[GitHub] flink issue #6373: [FLINK-9838][logging] Don't log slot request failures on ...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/6373 Ran into this bug too. +1 for the fix ---
[GitHub] flink pull request #6300: [FLINK-9692][Kinesis Connector] Adaptive reads fro...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/6300#discussion_r202199865
--- Diff:
flink-connectors/flink-connector-kinesis/src/main/java/org/apache/flink/streaming/connectors/kinesis/config/ConsumerConfigConstants.java
---
@@ -134,6 +134,10 @@ public SentinelSequenceNumber
toSentinelSequenceNumber() {
/** The interval between each attempt to discover new shards. */
public static final String SHARD_DISCOVERY_INTERVAL_MILLIS =
"flink.shard.discovery.intervalmillis";
+ /** The config to turn on adaptive reads from a shard. */
+ public static final String SHARD_USE_ADAPTIVE_READS =
"flink.shard.use.adaptive.reads";
--- End diff --
[most Flink's feature
flags](https://ci.apache.org/projects/flink/flink-docs-master/ops/config.html)
are named `xx.enabled`, I'd suggest rename it to something like
`flink.shard.adaptive.read.records.enabled`
---
[GitHub] flink pull request #6300: [FLINK-9692][Kinesis Connector] Adaptive reads fro...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/6300#discussion_r202201507
--- Diff:
flink-connectors/flink-connector-kinesis/src/main/java/org/apache/flink/streaming/connectors/kinesis/internals/ShardConsumer.java
---
@@ -330,4 +347,24 @@ private GetRecordsResult getRecords(String shardItr,
int maxNumberOfRecords) thr
protected static List deaggregateRecords(List
records, String startingHashKey, String endingHashKey) {
return UserRecord.deaggregate(records, new
BigInteger(startingHashKey), new BigInteger(endingHashKey));
}
+
+ /**
+* Adapts the maxNumberOfRecordsPerFetch based on the current average
record size
+* to optimize 2 Mb / sec read limits.
+*
+* @param averageRecordSizeBytes
+* @return adaptedMaxRecordsPerFetch
+*/
+
+ protected int getAdaptiveMaxRecordsPerFetch(long
averageRecordSizeBytes) {
+ int adaptedMaxRecordsPerFetch = maxNumberOfRecordsPerFetch;
+ if (averageRecordSizeBytes != 0 && fetchIntervalMillis != 0) {
+ adaptedMaxRecordsPerFetch = (int)
(KINESIS_SHARD_BYTES_PER_SECOND_LIMIT / (averageRecordSizeBytes * 1000L /
fetchIntervalMillis));
+
+ // Ensure the value is not more than 1L
+ adaptedMaxRecordsPerFetch =
adaptedMaxRecordsPerFetch <=
ConsumerConfigConstants.DEFAULT_SHARD_GETRECORDS_MAX ?
--- End diff --
adaptedMaxRecordsPerFetch = Math.min(adaptedMaxRecordsPerFetch,
ConsumerConfigConstants.DEFAULT_SHARD_GETRECORDS_MAX);
---
[GitHub] flink pull request #6319: [FLINK-9822] Add Dockerfile for StandaloneJobClust...
Github user bowenli86 commented on a diff in the pull request: https://github.com/apache/flink/pull/6319#discussion_r202198679 --- Diff: flink-container/docker/README.md --- @@ -0,0 +1,44 @@ +# Apache Flink cluster deployment on docker using docker-compose --- End diff -- Does this apply to both standalone and cluster mode? Want to get clarified since the PR title says it's for standaloneJobCluster ---
[GitHub] flink pull request #6319: [FLINK-9822] Add Dockerfile for StandaloneJobClust...
Github user bowenli86 commented on a diff in the pull request: https://github.com/apache/flink/pull/6319#discussion_r202197686 --- Diff: flink-container/docker/README.md --- @@ -0,0 +1,44 @@ +# Apache Flink cluster deployment on docker using docker-compose + +## Installation + +Install the most recent stable version of docker +https://docs.docker.com/installation/ + +## Build + +Images are based on the official Java Alpine (OpenJDK 8) image. If you want to +build the flink image run: + +sh build.sh --job-jar /path/to/job/jar/job.jar --image-name flink:job + +or + +docker build -t flink . + +If you want to build the container for a specific version of flink/hadoop/scala +you can configure it in the respective args: + +docker build --build-arg FLINK_VERSION=1.0.3 --build-arg HADOOP_VERSION=26 --build-arg SCALA_VERSION=2.10 -t "flink:1.0.3-hadoop2.6-scala_2.10" flink --- End diff -- Is FLINK_VERSION 1.0.3 only for demo purpose? Can we use a more recent version for demoing? ---
[GitHub] flink issue #6109: [FLINK-9483] 'Building Flink' doc doesn't highlight quick...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/6109 cc @zentol ---
[GitHub] flink pull request #6277: [FLINK-9511] Implement TTL config
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/6277#discussion_r201216406
--- Diff:
flink-core/src/main/java/org/apache/flink/api/common/state/StateTtlConfiguration.java
---
@@ -93,4 +97,82 @@ public Time getTtl() {
public TtlTimeCharacteristic getTimeCharacteristic() {
return timeCharacteristic;
}
+
+ @Override
+ public String toString() {
+ return "StateTtlConfiguration{" +
+ "ttlUpdateType=" + ttlUpdateType +
+ ", stateVisibility=" + stateVisibility +
+ ", timeCharacteristic=" + timeCharacteristic +
+ ", ttl=" + ttl +
+ '}';
+ }
+
+ public static Builder newBuilder(Time ttl) {
+ return new Builder(ttl);
+ }
+
+ /**
+* Builder for the {@link StateTtlConfiguration}.
+*/
+ public static class Builder {
+
+ private TtlUpdateType ttlUpdateType = OnCreateAndWrite;
+ private TtlStateVisibility stateVisibility = NeverReturnExpired;
+ private TtlTimeCharacteristic timeCharacteristic =
ProcessingTime;
+ private Time ttl;
+
+ public Builder(Time ttl) {
--- End diff --
Should `TimeCharacteristic` be a builder's constructor param as well?
Otherwise, users may not notice they have to set it, and may easily lead into
confusion
---
[GitHub] flink issue #6290: [Flink-9691] [Kinesis Connector] Attempt to call getRecor...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/6290 +1, LGTM ---
[GitHub] flink issue #6195: [FLINK-9543][METRICS] Expose JobMaster ID to metric syste...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/6195 Can you also add documentation to the Metrics page? ---
[GitHub] flink pull request #6130: [FLINK-9545] Support read a file multiple times in...
Github user bowenli86 closed the pull request at: https://github.com/apache/flink/pull/6130 ---
[GitHub] flink issue #6156: [FLINK-9572] Extend InternalAppendingState with internal ...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/6156 +1 LGTM ---
[GitHub] flink issue #6130: [FLINK-9545] Support read a file multiple times in Flink ...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/6130 Not really. It's not about having n copies of data. One use case is File-fed stream pipeline usually runs very fast with inadequate metrics, users need to run it end-to-end for a longer time to gather stable metrics and tune all components in the pipeline. I'll close it if community is not interested. ---
[GitHub] flink issue #6130: [FLINK-9545] Support read a file multiple times in Flink ...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/6130 @aljoscha Motivation: We have the requirements to read a bunch files, each file to read multiple times, to feed our streams Specifically we need `StreamExecutionEnvironment.readFile/readTextFile` to be able to read a file for a specified `N` times, but currently it only supports reading file once. We've implemented this internally. Would be good to get it back to the community version. This jira is to add support for the feature. ---
[GitHub] flink pull request #6130: [FLINK-9545] Support read a file multiple times in...
GitHub user bowenli86 opened a pull request: https://github.com/apache/flink/pull/6130 [FLINK-9545] Support read a file multiple times in Flink DataStream ## What is the purpose of the change we need `StreamExecutionEnvironment.readFile/readTextFile` to read each file for N times, but currently it only supports reading file once. add support for the feature. ## Brief change log - add a new processing mode as PROCESSING_N_TIMES - add additional parameter numTimes for StreamExecutionEnvironment.readFile/readTextFile ## Verifying this change This change is already covered by existing tests, such as *(please describe tests)*. ## Does this pull request potentially affect one of the following parts: - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes) ## Documentation - Does this pull request introduce a new feature? (yes) - If yes, how is the feature documented? (docs / JavaDocs) You can merge this pull request into a Git repository by running: $ git pull https://github.com/bowenli86/flink FLINK-9545 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/6130.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #6130 commit d51fd25ca0ff8e38aaf84d2076c9c979cd136c9d Author: Bowen Li Date: 2018-06-07T00:12:59Z [FLINK-9545] Support read a file multiple times in Flink DataStream ---
[GitHub] flink pull request #6021: [FLINK-9374] [kinesis] Enable FlinkKinesisProducer...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/6021#discussion_r192834879
--- Diff:
flink-connectors/flink-connector-kinesis/src/main/java/org/apache/flink/streaming/connectors/kinesis/util/TimeoutLatch.java
---
@@ -0,0 +1,41 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.streaming.connectors.kinesis.util;
+
+public class TimeoutLatch {
+
+ private final Object lock = new Object();
+ private volatile boolean waiting;
+
+ public void await(long timeout) throws InterruptedException {
+ synchronized (lock) {
+ waiting = true;
+ lock.wait(timeout);
+ }
+ }
+
+ public void trigger() {
+ if (waiting) {
+ synchronized (lock) {
+ waiting = false;
--- End diff --
needs another `if (waiting)` here inside the synchronized block, to ensure
no one chimes in between line 34 and 35
---
[GitHub] flink pull request #6021: [FLINK-9374] [kinesis] Enable FlinkKinesisProducer...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/6021#discussion_r192837000
--- Diff:
flink-connectors/flink-connector-kinesis/src/main/java/org/apache/flink/streaming/connectors/kinesis/FlinkKinesisProducer.java
---
@@ -180,9 +204,16 @@ public void open(Configuration parameters) throws
Exception {
KinesisProducerConfiguration producerConfig =
KinesisConfigUtil.getValidatedProducerConfiguration(configProps);
producer = getKinesisProducer(producerConfig);
+
+ final MetricGroup kinesisMectricGroup =
getRuntimeContext().getMetricGroup().addGroup("kinesisProducer");
--- End diff --
minor: better to make these three strings constant (static final String)
for easier maintenance.
