewUtils;
+import org.apache.hadoop.hive.ql.parse.ASTNode;
+import org.apache.hadoop.hive.ql.parse.CalcitePlanner;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.util.EnumSet;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.Stack;
+import java.util.function.Predicate;
+
+import static java.util.Collections.singletonList;
+import static java.util.Collections.unmodifiableMap;
+import static java.util.Collections.unmodifiableSet;
+import static
org.apache.hadoop.hive.ql.metadata.HiveRelOptMaterialization.RewriteAlgorithm.NON_CALCITE;
+import static
org.apache.hadoop.hive.ql.optimizer.calcite.rules.views.HiveMaterializedViewUtils.extractTable;
+
+/**
+ * Traverse the plan and tries to rewrite subtrees of the plan to materialized
view scans.
+ *
+ * The rewrite depends on whether the subtree's corresponding AST match with
any materialized view
+ * definitions AST.
+ */
+public class HiveMaterializedViewASTSubQueryRewriteShuttle extends
HiveRelShuttleImpl {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(HiveMaterializedViewASTSubQueryRewriteShuttle.class);
+
+ private final Map subQueryMap;
+ private final ASTNode originalAST;
+ private final ASTNode expandedAST;
+ private final RelBuilder relBuilder;
+ private final Hive db;
+ private final Set tablesUsedByOriginalPlan;
+ private final HiveTxnManager txnManager;
+
+ public HiveMaterializedViewASTSubQueryRewriteShuttle(
+ Map subQueryMap,
+ ASTNode originalAST,
+ ASTNode expandedAST,
+ RelBuilder relBuilder,
+ Hive db,
+ Set tablesUsedByOriginalPlan,
+ HiveTxnManager txnManager) {
+this.subQueryMap = unmodifiableMap(subQueryMap);
+this.originalAST = originalAST;
+this.expandedAST = expandedAST;
+this.relBuilder = relBuilder;
+this.db = db;
+this.tablesUsedByOriginalPlan = unmodifiableSet(tablesUsedByOriginalPlan);
+this.txnManager = txnManager;
+ }
+
+ public RelNode rewrite(RelNode relNode) {
+return relNode.accept(this);
+ }
+
+ @Override
+ public RelNode visit(HiveProject project) {
+if (!subQueryMap.containsKey(project)) {
Review Comment:
Added check
Issue Time Tracking
---
Worklog Id: (was: 755235)
Time Spent: 1.5h (was: 1h 20m)
> Long compilation time of complex query due to analysis for materialized view
> rewrite
>
>
> Key: HIVE-25941
> URL: https://issues.apache.org/jira/browse/HIVE-25941
> Project:
[jira] [Work logged] (HIVE-26102) Implement DELETE statements for Iceberg tables
[ https://issues.apache.org/jira/browse/HIVE-26102?focusedWorklogId=755231=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755231 ] ASF GitHub Bot logged work on HIVE-26102: - Author: ASF GitHub Bot Created on: 11/Apr/22 13:46 Start Date: 11/Apr/22 13:46 Worklog Time Spent: 10m Work Description: marton-bod commented on PR #3131: URL: https://github.com/apache/hive/pull/3131#issuecomment-1095073865 @pvary I've refactored the `UpdateDeleteSemanticAnalyzer` to obtain the selectColumns and sortColumns during query rewriting from the `HiveStorageHandler` (see HiveStorageHandler#acidSelectColumns and HiveStorageHandler#acidSortColumns in [509c58b](https://github.com/apache/hive/pull/3131/commits/509c58b94693394e031b8780d3e6805286c85262)) Issue Time Tracking --- Worklog Id: (was: 755231) Time Spent: 16h 40m (was: 16.5h) > Implement DELETE statements for Iceberg tables > -- > > Key: HIVE-26102 > URL: https://issues.apache.org/jira/browse/HIVE-26102 > Project: Hive > Issue Type: New Feature >Reporter: Marton Bod >Assignee: Marton Bod >Priority: Major > Labels: pull-request-available > Time Spent: 16h 40m > Remaining Estimate: 0h > -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Work logged] (HIVE-26102) Implement DELETE statements for Iceberg tables
[
https://issues.apache.org/jira/browse/HIVE-26102?focusedWorklogId=755230=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755230
]
ASF GitHub Bot logged work on HIVE-26102:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 13:43
Start Date: 11/Apr/22 13:43
Worklog Time Spent: 10m
Work Description: marton-bod commented on code in PR #3131:
URL: https://github.com/apache/hive/pull/3131#discussion_r847343603
##
iceberg/iceberg-handler/src/main/java/org/apache/iceberg/mr/hive/HiveIcebergOutputCommitter.java:
##
@@ -325,9 +327,40 @@ private void commitTable(FileIO io, ExecutorService
executor, JobContext jobCont
"numReduceTasks/numMapTasks", jobContext.getJobID(), name);
return conf.getNumReduceTasks() > 0 ? conf.getNumReduceTasks() :
conf.getNumMapTasks();
});
-Collection dataFiles = dataFiles(numTasks, executor, location,
jobContext, io, true);
-boolean isOverwrite = conf.getBoolean(InputFormatConfig.IS_OVERWRITE,
false);
+if (HiveIcebergStorageHandler.isDelete(conf, name)) {
+ Collection writeResults = collectResults(numTasks,
executor, location, jobContext, io, true);
+ commitDelete(jobContext, table, startTime, writeResults);
+} else if (HiveIcebergStorageHandler.isWrite(conf, name)) {
+ Collection writeResults = collectResults(numTasks,
executor, location, jobContext, io, true);
+ boolean isOverwrite = conf.getBoolean(InputFormatConfig.IS_OVERWRITE,
false);
+ commitInsert(jobContext, table, startTime, writeResults, isOverwrite);
+} else {
+ LOG.info("Unable to determine commit operation type for table: {},
jobID: {}. Will not create a commit.",
+ table, jobContext.getJobID());
+}
+ }
+
+ private void commitDelete(JobContext jobContext, Table table, long
startTime, Collection results) {
Review Comment:
Thanks for checking! I've refactored the `commitDelete` and `commitInsert`
to use an optional Transaction object, which can be passed in case of an update
or merge query.
Issue Time Tracking
---
Worklog Id: (was: 755230)
Time Spent: 16.5h (was: 16h 20m)
> Implement DELETE statements for Iceberg tables
> --
>
> Key: HIVE-26102
> URL: https://issues.apache.org/jira/browse/HIVE-26102
> Project: Hive
> Issue Type: New Feature
>Reporter: Marton Bod
>Assignee: Marton Bod
>Priority: Major
> Labels: pull-request-available
> Time Spent: 16.5h
> Remaining Estimate: 0h
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Work logged] (HIVE-26102) Implement DELETE statements for Iceberg tables
[ https://issues.apache.org/jira/browse/HIVE-26102?focusedWorklogId=755228=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755228 ] ASF GitHub Bot logged work on HIVE-26102: - Author: ASF GitHub Bot Created on: 11/Apr/22 13:39 Start Date: 11/Apr/22 13:39 Worklog Time Spent: 10m Work Description: marton-bod commented on code in PR #3131: URL: https://github.com/apache/hive/pull/3131#discussion_r847339367 ## ql/src/java/org/apache/hadoop/hive/ql/exec/MapOperator.java: ## @@ -673,7 +674,31 @@ private String toErrorMessage(Writable value, Object row, ObjectInspector inspec ctx.getIoCxt().setRecordIdentifier(null);//so we don't accidentally cache the value; shouldn't //happen since IO layer either knows how to produce ROW__ID or not - but to be safe } - break; + break; +case PARTITION_SPEC_ID: Review Comment: Unfortunately we don't have the Table object anywhere around this area as far as I can tell, so I'm not sure how we could inject the logic using the storage handler. Besides, this method is called `populateVirtualColumns` where all the other virtual cols are filled out too, so right now I don't see a better place to put it Issue Time Tracking --- Worklog Id: (was: 755228) Time Spent: 16h 20m (was: 16h 10m) > Implement DELETE statements for Iceberg tables > -- > > Key: HIVE-26102 > URL: https://issues.apache.org/jira/browse/HIVE-26102 > Project: Hive > Issue Type: New Feature >Reporter: Marton Bod >Assignee: Marton Bod >Priority: Major > Labels: pull-request-available > Time Spent: 16h 20m > Remaining Estimate: 0h > -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Work logged] (HIVE-26130) Incorrect matching of external table when validating NOT NULL constraints
[
https://issues.apache.org/jira/browse/HIVE-26130?focusedWorklogId=755225=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755225
]
ASF GitHub Bot logged work on HIVE-26130:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 13:37
Start Date: 11/Apr/22 13:37
Worklog Time Spent: 10m
Work Description: zhangbutao commented on PR #3199:
URL: https://github.com/apache/hive/pull/3199#issuecomment-1095063659
Failed tests unrelated
Issue Time Tracking
---
Worklog Id: (was: 755225)
Time Spent: 20m (was: 10m)
> Incorrect matching of external table when validating NOT NULL constraints
> -
>
> Key: HIVE-26130
> URL: https://issues.apache.org/jira/browse/HIVE-26130
> Project: Hive
> Issue Type: Bug
>Affects Versions: 4.0.0-alpha-1, 4.0.0-alpha-2
>Reporter: zhangbutao
>Assignee: zhangbutao
>Priority: Major
> Labels: pull-request-available
> Fix For: 4.0.0-alpha-2
>
> Time Spent: 20m
> Remaining Estimate: 0h
>
> _AbstractAlterTablePropertiesAnalyzer.validate_ uses incorrect external table
> judgment statement:
> {code:java}
> else if (entry.getKey().equals("external") && entry.getValue().equals("true")
> {code}
> In current hive code, we use hive tblproperties('EXTERNAL'='true' or
> 'EXTERNAL'='TRUE) to validate external table.
