[GitHub] spark pull request #22598: [SPARK-25501][SS] Add kafka delegation token supp...
Github user gaborgsomogyi commented on a diff in the pull request:
https://github.com/apache/spark/pull/22598#discussion_r223353827
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaSecurityHelper.scala
---
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.kafka010
+
+import org.apache.hadoop.security.UserGroupInformation
+import org.apache.hadoop.security.token.{Token, TokenIdentifier}
+import org.apache.kafka.common.security.scram.ScramLoginModule
+
+import org.apache.spark.SparkConf
+import org.apache.spark.internal.Logging
+import org.apache.spark.internal.config._
+
+private[kafka010] object KafkaSecurityHelper extends Logging {
+ def getKeytabJaasParams(sparkConf: SparkConf): Option[String] = {
+if (sparkConf.get(KEYTAB).nonEmpty) {
+ Some(getKrbJaasParams(sparkConf))
+} else {
+ None
+}
+ }
+
+ def getKrbJaasParams(sparkConf: SparkConf): String = {
+val serviceName = sparkConf.get(KAFKA_KERBEROS_SERVICE_NAME)
+require(serviceName.nonEmpty, "Kerberos service name must be defined")
+val keytab = sparkConf.get(KEYTAB)
+require(keytab.nonEmpty, "Keytab must be defined")
+val principal = sparkConf.get(PRINCIPAL)
+require(principal.nonEmpty, "Principal must be defined")
+
+val params =
+ s"""
+ |${getKrb5LoginModuleName} required
+ | useKeyTab=true
+ | serviceName="${serviceName.get}"
+ | keyTab="${keytab.get}"
+ | principal="${principal.get}";
+ """.stripMargin.replace("\n", "")
+logInfo(s"Krb JAAS params: $params")
--- End diff --
Fixed.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22598: [SPARK-25501][SS] Add kafka delegation token supp...
Github user gaborgsomogyi commented on a diff in the pull request:
https://github.com/apache/spark/pull/22598#discussion_r223353785
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaSecurityHelper.scala
---
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.kafka010
+
+import org.apache.hadoop.security.UserGroupInformation
+import org.apache.hadoop.security.token.{Token, TokenIdentifier}
+import org.apache.kafka.common.security.scram.ScramLoginModule
+
+import org.apache.spark.SparkConf
+import org.apache.spark.internal.Logging
+import org.apache.spark.internal.config._
+
+private[kafka010] object KafkaSecurityHelper extends Logging {
+ def getKeytabJaasParams(sparkConf: SparkConf): Option[String] = {
+if (sparkConf.get(KEYTAB).nonEmpty) {
+ Some(getKrbJaasParams(sparkConf))
+} else {
+ None
+}
+ }
+
+ def getKrbJaasParams(sparkConf: SparkConf): String = {
--- End diff --
Inlined.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22598: [SPARK-25501][SS] Add kafka delegation token supp...
Github user gaborgsomogyi commented on a diff in the pull request:
https://github.com/apache/spark/pull/22598#discussion_r223353667
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaSecurityHelper.scala
---
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.kafka010
+
+import org.apache.hadoop.security.UserGroupInformation
+import org.apache.hadoop.security.token.{Token, TokenIdentifier}
+import org.apache.kafka.common.security.scram.ScramLoginModule
+
+import org.apache.spark.SparkConf
+import org.apache.spark.internal.Logging
+import org.apache.spark.internal.config._
+
+private[kafka010] object KafkaSecurityHelper extends Logging {
+ def getKeytabJaasParams(sparkConf: SparkConf): Option[String] = {
+if (sparkConf.get(KEYTAB).nonEmpty) {
--- End diff --
Fixed.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22598: [SPARK-25501][SS] Add kafka delegation token supp...
Github user gaborgsomogyi commented on a diff in the pull request:
https://github.com/apache/spark/pull/22598#discussion_r223353289
--- Diff:
core/src/main/scala/org/apache/spark/internal/config/package.scala ---
@@ -647,4 +647,42 @@ package object config {
.stringConf
.toSequence
.createWithDefault(Nil)
+
+ private[spark] val KAFKA_DELEGATION_TOKEN_ENABLED =
+ConfigBuilder("spark.kafka.delegation.token.enabled")
+ .doc("Set to 'true' for obtaining delegation token from kafka.")