---
[GitHub] flink issue #6116: [FLINK-9498][build] Disable dependency convergence for fl...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/6116 Will it lower the possibility of detecting lib version conflicts of Flink's dependencies? ---
[GitHub] flink pull request #6109: [FLINK-9483] 'Building Flink' doc doesn't highligh...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/6109#discussion_r192628940
--- Diff: docs/start/building.md ---
@@ -50,7 +50,11 @@ mvn clean install -DskipTests
This instructs [Maven](http://maven.apache.org) (`mvn`) to first remove
all existing builds (`clean`) and then create a new Flink binary (`install`).
-To speed up the build you can skip tests, checkstyle, and JavaDocs: `mvn
clean install -DskipTests -Dmaven.javadoc.skip=true -Dcheckstyle.skip=true`.
+To speed up the build you can skip tests, checkstyle, and JavaDocs:
+
+{% highlight bash %}
+mvn clean install -DskipTests -Dmaven.javadoc.skip=true
-Dcheckstyle.skip=true
--- End diff --
https://github.com/apache/flink/blob/56df6904688642b1c8f9a287646c163dfae7edfd/pom.xml#L639
---
[GitHub] flink pull request #6109: [FLINK-9483] 'Building Flink' doc doesn't highligh...
Github user bowenli86 commented on a diff in the pull request: https://github.com/apache/flink/pull/6109#discussion_r192535262 --- Diff: docs/start/building.md --- @@ -50,7 +50,11 @@ mvn clean install -DskipTests This instructs [Maven](http://maven.apache.org) (`mvn`) to first remove all existing builds (`clean`) and then create a new Flink binary (`install`). -To speed up the build you can skip tests, checkstyle, and JavaDocs: `mvn clean install -DskipTests -Dmaven.javadoc.skip=true -Dcheckstyle.skip=true`. +To speed up the build you can skip tests, checkstyle, and JavaDocs: --- End diff -- What's `QA-plugins`? Do you mean the set of QA checks in `tools/qa-check.sh`? ---
[GitHub] flink pull request #6109: [FLINK-9483] 'Building Flink' doc doesn't highligh...
GitHub user bowenli86 opened a pull request: https://github.com/apache/flink/pull/6109 [FLINK-9483] 'Building Flink' doc doesn't highlight quick build command ## What is the purpose of the change The blue part isn't corrected highlighted as the red ones 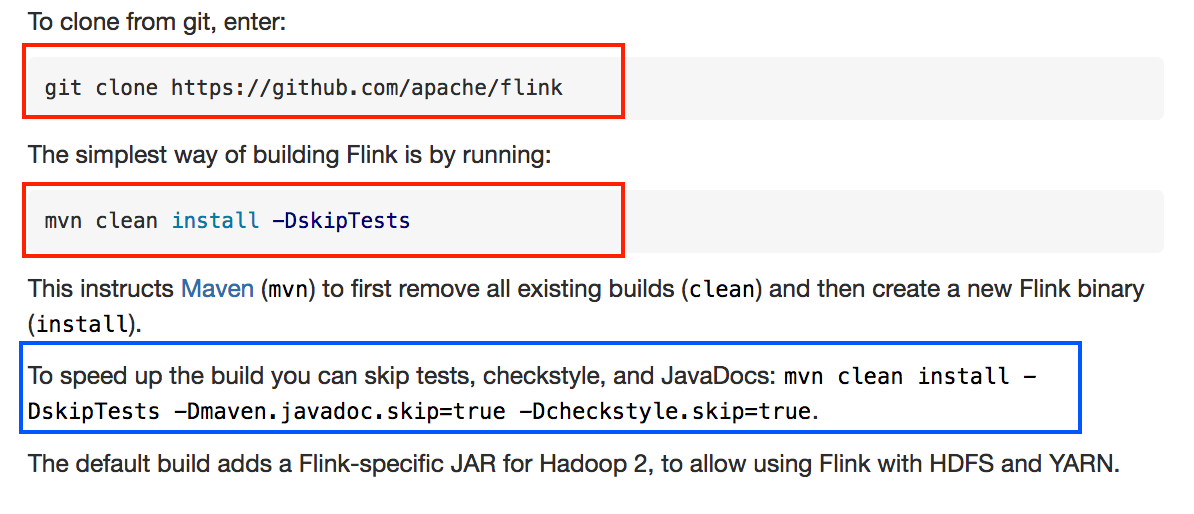 ## Brief change log Highlight quick build command ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: none ## Documentation none You can merge this pull request into a Git repository by running: $ git pull https://github.com/bowenli86/flink FLINK-9483 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/6109.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #6109 commit 8ea6f791de0266f481c45d03731d15ed999ea753 Author: Bowen Li Date: 2018-05-31T23:15:41Z [FLINK-9483] 'Building Flink' doc doesn't highlight quick build command ---
[GitHub] flink pull request #5649: [FLINK-8873] [DataStream API] [Tests] move unit te...
Github user bowenli86 closed the pull request at: https://github.com/apache/flink/pull/5649 ---
[GitHub] flink pull request #6104: [FLINK-9476]Emit late elements in CEP as sideOutPu...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/6104#discussion_r191858415
--- Diff: docs/dev/libs/cep.md ---
@@ -1524,7 +1524,52 @@ In `CEP` the order in which elements are processed
matters. To guarantee that el
To guarantee that elements across watermarks are processed in event-time
order, Flink's CEP library assumes
*correctness of the watermark*, and considers as *late* elements whose
timestamp is smaller than that of the last
-seen watermark. Late elements are not further processed.
+seen watermark. Late elements are not further processed. Also, you can
specify a sideOutput tag to collect the late elements come after the last seen
watermark, you can use it like this.
+
+
+
+
+{% highlight java %}
+PatternStream patternStream = CEP.pattern(input, pattern);
+
+OutputTag lataDataOutputTag = new
OutputTag("lata-data""){};
+
+OutputTag outputTag = new OutputTag("side-output""){};
+
+SingleOutputStreamOperator result = patternStream
+.sideOutputLateData(lataDataOutputTag)
+.select(
+new PatternTimeoutFunction() {...},
+outputTag,
+new PatternSelectFunction() {...}
+);
+
+DataStream lataData = result.getSideOutput(lataDataOutputTag);
--- End diff --
typo: lateData
---
[GitHub] flink pull request #6104: [FLINK-9476]Emit late elements in CEP as sideOutPu...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/6104#discussion_r191857843
--- Diff: docs/dev/libs/cep.md ---
@@ -1524,7 +1524,52 @@ In `CEP` the order in which elements are processed
matters. To guarantee that el
To guarantee that elements across watermarks are processed in event-time
order, Flink's CEP library assumes
*correctness of the watermark*, and considers as *late* elements whose
timestamp is smaller than that of the last
-seen watermark. Late elements are not further processed.
+seen watermark. Late elements are not further processed. Also, you can
specify a sideOutput tag to collect the late elements come after the last seen
watermark, you can use it like this.
+
+
+
+
+{% highlight java %}
+PatternStream patternStream = CEP.pattern(input, pattern);
+
+OutputTag lataDataOutputTag = new
OutputTag("lata-data""){};
--- End diff --
typo: "lateDataOutputTag" and "late-data"
---
[GitHub] flink issue #5649: [FLINK-8873] [DataStream API] [Tests] move unit tests of ...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5649 When I was developing KeyedProcessFunction, I initially wondered why there's no tests for KeyedStream, and researched and realized that they were actually mixed with DataStream tests. I think having that clarity by separating those tests would be great. Well, I also agree it doesn't hurt that much to keep them as-is. If you feel strongly against it, I can close this PR ---
[GitHub] flink issue #6097: [FLINK-9470] Allow querying the key in KeyedProcessFuncti...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/6097 +1. I might forget to add the interfaces back then, would be good to have them ---
[GitHub] flink pull request #6066: [FLINK-9428] [checkpointing] Allow operators to fl...
Github user bowenli86 commented on a diff in the pull request: https://github.com/apache/flink/pull/6066#discussion_r190342404 --- Diff: flink-streaming-java/src/main/java/org/apache/flink/streaming/api/operators/StreamOperator.java --- @@ -93,6 +93,20 @@ // state snapshots // + /** --- End diff -- This description feels like it states well what it's not intended for, but doesn't clearly describe what it's intended for. It would be great if you can add what you wrote in the ticket description here, as of "Some operators maintain some small transient state ... Rather that persisting that state in a checkpoint, it can make sense to flush the data downstream " ---
[GitHub] flink issue #5978: [FLINK-8554] Upgrade AWS SDK
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5978 Are there anything in `1.11.325` we desperately need? If not, I would oppose upgrading AWS SDK too frequently. Highly likely that we don't need any of the new changes in `1.11.325`. As you can see, the current sdk version is `1.11.319` which is upgraded just a few days ago. There're a few reasons we should discourage it: - It doesn't add much value, and we don't really need it - It costs lots of unnecessary work from both contributors and Flink community (committers, reviewers, etc) - AWS releases their SDK very frequently, in a much faster pace than we can possibly catch up ---
[GitHub] flink issue #6021: [FLINK-9374] [kinesis] Enable FlinkKinesisProducer Backpr...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/6021 @tzulitai adding docs to educate users on tuning KPL performance would be good. I has quite some experience on it (as you may have know :) Ping me if you start working on it before I do, and I'll be glad to help contribute ---
[GitHub] flink pull request #6021: [FLINK-9374] [kinesis] Enable FlinkKinesisProducer...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/6021#discussion_r189174902
--- Diff:
flink-connectors/flink-connector-kinesis/src/main/java/org/apache/flink/streaming/connectors/kinesis/FlinkKinesisProducer.java
---
@@ -326,6 +342,24 @@ private void checkAndPropagateAsyncError() throws
Exception {
}
}
+ /**
+* If the internal queue of the {@link KinesisProducer} gets too long,
+* flush some of the records until we are below the limit again.