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Work logged] (HIVE-25941) Long compilation time of complex query due to analysis for materialized view rewrite
[
https://issues.apache.org/jira/browse/HIVE-25941?focusedWorklogId=755214=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755214
]
ASF GitHub Bot logged work on HIVE-25941:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 13:06
Start Date: 11/Apr/22 13:06
Worklog Time Spent: 10m
Work Description: kasakrisz commented on code in PR #3014:
URL: https://github.com/apache/hive/pull/3014#discussion_r847305506
##
ql/src/java/org/apache/hadoop/hive/ql/metadata/MaterializedViewsCache.java:
##
@@ -205,4 +212,52 @@ HiveRelOptMaterialization get(String dbName, String
viewName) {
public boolean isEmpty() {
return materializedViews.isEmpty();
}
+
+
+ private static class ASTKey {
+private final ASTNode root;
+
+public ASTKey(ASTNode root) {
+ this.root = root;
+}
+
+@Override
+public boolean equals(Object o) {
+ if (this == o) return true;
+ if (o == null || getClass() != o.getClass()) return false;
+ ASTKey that = (ASTKey) o;
+ return equals(root, that.root);
+}
+
+private boolean equals(ASTNode astNode1, ASTNode astNode2) {
+ if (!(astNode1.getType() == astNode2.getType() &&
+ astNode1.getText().equals(astNode2.getText()) &&
+ astNode1.getChildCount() == astNode2.getChildCount())) {
+return false;
+ }
+
+ for (int i = 0; i < astNode1.getChildCount(); ++i) {
+if (!equals((ASTNode) astNode1.getChild(i), (ASTNode)
astNode2.getChild(i))) {
+ return false;
+}
+ }
+
+ return true;
+}
+
+@Override
+public int hashCode() {
+ return hashcode(root);
Review Comment:
* Hashcode of the ASTs stored in the `MaterializedViewCache` calculated only
once: when the MVs are loaded when hs2 starts or a new MV is created because
Java hashmap implementation caches the key's hashcode.
* When we look-up a Materialization the hashcode of the key is calculated
every time the get method is called. This is called only once for the entire
tree per query.
* To find sub-query rewrites the look-up is done by sub AST-s and the
hashcode is also calculated for the subTrees but when I did some performance
tests locally I didn't found this as a bottleneck.
This solution is still much faster then generating the expanded query text
of every possible sub-query using `UnparseTranslator` and `TokenRewriteStream`.
Issue Time Tracking
---
Worklog Id: (was: 755214)
Time Spent: 1h 20m (was: 1h 10m)
> Long compilation time of complex query due to analysis for materialized view
> rewrite
>
>
> Key: HIVE-25941
> URL: https://issues.apache.org/jira/browse/HIVE-25941
> Project: Hive
> Issue Type: Bug
> Components: Materialized views
>Reporter: Krisztian Kasa
>Assignee: Krisztian Kasa
>Priority: Major
> Labels: pull-request-available
> Attachments: sample.png
>
> Time Spent: 1h 20m
> Remaining Estimate: 0h
>
> When compiling query the optimizer tries to rewrite the query plan or
> subtrees of the plan to use materialized view scans.
> If
> {code}
> set hive.materializedview.rewriting.sql.subquery=false;
> {code}
> the compilation succeed in less then 10 sec otherwise it takes several
> minutes (~ 5min) depending on the hardware.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Work logged] (HIVE-26093) Deduplicate org.apache.hadoop.hive.metastore.annotation package-info.java
[
https://issues.apache.org/jira/browse/HIVE-26093?focusedWorklogId=755195=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755195
]
ASF GitHub Bot logged work on HIVE-26093:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 12:07
Start Date: 11/Apr/22 12:07
Worklog Time Spent: 10m
Work Description: pvary commented on code in PR #3168:
URL: https://github.com/apache/hive/pull/3168#discussion_r847253069
##
standalone-metastore/pom.xml:
##
@@ -531,6 +531,29 @@
+
+ javadoc
+
+
+
+org.apache.maven.plugins
+maven-javadoc-plugin
Review Comment:
Since the javadoc generation is a big mess ATM, I would suggest to keep it
as it is, and if the tests are failing then we can decide what we want to do
with them.
See also: #3185
Issue Time Tracking
---
Worklog Id: (was: 755195)
Time Spent: 2h 10m (was: 2h)
> Deduplicate org.apache.hadoop.hive.metastore.annotation package-info.java
> -
>
> Key: HIVE-26093
> URL: https://issues.apache.org/jira/browse/HIVE-26093
> Project: Hive
> Issue Type: Task
>Reporter: Peter Vary
>Assignee: Peter Vary
>Priority: Major
> Labels: pull-request-available
> Fix For: 4.0.0
>
> Time Spent: 2h 10m
> Remaining Estimate: 0h
>
> Currently we define
> org.apache.hadoop.hive.metastore.annotation.MetastoreVersionAnnotation in 2
> places:
> -
> ./standalone-metastore/metastore-common/src/gen/version/org/apache/hadoop/hive/metastore/annotation/package-info.java
> -
> ./standalone-metastore/metastore-server/src/gen/version/org/apache/hadoop/hive/metastore/annotation/package-info.java
> This causes javadoc generation to fail with:
> {code}
> [ERROR] Failed to execute goal
> org.apache.maven.plugins:maven-javadoc-plugin:3.0.1:aggregate (default-cli)
> on project hive: An error has occurred in Javadoc report generation:
> [ERROR] Exit code: 1 -
> /Users/pvary/dev/upstream/hive/standalone-metastore/metastore-server/src/gen/version/org/apache/hadoop/hive/metastore/annotation/package-info.java:8:
> warning: a package-info.java file has already been seen for package
> org.apache.hadoop.hive.metastore.annotation
> [ERROR] package org.apache.hadoop.hive.metastore.annotation;
> [ERROR] ^
> [ERROR] javadoc: warning - Multiple sources of package comments found for
> package "org.apache.hive.streaming"
> [ERROR]
> /Users/pvary/dev/upstream/hive/ql/src/java/org/apache/hadoop/hive/ql/exec/SerializationUtilities.java:556:
> error: type MapSerializer does not take parameters
> [ERROR] com.esotericsoftware.kryo.serializers.MapSerializer {
> [ERROR] ^
> [ERROR]
> /Users/pvary/dev/upstream/hive/standalone-metastore/metastore-server/src/gen/version/org/apache/hadoop/hive/metastore/annotation/package-info.java:4:
> error: package org.apache.hadoop.hive.metastore.annotation has already been
> annotated
> [ERROR] @MetastoreVersionAnnotation(version="4.0.0-alpha-1",
> shortVersion="4.0.0-alpha-1",
> [ERROR] ^
> [ERROR] java.lang.AssertionError
> [ERROR] at com.sun.tools.javac.util.Assert.error(Assert.java:126)
> [ERROR] at com.sun.tools.javac.util.Assert.check(Assert.java:45)
> [ERROR] at
> com.sun.tools.javac.code.SymbolMetadata.setDeclarationAttributesWithCompletion(SymbolMetadata.java:177)
> [ERROR] at
> com.sun.tools.javac.code.Symbol.setDeclarationAttributesWithCompletion(Symbol.java:215)
> [ERROR] at
> com.sun.tools.javac.comp.MemberEnter.actualEnterAnnotations(MemberEnter.java:952)
> [ERROR] at
> com.sun.tools.javac.comp.MemberEnter.access$600(MemberEnter.java:64)
> [ERROR] at
> com.sun.tools.javac.comp.MemberEnter$5.run(MemberEnter.java:876)
> [ERROR] at com.sun.tools.javac.comp.Annotate.flush(Annotate.java:143)
> [ERROR] at
> com.sun.tools.javac.comp.Annotate.enterDone(Annotate.java:129)
> [ERROR] at com.sun.tools.javac.comp.Enter.complete(Enter.java:512)
> [ERROR] at com.sun.tools.javac.comp.Enter.main(Enter.java:471)
> [ERROR] at com.sun.tools.javadoc.JavadocEnter.main(JavadocEnter.java:78)
> [ERROR] at
> com.sun.tools.javadoc.JavadocTool.getRootDocImpl(JavadocTool.java:186)
> [ERROR] at com.sun.tools.javadoc.Start.parseAndExecute(Start.java:346)
> [ERROR] at com.sun.tools.javadoc.Start.begin(Start.java:219)
> [ERROR] at com.sun.tools.javadoc.Start.begin(Start.java:205)
> [ERROR] at com.sun.tools.javadoc.Main.execute(Main.java:64)
> [ERROR] at com.sun.tools.javadoc.Main.main(Main.java:54)
> [ERROR] javadoc: error - fatal error
[jira] [Resolved] (HIVE-26093) Deduplicate org.apache.hadoop.hive.metastore.annotation package-info.java
[
https://issues.apache.org/jira/browse/HIVE-26093?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Peter Vary resolved HIVE-26093.
---
Fix Version/s: 4.0.0
Resolution: Fixed
Pushed to master.
Thanks for the review [~zabetak]!