+ .booleanConf
+ .createWithDefault(false)
+
+ private[spark] val KAFKA_BOOTSTRAP_SERVERS =
+ConfigBuilder("spark.kafka.bootstrap.servers")
+ .doc("A list of coma separated host/port pairs to use for
establishing the initial " +
+"connection to the Kafka cluster. For further details please see
kafka documentation.")
+ .stringConf.createOptional
--- End diff --
Fixed (a.k.a. "followed another existing pattern").
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22598: [SPARK-25501][SS] Add kafka delegation token supp...
Github user gaborgsomogyi commented on a diff in the pull request:
https://github.com/apache/spark/pull/22598#discussion_r223353521
--- Diff:
core/src/main/scala/org/apache/spark/internal/config/package.scala ---
@@ -647,4 +647,42 @@ package object config {
.stringConf
.toSequence
.createWithDefault(Nil)
+
+ private[spark] val KAFKA_DELEGATION_TOKEN_ENABLED =
--- End diff --
Removed.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22594: [SPARK-25674][SQL] If the records are incremented...
Github user srowen commented on a diff in the pull request:
https://github.com/apache/spark/pull/22594#discussion_r223353261
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/metric/SQLMetricsSuite.scala
---
@@ -570,4 +572,33 @@ class SQLMetricsSuite extends SparkFunSuite with
SQLMetricsTestUtils with Shared
}
}
}
+
+ test("InputMetrics---bytesRead") {
--- End diff --
This isn't really testing the code you changed. It's replicating something
similar and testing that. I don't think this test helps. Ideally you would
write a test for any path that uses `FileScanRDD` and check its metrics. Are
there tests around here that you could 'piggyback' onto? maybe an existing test
of the metrics involving `ColumnarBatch ` than can be changed to trigger this
case.
It may be hard, I don't know. Worth looking to see if there's an easy way
to test this.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22598: [SPARK-25501][SS] Add kafka delegation token supp...
Github user gaborgsomogyi commented on a diff in the pull request:
https://github.com/apache/spark/pull/22598#discussion_r223352921
--- Diff:
core/src/main/scala/org/apache/spark/deploy/security/KafkaDelegationTokenProvider.scala
---
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.deploy.security
+
+import scala.reflect.runtime.universe
+import scala.util.control.NonFatal
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.security.Credentials
+import org.apache.hadoop.security.token.{Token, TokenIdentifier}
+
+import org.apache.spark.SparkConf
+import org.apache.spark.internal.Logging
+import org.apache.spark.internal.config.{KAFKA_DELEGATION_TOKEN_ENABLED,
KAFKA_SECURITY_PROTOCOL}
+import org.apache.spark.util.Utils
+
+private[security] class KafkaDelegationTokenProvider
+ extends HadoopDelegationTokenProvider with Logging {
+
+ override def serviceName: String = "kafka"
+
+ override def obtainDelegationTokens(
+ hadoopConf: Configuration,
+ sparkConf: SparkConf,
+ creds: Credentials): Option[Long] = {
+try {
+ val mirror =
universe.runtimeMirror(Utils.getContextOrSparkClassLoader)
+ val obtainToken = mirror.classLoader.
+loadClass("org.apache.spark.sql.kafka010.TokenUtil").
+getMethod("obtainToken", classOf[SparkConf])
+
+ logDebug("Attempting to fetch Kafka security token.")
+ val token = obtainToken.invoke(null, sparkConf)
+.asInstanceOf[Token[_ <: TokenIdentifier]]
+ logInfo(s"Get token from Kafka: ${token.toString}")
+ creds.addToken(token.getService, token)
+} catch {
+ case NonFatal(e) =>
+logDebug(s"Failed to get token from service $serviceName", e)
--- End diff --
Fixed.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22598: [SPARK-25501][SS] Add kafka delegation token supp...
Github user gaborgsomogyi commented on a diff in the pull request:
https://github.com/apache/spark/pull/22598#discussion_r223352851
--- Diff:
core/src/main/scala/org/apache/spark/deploy/security/KafkaDelegationTokenProvider.scala
---
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.deploy.security
+
+import scala.reflect.runtime.universe
+import scala.util.control.NonFatal
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.security.Credentials
+import org.apache.hadoop.security.token.{Token, TokenIdentifier}
+
+import org.apache.spark.SparkConf
+import org.apache.spark.internal.Logging
+import org.apache.spark.internal.config.{KAFKA_DELEGATION_TOKEN_ENABLED,
KAFKA_SECURITY_PROTOCOL}
+import org.apache.spark.util.Utils
+
+private[security] class KafkaDelegationTokenProvider
+ extends HadoopDelegationTokenProvider with Logging {
+
+ override def serviceName: String = "kafka"
+
+ override def obtainDelegationTokens(
+ hadoopConf: Configuration,
+ sparkConf: SparkConf,
+ creds: Credentials): Option[Long] = {
+try {
+ val mirror =
universe.runtimeMirror(Utils.getContextOrSparkClassLoader)
+ val obtainToken = mirror.classLoader.