+* We don't want to flush _all_ records at this point since that would
+* break record aggregation.
+*/
+ private void checkQueueLimit() {
--- End diff --
probably rename it to something different, e.g `enforceQueueLimit()`?
because it clearly does things more than just 'check'
---
[GitHub] flink pull request #6021: [FLINK-9374] [kinesis] Enable FlinkKinesisProducer...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/6021#discussion_r189175770
--- Diff:
flink-connectors/flink-connector-kinesis/src/main/java/org/apache/flink/streaming/connectors/kinesis/FlinkKinesisProducer.java
---
@@ -326,6 +342,24 @@ private void checkAndPropagateAsyncError() throws
Exception {
}
}
+ /**
+* If the internal queue of the {@link KinesisProducer} gets too long,
+* flush some of the records until we are below the limit again.
+* We don't want to flush _all_ records at this point since that would
+* break record aggregation.
+*/
+ private void checkQueueLimit() {
+ while (producer.getOutstandingRecordsCount() >= queueLimit) {
+ producer.flush();
--- End diff --
Iooks like
[KinesisProducer](https://github.com/awslabs/amazon-kinesis-producer/blob/master/java/amazon-kinesis-producer/src/main/java/com/amazonaws/services/kinesis/producer/KinesisProducer.java)
doesn't have a way to get child process's callback. Or maybe I misunderstood
your proposal, Gordon?
---
[GitHub] flink pull request #6021: [FLINK-9374] [kinesis] Enable FlinkKinesisProducer...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/6021#discussion_r189176708
--- Diff:
flink-connectors/flink-connector-kinesis/src/main/java/org/apache/flink/streaming/connectors/kinesis/FlinkKinesisProducer.java
---
@@ -326,6 +342,24 @@ private void checkAndPropagateAsyncError() throws
Exception {
}
}
+ /**
+* If the internal queue of the {@link KinesisProducer} gets too long,
+* flush some of the records until we are below the limit again.
+* We don't want to flush _all_ records at this point since that would
+* break record aggregation.
+*/
+ private void checkQueueLimit() {
+ while (producer.getOutstandingRecordsCount() >= queueLimit) {
--- End diff --
A more important thing I would count and log here is how many times it has
already tried to flush within a single call of `enforceQueueLimit()`. We can
set a threshold, say 10 times, and then log a message saying that KPL is
leading to backpressure
---
[GitHub] flink pull request #6021: [FLINK-9374] [kinesis] Enable FlinkKinesisProducer...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/6021#discussion_r189176320
--- Diff:
flink-connectors/flink-connector-kinesis/src/main/java/org/apache/flink/streaming/connectors/kinesis/FlinkKinesisProducer.java
---
@@ -326,6 +342,24 @@ private void checkAndPropagateAsyncError() throws
Exception {
}
}
+ /**
+* If the internal queue of the {@link KinesisProducer} gets too long,
+* flush some of the records until we are below the limit again.
+* We don't want to flush _all_ records at this point since that would
+* break record aggregation.
+*/
+ private void checkQueueLimit() {
+ while (producer.getOutstandingRecordsCount() >= queueLimit) {
+ producer.flush();
+ try {
+ Thread.sleep(500);
+ } catch (InterruptedException e) {
+ LOG.warn("Flushing was interrupted.");
--- End diff --
you can remove this two lines, they don't provide much value. After
removal, it will be almost exactly how `KinesisProducer#flushSync` works
```
// KinesisProducer.java
@Override
public void flushSync() {
while (getOutstandingRecordsCount() > 0) {
flush();
try {
Thread.sleep(500);
} catch (InterruptedException e) { }
}
}
```
---
[GitHub] flink issue #5649: [FLINK-8873] [DataStream API] [Tests] move unit tests of ...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5649 Hi @kl0u , can you pls take a look at this PR? ---
[GitHub] flink issue #5979: [FLINK-9070][state]improve the performance of RocksDBMapS...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5979 LGTM +1 ---
[GitHub] flink pull request #5979: [FLINK-9070][state]improve the performance of Rock...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/5979#discussion_r187255609
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBMapState.java
---
@@ -356,6 +369,20 @@ private UV deserializeUserValue(byte[] rawValueBytes,
TypeSerializer valueSe
return isNull ? null : valueSerializer.deserialize(in);
}
+ private boolean startWithKeyPrefix(byte[] keyPrefixBytes, byte[]
rawKeyBytes) {
+ if (rawKeyBytes.length < keyPrefixBytes.length) {
+ return false;
+ }
+
+ for (int i = keyPrefixBytes.length; --i >=
backend.getKeyGroupPrefixBytes(); ) {
--- End diff --
I recommend moving `--i` to the increment part of the `for` loop, instead
of keeping it in the termination part
---
[GitHub] flink pull request #5949: [FLINK-9288][docs] clarify the event time / waterm...
Github user bowenli86 commented on a diff in the pull request: https://github.com/apache/flink/pull/5949#discussion_r185588020 --- Diff: docs/dev/event_time.md --- @@ -35,30 +35,32 @@ Flink supports different notions of *time* in streaming programs. respective operation. When a streaming program runs on processing time, all time-based operations (like time windows) will -use the system clock of the machines that run the respective operator. For example, an hourly +use the system clock of the machines that run the respective operator. An hourly processing time window will include all records that arrived at a specific operator between the -times when the system clock indicated the full hour. +times when the system clock indicated the full hour. For example, if an application +begins running at 9:15am, the first hourly processing time window will include events +processed between 9:15am and 10:00am, the next window will include events processed between 10:00am and 11:00am, and so on. Processing time is the simplest notion of time and requires no coordination between streams and machines. It provides the best performance and the lowest latency. However, in distributed and asynchronous environments processing time does not provide determinism, because it is susceptible to the speed at which -records arrive in the system (for example from the message queue), and to the speed at which the -records flow between operators inside the system. +records arrive in the system (for example from the message queue), to the speed at which the +records flow between operators inside the system, and to outages (scheduled, or otherwise). - **Event time:** Event time is the time that each individual event occurred on its producing device. -This time is typically embedded within the records before they enter Flink and that *event timestamp* -can be extracted from the record. An hourly event time window will contain all records that carry an -event timestamp that falls into that hour, regardless of when the records arrive, and in what order -they arrive. +This time is typically embedded within the records before they enter Flink, and that *event timestamp* +can be extracted from each record. An hourly event time window will contain all records that carry an --- End diff -- better mention allowed lateness here. â...will contain all records, ..., regardless of when the records arriveâ sounds too absolute, the guarantee can only be achieved with lateness requirements ---
[GitHub] flink pull request #5937: [FLINK-9270] Upgrade RocksDB to 5.11.3, and resolv...
Github user bowenli86 closed the pull request at: https://github.com/apache/flink/pull/5937 ---
[GitHub] flink pull request #5937: [FLINK-9270] Upgrade RocksDB to 5.11.3, and resolv...
GitHub user bowenli86 opened a pull request: https://github.com/apache/flink/pull/5937 [FLINK-9270] Upgrade RocksDB to 5.11.3, and resolve concurrent test invocation problem of @RetryOnFailure ## What is the purpose of the change - Upgrade RocksDB to 5.11.3 to take latest bug fixes - Besides, I found that unit tests annotated with `@RetryOnFailure` will be run concurrently if there's only `try` clause without a `catch` following. For example, sometimes, `RocksDBPerformanceTest.testRocksDbMergePerformance()` will actually be running in 3 concurrent invocations, and multiple concurrent write to RocksDB result in errors. ## Brief change log - Upgrade RocksDB to 5.11.3 - For all RocksDB performance tests, add a `catch` clause to follow `try` This change is already covered by existing tests ## Does this pull request potentially affect one of the following parts: none ## Documentation none You can merge this pull request into a Git repository by running: $ git pull https://github.com/bowenli86/flink FLINK-9270 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/5937.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5937 commit 9fed7b9cba78dfdc6512818d9c2c07fc80892d72 Author: Bowen Li <bowenli86@...> Date: 2018-04-28T08:32:09Z [FLINK-9270] Upgrade RocksDB to 5.11.3, and resolve concurrent test invocation problem of @RetryOnFailure ---
[GitHub] flink pull request #5913: [FLINK-9181] [docs] [sql-client] Add documentation...
Github user bowenli86 commented on a diff in the pull request: https://github.com/apache/flink/pull/5913#discussion_r184831365 --- Diff: docs/dev/table/sqlClient.md --- @@ -0,0 +1,539 @@ +--- +title: "SQL Client" +nav-parent_id: tableapi +nav-pos: 100 +is_beta: true +--- + + + +Although Flinkâs Table & SQL API allows to declare queries in the SQL language. A SQL query needs to be embedded within a table program that is written either in Java or Scala. The table program needs to be packaged with a build tool before it can be submitted to a cluster. This limits the usage of Flink to mostly Java/Scala programmers. --- End diff -- minor: should be either `either in Java or in Scala` or `in either Java or Scala` ---
[GitHub] flink pull request #5885: [FLINK-8715] Remove usage of StateDescriptor in st...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/5885#discussion_r184830451
--- Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/state/AbstractKeyedStateBackend.java
---
@@ -455,4 +455,5 @@ public StreamCompressionDecorator
getKeyGroupCompressionDecorator() {
@VisibleForTesting
public abstract int numStateEntries();
+
--- End diff --
revert this?
---
[GitHub] flink pull request #5885: [FLINK-8715] Remove usage of StateDescriptor in st...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/5885#discussion_r184831125
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/AbstractRocksDBState.java
---
@@ -190,4 +197,12 @@ protected void writeKeyWithGroupAndNamespace(
RocksDBKeySerializationUtils.writeKey(key, keySerializer,
keySerializationStream, keySerializationDataOutputView, ambiguousKeyPossible);
RocksDBKeySerializationUtils.writeNameSpace(namespace,
namespaceSerializer, keySerializationStream, keySerializationDataOutputView,
ambiguousKeyPossible);
}
+
+ protected V getDefaultValue() {
--- End diff --
this method is duplicated among some impl classes. We can move it to
`InternalKvState` as a [default
method](https://docs.oracle.com/javase/tutorial/java/IandI/defaultmethods.html).