> Deduplicate org.apache.hadoop.hive.metastore.annotation package-info.java
> -
>
> Key: HIVE-26093
> URL: https://issues.apache.org/jira/browse/HIVE-26093
> Project: Hive
> Issue Type: Task
>Reporter: Peter Vary
>Assignee: Peter Vary
>Priority: Major
> Labels: pull-request-available
> Fix For: 4.0.0
>
> Time Spent: 2h
> Remaining Estimate: 0h
>
> Currently we define
> org.apache.hadoop.hive.metastore.annotation.MetastoreVersionAnnotation in 2
> places:
> -
> ./standalone-metastore/metastore-common/src/gen/version/org/apache/hadoop/hive/metastore/annotation/package-info.java
> -
> ./standalone-metastore/metastore-server/src/gen/version/org/apache/hadoop/hive/metastore/annotation/package-info.java
> This causes javadoc generation to fail with:
> {code}
> [ERROR] Failed to execute goal
> org.apache.maven.plugins:maven-javadoc-plugin:3.0.1:aggregate (default-cli)
> on project hive: An error has occurred in Javadoc report generation:
> [ERROR] Exit code: 1 -
> /Users/pvary/dev/upstream/hive/standalone-metastore/metastore-server/src/gen/version/org/apache/hadoop/hive/metastore/annotation/package-info.java:8:
> warning: a package-info.java file has already been seen for package
> org.apache.hadoop.hive.metastore.annotation
> [ERROR] package org.apache.hadoop.hive.metastore.annotation;
> [ERROR] ^
> [ERROR] javadoc: warning - Multiple sources of package comments found for
> package "org.apache.hive.streaming"
> [ERROR]
> /Users/pvary/dev/upstream/hive/ql/src/java/org/apache/hadoop/hive/ql/exec/SerializationUtilities.java:556:
> error: type MapSerializer does not take parameters
> [ERROR] com.esotericsoftware.kryo.serializers.MapSerializer {
> [ERROR] ^
> [ERROR]
> /Users/pvary/dev/upstream/hive/standalone-metastore/metastore-server/src/gen/version/org/apache/hadoop/hive/metastore/annotation/package-info.java:4:
> error: package org.apache.hadoop.hive.metastore.annotation has already been
> annotated
> [ERROR] @MetastoreVersionAnnotation(version="4.0.0-alpha-1",
> shortVersion="4.0.0-alpha-1",
> [ERROR] ^
> [ERROR] java.lang.AssertionError
> [ERROR] at com.sun.tools.javac.util.Assert.error(Assert.java:126)
> [ERROR] at com.sun.tools.javac.util.Assert.check(Assert.java:45)
> [ERROR] at
> com.sun.tools.javac.code.SymbolMetadata.setDeclarationAttributesWithCompletion(SymbolMetadata.java:177)
> [ERROR] at
> com.sun.tools.javac.code.Symbol.setDeclarationAttributesWithCompletion(Symbol.java:215)
> [ERROR] at
> com.sun.tools.javac.comp.MemberEnter.actualEnterAnnotations(MemberEnter.java:952)
> [ERROR] at
> com.sun.tools.javac.comp.MemberEnter.access$600(MemberEnter.java:64)
> [ERROR] at
> com.sun.tools.javac.comp.MemberEnter$5.run(MemberEnter.java:876)
> [ERROR] at com.sun.tools.javac.comp.Annotate.flush(Annotate.java:143)
> [ERROR] at
> com.sun.tools.javac.comp.Annotate.enterDone(Annotate.java:129)
> [ERROR] at com.sun.tools.javac.comp.Enter.complete(Enter.java:512)
> [ERROR] at com.sun.tools.javac.comp.Enter.main(Enter.java:471)
> [ERROR] at com.sun.tools.javadoc.JavadocEnter.main(JavadocEnter.java:78)
> [ERROR] at
> com.sun.tools.javadoc.JavadocTool.getRootDocImpl(JavadocTool.java:186)
> [ERROR] at com.sun.tools.javadoc.Start.parseAndExecute(Start.java:346)
> [ERROR] at com.sun.tools.javadoc.Start.begin(Start.java:219)
> [ERROR] at com.sun.tools.javadoc.Start.begin(Start.java:205)
> [ERROR] at com.sun.tools.javadoc.Main.execute(Main.java:64)
> [ERROR] at com.sun.tools.javadoc.Main.main(Main.java:54)
> [ERROR] javadoc: error - fatal error
> [ERROR]
> [ERROR] Command line was:
> /usr/local/Cellar/openjdk@8/1.8.0+302/libexec/openjdk.jdk/Contents/Home/jre/../bin/javadoc
> @options @packages
> [ERROR]
> [ERROR] Refer to the generated Javadoc files in
> '/Users/pvary/dev/upstream/hive/target/site/apidocs' dir.
> {code}
> We should fix this by removing one of the above
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Work logged] (HIVE-26093) Deduplicate org.apache.hadoop.hive.metastore.annotation package-info.java
[
https://issues.apache.org/jira/browse/HIVE-26093?focusedWorklogId=755194=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755194
]
ASF GitHub Bot logged work on HIVE-26093:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 12:04
Start Date: 11/Apr/22 12:04
Worklog Time Spent: 10m
Work Description: pvary merged PR #3168:
URL: https://github.com/apache/hive/pull/3168
Issue Time Tracking
---
Worklog Id: (was: 755194)
Time Spent: 2h (was: 1h 50m)
> Deduplicate org.apache.hadoop.hive.metastore.annotation package-info.java
> -
>
> Key: HIVE-26093
> URL: https://issues.apache.org/jira/browse/HIVE-26093
> Project: Hive
> Issue Type: Task
>Reporter: Peter Vary
>Assignee: Peter Vary
>Priority: Major
> Labels: pull-request-available
> Time Spent: 2h
> Remaining Estimate: 0h
>
> Currently we define
> org.apache.hadoop.hive.metastore.annotation.MetastoreVersionAnnotation in 2
> places:
> -
> ./standalone-metastore/metastore-common/src/gen/version/org/apache/hadoop/hive/metastore/annotation/package-info.java
> -
> ./standalone-metastore/metastore-server/src/gen/version/org/apache/hadoop/hive/metastore/annotation/package-info.java
> This causes javadoc generation to fail with:
> {code}
> [ERROR] Failed to execute goal
> org.apache.maven.plugins:maven-javadoc-plugin:3.0.1:aggregate (default-cli)
> on project hive: An error has occurred in Javadoc report generation:
> [ERROR] Exit code: 1 -
> /Users/pvary/dev/upstream/hive/standalone-metastore/metastore-server/src/gen/version/org/apache/hadoop/hive/metastore/annotation/package-info.java:8:
> warning: a package-info.java file has already been seen for package
> org.apache.hadoop.hive.metastore.annotation
> [ERROR] package org.apache.hadoop.hive.metastore.annotation;
> [ERROR] ^
> [ERROR] javadoc: warning - Multiple sources of package comments found for
> package "org.apache.hive.streaming"
> [ERROR]
> /Users/pvary/dev/upstream/hive/ql/src/java/org/apache/hadoop/hive/ql/exec/SerializationUtilities.java:556:
> error: type MapSerializer does not take parameters
> [ERROR] com.esotericsoftware.kryo.serializers.MapSerializer {
> [ERROR] ^
> [ERROR]
> /Users/pvary/dev/upstream/hive/standalone-metastore/metastore-server/src/gen/version/org/apache/hadoop/hive/metastore/annotation/package-info.java:4:
> error: package org.apache.hadoop.hive.metastore.annotation has already been
> annotated
> [ERROR] @MetastoreVersionAnnotation(version="4.0.0-alpha-1",
> shortVersion="4.0.0-alpha-1",
> [ERROR] ^
> [ERROR] java.lang.AssertionError
> [ERROR] at com.sun.tools.javac.util.Assert.error(Assert.java:126)
> [ERROR] at com.sun.tools.javac.util.Assert.check(Assert.java:45)
> [ERROR] at
> com.sun.tools.javac.code.SymbolMetadata.setDeclarationAttributesWithCompletion(SymbolMetadata.java:177)
> [ERROR] at
> com.sun.tools.javac.code.Symbol.setDeclarationAttributesWithCompletion(Symbol.java:215)
> [ERROR] at
> com.sun.tools.javac.comp.MemberEnter.actualEnterAnnotations(MemberEnter.java:952)
> [ERROR] at
> com.sun.tools.javac.comp.MemberEnter.access$600(MemberEnter.java:64)
> [ERROR] at
> com.sun.tools.javac.comp.MemberEnter$5.run(MemberEnter.java:876)
> [ERROR] at com.sun.tools.javac.comp.Annotate.flush(Annotate.java:143)
> [ERROR] at
> com.sun.tools.javac.comp.Annotate.enterDone(Annotate.java:129)
> [ERROR] at com.sun.tools.javac.comp.Enter.complete(Enter.java:512)
> [ERROR] at com.sun.tools.javac.comp.Enter.main(Enter.java:471)
> [ERROR] at com.sun.tools.javadoc.JavadocEnter.main(JavadocEnter.java:78)
> [ERROR] at
> com.sun.tools.javadoc.JavadocTool.getRootDocImpl(JavadocTool.java:186)
> [ERROR] at com.sun.tools.javadoc.Start.parseAndExecute(Start.java:346)
> [ERROR] at com.sun.tools.javadoc.Start.begin(Start.java:219)
> [ERROR] at com.sun.tools.javadoc.Start.begin(Start.java:205)
> [ERROR] at com.sun.tools.javadoc.Main.execute(Main.java:64)
> [ERROR] at com.sun.tools.javadoc.Main.main(Main.java:54)
> [ERROR] javadoc: error - fatal error
> [ERROR]
> [ERROR] Command line was:
> /usr/local/Cellar/openjdk@8/1.8.0+302/libexec/openjdk.jdk/Contents/Home/jre/../bin/javadoc
> @options @packages
> [ERROR]
> [ERROR] Refer to the generated Javadoc files in
> '/Users/pvary/dev/upstream/hive/target/site/apidocs' dir.