+loadClass("org.apache.spark.sql.kafka010.TokenUtil").
+getMethod("obtainToken", classOf[SparkConf])
+
+ logDebug("Attempting to fetch Kafka security token.")
+ val token = obtainToken.invoke(null, sparkConf)
+.asInstanceOf[Token[_ <: TokenIdentifier]]
+ logInfo(s"Get token from Kafka: ${token.toString}")
--- End diff --
Fixed.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22598: [SPARK-25501][SS] Add kafka delegation token supp...
Github user gaborgsomogyi commented on a diff in the pull request:
https://github.com/apache/spark/pull/22598#discussion_r223352683
--- Diff:
core/src/test/scala/org/apache/spark/deploy/security/HadoopDelegationTokenManagerSuite.scala
---
@@ -111,6 +113,17 @@ class HadoopDelegationTokenManagerSuite extends
SparkFunSuite with Matchers {
creds.getAllTokens.size should be (0)
}
+ test("Obtain tokens For Kafka") {
+val hadoopConf = new Configuration()
+sparkConf.set(KAFKA_DELEGATION_TOKEN_ENABLED, true)
+
+val kafkaTokenProvider = new KafkaDelegationTokenProvider()
+val creds = new Credentials()
+kafkaTokenProvider.obtainDelegationTokens(hadoopConf, sparkConf, creds)
+
+creds.getAllTokens.size should be (0)
--- End diff --
Increased test coverage.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22630: [SPARK-25497][SQL] Limit operation within whole stage co...
Github user mgaido91 commented on the issue: https://github.com/apache/spark/pull/22630 LGTM --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22630: [SPARK-25497][SQL] Limit operation within whole stage co...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22630 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97106/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22630: [SPARK-25497][SQL] Limit operation within whole stage co...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22630 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22630: [SPARK-25497][SQL] Limit operation within whole stage co...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22630 **[Test build #97106 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97106/testReport)** for PR 22630 at commit [`e61078b`](https://github.com/apache/spark/commit/e61078bb563c6868be02f256041a0fb5fbd7c7d7). * This patch passes all tests. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * `trait BlockingOperatorWithCodegen extends CodegenSupport ` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22482: WIP - [SPARK-10816][SS] Support session window natively
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22482 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22482: WIP - [SPARK-10816][SS] Support session window natively
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22482 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97107/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22482: WIP - [SPARK-10816][SS] Support session window natively
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22482 **[Test build #97107 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97107/testReport)** for PR 22482 at commit [`78fdd99`](https://github.com/apache/spark/commit/78fdd9923d74ff47c9cb402e2da6c1953738ddc8). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22615: [SPARK-25016][BUILD][CORE] Remove support for Hadoop 2.6
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22615 Build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22615: [SPARK-25016][BUILD][CORE] Remove support for Hadoop 2.6
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22615 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97105/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22615: [SPARK-25016][BUILD][CORE] Remove support for Hadoop 2.6
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22615 **[Test build #97105 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97105/testReport)** for PR 22615 at commit [`9efb76c`](https://github.com/apache/spark/commit/9efb76cde8b7fa31866266dbd90fd57408147dcf). * This patch **fails Spark unit tests**. * This patch **does not merge cleanly**. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22594: [SPARK-25674][SQL] If the records are incremented by mor...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22594 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97104/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22594: [SPARK-25674][SQL] If the records are incremented by mor...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22594 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22594: [SPARK-25674][SQL] If the records are incremented by mor...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22594 **[Test build #97104 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97104/testReport)** for PR 22594 at commit [`8134249`](https://github.com/apache/spark/commit/8134249d7c6214475acc87a8b0f5a7c99bd21d45). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22630: [SPARK-25497][SQL] Limit operation within whole s...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22630#discussion_r223319859
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/WholeStageCodegenExec.scala
---
@@ -345,6 +345,61 @@ trait CodegenSupport extends SparkPlan {
* don't require shouldStop() in the loop of producing rows.