---
[GitHub] flink issue #5887: [FLINK-6719] [docs] Add details about fault-tolerance of ...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5887 @fhueske updated! let me know how it looks now ---
[GitHub] flink issue #5932: [FLINK-9266][flink-connector-kinesis]Updates Kinesis conn...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5932 +1 ---
[GitHub] flink issue #5910: [FLINK-8841] [state] Remove HashMapSerializer and use Map...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5910 +1 ---
[GitHub] flink issue #5904: [FLINK-9249][build] Add convenience profile for skipping ...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5904 +1 ---
[GitHub] flink pull request #5887: [FLINK-6719] Add details about fault-tolerance of ...
GitHub user bowenli86 opened a pull request: https://github.com/apache/flink/pull/5887 [FLINK-6719] Add details about fault-tolerance of timers to ProcessFunction docs ## What is the purpose of the change The fault-tolerance of timers is a frequently asked questions on the mailing lists. We should add details about the topic in the ProcessFunction docs. ## Brief change log Added details about the topic in the ProcessFunction docs. ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: none ## Documentation none You can merge this pull request into a Git repository by running: $ git pull https://github.com/bowenli86/flink FLINK-6719 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/5887.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5887 commit 324f68d6595444ae9a84ee1ccced645c51aab471 Author: Bowen Li <bowenli86@...> Date: 2018-04-21T06:46:57Z [FLINK-6719] Add details about fault-tolerance of timers to ProcessFunction docs ---
[GitHub] flink issue #5864: [FLINK-8661] Replace Collections.EMPTY_MAP with Collectio...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5864 +1 ---
[GitHub] flink issue #5864: [FLINK-8661] Replace Collections.EMPTY_MAP with Collectio...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5864 does using Collections.EMPTY_MAP/EMPTY_SET lead to some warnings logging? ---
[GitHub] flink issue #5820: [hotfix] [DataStream API] [Scala] removed unused scala im...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5820 @zentol which scala checkstyle mvn plugin are you looking at? I didn't find any available ones, and I'm afraid there might will not be one. scalastyle explicitly said that they will not support capturing unused imports at https://github.com/scalastyle/scalastyle/issues/193 ---
[GitHub] flink pull request #5820: [hotfix] removed unused scala imports
GitHub user bowenli86 opened a pull request: https://github.com/apache/flink/pull/5820 [hotfix] removed unused scala imports ## What is the purpose of the change removed unused scala imports ## Brief change log removed unused scala imports ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: none ## Documentation none You can merge this pull request into a Git repository by running: $ git pull https://github.com/bowenli86/flink hotfix_2 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/5820.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5820 commit f6940a0bf0fd5ff487a63ffad29e4dc9cd7a970c Author: Bowen Li <bowenli86@...> Date: 2018-04-05T07:52:37Z [hotfix] removed unused scala imports ---
[GitHub] flink pull request #5819: [FLINK-9140] [Build System] [scalastyle] simplify ...
GitHub user bowenli86 opened a pull request: https://github.com/apache/flink/pull/5819 [FLINK-9140] [Build System] [scalastyle] simplify scalastyle configurations ## What is the purpose of the change Simplifying `` to `` ## Brief change log Simplifying `` to `` ## Verifying this change This change is already covered by existing tests ## Does this pull request potentially affect one of the following parts: none ## Documentation none You can merge this pull request into a Git repository by running: $ git pull https://github.com/bowenli86/flink FLINK-9140 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/5819.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5819 commit 8bcddf43805190665237325b1f2efd17a5b9f47f Author: Bowen Li <bowenli86@...> Date: 2018-04-05T07:42:50Z [FLINK-9140] simplify scalastyle configurations ---
[GitHub] flink issue #5810: [FLINK-9127] [Core] Filesystem State Backend logged incor...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5810 The original logging is correct - filesystem state backend is actually memory state backend + filesystem checkpointing. No need to change the logging. ---
[GitHub] flink pull request #5809: [FLINK-8697] [Kinesis Connector] Rename DummyFlink...
GitHub user bowenli86 opened a pull request: https://github.com/apache/flink/pull/5809 [FLINK-8697] [Kinesis Connector] Rename DummyFlinkKafkaConsumer in KinesisDataFetcherTest ## What is the purpose of the change `DummyFlinkKafkaConsumer` in `KinesisDataFetcherTest` should be named `DummyFlinkKinesisConsumer` ## Brief change log Rename `DummyFlinkKafkaConsumer` to `DummyFlinkKinesisConsumer` in Kinesis tests ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: none ## Documentation none You can merge this pull request into a Git repository by running: $ git pull https://github.com/bowenli86/flink FLINK-8697 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/5809.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5809 commit 6c836a62248b51c762558e87a3e80410a19262c0 Author: Bowen Li <bowenli86@...> Date: 2018-04-03T20:53:23Z [FLINK-8697] Rename DummyFlinkKafkaConsumer in Kinesis tests ---
[GitHub] flink issue #5800: [FLINK-8837] add @Experimental annotation and properly an...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5800 cc @StephanEwen @tillrohrmann @zentol ---
[GitHub] flink issue #5760: [hotfix] [doc] update maven versions in building flink pa...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5760 cc @zentol ---
[GitHub] flink pull request #5800: [FLINK-8837] add @Experimental annotation and prop...
GitHub user bowenli86 opened a pull request: https://github.com/apache/flink/pull/5800 [FLINK-8837] add @Experimental annotation and properly annotate some classes ## What is the purpose of the change - add @Experimental annotation - properly annotate some classes with @Experimental ## Brief change log - add @Experimental annotation - properly annotate some classes with @Experimental ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes) ## Documentation - Does this pull request introduce a new feature? (yes) - If yes, how is the feature documented? (JavaDocs) You can merge this pull request into a Git repository by running: $ git pull https://github.com/bowenli86/flink FLINK-8837 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/5800.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5800 commit ef729e91d29b47d68d38d4f08cfcc5f246d4dc34 Author: Bowen Li <bowenli86@...> Date: 2018-04-02T07:59:34Z [FLINK-8837] add @Experimental annotation and properly annotate some classes ---
[GitHub] flink pull request #5760: [hotfix] [doc] fix maven version in building flink
GitHub user bowenli86 opened a pull request: https://github.com/apache/flink/pull/5760 [hotfix] [doc] fix maven version in building flink ## What is the purpose of the change The maven version in `start/building` is inconsistent. Make it consistent by changing the maven version to 3.0.4 ## Brief change log The maven version in `start/building` is inconsistent. Make it consistent by changing the maven version to 3.0.4 ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: none ## Documentation none You can merge this pull request into a Git repository by running: $ git pull https://github.com/bowenli86/flink hotfix Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/5760.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5760 commit 8a17ccedf33bed267f4dcfeef185cc589fb70fe1 Author: Bowen Li <bli@...> Date: 2018-03-24T15:11:16Z [hotfix] fix maven version in building flink ---
[GitHub] flink issue #5702: [FLINK-8771] [Build System] [Checkstyle/Scalastyle] Upgra...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5702 Hi @zentol , can you take a look at this PR? ---
[GitHub] flink issue #5702: [FLINK-8771] [Build System] [Checkstyle/Scalastyle] Upgra...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5702 cc @zentol ---
[GitHub] flink pull request #5702: [FLINK-8771] Upgrade scalastyle to 1.0.0
GitHub user bowenli86 opened a pull request: https://github.com/apache/flink/pull/5702 [FLINK-8771] Upgrade scalastyle to 1.0.0 ## What is the purpose of the change Upgrade scalastyle from 0.8.0 to 1.0.0 ## Brief change log - Upgrade scalastyle from 0.8.0 to 1.0.0 - Fixed some license style issues along the way, because scalalstyle 1.0.0 detected those as errors ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: none ## Documentation none You can merge this pull request into a Git repository by running: $ git pull https://github.com/bowenli86/flink FLINK-8771 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/5702.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5702 commit 97160a70ae64e90cc101512ab0fb4c08ba79d924 Author: Bowen Li <bowenli86@...> Date: 2018-03-15T00:26:18Z [FLINK-8771] Upgrade scalastyle to 1.0.0 ---
[GitHub] flink pull request #5356: [FLINK-8364][state backend] Add iterator() to List...
Github user bowenli86 closed the pull request at: https://github.com/apache/flink/pull/5356 ---
[GitHub] flink issue #5649: [FLINK-8873] [DataStream API] [Tests] move unit tests of ...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5649 cc @kl0u ---
[GitHub] flink pull request #5650: [FLINK-8845][state] Introduce RocksDBWriteBatchWra...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/5650#discussion_r174231064
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/test/java/org/apache/flink/contrib/streaming/state/RocksDBWriteBatchWrapperTest.java
---
@@ -0,0 +1,159 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.api.java.tuple.Tuple2;
+
+import org.junit.Assert;
+import org.junit.Ignore;
+import org.junit.Rule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+import org.rocksdb.ColumnFamilyDescriptor;
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.WriteOptions;
+
+import java.util.ArrayList;
+import java.util.List;
+
+/**
+ * Tests to guard {@link RocksDBWriteBatchWrapper}.