> {code}
> We should fix this by removing one of the above
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Work logged] (HIVE-26102) Implement DELETE statements for Iceberg tables
[
https://issues.apache.org/jira/browse/HIVE-26102?focusedWorklogId=755191=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755191
]
ASF GitHub Bot logged work on HIVE-26102:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 11:47
Start Date: 11/Apr/22 11:47
Worklog Time Spent: 10m
Work Description: marton-bod commented on code in PR #3131:
URL: https://github.com/apache/hive/pull/3131#discussion_r847237421
##
iceberg/iceberg-handler/src/main/java/org/apache/iceberg/mr/hive/IcebergAcidUtil.java:
##
@@ -0,0 +1,139 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.mr.hive;
+
+import java.util.List;
+import java.util.Map;
+import java.util.Objects;
+import org.apache.iceberg.MetadataColumns;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.data.GenericRecord;
+import org.apache.iceberg.data.Record;
+import org.apache.iceberg.deletes.PositionDelete;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.types.Types;
+import org.apache.iceberg.util.StructProjection;
+
+public class IcebergAcidUtil {
+
+ private IcebergAcidUtil() {
+ }
+
+ private static final Types.NestedField PARTITION_STRUCT_META_COL = null; //
placeholder value in the map
+ private static final Map
DELETE_FILE_READ_META_COLS = Maps.newLinkedHashMap();
+
+ static {
+DELETE_FILE_READ_META_COLS.put(MetadataColumns.SPEC_ID, 0);
+DELETE_FILE_READ_META_COLS.put(PARTITION_STRUCT_META_COL, 1);
+DELETE_FILE_READ_META_COLS.put(MetadataColumns.FILE_PATH, 2);
+DELETE_FILE_READ_META_COLS.put(MetadataColumns.ROW_POSITION, 3);
+ }
+
+ private static final Types.NestedField PARTITION_HASH_META_COL =
Types.NestedField.required(
+ MetadataColumns.PARTITION_COLUMN_ID,
MetadataColumns.PARTITION_COLUMN_NAME, Types.LongType.get());
+ private static final Map DELETE_SERDE_META_COLS
= Maps.newLinkedHashMap();
+
+ static {
+DELETE_SERDE_META_COLS.put(MetadataColumns.SPEC_ID, 0);
+DELETE_SERDE_META_COLS.put(PARTITION_HASH_META_COL, 1);
+DELETE_SERDE_META_COLS.put(MetadataColumns.FILE_PATH, 2);
+DELETE_SERDE_META_COLS.put(MetadataColumns.ROW_POSITION, 3);
+ }
+
+ /**
+ * @param dataCols The columns of the original file read schema
+ * @param table The table object - it is used for populating the partition
struct meta column
+ * @return The schema for reading files, extended with metadata columns
needed for deletes
+ */
+ public static Schema createFileReadSchemaForDelete(List
dataCols, Table table) {
+List cols =
Lists.newArrayListWithCapacity(dataCols.size() +
DELETE_FILE_READ_META_COLS.size());
+DELETE_FILE_READ_META_COLS.forEach((metaCol, index) -> {
+ if (metaCol == PARTITION_STRUCT_META_COL) {
+cols.add(MetadataColumns.metadataColumn(table,
MetadataColumns.PARTITION_COLUMN_NAME));
+ } else {
+cols.add(metaCol);
+ }
+});
+cols.addAll(dataCols);
+return new Schema(cols);
+ }
+
+ /**
+ * @param dataCols The columns of the serde projection schema
+ * @return The schema for SerDe operations, extended with metadata columns
needed for deletes
+ */
+ public static Schema createSerdeSchemaForDelete(List
dataCols) {
+List cols =
Lists.newArrayListWithCapacity(dataCols.size() + DELETE_SERDE_META_COLS.size());
+DELETE_SERDE_META_COLS.forEach((metaCol, index) -> cols.add(metaCol));
+cols.addAll(dataCols);
+return new Schema(cols);
+ }
+
+ /**
+ * @param rec The record read by the file scan task, which contains both the
metadata fields and the row data fields
+ * @param rowData The record object to populate with the rowData fields only
+ * @return The position delete object
+ */
+ public static PositionDelete getPositionDelete(Record rec,
GenericRecord rowData) {
+PositionDelete positionDelete = PositionDelete.create();
+String filePath =
rec.get(DELETE_SERDE_META_COLS.get(MetadataColumns.FILE_PATH), String.class);
+
[jira] [Updated] (HIVE-26130) Incorrect matching of external table when validating NOT NULL constraints
[
https://issues.apache.org/jira/browse/HIVE-26130?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
zhangbutao updated HIVE-26130:
--
Fix Version/s: 4.0.0-alpha-2
Affects Version/s: 4.0.0-alpha-1
4.0.0-alpha-2
> Incorrect matching of external table when validating NOT NULL constraints
> -
>
> Key: HIVE-26130
> URL: https://issues.apache.org/jira/browse/HIVE-26130
> Project: Hive
> Issue Type: Bug
>Affects Versions: 4.0.0-alpha-1, 4.0.0-alpha-2
>Reporter: zhangbutao
>Assignee: zhangbutao
>Priority: Major
> Labels: pull-request-available
> Fix For: 4.0.0-alpha-2
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> _AbstractAlterTablePropertiesAnalyzer.validate_ uses incorrect external table
> judgment statement:
> {code:java}
> else if (entry.getKey().equals("external") && entry.getValue().equals("true")
> {code}
> In current hive code, we use hive tblproperties('EXTERNAL'='true' or
> 'EXTERNAL'='TRUE) to validate external table.
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Work started] (HIVE-26130) Incorrect matching of external table when validating NOT NULL constraints
[
https://issues.apache.org/jira/browse/HIVE-26130?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Work on HIVE-26130 started by zhangbutao.
-
> Incorrect matching of external table when validating NOT NULL constraints
> -
>
> Key: HIVE-26130
> URL: https://issues.apache.org/jira/browse/HIVE-26130
> Project: Hive
> Issue Type: Bug
>Reporter: zhangbutao
>Assignee: zhangbutao
>Priority: Major
> Labels: pull-request-available
> Time Spent: 10m
> Remaining Estimate: 0h
>
> _AbstractAlterTablePropertiesAnalyzer.validate_ uses incorrect external table
> judgment statement:
> {code:java}
> else if (entry.getKey().equals("external") && entry.getValue().equals("true")
> {code}
> In current hive code, we use hive tblproperties('EXTERNAL'='true' or
> 'EXTERNAL'='TRUE) to validate external table.
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Resolved] (HIVE-25492) Major query-based compaction is skipped if partition is empty
[ https://issues.apache.org/jira/browse/HIVE-25492?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Antal Sinkovits resolved HIVE-25492. Fix Version/s: 4.0.0 Resolution: Fixed Pushed to master. Thanks for the review [~dkuzmenko] > Major query-based compaction is skipped if partition is empty > - > > Key: HIVE-25492 > URL: https://issues.apache.org/jira/browse/HIVE-25492 > Project: Hive > Issue Type: Bug >Affects Versions: 4.0.0-alpha-1, 4.0.0-alpha-2 >Reporter: Karen Coppage >Assignee: Antal Sinkovits >Priority: Major > Labels: pull-request-available > Fix For: 4.0.0 > > Time Spent: 2h 20m > Remaining Estimate: 0h > > Currently if the result of query-based compaction is an empty base, delta, or > delete delta, the empty directory is deleted. > This is because of minor compaction – if there are only deltas to compact, > then no compacted delete delta should be created (only a compacted delta). In > the same way, if there are only delete deltas to compact, then no compacted > delta should be created (only a compacted delete delta). > There is an issue with major compaction. If all the data in the partition has > been deleted, then we should get an empty base directory after compaction. > Instead, the empty base directory is deleted because it's empty and > compaction claims to succeed but we end up with the same deltas/delete deltas > we started with – basically compaction does not run. > Where to start? MajorQueryCompactor#commitCompaction -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (HIVE-25492) Major query-based compaction is skipped if partition is empty
[ https://issues.apache.org/jira/browse/HIVE-25492?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Antal Sinkovits updated HIVE-25492: --- Affects Version/s: 4.0.0-alpha-1 4.0.0-alpha-2 > Major query-based compaction is skipped if partition is empty > - > > Key: HIVE-25492 > URL: https://issues.apache.org/jira/browse/HIVE-25492 > Project: Hive > Issue Type: Bug >Affects Versions: 4.0.0-alpha-1, 4.0.0-alpha-2 >Reporter: Karen Coppage >Assignee: Antal Sinkovits >Priority: Major > Labels: pull-request-available > Time Spent: 2h 20m > Remaining Estimate: 0h > > Currently if the result of query-based compaction is an empty base, delta, or > delete delta, the empty directory is deleted. > This is because of minor compaction – if there are only deltas to compact, > then no compacted delete delta should be created (only a compacted delta). In > the same way, if there are only delete deltas to compact, then no compacted > delta should be created (only a compacted delete delta). > There is an issue with major compaction. If all the data in the partition has > been deleted, then we should get an empty base directory after compaction. > Instead, the empty base directory is deleted because it's empty and > compaction claims to succeed but we end up with the same deltas/delete deltas > we started with – basically compaction does not run. > Where to start? MajorQueryCompactor#commitCompaction -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Work logged] (HIVE-25492) Major query-based compaction is skipped if partition is empty