*/
def needStopCheck: Boolean = parent.needStopCheck
+
+ /**
+ * A sequence of checks which evaluate to true if the downstream Limit
operators have not received
+ * enough records and reached the limit. If current node is a data
producing node, it can leverage
+ * this information to stop producing data and complete the data flow
earlier. Common data
+ * producing nodes are leaf nodes like Range and Scan, and blocking
nodes like Sort and Aggregate.
+ * These checks should be put into the loop condition of the data
producing loop.
+ */
+ def limitNotReachedChecks: Seq[String] = parent.limitNotReachedChecks
+
+ /**
+ * A helper method to generate the data producing loop condition
according to the
+ * limit-not-reached checks.
+ */
+ final def limitNotReachedCond: String = {
+// InputAdapter is also a leaf node.
+val isLeafNode = children.isEmpty || this.isInstanceOf[InputAdapter]
+if (isLeafNode || this.isInstanceOf[BlockingOperatorWithCodegen]) {
+ val errMsg = "only leaf nodes and blocking nodes need to call
'limitNotReachedCond' " +
+"in its data producing loop."
+ if (Utils.isTesting) {
+throw new IllegalStateException(errMsg)
+ } else {
+logWarning(errMsg)
--- End diff --
nit: shall we also mention to report to the community if seen?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22630: [SPARK-25497][SQL] Limit operation within whole s...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22630#discussion_r223319524
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/WholeStageCodegenExec.scala
---
@@ -345,6 +345,61 @@ trait CodegenSupport extends SparkPlan {
* don't require shouldStop() in the loop of producing rows.
*/
def needStopCheck: Boolean = parent.needStopCheck
+
+ /**
+ * A sequence of checks which evaluate to true if the downstream Limit
operators have not received
+ * enough records and reached the limit. If current node is a data
producing node, it can leverage
+ * this information to stop producing data and complete the data flow
earlier. Common data
+ * producing nodes are leaf nodes like Range and Scan, and blocking
nodes like Sort and Aggregate.
+ * These checks should be put into the loop condition of the data
producing loop.
+ */
+ def limitNotReachedChecks: Seq[String] = parent.limitNotReachedChecks
+
+ /**
+ * A helper method to generate the data producing loop condition
according to the
+ * limit-not-reached checks.
+ */
+ final def limitNotReachedCond: String = {
+// InputAdapter is also a leaf node.
+val isLeafNode = children.isEmpty || this.isInstanceOf[InputAdapter]
+if (isLeafNode || this.isInstanceOf[BlockingOperatorWithCodegen]) {
+ val errMsg = "only leaf nodes and blocking nodes need to call
'limitNotReachedCond' " +
--- End diff --
nit: `Only`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22029: [SPARK-24395][SQL] IN operator should return NULL when c...
Github user mgaido91 commented on the issue: https://github.com/apache/spark/pull/22029 @cloud-fan @dongjoon-hyun @gatorsmile anymore comments on this? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22630: [SPARK-25497][SQL] Limit operation within whole s...
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/22630#discussion_r223318798
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/WholeStageCodegenExec.scala
---
@@ -362,8 +362,15 @@ trait CodegenSupport extends SparkPlan {
final def limitNotReachedCond: String = {
// InputAdapter is also a leaf node.
val isLeafNode = children.isEmpty || this.isInstanceOf[InputAdapter]
-assert(isLeafNode || this.isInstanceOf[BlockingOperatorWithCodegen],
- "only leaf nodes and blocking nodes need to call this method in its
data producing loop.")
+if (isLeafNode || this.isInstanceOf[BlockingOperatorWithCodegen]) {
--- End diff --
`if (!isLeafNode && !this.isInstanceOf[BlockingOperatorWithCodegen])`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20999: [SPARK-14922][SPARK-17732][SPARK-23866][SQL] Support par...
Github user mgaido91 commented on the issue: https://github.com/apache/spark/pull/20999 kindly ping @cloud-fan @dongjoon-hyun @gatorsmile @viirya --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22630: [SPARK-25497][SQL] Limit operation within whole s...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22630#discussion_r223315367
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/WholeStageCodegenExec.scala
---
@@ -360,6 +360,10 @@ trait CodegenSupport extends SparkPlan {
* limit-not-reached checks.
*/
final def limitNotReachedCond: String = {
+// InputAdapter is also a leaf node.
+val isLeafNode = children.isEmpty || this.isInstanceOf[InputAdapter]
+assert(isLeafNode || this.isInstanceOf[BlockingOperatorWithCodegen],
--- End diff --
ah good idea!