+ */
+public class RocksDBWriteBatchWrapperTest {
+
+ @Rule
+ public TemporaryFolder folder = new TemporaryFolder();
+
+ @Test
+ public void basicTest() throws Exception {
+
+ List<Tuple2<byte[], byte[]>> data = new ArrayList<>(1);
+ for (int i = 0; i < 1; ++i) {
+ data.add(new Tuple2<>(("key:" + i).getBytes(),
("value:" + i).getBytes()));
+ }
+
+ try (RocksDB db =
RocksDB.open(folder.newFolder().getAbsolutePath());
+ WriteOptions options = new
WriteOptions().setDisableWAL(true);
+ ColumnFamilyHandle handle = db.createColumnFamily(new
ColumnFamilyDescriptor("test".getBytes()));
+ RocksDBWriteBatchWrapper writeBatchWrapper = new
RocksDBWriteBatchWrapper(db, options, 200)) {
+
+ // insert data
+ for (Tuple2<byte[], byte[]> item : data) {
+ writeBatchWrapper.put(handle, item.f0, item.f1);
+ }
+ writeBatchWrapper.flush();
+
+ // valid result
+ for (Tuple2<byte[], byte[]> item : data) {
+ Assert.assertArrayEquals(item.f1,
db.get(handle, item.f0));
+ }
+ }
+ }
+
+ @Test
+ @Ignore
+ public void benchMark() throws Exception {
+
+ // put with disableWAL=true VS put with disableWAL=false
+ System.out.println("--> put with disableWAL=true VS put with
disableWAL=false <--");
+ benchMarkHelper(1_000, true, WRITETYPE.PUT);
+ benchMarkHelper(1_000, false, WRITETYPE.PUT);
+
+ benchMarkHelper(10_000, true, WRITETYPE.PUT);
+ benchMarkHelper(10_000, false, WRITETYPE.PUT);
+
+ benchMarkHelper(100_000, true, WRITETYPE.PUT);
+ benchMarkHelper(100_000, false, WRITETYPE.PUT);
+
+ benchMarkHelper(1_000_000, true, WRITETYPE.PUT);
+ benchMarkHelper(1_000_000, false, WRITETYPE.PUT);
+
+ // put with disableWAL=true VS write batch with disableWAL=false
+ System.out.println("--> put with disableWAL=true VS write batch
with disableWAL=false <--");
--- End diff --
replace console output with logging, you can refer to
`RocksDBListStatePerformanceTest.java`
---
[GitHub] flink pull request #5650: [FLINK-8845][state] Introduce RocksDBWriteBatchWra...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/5650#discussion_r174230739
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/test/java/org/apache/flink/contrib/streaming/state/RocksDBWriteBatchWrapperTest.java
---
@@ -0,0 +1,159 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.api.java.tuple.Tuple2;
+
+import org.junit.Assert;
+import org.junit.Ignore;
+import org.junit.Rule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+import org.rocksdb.ColumnFamilyDescriptor;
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.WriteOptions;
+
+import java.util.ArrayList;
+import java.util.List;
+
+/**
+ * Tests to guard {@link RocksDBWriteBatchWrapper}.
+ */
+public class RocksDBWriteBatchWrapperTest {
+
+ @Rule
+ public TemporaryFolder folder = new TemporaryFolder();
+
+ @Test
+ public void basicTest() throws Exception {
+
+ List<Tuple2<byte[], byte[]>> data = new ArrayList<>(1);
+ for (int i = 0; i < 1; ++i) {
+ data.add(new Tuple2<>(("key:" + i).getBytes(),
("value:" + i).getBytes()));
+ }
+
+ try (RocksDB db =
RocksDB.open(folder.newFolder().getAbsolutePath());
+ WriteOptions options = new
WriteOptions().setDisableWAL(true);
+ ColumnFamilyHandle handle = db.createColumnFamily(new
ColumnFamilyDescriptor("test".getBytes()));
+ RocksDBWriteBatchWrapper writeBatchWrapper = new
RocksDBWriteBatchWrapper(db, options, 200)) {
+
+ // insert data
+ for (Tuple2<byte[], byte[]> item : data) {
+ writeBatchWrapper.put(handle, item.f0, item.f1);
+ }
+ writeBatchWrapper.flush();
+
+ // valid result
+ for (Tuple2<byte[], byte[]> item : data) {
+ Assert.assertArrayEquals(item.f1,
db.get(handle, item.f0));
+ }
+ }
+ }
+
+ @Test
+ @Ignore
+ public void benchMark() throws Exception {
--- End diff --
Need to move the benchmark test to
`org.apache.flink.contrib.streaming.state.benchmark` package.
---
[GitHub] flink pull request #5650: [FLINK-8845][state] Introduce RocksDBWriteBatchWra...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/5650#discussion_r174231142
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/test/java/org/apache/flink/contrib/streaming/state/RocksDBWriteBatchWrapperTest.java
---
@@ -0,0 +1,159 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.api.java.tuple.Tuple2;
+
+import org.junit.Assert;
+import org.junit.Ignore;
+import org.junit.Rule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+import org.rocksdb.ColumnFamilyDescriptor;
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.WriteOptions;
+
+import java.util.ArrayList;
+import java.util.List;
+
+/**
+ * Tests to guard {@link RocksDBWriteBatchWrapper}.
+ */
+public class RocksDBWriteBatchWrapperTest {
+
+ @Rule
+ public TemporaryFolder folder = new TemporaryFolder();
+
+ @Test
+ public void basicTest() throws Exception {
+
+ List<Tuple2<byte[], byte[]>> data = new ArrayList<>(1);
+ for (int i = 0; i < 1; ++i) {
+ data.add(new Tuple2<>(("key:" + i).getBytes(),
("value:" + i).getBytes()));
+ }
+
+ try (RocksDB db =
RocksDB.open(folder.newFolder().getAbsolutePath());
+ WriteOptions options = new
WriteOptions().setDisableWAL(true);
+ ColumnFamilyHandle handle = db.createColumnFamily(new
ColumnFamilyDescriptor("test".getBytes()));
+ RocksDBWriteBatchWrapper writeBatchWrapper = new
RocksDBWriteBatchWrapper(db, options, 200)) {
+
+ // insert data
+ for (Tuple2<byte[], byte[]> item : data) {
+ writeBatchWrapper.put(handle, item.f0, item.f1);
+ }
+ writeBatchWrapper.flush();
+
+ // valid result
+ for (Tuple2<byte[], byte[]> item : data) {
+ Assert.assertArrayEquals(item.f1,
db.get(handle, item.f0));
+ }
+ }
+ }
+
+ @Test
+ @Ignore
+ public void benchMark() throws Exception {
+
+ // put with disableWAL=true VS put with disableWAL=false
+ System.out.println("--> put with disableWAL=true VS put with
disableWAL=false <--");
+ benchMarkHelper(1_000, true, WRITETYPE.PUT);
+ benchMarkHelper(1_000, false, WRITETYPE.PUT);
+
+ benchMarkHelper(10_000, true, WRITETYPE.PUT);
+ benchMarkHelper(10_000, false, WRITETYPE.PUT);
+
+ benchMarkHelper(100_000, true, WRITETYPE.PUT);
+ benchMarkHelper(100_000, false, WRITETYPE.PUT);
+
+ benchMarkHelper(1_000_000, true, WRITETYPE.PUT);
+ benchMarkHelper(1_000_000, false, WRITETYPE.PUT);
+
+ // put with disableWAL=true VS write batch with disableWAL=false
+ System.out.println("--> put with disableWAL=true VS write batch
with disableWAL=false <--");
+ benchMarkHelper(1_000, true, WRITETYPE.PUT);
+ benchMarkHelper(1_000, false, WRITETYPE.WRITE_BATCH);
+
+ benchMarkHelper(10_000, true, WRITETYPE.PUT);
+ benchMarkHelper(10_000, false, WRITETYPE.WRITE_BATCH);
+
+ benchMarkHelper(100_000, true, WRITETYPE.PUT);
+ benchMarkHelper(100_000, false, WRITETYPE.WRITE_BATCH);
+
+ benchMarkHelper(1_000_000, true, WRITETYPE.PUT);
+ benchMarkHelper(1_000_000, false, WRITETYPE.WRITE_BATCH);
+
+ // write batch with disableWAL=true VS write batch disableWAL =
true
+ System.out.pri
[GitHub] flink pull request #5650: [FLINK-8845][state] Introduce RocksDBWriteBatchWra...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/5650#discussion_r174231173
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/test/java/org/apache/flink/contrib/streaming/state/RocksDBWriteBatchWrapperTest.java
---
@@ -0,0 +1,159 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.api.java.tuple.Tuple2;
+
+import org.junit.Assert;
+import org.junit.Ignore;
+import org.junit.Rule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+import org.rocksdb.ColumnFamilyDescriptor;
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.WriteOptions;
+
+import java.util.ArrayList;
+import java.util.List;
+
+/**
+ * Tests to guard {@link RocksDBWriteBatchWrapper}.
+ */
+public class RocksDBWriteBatchWrapperTest {
+
+ @Rule
+ public TemporaryFolder folder = new TemporaryFolder();
+
+ @Test
+ public void basicTest() throws Exception {
+
+ List<Tuple2<byte[], byte[]>> data = new ArrayList<>(1);
+ for (int i = 0; i < 1; ++i) {
+ data.add(new Tuple2<>(("key:" + i).getBytes(),
("value:" + i).getBytes()));
+ }
+
+ try (RocksDB db =
RocksDB.open(folder.newFolder().getAbsolutePath());
+ WriteOptions options = new
WriteOptions().setDisableWAL(true);
+ ColumnFamilyHandle handle = db.createColumnFamily(new
ColumnFamilyDescriptor("test".getBytes()));
+ RocksDBWriteBatchWrapper writeBatchWrapper = new
RocksDBWriteBatchWrapper(db, options, 200)) {
+
+ // insert data
+ for (Tuple2<byte[], byte[]> item : data) {
+ writeBatchWrapper.put(handle, item.f0, item.f1);
+ }
+ writeBatchWrapper.flush();
+
+ // valid result
+ for (Tuple2<byte[], byte[]> item : data) {
+ Assert.assertArrayEquals(item.f1,
db.get(handle, item.f0));
+ }
+ }
+ }
+
+ @Test
+ @Ignore
+ public void benchMark() throws Exception {
+
+ // put with disableWAL=true VS put with disableWAL=false
+ System.out.println("--> put with disableWAL=true VS put with
disableWAL=false <--");
+ benchMarkHelper(1_000, true, WRITETYPE.PUT);
+ benchMarkHelper(1_000, false, WRITETYPE.PUT);
+
+ benchMarkHelper(10_000, true, WRITETYPE.PUT);
+ benchMarkHelper(10_000, false, WRITETYPE.PUT);
+
+ benchMarkHelper(100_000, true, WRITETYPE.PUT);
+ benchMarkHelper(100_000, false, WRITETYPE.PUT);
+
+ benchMarkHelper(1_000_000, true, WRITETYPE.PUT);
+ benchMarkHelper(1_000_000, false, WRITETYPE.PUT);
+
+ // put with disableWAL=true VS write batch with disableWAL=false
+ System.out.println("--> put with disableWAL=true VS write batch
with disableWAL=false <--");
+ benchMarkHelper(1_000, true, WRITETYPE.PUT);
+ benchMarkHelper(1_000, false, WRITETYPE.WRITE_BATCH);
+
+ benchMarkHelper(10_000, true, WRITETYPE.PUT);
+ benchMarkHelper(10_000, false, WRITETYPE.WRITE_BATCH);
+
+ benchMarkHelper(100_000, true, WRITETYPE.PUT);
+ benchMarkHelper(100_000, false, WRITETYPE.WRITE_BATCH);
+
+ benchMarkHelper(1_000_000, true, WRITETYPE.PUT);
+ benchMarkHelper(1_000_000, false, WRITETYPE.WRITE_BATCH);
+
+ // write batch with disableWAL=true VS write batch disableWAL =
true
+ System.out.pri
[GitHub] flink issue #5680: [FLINK-8919] Add KeyedProcessFunctionWithCleanupState.