[ https://issues.apache.org/jira/browse/HIVE-25492?focusedWorklogId=755170=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755170 ] ASF GitHub Bot logged work on HIVE-25492: - Author: ASF GitHub Bot Created on: 11/Apr/22 10:12 Start Date: 11/Apr/22 10:12 Worklog Time Spent: 10m Work Description: asinkovits merged PR #3157: URL: https://github.com/apache/hive/pull/3157 Issue Time Tracking --- Worklog Id: (was: 755170) Time Spent: 2h 20m (was: 2h 10m) > Major query-based compaction is skipped if partition is empty > - > > Key: HIVE-25492 > URL: https://issues.apache.org/jira/browse/HIVE-25492 > Project: Hive > Issue Type: Bug >Reporter: Karen Coppage >Assignee: Antal Sinkovits >Priority: Major > Labels: pull-request-available > Time Spent: 2h 20m > Remaining Estimate: 0h > > Currently if the result of query-based compaction is an empty base, delta, or > delete delta, the empty directory is deleted. > This is because of minor compaction – if there are only deltas to compact, > then no compacted delete delta should be created (only a compacted delta). In > the same way, if there are only delete deltas to compact, then no compacted > delta should be created (only a compacted delete delta). > There is an issue with major compaction. If all the data in the partition has > been deleted, then we should get an empty base directory after compaction. > Instead, the empty base directory is deleted because it's empty and > compaction claims to succeed but we end up with the same deltas/delete deltas > we started with – basically compaction does not run. > Where to start? MajorQueryCompactor#commitCompaction -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Work logged] (HIVE-26123) Introduce test coverage for sysdb for the different metastores
[ https://issues.apache.org/jira/browse/HIVE-26123?focusedWorklogId=755169=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755169 ] ASF GitHub Bot logged work on HIVE-26123: - Author: ASF GitHub Bot Created on: 11/Apr/22 10:09 Start Date: 11/Apr/22 10:09 Worklog Time Spent: 10m Work Description: asolimando commented on PR #3196: URL: https://github.com/apache/hive/pull/3196#issuecomment-1094860222 > I really don't like to grow the number of core cli test drivers; why do we need separate for oracle/etc? > > can't we use a qoption instead of a whole set of new drivers? > > I wonder if we really need to have mile long q.out results for these kind of things. I think these kind of things should be run as part of some automated smoke tests for the release - with a real installation undernteath The existing test infra could be improved in many ways, regarding the metastore bit, there is already a ticket: https://issues.apache.org/jira/browse/HIVE-26005. We have discussed offline with @zabetak and we thought it would be better to move forward with what we have, and to tackle the improvement in the other ticket, since at the moment we already have broken support for mysql for sysdb: https://issues.apache.org/jira/browse/HIVE-26125. If you think HIVE-26005 is a must-do, please update the link between the tickets accordingly and I will pause this until me or somebody else finds the time to tackle it, otherwise if you agree that is better to have more coverage now and improve tests later, I am open to suggestions on how to improve the current proposal. I have explored the qoption way you suggest (adding a metastore option to sysdb qoption), I can start the sought docker containers, but changing the configuration properties to use another metastore failed, the new cli driver was the only way I could make these tests working. Issue Time Tracking --- Worklog Id: (was: 755169) Time Spent: 1h (was: 50m) > Introduce test coverage for sysdb for the different metastores > -- > > Key: HIVE-26123 > URL: https://issues.apache.org/jira/browse/HIVE-26123 > Project: Hive > Issue Type: Test > Components: Testing Infrastructure >Affects Versions: 4.0.0-alpha-2 >Reporter: Alessandro Solimando >Assignee: Alessandro Solimando >Priority: Major > Labels: pull-request-available > Fix For: 4.0.0-alpha-2 > > Time Spent: 1h > Remaining Estimate: 0h > > _sydb_ exposes (some of) the metastore tables from Hive via JDBC queries. > Existing tests are running only against Derby, meaning that any change > against sysdb query mapping is not covered by CI. > The present ticket aims at bridging this gap by introducing test coverage for > the different supported metastore for sydb. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (HIVE-26130) Incorrect matching of external table when validating NOT NULL constraints
[
https://issues.apache.org/jira/browse/HIVE-26130?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
zhangbutao updated HIVE-26130:
--
Description:
_AbstractAlterTablePropertiesAnalyzer.validate_ uses incorrect external table
judgment statement:
{code:java}
else if (entry.getKey().equals("external") && entry.getValue().equals("true")
{code}
In current hive code, we use hive tblproperties('EXTERNAL'='true' or
'EXTERNAL'='TRUE) to validate external table.
was:
_AbstractAlterTablePropertiesAnalyzer.validate_ uses incorrect external table
judgment statement:
{code:java}
else if (entry.getKey().equals("external") && entry.getValue().equals("true")
{code}
In current hive code, we use hive tblproperties('EXTERNAL'='true' or
'EXTERNAL'='TRUE) to validate external table.
> Incorrect matching of external table when validating NOT NULL constraints
> -
>
> Key: HIVE-26130
> URL: https://issues.apache.org/jira/browse/HIVE-26130
> Project: Hive
> Issue Type: Bug
>Reporter: zhangbutao
>Assignee: zhangbutao
>Priority: Major
> Labels: pull-request-available
> Time Spent: 10m
> Remaining Estimate: 0h
>
> _AbstractAlterTablePropertiesAnalyzer.validate_ uses incorrect external table
> judgment statement:
> {code:java}
> else if (entry.getKey().equals("external") && entry.getValue().equals("true")
> {code}
> In current hive code, we use hive tblproperties('EXTERNAL'='true' or
> 'EXTERNAL'='TRUE) to validate external table.
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Work logged] (HIVE-26130) Incorrect matching of external table when validating NOT NULL constraints
[
https://issues.apache.org/jira/browse/HIVE-26130?focusedWorklogId=755162=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755162
]
ASF GitHub Bot logged work on HIVE-26130:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 09:56
Start Date: 11/Apr/22 09:56
Worklog Time Spent: 10m
Work Description: zhangbutao opened a new pull request, #3199:
URL: https://github.com/apache/hive/pull/3199
### What changes were proposed in this pull request?
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Issue Time Tracking
---
Worklog Id: (was: 755162)
Remaining Estimate: 0h
Time Spent: 10m
> Incorrect matching of external table when validating NOT NULL constraints
> -
>
> Key: HIVE-26130
> URL: https://issues.apache.org/jira/browse/HIVE-26130
> Project: Hive
> Issue Type: Bug
>Reporter: zhangbutao
>Assignee: zhangbutao
>Priority: Major
> Time Spent: 10m
> Remaining Estimate: 0h
>
> _AbstractAlterTablePropertiesAnalyzer.validate_ uses incorrect external table
> judgment statement:
>
> {code:java}
> else if (entry.getKey().equals("external") && entry.getValue().equals("true")
> {code}
> In current hive code, we use hive tblproperties('EXTERNAL'='true' or
> 'EXTERNAL'='TRUE) to validate external table.
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (HIVE-26130) Incorrect matching of external table when validating NOT NULL constraints
[
https://issues.apache.org/jira/browse/HIVE-26130?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated HIVE-26130:
--
Labels: pull-request-available (was: )
> Incorrect matching of external table when validating NOT NULL constraints
> -
>
> Key: HIVE-26130
> URL: https://issues.apache.org/jira/browse/HIVE-26130
> Project: Hive
> Issue Type: Bug
>Reporter: zhangbutao
>Assignee: zhangbutao
>Priority: Major
> Labels: pull-request-available
> Time Spent: 10m
> Remaining Estimate: 0h
>
> _AbstractAlterTablePropertiesAnalyzer.validate_ uses incorrect external table
> judgment statement:
>
> {code:java}
> else if (entry.getKey().equals("external") && entry.getValue().equals("true")
> {code}
> In current hive code, we use hive tblproperties('EXTERNAL'='true' or
> 'EXTERNAL'='TRUE) to validate external table.
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (HIVE-26130) Incorrect matching of external table when validating NOT NULL constraints
[
https://issues.apache.org/jira/browse/HIVE-26130?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
zhangbutao updated HIVE-26130:
--
Description:
_AbstractAlterTablePropertiesAnalyzer.validate_ uses incorrect external table
judgment statement:
{code:java}
else if (entry.getKey().equals("external") && entry.getValue().equals("true")
{code}
In current hive code, we use hive tblproperties('EXTERNAL'='true' or
'EXTERNAL'='TRUE) to validate external table.
> Incorrect matching of external table when validating NOT NULL constraints
> -
>
> Key: HIVE-26130
> URL: https://issues.apache.org/jira/browse/HIVE-26130
> Project: Hive
> Issue Type: Bug
>Reporter: zhangbutao
>Assignee: zhangbutao
>Priority: Major
>
> _AbstractAlterTablePropertiesAnalyzer.validate_ uses incorrect external table
> judgment statement:
>
> {code:java}
> else if (entry.getKey().equals("external") && entry.getValue().equals("true")
> {code}
> In current hive code, we use hive tblproperties('EXTERNAL'='true' or
> 'EXTERNAL'='TRUE) to validate external table.