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22631: [SPARK-25605][TESTS] Run cast string to timestamp...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22631#discussion_r223314632
--- Diff:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CastSuite.scala
---
@@ -110,7 +112,7 @@ class CastSuite extends SparkFunSuite with
ExpressionEvalHelper {
}
test("cast string to timestamp") {
-for (tz <- ALL_TIMEZONES) {
+for (tz <- Random.shuffle(ALL_TIMEZONES).take(50)) {
--- End diff --
> we should categorize timezones, pick up some timezones representing them
and test fixed set
That would be the best, but we need some deep understanding of timezone, to
make sure the test coverage is good.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22671: [SPARK-25615][SQL][TEST] Improve the test runtime...
GitHub user dilipbiswal opened a pull request: https://github.com/apache/spark/pull/22671 [SPARK-25615][SQL][TEST] Improve the test runtime of KafkaSinkSuite: streaming write to non-existing topic ## What changes were proposed in this pull request? Specify `kafka.max.block.ms` to 10 seconds while creating the kafka writer. In the absence of this overridden config, by default it uses a default time out of 60 seconds. With this change the test completes in close to 10 seconds as opposed to 1 minute. ## How was this patch tested? This is a test fix. You can merge this pull request into a Git repository by running: $ git pull https://github.com/dilipbiswal/spark SPARK-25615 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22671.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22671 commit 6a36250dec0e23520f482d8d092cb658ce147fb7 Author: Dilip Biswal Date: 2018-10-08T09:07:47Z [SPARK-25615] Improve the test runtime of KafkaSinkSuite: streaming - write to non-existing topic --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22631: [SPARK-25605][TESTS] Run cast string to timestamp...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22631#discussion_r223292455
--- Diff:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CastSuite.scala
---
@@ -110,7 +112,7 @@ class CastSuite extends SparkFunSuite with
ExpressionEvalHelper {
}
test("cast string to timestamp") {
-for (tz <- ALL_TIMEZONES) {
+for (tz <- Random.shuffle(ALL_TIMEZONES).take(50)) {
--- End diff --
I don't think that adding parallelism is a good way for improve test time.
The amount of resources used for testing is anyway limited. I think the goal
here is not (only) reduce the overall time of the test but also reduce the
amount of resources needed to test.
Problems with a specific timezone like you mentioned, @HyukjinKwon, are
exactly the reason why I am proposing this randomized approach, rather than
picking 3 timezones and always use them as done in `DateExpressionsSuite`: if
there is a problem with a specific timezone, in this way, we will be able to
catch it. With a fixed subset of them (even though not on the single run), we
are not.
The only safe deterministic way would be to run against all of them, as it
was done before, but then I'd argue that we should do the same everywhere we
have different timezones involved in tests (why are we testing all timezones
only for casting to timestamp and not for all other functions involving dates
and times, if it is so important to check all timezones?). But then the amount
of time needed to run all the tests would be crazy, so it is not doable.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22482: WIP - [SPARK-10816][SS] Support session window natively
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22482 **[Test build #97107 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97107/testReport)** for PR 22482 at commit [`78fdd99`](https://github.com/apache/spark/commit/78fdd9923d74ff47c9cb402e2da6c1953738ddc8). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22631: [SPARK-25605][TESTS] Run cast string to timestamp...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22631#discussion_r223286771
--- Diff:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CastSuite.scala
---
@@ -110,7 +112,7 @@ class CastSuite extends SparkFunSuite with
ExpressionEvalHelper {
}
test("cast string to timestamp") {
-for (tz <- ALL_TIMEZONES) {
+for (tz <- Random.shuffle(ALL_TIMEZONES).take(50)) {
--- End diff --
I mean some tests like with randomized input, let's say, integer range
input are fine in common sense but this case is different, isn't it?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22631: [SPARK-25605][TESTS] Run cast string to timestamp...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22631#discussion_r223285813
--- Diff:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CastSuite.scala
---
@@ -110,7 +112,7 @@ class CastSuite extends SparkFunSuite with
ExpressionEvalHelper {
}
test("cast string to timestamp") {
-for (tz <- ALL_TIMEZONES) {
+for (tz <- Random.shuffle(ALL_TIMEZONES).take(50)) {
--- End diff --
I think tests need to be deterministic in general as well.