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5680 shall we add a unit test? ---
[GitHub] flink pull request #5677: [hotfix] update doc of InternalTimerService.regist...
GitHub user bowenli86 opened a pull request: https://github.com/apache/flink/pull/5677 [hotfix] update doc of InternalTimerService.registerEventTimeTimer() ## What is the purpose of the change update doc of InternalTimerService.registerEventTimeTimer() ## Brief change log update doc of InternalTimerService.registerEventTimeTimer() ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: none ## Documentation none You can merge this pull request into a Git repository by running: $ git pull https://github.com/bowenli86/flink hotfix Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/5677.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5677 commit 410601674a532f01268acd37c9c043b39d9ae6b1 Author: Bowen Li <bowenli86@...> Date: 2018-03-10T07:35:15Z [hotfix] update doc of InternalTimerService.registerEventTimeTimer() ---
[GitHub] flink issue #5663: [FLINK-8888] [Kinesis Connectors] Update the AWS SDK for ...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5663 Is your testing Flink job both reading from and writing to Kinesis, aka both KCL and KPL are tested? If so, +1 ---
[GitHub] flink issue #5356: [FLINK-8364][state backend] Add iterator() to ListState w...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5356 hmmm I think you are right, this actually might be a non-issue in the first place ---
[GitHub] flink pull request #5365: [FLINK-8515] update RocksDBMapState to replace dep...
Github user bowenli86 closed the pull request at: https://github.com/apache/flink/pull/5365 ---
[GitHub] flink pull request #5650: [FLINK-8845][state] Introduce RocksDBWriteBatchWra...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/5650#discussion_r172935414
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBWriteBatchWrapper.java
---
@@ -0,0 +1,86 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.util.Preconditions;
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+import org.rocksdb.WriteBatch;
+import org.rocksdb.WriteOptions;
+
+import javax.annotation.Nonnull;
+
+/**
+ * A wrapper class to wrap WriteBatch.
+ */
+public class RocksDBWriteBatchWrapper implements AutoCloseable {
+
+ private final static int MIN_CAPACITY = 100;
+ private final static int MAX_CAPACITY = 1;
+
+ private final RocksDB db;
+
+ private final WriteBatch batch;
+
+ private final WriteOptions options;
+
+ private final int capacity;
+
+ private int currentSize;
+
+ public RocksDBWriteBatchWrapper(@Nonnull RocksDB rocksDB,
+
@Nonnull WriteOptions options,
+ int
capacity) {
+
+ Preconditions.checkArgument(capacity >= MIN_CAPACITY &&
capacity <= MAX_CAPACITY,
+ "capacity should at least greater than 100");
+
+ this.db = rocksDB;
+ this.options = options;
+ this.capacity = capacity;
+ this.batch = new WriteBatch(this.capacity);
+ this.currentSize = 0;
+ }
+
+ public void put(ColumnFamilyHandle handle, byte[] key, byte[] value)
throws RocksDBException {
+
+ this.batch.put(handle, key, value);
+
+ if (++currentSize == capacity) {
+ flush();
+ }
+ }
+
+ public void flush() throws RocksDBException {
+ this.db.write(options, batch);
+ batch.clear();
+ currentSize = 0;
+ }
+
+ @Override
+ public void close() throws RocksDBException {
+ if (batch != null) {
--- End diff --
can batch be null?
---
[GitHub] flink pull request #5650: [FLINK-8845][state] Introduce RocksDBWriteBatchWra...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/5650#discussion_r172935214
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBWriteBatchWrapper.java
---
@@ -0,0 +1,86 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.util.Preconditions;
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+import org.rocksdb.WriteBatch;
+import org.rocksdb.WriteOptions;
+
+import javax.annotation.Nonnull;
+
+/**
+ * A wrapper class to wrap WriteBatch.
+ */
+public class RocksDBWriteBatchWrapper implements AutoCloseable {
+
+ private final static int MIN_CAPACITY = 100;
+ private final static int MAX_CAPACITY = 1;
+
+ private final RocksDB db;
+
+ private final WriteBatch batch;
+
+ private final WriteOptions options;
+
+ private final int capacity;
+
+ private int currentSize;
+
+ public RocksDBWriteBatchWrapper(@Nonnull RocksDB rocksDB,
+
@Nonnull WriteOptions options,
+ int
capacity) {
+
+ Preconditions.checkArgument(capacity >= MIN_CAPACITY &&
capacity <= MAX_CAPACITY,
+ "capacity should at least greater than 100");
+
+ this.db = rocksDB;
+ this.options = options;
+ this.capacity = capacity;
+ this.batch = new WriteBatch(this.capacity);
+ this.currentSize = 0;
+ }
+
+ public void put(ColumnFamilyHandle handle, byte[] key, byte[] value)
throws RocksDBException {
--- End diff --
need synchronization on put() and flush()
---
[GitHub] flink pull request #5650: [FLINK-8845][state] Introduce RocksDBWriteBatchWra...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/5650#discussion_r172934683
--- Diff:
flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBWriteBatchWrapper.java
---
@@ -0,0 +1,86 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.contrib.streaming.state;
+
+import org.apache.flink.util.Preconditions;
+import org.rocksdb.ColumnFamilyHandle;
+import org.rocksdb.RocksDB;
+import org.rocksdb.RocksDBException;
+import org.rocksdb.WriteBatch;
+import org.rocksdb.WriteOptions;
+
+import javax.annotation.Nonnull;
+
+/**
+ * A wrapper class to wrap WriteBatch.
+ */
+public class RocksDBWriteBatchWrapper implements AutoCloseable {
+
+ private final static int MIN_CAPACITY = 100;
+ private final static int MAX_CAPACITY = 1;
+
+ private final RocksDB db;
+
+ private final WriteBatch batch;
+
+ private final WriteOptions options;
+
+ private final int capacity;
+
+ private int currentSize;
+
+ public RocksDBWriteBatchWrapper(@Nonnull RocksDB rocksDB,
+
@Nonnull WriteOptions options,
+ int
capacity) {
+
+ Preconditions.checkArgument(capacity >= MIN_CAPACITY &&
capacity <= MAX_CAPACITY,
+ "capacity should at least greater than 100");
--- End diff --
how is the capacity range determined - is it recommended by RocksDB?
the msg should be: "capacity should be between " + MIN + " and " + MAX
---
[GitHub] flink pull request #5649: [FLINK-8873] [DataStream API] [Tests] move unit te...
GitHub user bowenli86 opened a pull request: https://github.com/apache/flink/pull/5649 [FLINK-8873] [DataStream API] [Tests] move unit tests of KeyedStream from DataStreamTest to KeyedStreamTest ## What is the purpose of the change move unit tests of `KeyedStream` from `DataStreamTest` to `KeyedStreamTest`, in order to have a clearer separation ## Brief change log added `KeyedStreamTest.java` and `KeyedStreamTest.scala`, and moved related unit tests to them ## Verifying this change This change is already covered by existing tests, such as *KeyedStreamTest*. ## Does this pull request potentially affect one of the following parts: none ## Documentation none You can merge this pull request into a Git repository by running: $ git pull https://github.com/bowenli86/flink FLINK-8873 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/5649.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5649 commit d4e372fbb21edc0507df461aa7f47a9168350a1a Author: Bowen Li <bowenli86@...> Date: 2018-03-05T19:52:37Z [FLINK-8873] move unit tests of KeyedStream from DataStreamTest to KeyedStreamTest ---
[GitHub] flink issue #5501: [FLINK-6053][metrics] Add new Number-/StringGauge metric ...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5501 LGTM, +1 on merging to 1.6.0 ---
[GitHub] flink issue #5481: [FLINK-8560] Access to the current key in ProcessFunction...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5481 @kl0u @aljoscha I added the scala example, and I believe the only build failure in Travis is irrelevant ---
[GitHub] flink pull request #5482: [FLINK-8480][DataStream] Add Java API for timeboun...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/5482#discussion_r172306197
--- Diff:
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/functions/TimeBoundedStreamJoinOperator.java
---
@@ -0,0 +1,480 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.streaming.api.functions;
+
+import org.apache.flink.annotation.Internal;
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.api.common.state.MapState;
+import org.apache.flink.api.common.state.MapStateDescriptor;
+import org.apache.flink.api.common.typeutils.TypeSerializer;
+import org.apache.flink.api.common.typeutils.base.BooleanSerializer;
+import org.apache.flink.api.common.typeutils.base.ListSerializer;
+import org.apache.flink.api.common.typeutils.base.LongSerializer;
+import org.apache.flink.api.java.tuple.Tuple2;
+import org.apache.flink.api.java.tuple.Tuple3;
+import org.apache.flink.api.java.typeutils.runtime.TupleSerializer;
+import org.apache.flink.runtime.state.StateInitializationContext;
+import org.apache.flink.runtime.state.VoidNamespace;
+import org.apache.flink.runtime.state.VoidNamespaceSerializer;
+import org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator;
+import org.apache.flink.streaming.api.operators.InternalTimer;
+import org.apache.flink.streaming.api.operators.InternalTimerService;
+import org.apache.flink.streaming.api.operators.TimestampedCollector;
+import org.apache.flink.streaming.api.operators.Triggerable;
+import org.apache.flink.streaming.api.operators.TwoInputStreamOperator;
+import org.apache.flink.streaming.api.watermark.Watermark;
+import org.apache.flink.streaming.runtime.streamrecord.StreamRecord;
+import org.apache.flink.util.OutputTag;
+import org.apache.flink.util.Preconditions;
+
+import java.util.ArrayList;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Map;
+
+/**
+ * A TwoInputStreamOperator to execute time-bounded stream inner joins.