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Work logged] (HIVE-25941) Long compilation time of complex query due to analysis for materialized view rewrite
[
https://issues.apache.org/jira/browse/HIVE-25941?focusedWorklogId=755148=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755148
]
ASF GitHub Bot logged work on HIVE-25941:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 09:48
Start Date: 11/Apr/22 09:48
Worklog Time Spent: 10m
Work Description: kgyrtkirk commented on code in PR #3014:
URL: https://github.com/apache/hive/pull/3014#discussion_r847121787
##
ql/src/java/org/apache/hadoop/hive/ql/metadata/MaterializedViewsCache.java:
##
@@ -205,4 +212,52 @@ HiveRelOptMaterialization get(String dbName, String
viewName) {
public boolean isEmpty() {
return materializedViews.isEmpty();
}
+
+
+ private static class ASTKey {
+private final ASTNode root;
+
+public ASTKey(ASTNode root) {
+ this.root = root;
+}
+
+@Override
+public boolean equals(Object o) {
+ if (this == o) return true;
+ if (o == null || getClass() != o.getClass()) return false;
+ ASTKey that = (ASTKey) o;
+ return equals(root, that.root);
+}
+
+private boolean equals(ASTNode astNode1, ASTNode astNode2) {
+ if (!(astNode1.getType() == astNode2.getType() &&
+ astNode1.getText().equals(astNode2.getText()) &&
+ astNode1.getChildCount() == astNode2.getChildCount())) {
+return false;
+ }
+
+ for (int i = 0; i < astNode1.getChildCount(); ++i) {
+if (!equals((ASTNode) astNode1.getChild(i), (ASTNode)
astNode2.getChild(i))) {
+ return false;
+}
+ }
+
+ return true;
+}
+
+@Override
+public int hashCode() {
+ return hashcode(root);
Review Comment:
you could probably cache the hashcode - so that its not neccessary to
compute it multiple times
##
ql/src/java/org/apache/hadoop/hive/ql/optimizer/calcite/HiveMaterializedViewASTSubQueryRewriteShuttle.java:
##
@@ -0,0 +1,189 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.hadoop.hive.ql.optimizer.calcite;
+
+import org.apache.calcite.plan.RelOptCluster;
+import org.apache.calcite.rel.RelNode;
+import org.apache.calcite.rex.RexNode;
+import org.apache.calcite.tools.RelBuilder;
+import org.apache.hadoop.hive.common.TableName;
+import org.apache.hadoop.hive.ql.lockmgr.HiveTxnManager;
+import org.apache.hadoop.hive.ql.metadata.Hive;
+import org.apache.hadoop.hive.ql.metadata.HiveException;
+import org.apache.hadoop.hive.ql.metadata.HiveRelOptMaterialization;
+import org.apache.hadoop.hive.ql.metadata.Table;
+import org.apache.hadoop.hive.ql.optimizer.calcite.reloperators.HiveFilter;
+import org.apache.hadoop.hive.ql.optimizer.calcite.reloperators.HiveProject;
+import
org.apache.hadoop.hive.ql.optimizer.calcite.rules.views.HiveMaterializedViewUtils;
+import org.apache.hadoop.hive.ql.parse.ASTNode;
+import org.apache.hadoop.hive.ql.parse.CalcitePlanner;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.util.EnumSet;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.Stack;
+import java.util.function.Predicate;
+
+import static java.util.Collections.singletonList;
+import static java.util.Collections.unmodifiableMap;
+import static java.util.Collections.unmodifiableSet;
+import static
org.apache.hadoop.hive.ql.metadata.HiveRelOptMaterialization.RewriteAlgorithm.NON_CALCITE;
+import static
org.apache.hadoop.hive.ql.optimizer.calcite.rules.views.HiveMaterializedViewUtils.extractTable;
+
+/**
+ * Traverse the plan and tries to rewrite subtrees of the plan to materialized
view scans.
+ *
+ * The rewrite depends on whether the subtree's corresponding AST match with
any materialized view
+ * definitions AST.
+ */
+public class HiveMaterializedViewASTSubQueryRewriteShuttle extends
HiveRelShuttleImpl {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(HiveMaterializedViewASTSubQueryRewriteShuttle.class);
+
+ private final Map subQueryMap;
+ private final ASTNode originalAST;
+ private final ASTNode expandedAST;
+ private final RelBuilder relBuilder;
+
[jira] [Assigned] (HIVE-26130) Incorrect matching of external table when validating NOT NULL constraints
[ https://issues.apache.org/jira/browse/HIVE-26130?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] zhangbutao reassigned HIVE-26130: - > Incorrect matching of external table when validating NOT NULL constraints > - > > Key: HIVE-26130 > URL: https://issues.apache.org/jira/browse/HIVE-26130 > Project: Hive > Issue Type: Bug >Reporter: zhangbutao >Assignee: zhangbutao >Priority: Major > -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Work logged] (HIVE-26092) Fix javadoc errors for the 4.0.0 release
[
https://issues.apache.org/jira/browse/HIVE-26092?focusedWorklogId=755140=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755140
]
ASF GitHub Bot logged work on HIVE-26092:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 09:13
Start Date: 11/Apr/22 09:13
Worklog Time Spent: 10m
Work Description: kgyrtkirk commented on code in PR #3185:
URL: https://github.com/apache/hive/pull/3185#discussion_r847111093
##
Jenkinsfile:
##
@@ -350,6 +350,18 @@ tar -xzf
packaging/target/apache-hive-*-nightly-*-src.tar.gz
}
}
}
+ branches['javadoc-check'] = {
+executorNode {
+ stage('Prepare') {
+ loadWS();
+ }
+ stage('Generate javadoc') {
+ sh """#!/bin/bash -e
+mvn clean install javadoc:javadoc javadoc:aggregate -DskipTests
Review Comment:
this is not good; please look how other parts of this file are using maven.
Issue Time Tracking
---
Worklog Id: (was: 755140)
Time Spent: 20m (was: 10m)
> Fix javadoc errors for the 4.0.0 release
>
>
> Key: HIVE-26092
> URL: https://issues.apache.org/jira/browse/HIVE-26092
> Project: Hive
> Issue Type: Task
>Reporter: Peter Vary
>Assignee: Peter Vary
>Priority: Major
> Labels: pull-request-available
> Time Spent: 20m
> Remaining Estimate: 0h
>
> Currently there are plenty of errors in the javadoc.
> We should fix those before a final release
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Work logged] (HIVE-26123) Introduce test coverage for sysdb for the different metastores
[
https://issues.apache.org/jira/browse/HIVE-26123?focusedWorklogId=755139=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755139
]
ASF GitHub Bot logged work on HIVE-26123:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 09:10
Start Date: 11/Apr/22 09:10
Worklog Time Spent: 10m
Work Description: kgyrtkirk commented on code in PR #3196:
URL: https://github.com/apache/hive/pull/3196#discussion_r847106908
##
itests/qtest/src/test/java/org/apache/hadoop/hive/cli/TestPostgresMetastoreCliDriver.java:
##
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.hadoop.hive.cli;
+
+import org.apache.hadoop.hive.cli.control.CliAdapter;
+import org.apache.hadoop.hive.cli.control.CliConfigs;
+import org.apache.hadoop.hive.cli.control.SplitSupport;
+import org.junit.ClassRule;
+import org.junit.Rule;
+import org.junit.Test;
+import org.junit.rules.TestRule;
+import org.junit.runner.RunWith;
+import org.junit.runners.Parameterized;
+import org.junit.runners.Parameterized.Parameters;
+import org.junit.runners.model.Statement;
+
+import java.io.File;
+import java.util.List;
+
+@RunWith(Parameterized.class)
+public class TestPostgresMetastoreCliDriver {
+
+ static CliAdapter adapter = new
CliConfigs.PostgresMetastoreCliConfig().getCliAdapter();
+
+ private static final int N_SPLITS = 32;
Review Comment:
seems like copy-paste ? do you know what you are doing?