In this particular case ideally, we should categorize timezones and test
fixed set. For instance, timezone with DST, without DST, and some exceptions
such as, for instance, see this particular case which Python 3.6 addressed
lately
(https://github.com/python/cpython/blob/e42b705188271da108de42b55d9344642170aa2b/Lib/datetime.py#L1572-L1574),
IMHO.
Of course, this approach requires a lot of investigations and overheads.
So, as an alternative, I would incline to go for Sean's approach
(https://github.com/apache/spark/pull/22631/files#r223224573) for this
particular case.
For randomness, I think primarily we should have first deterministic set of
tests. Maybe we could additionally have some set of randomized input to cover
some cases we haven't foreseen but that's secondary.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21996: [SPARK-24888][CORE] spark-submit --master spark://host:p...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21996 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22564: [SPARK-25282][K8s][DOC] Improved docs to avoid running i...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/22564 I am sorry for the trouble, @liyinan926 and @srowen. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22564: [SPARK-25282][K8s][DOC] Improved docs to avoid running i...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/22564 Looks like this is working without making a release. It is not clear what change could have fixed the problem. Closing the PR for now. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22564: [SPARK-25282][K8s][DOC] Improved docs to avoid ru...
Github user ScrapCodes closed the pull request at: https://github.com/apache/spark/pull/22564 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22630: [SPARK-25497][SQL] Limit operation within whole s...
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22630#discussion_r223277348
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/WholeStageCodegenExec.scala
---
@@ -360,6 +360,10 @@ trait CodegenSupport extends SparkPlan {
* limit-not-reached checks.
*/
final def limitNotReachedCond: String = {
+// InputAdapter is also a leaf node.
+val isLeafNode = children.isEmpty || this.isInstanceOf[InputAdapter]
+assert(isLeafNode || this.isInstanceOf[BlockingOperatorWithCodegen],
--- End diff --
nit: shall we do this only if `Utils.isTesting` and otherwise just emit a
warning maybe?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22630: [SPARK-25497][SQL] Limit operation within whole stage co...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22630 **[Test build #97106 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97106/testReport)** for PR 22630 at commit [`e61078b`](https://github.com/apache/spark/commit/e61078bb563c6868be02f256041a0fb5fbd7c7d7). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22630: [SPARK-25497][SQL] Limit operation within whole stage co...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22630 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22630: [SPARK-25497][SQL] Limit operation within whole stage co...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22630 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/3790/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22630: [SPARK-25497][SQL] Limit operation within whole stage co...
Github user viirya commented on the issue: https://github.com/apache/spark/pull/22630 retest this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22655: [SPARK-25666][PYTHON] Internally document type conversio...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22655 Merged to master. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22655: [SPARK-25666][PYTHON] Internally document type co...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/22655 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22669: [SPARK-25677] [Doc] spark.io.compression.codec = ...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/22669 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22655: [SPARK-25666][PYTHON] Internally document type conversio...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22655 I am getting this in. This is an ongoing effort and it just documents them internally for now. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22669: [SPARK-25677] [Doc] spark.io.compression.codec = org.apa...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22669 Merged to master and branch-2.4. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22635: [SPARK-25591][PySpark][SQL] Avoid overwriting deserializ...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22635 Merged to master and branch-2.4. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22668: [SPARK-25675] [Spark Job History] Job UI page does not s...