+ *
+ * By using a configurable lower and upper bound this operator will
emit exactly those pairs
+ * (T1, T2) where t2.ts â [T1.ts + lowerBound, T1.ts + upperBound]. Both
the lower and the
+ * upper bound can be configured to be either inclusive or exclusive.
+ *
+ * As soon as elements are joined they are passed to a user-defined
{@link TimeBoundedJoinFunction},
+ * as a {@link Tuple2}, with f0 being the left element and f1 being the
right element
+ *
+ * The basic idea of this implementation is as follows: Whenever we
receive an element at
+ * {@link #processElement1(StreamRecord)} (a.k.a. the left side), we add
it to the left buffer.
+ * We then check the right buffer to see whether there are any elements
that can be joined. If
+ * there are, they are joined and passed to a user-defined {@link
TimeBoundedJoinFunction}.
+ * The same happens the other way around when receiving an element on the
right side.
+ *
+ * In some cases the watermark needs to be delayed. This for example
can happen if
+ * if t2.ts â [t1.ts + 1, t1.ts + 2] and elements from t1 arrive earlier
than elements from t2 and
+ * therefore get added to the left buffer. When an element now arrives on
the right side, the
+ * watermark might have already progressed. The right element now gets
joined with an
+ * older element from the left side, where the timestamp of the left
element is lower than the
+ * current watermark, which would make this element late. This can be
avoided by holding back the
+ * watermarks.
+ *
+ * The left and right buffers are cleared from unused values
periodically
+ * (triggered by watermarks) in order not to grow infinitely.
+ *
+ *
+ * @param The type of the elements in the left stream
+ * @param The type of the elements in the right stream
+ * @param The output type created by the u
[GitHub] flink pull request #5482: [FLINK-8480][DataStream] Add Java API for timeboun...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/5482#discussion_r172303424
--- Diff:
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/datastream/JoinedStreams.java
---
@@ -137,6 +158,151 @@ public EqualTo equalTo(KeySelector<T2, KEY>
keySelector) {
public WithWindow<T1, T2, KEY, W>
window(WindowAssigner, W> assigner) {
return new WithWindow<>(input1, input2,
keySelector1, keySelector2, keyType, assigner, null, null);
}
+
+ /**
+* Specifies the time boundaries over which the join
operation works, so that
+* leftElement.timestamp + lowerBound <=
rightElement.timestamp <= leftElement.timestamp + upperBound
+* By default both the lower and the upper bound are
inclusive. This can be configured
+* with {@link
TimeBounded#lowerBoundExclusive(boolean)} and
+* {@link TimeBounded#upperBoundExclusive(boolean)}
+*
+* @param lowerBound The lower bound. Needs to be
smaller than or equal to the upperBound
+* @param upperBound The upper bound. Needs to be
bigger than or equal to the lowerBound
+*/
+ public TimeBounded<T1, T2, KEY> between(Time
lowerBound, Time upperBound) {
+
+ TimeCharacteristic timeCharacteristic =
+
input1.getExecutionEnvironment().getStreamTimeCharacteristic();
+
+ if (timeCharacteristic !=
TimeCharacteristic.EventTime) {
+ throw new
RuntimeException("Time-bounded stream joins are only supported in event time");
+ }
+
+ checkNotNull(lowerBound, "A lower bound needs
to be provided for a time-bounded join");
+ checkNotNull(upperBound, "An upper bound needs
to be provided for a time-bounded join");
+ return new TimeBounded<>(
+ input1,
+ input2,
+ lowerBound.toMilliseconds(),
+ upperBound.toMilliseconds(),
+ true,
+ true,
+ keySelector1,
+ keySelector2
+ );
+ }
+ }
+ }
+
+ /**
+* Joined streams that have keys for both sides as well as the time
boundaries over which
+* elements should be joined defined.
+*
+* @param Input type of elements from the first stream
+* @param Input type of elements from the second stream
+* @param The type of the key
+*/
+ public static class TimeBounded<IN1, IN2, KEY> {
+
+ private static final String TIMEBOUNDED_JOIN_FUNC_NAME =
"TimeBoundedJoin";
+
+ private final DataStream left;
+ private final DataStream right;
+
+ private final long lowerBound;
+ private final long upperBound;
+
+ private final KeySelector<IN1, KEY> keySelector1;
+ private final KeySelector<IN2, KEY> keySelector2;
+
+ private boolean lowerBoundInclusive;
+ private boolean upperBoundInclusive;
+
+ public TimeBounded(
+ DataStream left,
+ DataStream right,
+ long lowerBound,
+ long upperBound,
+ boolean lowerBoundInclusive,
+ boolean upperBoundInclusive,
+ KeySelector<IN1, KEY> keySelector1,
+ KeySelector<IN2, KEY> keySelector2) {
+
+ this.left = Preconditions.checkNotNull(left);
+ this.right = Preconditions.checkNotNull(right);
+
+ this.lowerBound = lowerBound;
+ this.upperBound = upperBound;
+
+ this.lowerBoundInclusive = lowerBoundInclusive;
+ this.upperBoundInclusive = upperBoundInclusive;
+
+ this.keySelector1 =
Preconditions.checkNotNull(keySelector1);
+ this.keySelector2 =
Preconditions.checkNotNull(keySelector2);
+ }
+
+ /**
+* Configure whether the upper bound shoul
[GitHub] flink pull request #5482: [FLINK-8480][DataStream] Add Java API for timeboun...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/5482#discussion_r172302147
--- Diff:
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/datastream/JoinedStreams.java
---
@@ -137,6 +158,151 @@ public EqualTo equalTo(KeySelector<T2, KEY>
keySelector) {
public WithWindow<T1, T2, KEY, W>
window(WindowAssigner, W> assigner) {
return new WithWindow<>(input1, input2,
keySelector1, keySelector2, keyType, assigner, null, null);
}
+
+ /**
+* Specifies the time boundaries over which the join
operation works, so that
+* leftElement.timestamp + lowerBound <=
rightElement.timestamp <= leftElement.timestamp + upperBound
+* By default both the lower and the upper bound are
inclusive. This can be configured
+* with {@link
TimeBounded#lowerBoundExclusive(boolean)} and
+* {@link TimeBounded#upperBoundExclusive(boolean)}
+*
+* @param lowerBound The lower bound. Needs to be
smaller than or equal to the upperBound
+* @param upperBound The upper bound. Needs to be
bigger than or equal to the lowerBound
+*/
+ public TimeBounded<T1, T2, KEY> between(Time
lowerBound, Time upperBound) {
+
+ TimeCharacteristic timeCharacteristic =
+
input1.getExecutionEnvironment().getStreamTimeCharacteristic();
+
+ if (timeCharacteristic !=
TimeCharacteristic.EventTime) {
+ throw new
RuntimeException("Time-bounded stream joins are only supported in event time");
--- End diff --
should use `IllegalStateException`. or even better, shall we create a Flink
specific exception?
---
[GitHub] flink pull request #5482: [FLINK-8480][DataStream] Add Java API for timeboun...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/5482#discussion_r172302583
--- Diff:
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/datastream/JoinedStreams.java
---
@@ -137,6 +158,151 @@ public EqualTo equalTo(KeySelector<T2, KEY>
keySelector) {
public WithWindow<T1, T2, KEY, W>
window(WindowAssigner, W> assigner) {
return new WithWindow<>(input1, input2,
keySelector1, keySelector2, keyType, assigner, null, null);
}
+
+ /**
+* Specifies the time boundaries over which the join
operation works, so that
+* leftElement.timestamp + lowerBound <=
rightElement.timestamp <= leftElement.timestamp + upperBound
+* By default both the lower and the upper bound are
inclusive. This can be configured
+* with {@link
TimeBounded#lowerBoundExclusive(boolean)} and
+* {@link TimeBounded#upperBoundExclusive(boolean)}
+*
+* @param lowerBound The lower bound. Needs to be
smaller than or equal to the upperBound
+* @param upperBound The upper bound. Needs to be
bigger than or equal to the lowerBound
+*/
+ public TimeBounded<T1, T2, KEY> between(Time
lowerBound, Time upperBound) {
+
+ TimeCharacteristic timeCharacteristic =
+
input1.getExecutionEnvironment().getStreamTimeCharacteristic();
+
+ if (timeCharacteristic !=
TimeCharacteristic.EventTime) {
+ throw new
RuntimeException("Time-bounded stream joins are only supported in event time");
+ }
+
+ checkNotNull(lowerBound, "A lower bound needs
to be provided for a time-bounded join");
+ checkNotNull(upperBound, "An upper bound needs
to be provided for a time-bounded join");
+ return new TimeBounded<>(
+ input1,
+ input2,
+ lowerBound.toMilliseconds(),
+ upperBound.toMilliseconds(),
+ true,
+ true,
+ keySelector1,
+ keySelector2
+ );
+ }
+ }
+ }
+
+ /**
+* Joined streams that have keys for both sides as well as the time
boundaries over which
+* elements should be joined defined.
+*
+* @param Input type of elements from the first stream
+* @param Input type of elements from the second stream
+* @param The type of the key
+*/
+ public static class TimeBounded<IN1, IN2, KEY> {
+
+ private static final String TIMEBOUNDED_JOIN_FUNC_NAME =
"TimeBoundedJoin";
--- End diff --
hmm... this might be not very relevant, but I'd prefer a single config
class that holds all function's names, rather than having them scattered all
over the code base.
---
[GitHub] flink pull request #5482: [FLINK-8480][DataStream] Add Java API for timeboun...