##
itests/util/src/main/java/org/apache/hadoop/hive/cli/control/CliConfigs.java:
##
@@ -240,6 +240,101 @@ public MiniLlapLocalCliConfig() {
}
}
+ public static class PostgresMetastoreCliConfig extends AbstractCliConfig {
+public PostgresMetastoreCliConfig() {
+ super(CoreCliDriver.class);
+ try {
+setQueryDir("ql/src/test/queries/clientpositive");
+includesFrom(testConfigProps, "ms.postgres.query.files");
+setResultsDir("ql/src/test/results/clientpositive/mspostgres");
+setLogDir("itests/qtest/target/qfile-results/mspostgres");
+setInitScript("q_test_init.sql");
+setCleanupScript("q_test_cleanup.sql");
+setHiveConfDir("data/conf/llap");
+setClusterType(MiniClusterType.LLAP);
+setMetastoreType("postgres");
+ } catch (Exception e) {
+throw new RuntimeException("can't construct cliconfig", e);
+ }
+}
+ }
+
+ public static class MssqlMetastoreCliConfig extends AbstractCliConfig {
+public MssqlMetastoreCliConfig() {
+ super(CoreCliDriver.class);
+ try {
+setQueryDir("ql/src/test/queries/clientpositive");
+includesFrom(testConfigProps, "ms.mssql.query.files");
+setResultsDir("ql/src/test/results/clientpositive/msmssql");
+setLogDir("itests/qtest/target/qfile-results/msmssql");
+setInitScript("q_test_init.sql");
+setCleanupScript("q_test_cleanup.sql");
+setHiveConfDir("data/conf/llap");
+setClusterType(MiniClusterType.LLAP);
+setMetastoreType("mssql");
+ } catch (Exception e) {
+throw new RuntimeException("can't construct cliconfig", e);
+ }
+}
+ }
+
+ public static class OracleMetastoreCliConfig extends AbstractCliConfig {
+public OracleMetastoreCliConfig() {
+ super(CoreCliDriver.class);
+ try {
+setQueryDir("ql/src/test/queries/clientpositive");
+includesFrom(testConfigProps, "ms.oracle.query.files");
+setResultsDir("ql/src/test/results/clientpositive/msoracle");
+setLogDir("itests/qtest/target/qfile-results/msoracle");
+setInitScript("q_test_init.sql");
+setCleanupScript("q_test_cleanup.sql");
+setHiveConfDir("data/conf/llap");
+setClusterType(MiniClusterType.LLAP);
+setMetastoreType("oracle");
+ } catch (Exception e) {
+throw new RuntimeException("can't construct cliconfig", e);
+ }
+}
+ }
+
+ public static class MysqlMetastoreCliConfig extends AbstractCliConfig {
+public MysqlMetastoreCliConfig() {
+ super(CoreCliDriver.class);
+ try {
+
[jira] [Work logged] (HIVE-26123) Introduce test coverage for sysdb for the different metastores
[ https://issues.apache.org/jira/browse/HIVE-26123?focusedWorklogId=755138=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755138 ] ASF GitHub Bot logged work on HIVE-26123: - Author: ASF GitHub Bot Created on: 11/Apr/22 09:09 Start Date: 11/Apr/22 09:09 Worklog Time Spent: 10m Work Description: kgyrtkirk commented on PR #3196: URL: https://github.com/apache/hive/pull/3196#issuecomment-1094773625 I really don't like to grow the number of core cli test drivers; why do we need separate for oracle/etc? can't we use a qoption instead of a whole set of new drivers? I wonder if we really need to have mile long q.out results for these kind of things. I think these kind of things should be run as part of some automated smoke tests for the release - with a real installation undernteath Issue Time Tracking --- Worklog Id: (was: 755138) Time Spent: 40m (was: 0.5h) > Introduce test coverage for sysdb for the different metastores > -- > > Key: HIVE-26123 > URL: https://issues.apache.org/jira/browse/HIVE-26123 > Project: Hive > Issue Type: Test > Components: Testing Infrastructure >Affects Versions: 4.0.0-alpha-2 >Reporter: Alessandro Solimando >Assignee: Alessandro Solimando >Priority: Major > Labels: pull-request-available > Fix For: 4.0.0-alpha-2 > > Time Spent: 40m > Remaining Estimate: 0h > > _sydb_ exposes (some of) the metastore tables from Hive via JDBC queries. > Existing tests are running only against Derby, meaning that any change > against sysdb query mapping is not covered by CI. > The present ticket aims at bridging this gap by introducing test coverage for > the different supported metastore for sydb. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Work logged] (HIVE-26121) Hive transaction rollback should be thread-safe
[
https://issues.apache.org/jira/browse/HIVE-26121?focusedWorklogId=755133=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755133
]
ASF GitHub Bot logged work on HIVE-26121:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 08:34
Start Date: 11/Apr/22 08:34
Worklog Time Spent: 10m
Work Description: deniskuzZ commented on PR #3181:
URL: https://github.com/apache/hive/pull/3181#issuecomment-1094709982
> endTransactionAndCleanup
yes, we definitely need to synchronize
`DriverTxnHandler.endTransactionAndCleanup`. As for
`DbTxnManager.java.stopHeartbeat` it was already kinda synchronized and it's
possible that concurrent execution might still occur when shutdownhook is
invoked.
Issue Time Tracking
---
Worklog Id: (was: 755133)
Time Spent: 50m (was: 40m)
> Hive transaction rollback should be thread-safe
> ---
>
> Key: HIVE-26121
> URL: https://issues.apache.org/jira/browse/HIVE-26121
> Project: Hive
> Issue Type: Task
>Reporter: Denys Kuzmenko
>Priority: Major
> Labels: pull-request-available
> Time Spent: 50m
> Remaining Estimate: 0h
>
> When Hive query is being interrupted via cancel request, both the background
> pool thread (HiveServer2-Background) executing the query and the HttpHandler
> thread (HiveServer2-Handler) running the HiveSession.cancelOperation logic
> will eventually trigger the below method:
> {code}
> DriverTxnHandler.endTransactionAndCleanup(boolean commit)
> {code}
> Since this method could be invoked concurrently we need to synchronize access
> to it, so that only 1 thread would attempt to abort the transaction and stop
> the heartbeat.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Work logged] (HIVE-26123) Introduce test coverage for sysdb for the different metastores
[
https://issues.apache.org/jira/browse/HIVE-26123?focusedWorklogId=755127=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755127
]
ASF GitHub Bot logged work on HIVE-26123:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 08:00
Start Date: 11/Apr/22 08:00
Worklog Time Spent: 10m
Work Description: pvary commented on code in PR #3196:
URL: https://github.com/apache/hive/pull/3196#discussion_r847047102
##
itests/util/src/main/java/org/apache/hadoop/hive/cli/control/CliConfigs.java:
##
@@ -240,6 +240,101 @@ public MiniLlapLocalCliConfig() {
}
}
+ public static class PostgresMetastoreCliConfig extends AbstractCliConfig {
+public PostgresMetastoreCliConfig() {
+ super(CoreCliDriver.class);
+ try {
+setQueryDir("ql/src/test/queries/clientpositive");
+includesFrom(testConfigProps, "ms.postgres.query.files");
+setResultsDir("ql/src/test/results/clientpositive/mspostgres");
+setLogDir("itests/qtest/target/qfile-results/mspostgres");
+setInitScript("q_test_init.sql");
+setCleanupScript("q_test_cleanup.sql");
+setHiveConfDir("data/conf/llap");
+setClusterType(MiniClusterType.LLAP);
Review Comment:
Which is the least costly (wrt resources) cluster type?
Do we need to initialize LLAP for this?
Issue Time Tracking
---
Worklog Id: (was: 755127)
Time Spent: 0.5h (was: 20m)
> Introduce test coverage for sysdb for the different metastores
> --
>
> Key: HIVE-26123
> URL: https://issues.apache.org/jira/browse/HIVE-26123
> Project: Hive
> Issue Type: Test
> Components: Testing Infrastructure
>Affects Versions: 4.0.0-alpha-2
>Reporter: Alessandro Solimando
>Assignee: Alessandro Solimando
>Priority: Major
> Labels: pull-request-available
> Fix For: 4.0.0-alpha-2
>
> Time Spent: 0.5h
> Remaining Estimate: 0h
>
> _sydb_ exposes (some of) the metastore tables from Hive via JDBC queries.
> Existing tests are running only against Derby, meaning that any change
> against sysdb query mapping is not covered by CI.
> The present ticket aims at bridging this gap by introducing test coverage for
> the different supported metastore for sydb.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Work logged] (HIVE-25980) Reduce fs calls in HiveMetaStoreChecker.checkTable
[
https://issues.apache.org/jira/browse/HIVE-25980?focusedWorklogId=755120=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-755120
]
ASF GitHub Bot logged work on HIVE-25980:
-
Author: ASF GitHub Bot
Created on: 11/Apr/22 07:45
Start Date: 11/Apr/22 07:45
Worklog Time Spent: 10m
Work Description: pvary commented on code in PR #3053:
URL: https://github.com/apache/hive/pull/3053#discussion_r847034829
##
standalone-metastore/metastore-server/src/main/java/org/apache/hadoop/hive/metastore/HiveMetaStoreChecker.java:
##
@@ -425,11 +425,11 @@ void findUnknownPartitions(Table table, Set
partPaths, Set partPath
Set correctPartPathsInMS = new HashSet<>(partPathsInMS);
// remove partition paths in partPathsInMS, to getPartitionsNotOnFs
partPathsInMS.removeAll(allPartDirs);
-FileSystem fs = tablePath.getFileSystem(conf);
// There can be edge case where user can define partition directory
outside of table directory
// to avoid eviction of such partitions
// we check for partition path not exists and add to result for
getPartitionsNotOnFs.
for (Path partPath : partPathsInMS) {
+ FileSystem fs = partPath.getFileSystem(conf);
Review Comment:
This could be costly to do it every time.
Are we expecting this to be different for every `partPath`?
Issue Time Tracking
---
Worklog Id: (was: 755120)
Time Spent: 5h 20m (was: 5h 10m)
> Reduce fs calls in HiveMetaStoreChecker.checkTable
> --
>
> Key: HIVE-25980
> URL: https://issues.apache.org/jira/browse/HIVE-25980
> Project: Hive
> Issue Type: Improvement
> Components: Standalone Metastore
>Affects Versions: 3.1.2, 4.0.0
>Reporter: Chiran Ravani
>Assignee: Chiran Ravani
>Priority: Major
> Labels: pull-request-available
> Time Spent: 5h 20m
> Remaining Estimate: 0h
>
> MSCK Repair table for high partition table can perform slow on Cloud Storage
> such as S3, one of the case we found where slowness was observed in
> HiveMetaStoreChecker.checkTable.