Github user shivusondur commented on the issue: https://github.com/apache/spark/pull/22668 @felixcheung If the user inputs **rowcount** in **Show** tab such that all the rows comes in one page, From here on user can't see the pagination and he will not able to inputs **rowcount** again to see pagination. To see pagination, he has to refresh the entire page again. 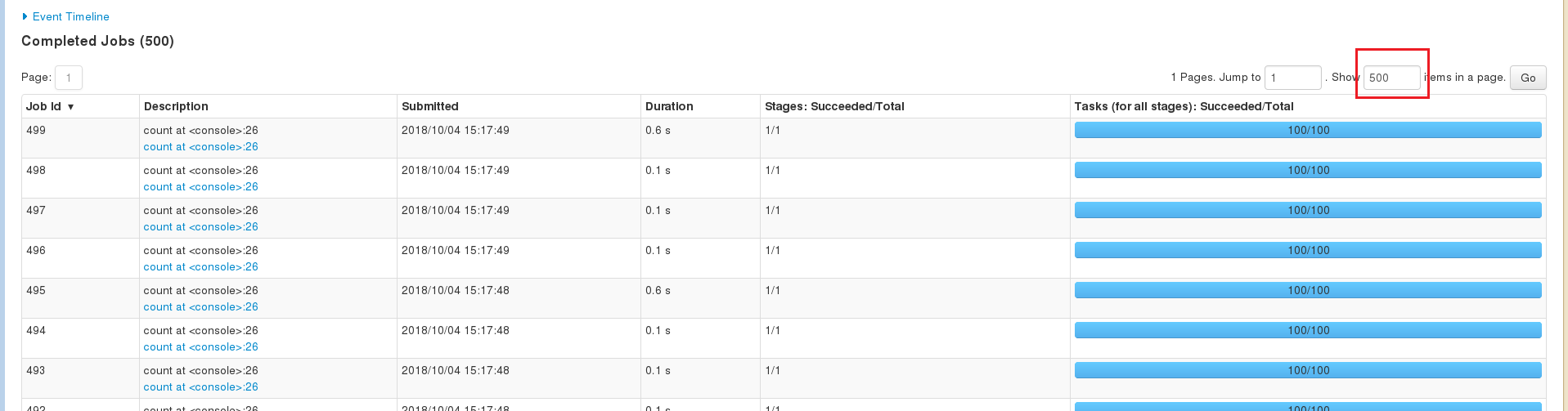 In the Executors page even in one page it is showing the pagination 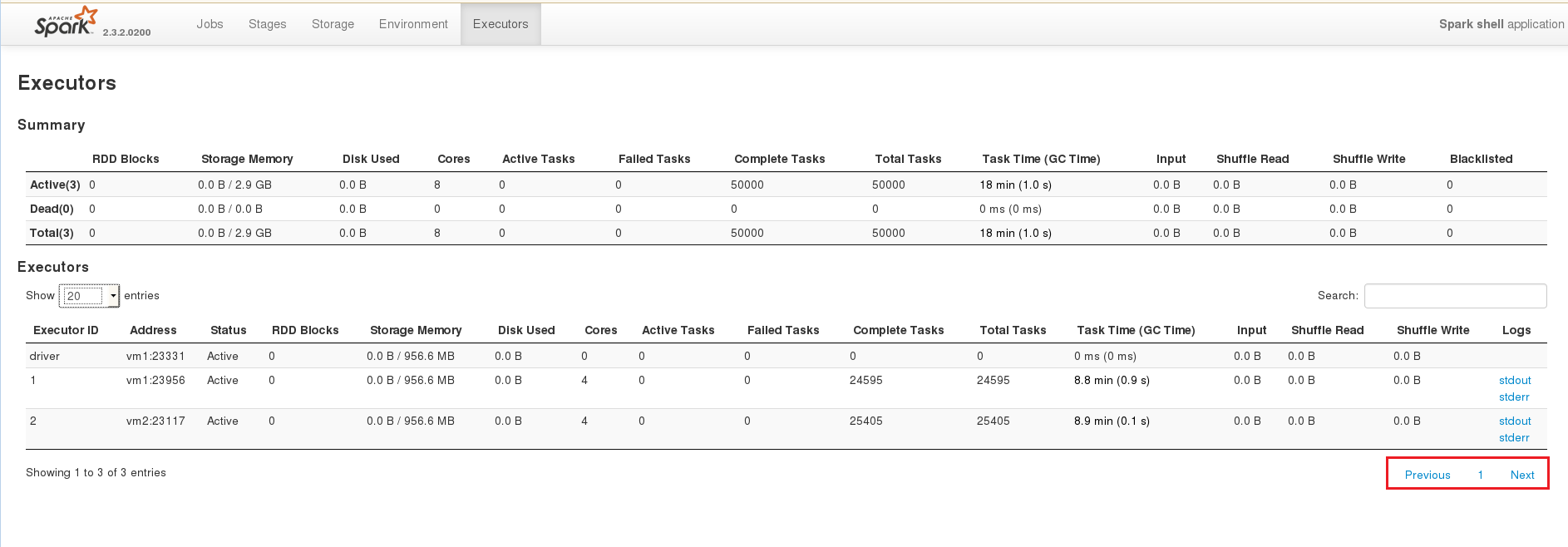 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22615: [SPARK-25016][BUILD][CORE] Remove support for Hadoop 2.6
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22615 **[Test build #97105 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97105/testReport)** for PR 22615 at commit [`9efb76c`](https://github.com/apache/spark/commit/9efb76cde8b7fa31866266dbd90fd57408147dcf). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22669: [SPARK-25677] [Doc] spark.io.compression.codec = org.apa...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22669 **[Test build #97103 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97103/testReport)** for PR 22669 at commit [`8a1a30d`](https://github.com/apache/spark/commit/8a1a30dd64082d2625cfe44560cae1e19f2546fc). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22669: [SPARK-25677] [Doc] spark.io.compression.codec = org.apa...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22669 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97103/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22669: [SPARK-25677] [Doc] spark.io.compression.codec = org.apa...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22669 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22635: [SPARK-25591][PySpark][SQL] Avoid overwriting des...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/22635 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22594: [SPARK-25674][SQL] If the records are incremented by mor...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22594 **[Test build #97104 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97104/testReport)** for PR 22594 at commit [`8134249`](https://github.com/apache/spark/commit/8134249d7c6214475acc87a8b0f5a7c99bd21d45). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22594: [SPARK-25674][SQL] If the records are incremented by mor...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22594 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/3789/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22594: [SPARK-25674][SQL] If the records are incremented by mor...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22594 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #13326: [SPARK-15560] [Mesos] Queued/Supervise drivers waiting f...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/13326 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #13379: [SPARK-12431][GraphX] Add local checkpointing to GraphX.
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/13379 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22594: [SPARK-25674][SQL] If the records are incremented by mor...
Github user dilipbiswal commented on the issue: https://github.com/apache/spark/pull/22594 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22665: add [openjdk11] to Travis build matrix
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/22665 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22667: [SPARK-25673][BUILD] Remove Travis CI which enabl...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/22667 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22237: [SPARK-25243][SQL] Use FailureSafeParser in from_...
Github user MaxGekk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22237#discussion_r223263164
--- Diff: docs/sql-programming-guide.md ---
@@ -1890,6 +1890,10 @@ working with timestamps in `pandas_udf`s to get the
best performance, see
# Migration Guide
+## Upgrading From Spark SQL 2.4 to 3.0
+
+ - Since Spark 3.0, the `from_json` functions supports two modes -
`PERMISSIVE` and `FAILFAST`. The modes can be set via the `mode` option. The
default mode became `PERMISSIVE`. In previous versions, behavior of `from_json`
did not conform to either `PERMISSIVE` nor `FAILFAST`, especially in processing
of malformed JSON records. For example, the JSON string `{"a" 1}` with the
schema `a INT` is converted to `null` by previous versions but Spark 3.0
converts it to `Row(null)`. In version 2.4 and earlier, arrays of JSON objects
are considered as invalid and converted to `null` if specified schema is
`StructType`. Since Spark 3.0, the input is considered as a valid JSON array
and only its first element is parsed if it conforms to the specified
`StructType`.
--- End diff --
I will check that.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22669: [SPARK-25677] [Doc] spark.io.compression.codec = org.apa...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22669 **[Test build #97103 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97103/testReport)** for PR 22669 at commit [`8a1a30d`](https://github.com/apache/spark/commit/8a1a30dd64082d2625cfe44560cae1e19f2546fc). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22667: [SPARK-25673][BUILD] Remove Travis CI which enables Java...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22667 Merged to master and branch-2.4. Thanks @srowen and @felixcheung. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22630: [SPARK-25497][SQL] Limit operation within whole stage co...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22630 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97101/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22594: [SPARK-25674][SQL] If the records are incremented by mor...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22594 Build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22630: [SPARK-25497][SQL] Limit operation within whole stage co...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22630 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22594: [SPARK-25674][SQL] If the records are incremented by mor...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22594 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97095/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22669: [SPARK-25677] [Doc] spark.io.compression.codec = org.apa...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22669 ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22594: [SPARK-25674][SQL] If the records are incremented by mor...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22594 **[Test build #97095 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97095/testReport)** for PR 22594 at commit [`c332716`](https://github.com/apache/spark/commit/c332716f87b52b2bc3f1cd64e2cde945ac44d142). * This patch **fails due to an unknown error code, -9**. * This patch **does not merge cleanly**. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22630: [SPARK-25497][SQL] Limit operation within whole stage co...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22630 **[Test build #97101 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97101/testReport)** for PR 22630 at commit [`e61078b`](https://github.com/apache/spark/commit/e61078bb563c6868be02f256041a0fb5fbd7c7d7). * This patch **fails due to an unknown error code, -9**. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * `trait BlockingOperatorWithCodegen extends CodegenSupport ` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22594: [SPARK-25674][SQL] If the records are incremented by mor...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22594 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22594: [SPARK-25674][SQL] If the records are incremented by mor...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22594 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97096/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org