> {code:java}
> "HiveServer2-Background-Pool: Thread-382" #382 prio=5 os_prio=0
> tid=0x7f97fc4a4000 nid=0x5c2a runnable [0x7f97c41a8000]
>java.lang.Thread.State: RUNNABLE
> at java.net.SocketInputStream.socketRead0(Native Method)
> at java.net.SocketInputStream.socketRead(SocketInputStream.java:116)
> at java.net.SocketInputStream.read(SocketInputStream.java:171)
> at java.net.SocketInputStream.read(SocketInputStream.java:141)
> at
> sun.security.ssl.SSLSocketInputRecord.read(SSLSocketInputRecord.java:464)
> at
> sun.security.ssl.SSLSocketInputRecord.bytesInCompletePacket(SSLSocketInputRecord.java:68)
> at
> sun.security.ssl.SSLSocketImpl.readApplicationRecord(SSLSocketImpl.java:1341)
> at sun.security.ssl.SSLSocketImpl.access$300(SSLSocketImpl.java:73)
> at
> sun.security.ssl.SSLSocketImpl$AppInputStream.read(SSLSocketImpl.java:957)
> at
> com.amazonaws.thirdparty.apache.http.impl.io.SessionInputBufferImpl.streamRead(SessionInputBufferImpl.java:137)
> at
> com.amazonaws.thirdparty.apache.http.impl.io.SessionInputBufferImpl.fillBuffer(SessionInputBufferImpl.java:153)
> at
> com.amazonaws.thirdparty.apache.http.impl.io.SessionInputBufferImpl.readLine(SessionInputBufferImpl.java:280)
> at
> com.amazonaws.thirdparty.apache.http.impl.conn.DefaultHttpResponseParser.parseHead(DefaultHttpResponseParser.java:138)
> at
> com.amazonaws.thirdparty.apache.http.impl.conn.DefaultHttpResponseParser.parseHead(DefaultHttpResponseParser.java:56)
> at
> com.amazonaws.thirdparty.apache.http.impl.io.AbstractMessageParser.parse(AbstractMessageParser.java:259)
> at
> com.amazonaws.thirdparty.apache.http.impl.DefaultBHttpClientConnection.receiveResponseHeader(DefaultBHttpClientConnection.java:163)
> at
> com.amazonaws.thirdparty.apache.http.impl.conn.CPoolProxy.receiveResponseHeader(CPoolProxy.java:157)
> at
> com.amazonaws.thirdparty.apache.http.protocol.HttpRequestExecutor.doReceiveResponse(HttpRequestExecutor.java:273)
> at
> com.amazonaws.http.protocol.SdkHttpRequestExecutor.doReceiveResponse(SdkHttpRequestExecutor.java:82)
> at
> com.amazonaws.thirdparty.apache.http.protocol.HttpRequestExecutor.execute(HttpRequestExecutor.java:125)
> at
> com.amazonaws.thirdparty.apache.http.impl.execchain.MainClientExec.execute(MainClientExec.java:272)
> at
> com.amazonaws.thirdparty.apache.http.impl.execchain.ProtocolExec.execute(ProtocolExec.java:186)
> at
> com.amazonaws.thirdparty.apache.http.impl.client.InternalHttpClient.doExecute(InternalHttpClient.java:185)
> at
>
[jira] [Comment Edited] (HIVE-23010) IllegalStateException in tez.ReduceRecordProcessor when containers are being reused
[
https://issues.apache.org/jira/browse/HIVE-23010?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17520364#comment-17520364
]
Wei Zhang edited comment on HIVE-23010 at 4/11/22 7:40 AM:
---
This is because the mergejoin operator will be added as the dummyoperatore's
child during the first attempt run, and the mergeworklist is cached across
different attempts.
was (Author: zhangweilst):
This is because the mergejoin operator will be added as the dummyoperatore's
child, and the mergeworklist is cached across different attempts.
> IllegalStateException in tez.ReduceRecordProcessor when containers are being
> reused
> ---
>
> Key: HIVE-23010
> URL: https://issues.apache.org/jira/browse/HIVE-23010
> Project: Hive
> Issue Type: Bug
>Affects Versions: 3.1.0
>Reporter: Sebastian Klemke
>Priority: Major
> Attachments: simplified-explain.txt
>
>
> When executing a query in Hive that runs a filesink, mergejoin and two group
> by operators in a single reduce vertex (reducer 2 in
> [^simplified-explain.txt]), the following exception occurs
> non-deterministically:
> {code:java}
> java.lang.RuntimeException: java.lang.IllegalStateException: Was expecting
> dummy store operator but found: FS[17]
> at
> org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:296)
> at
> org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:250)
> at
> org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:374)
> at
> org.apache.tez.runtime.task.TaskRunner2Callable$1.run(TaskRunner2Callable.java:73)
> at
> org.apache.tez.runtime.task.TaskRunner2Callable$1.run(TaskRunner2Callable.java:61)
> at java.security.AccessController.doPrivileged(Native Method)
> at javax.security.auth.Subject.doAs(Subject.java:422)
> at
> org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730)
> at
> org.apache.tez.runtime.task.TaskRunner2Callable.callInternal(TaskRunner2Callable.java:61)
> at
> org.apache.tez.runtime.task.TaskRunner2Callable.callInternal(TaskRunner2Callable.java:37)
> at org.apache.tez.common.CallableWithNdc.call(CallableWithNdc.java:36)
> at
> com.google.common.util.concurrent.TrustedListenableFutureTask$TrustedFutureInterruptibleTask.runInterruptibly(TrustedListenableFutureTask.java:125)
> at
> com.google.common.util.concurrent.InterruptibleTask.run(InterruptibleTask.java:69)
> at
> com.google.common.util.concurrent.TrustedListenableFutureTask.run(TrustedListenableFutureTask.java:78)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:748)
> Caused by: java.lang.IllegalStateException: Was expecting dummy store
> operator but found: FS[17]
> at
> org.apache.hadoop.hive.ql.exec.tez.ReduceRecordProcessor.getJoinParentOp(ReduceRecordProcessor.java:421)
> at
> org.apache.hadoop.hive.ql.exec.tez.ReduceRecordProcessor.getJoinParentOp(ReduceRecordProcessor.java:425)
> at
> org.apache.hadoop.hive.ql.exec.tez.ReduceRecordProcessor.getJoinParentOp(ReduceRecordProcessor.java:425)
> at
> org.apache.hadoop.hive.ql.exec.tez.ReduceRecordProcessor.getJoinParentOp(ReduceRecordProcessor.java:425)
> at
> org.apache.hadoop.hive.ql.exec.tez.ReduceRecordProcessor.init(ReduceRecordProcessor.java:148)
> at
> org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:266)
> ... 16 more
> {code}
> Looking at Yarn logs, IllegalStateException occurs in a container if and only
> if
> * the container has been running a task attempt of "Reducer 2" successfully
> before
> * the container is then being reused for another task attempt of the same
> "Reducer 2" vertex
> The same query runs fine with tez.am.container.reuse.enabled=false.
> Apparently, this error occurs deterministically within a container that is
> being reused for multiple task attempts of the same reduce vertex.
> We have not been able to reproduce this error deterministically or with a
> smaller execution plan due to low probability of container reuse for same
> vertex.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Commented] (HIVE-23010) IllegalStateException in tez.ReduceRecordProcessor when containers are being reused
[
https://issues.apache.org/jira/browse/HIVE-23010?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17520364#comment-17520364
]
Wei Zhang commented on HIVE-23010:
--
This is because the mergejoin operator will be added as the dummyoperatore's
child, and the mergeworklist is cached across different attempts.
> IllegalStateException in tez.ReduceRecordProcessor when containers are being
> reused
> ---
>
> Key: HIVE-23010
> URL: https://issues.apache.org/jira/browse/HIVE-23010
> Project: Hive
> Issue Type: Bug
>Affects Versions: 3.1.0
>Reporter: Sebastian Klemke
>Priority: Major
> Attachments: simplified-explain.txt
>
>
> When executing a query in Hive that runs a filesink, mergejoin and two group
> by operators in a single reduce vertex (reducer 2 in
> [^simplified-explain.txt]), the following exception occurs
> non-deterministically:
> {code:java}
> java.lang.RuntimeException: java.lang.IllegalStateException: Was expecting
> dummy store operator but found: FS[17]
> at
> org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:296)
> at
> org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:250)
> at
> org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:374)
> at
> org.apache.tez.runtime.task.TaskRunner2Callable$1.run(TaskRunner2Callable.java:73)
> at
> org.apache.tez.runtime.task.TaskRunner2Callable$1.run(TaskRunner2Callable.java:61)
> at java.security.AccessController.doPrivileged(Native Method)
> at javax.security.auth.Subject.doAs(Subject.java:422)
> at
> org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730)
> at
> org.apache.tez.runtime.task.TaskRunner2Callable.callInternal(TaskRunner2Callable.java:61)
> at
> org.apache.tez.runtime.task.TaskRunner2Callable.callInternal(TaskRunner2Callable.java:37)
> at org.apache.tez.common.CallableWithNdc.call(CallableWithNdc.java:36)
> at
> com.google.common.util.concurrent.TrustedListenableFutureTask$TrustedFutureInterruptibleTask.runInterruptibly(TrustedListenableFutureTask.java:125)
> at
> com.google.common.util.concurrent.InterruptibleTask.run(InterruptibleTask.java:69)
> at
> com.google.common.util.concurrent.TrustedListenableFutureTask.run(TrustedListenableFutureTask.java:78)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:748)
> Caused by: java.lang.IllegalStateException: Was expecting dummy store
> operator but found: FS[17]
> at
> org.apache.hadoop.hive.ql.exec.tez.ReduceRecordProcessor.getJoinParentOp(ReduceRecordProcessor.java:421)
> at
> org.apache.hadoop.hive.ql.exec.tez.ReduceRecordProcessor.getJoinParentOp(ReduceRecordProcessor.java:425)
> at
> org.apache.hadoop.hive.ql.exec.tez.ReduceRecordProcessor.getJoinParentOp(ReduceRecordProcessor.java:425)
> at
> org.apache.hadoop.hive.ql.exec.tez.ReduceRecordProcessor.getJoinParentOp(ReduceRecordProcessor.java:425)
> at
> org.apache.hadoop.hive.ql.exec.tez.ReduceRecordProcessor.init(ReduceRecordProcessor.java:148)
> at
> org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:266)
> ... 16 more
> {code}
> Looking at Yarn logs, IllegalStateException occurs in a container if and only
> if
> * the container has been running a task attempt of "Reducer 2" successfully
> before
> * the container is then being reused for another task attempt of the same
> "Reducer 2" vertex
> The same query runs fine with tez.am.container.reuse.enabled=false.
> Apparently, this error occurs deterministically within a container that is
> being reused for multiple task attempts of the same reduce vertex.
> We have not been able to reproduce this error deterministically or with a
> smaller execution plan due to low probability of container reuse for same
> vertex.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)