Github user bowenli86 commented on a diff in the pull request: https://github.com/apache/flink/pull/5482#discussion_r172303671 --- Diff: flink-streaming-java/src/main/java/org/apache/flink/streaming/api/functions/TimeBoundedStreamJoinOperator.java --- @@ -0,0 +1,480 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.flink.streaming.api.functions; + +import org.apache.flink.annotation.Internal; +import org.apache.flink.annotation.VisibleForTesting; +import org.apache.flink.api.common.state.MapState; +import org.apache.flink.api.common.state.MapStateDescriptor; +import org.apache.flink.api.common.typeutils.TypeSerializer; +import org.apache.flink.api.common.typeutils.base.BooleanSerializer; +import org.apache.flink.api.common.typeutils.base.ListSerializer; +import org.apache.flink.api.common.typeutils.base.LongSerializer; +import org.apache.flink.api.java.tuple.Tuple2; +import org.apache.flink.api.java.tuple.Tuple3; +import org.apache.flink.api.java.typeutils.runtime.TupleSerializer; +import org.apache.flink.runtime.state.StateInitializationContext; +import org.apache.flink.runtime.state.VoidNamespace; +import org.apache.flink.runtime.state.VoidNamespaceSerializer; +import org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator; +import org.apache.flink.streaming.api.operators.InternalTimer; +import org.apache.flink.streaming.api.operators.InternalTimerService; +import org.apache.flink.streaming.api.operators.TimestampedCollector; +import org.apache.flink.streaming.api.operators.Triggerable; +import org.apache.flink.streaming.api.operators.TwoInputStreamOperator; +import org.apache.flink.streaming.api.watermark.Watermark; +import org.apache.flink.streaming.runtime.streamrecord.StreamRecord; +import org.apache.flink.util.OutputTag; +import org.apache.flink.util.Preconditions; + +import java.util.ArrayList; +import java.util.Iterator; +import java.util.List; +import java.util.Map; + +/** + * A TwoInputStreamOperator to execute time-bounded stream inner joins. + * + * By using a configurable lower and upper bound this operator will emit exactly those pairs + * (T1, T2) where t2.ts â [T1.ts + lowerBound, T1.ts + upperBound]. Both the lower and the + * upper bound can be configured to be either inclusive or exclusive. --- End diff -- bound**s** ---
[GitHub] flink issue #5616: [FLINK-8828] [stream, dataset, scala] Introduce collect m...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5616 need to add to java API as well ---
[GitHub] flink issue #5481: [FLINK-8560] Access to the current key in ProcessFunction...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5481 @kl0u I added the comments for `@deprecated` in the javadoc. Let me know if you can merge the two related PRs. Thanks ---
[GitHub] flink issue #5500: [FLINK-8667] expose key in KeyedBroadcastProcessFunction#...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5500 @kl0u @aljoscha I've updated this PR, and its build is green ---
[GitHub] flink issue #5500: [FLINK-8667] expose key in KeyedBroadcastProcessFunction#...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5500 @tillrohrmann @kl0u Thanks for reviewing, guys As @pnowojski mentioned, we three decided to expose timer keys in `ProcessFunction` in [FLINK-8560](https://github.com/apache/flink/pull/5481). Exposing timer keys in `KeyedBroadcastProcessFunction` extends that design. I think we should get this PR into 1.5.0 so we don't need to do the [complicated refactoring for FLINK-8560](https://github.com/apache/flink/pull/5481) to support backward compatibility ---
[GitHub] flink issue #5500: [FLINK-8667] expose key in KeyedBroadcastProcessFunction#...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5500 Hi @aljoscha , can you take a look? ---
[GitHub] flink issue #5481: [FLINK-8560] Access to the current key in ProcessFunction...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5481 Thanks for the review and suggestions. And your comment on `DataStream#process(KeyedProcessFunction)` makes sense, I've removed it. (btw, I feel https://github.com/apache/flink/pull/5500 is more urgent that this PR. Can you take it look at that one?) ---
[GitHub] flink issue #5481: [FLINK-8560] Access to the current key in ProcessFunction...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5481 cc @pnowojski @aljoscha ---
[GitHub] flink issue #5522: [FLINK-8710] [YARN] AbstractYarnClusterDescriptor doesn't...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5522 cc @tillrohrmann ---
[GitHub] flink issue #5500: [FLINK-8667] expose key in KeyedBroadcastProcessFunction#...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5500 cc @pnowojski @aljoscha ---
[GitHub] flink pull request #5537: [FLINK-8719] add module description for flink-cont...
GitHub user bowenli86 opened a pull request: https://github.com/apache/flink/pull/5537 [FLINK-8719] add module description for flink-contrib to clarify its purpose ## What is the purpose of the change flink-contrib currently doesn't have any clarification or description of its purpose, which confuses lots of developers. Adding clarification and module description ## Brief change log Adding clarification and module description which I borrowed from the PR description of https://github.com/apache/flink/pull/5523 ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: none ## Documentation none You can merge this pull request into a Git repository by running: $ git pull https://github.com/bowenli86/flink FLINK-8719 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/5537.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5537 commit aecfcdd6e776f2b885f4cb5288bcb1b27d4b23cd Author: Bowen Li <bowenli86@...> Date: 2018-02-20T19:04:43Z [FLINK-8719] add module description for flink-contrib to clarify its purpose ---
[GitHub] flink issue #5500: [FLINK-8667] expose key in KeyedBroadcastProcessFunction#...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5500 a irrelavent flaky unit test caused the error in travis build, and I've filed [FLINK-8709](https://issues.apache.org/jira/browse/FLINK-8709) for it ---
[GitHub] flink issue #5522: [hotfix] hotfix for AbstractYarnClusterDescriptor
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5522 the failure in travis build is irrelevant ---
[GitHub] flink pull request #5522: [hotfix] [javadoc] fix wrong javadoc in AbstractYa...
GitHub user bowenli86 opened a pull request: https://github.com/apache/flink/pull/5522 [hotfix] [javadoc] fix wrong javadoc in AbstractYarnClusterDescriptor ## What is the purpose of the change hotfix of javadoc in AbstractYarnClusterDescriptor ## Brief change log hotfix of javadoc in AbstractYarnClusterDescriptor ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: none ## Documentation none You can merge this pull request into a Git repository by running: $ git pull https://github.com/bowenli86/flink hotfix Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/5522.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5522 commit ae112511cf41931e8010b5e0607714ce02f5cc2f Author: Bowen Li <bowenli86@...> Date: 2018-02-19T08:04:54Z fix wrong javadoc ---
[GitHub] flink issue #5500: [FLINK-8667] expose key in KeyedBroadcastProcessFunction#...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5500 @pnowojski @aljoscha I updated the code. Hopefully we can make this into 1.5.0! Thanks! ---
[GitHub] flink issue #5501: [FLINK-6053][metrics] Add new Number-/StringGauge metric ...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5501 LGTM generally. I still feel having all the `instanceof` in `notifyOfAddedMetric` and `notifyOfRemovedMetric` is a bit inelegant. I'm fine with it since there'll (hopefully) be only a limited number of metric types, so the `instanceof` clauses won't grow insanely. ---
[GitHub] flink pull request #5239: [FLINK-8360] Implement task-local state recovery
Github user bowenli86 commented on a diff in the pull request: https://github.com/apache/flink/pull/5239#discussion_r168891314 --- Diff: docs/ops/state/large_state_tuning.md --- @@ -234,4 +234,97 @@ Compression can be activated through the `ExecutionConfig`: **Notice:** The compression option has no impact on incremental snapshots, because they are using RocksDB's internal format which is always using snappy compression out of the box. +## Task-Local Recovery + +### Motivation + +In Flink's checkpointing, each task produces a snapshot of its state that is then written to a distributed store. Each task acknowledges +a successful write of the state to the job manager by sending a handle that describes the location of the state in the distributed store. +The job manager, in turn, collects the handles from all tasks and bundles them into a checkpoint object. + +In case of recovery, the job manager opens the latest checkpoint object and sends the handles back to the corresponding tasks, which can +then restore their state from the distributed storage. Using a distributed storage to store state has two important advantages. First, the storage +is fault tolerant and second, all state in the distributed store is accessible to all nodes and can be easily redistributed (e.g. for rescaling). + +However, using a remote distributed store has also one big disadvantage: all tasks must read their state from a remote location, over the network. +In many scenarios, recovery could reschedule failed tasks to the same task manager as in the previous run (of course there are exceptions like machine +failures), but we still have to read remote state. This can result in *long recovery times for large states*, even if there was only a small failure on +a single machine. + +### Approach + +Task-local state recovery targets exactly this problem of long recovery times and the main idea is the following: for every checkpoint, we do not +only write task states to the distributed storage, but also keep *a secondary copy of the state snapshot in a storage that is local to the task* +(e.g. on local disk or in memory). Notice that the primary store for snapshots must still be the distributed store, because local storage does not +ensure durability under node failures abd also does not provide access for other nodes to redistribute state, this functionality still requires the +primary copy. + +However, for each task that can be rescheduled to the previous location for recovery, we can restore state from the secondary, local +copy and avoid the costs of reading the state remotely. Given that *many failures are not node failures and node failures typically only affect one +or very few nodes at a time*, it is very likely that in a recovery most tasks can return to their previous location and find their local state intact. +This is what makes local recovery effective in reducing recovery time. + +Please note that this can come at some additional costs per checkpoint for creating and storing the secondary local state copy, depending on the +chosen state backend and checkpointing strategy. For example, in most cases the implementation will simply duplicate the writes to the distributed +store to a local file. + + + +### Relationship of primary (distributed store) and secondary (task-local) state snapshots + +Task-local state is always considered a secondary copy, the ground truth of the checkpoint state is the primary copy in the distributed store. This +has implications for problems with local state during checkpointing and recovery: + +- For checkpointing, the *primary copy must be successful* and a failure to produce the *secondary, local copy will not fail* the checkpoint. A checkpoint +will fail if the primary copy could not be created, even if the secondary copy was successfully created. + +- Only the primary copy is acknowledged and managed by the job manager, secondary copies are owned by task managers and their life cycle can be +independent from their primary copy. For example, it is possible to retain a history of the 3 latest checkpoints as primary copies and only keep +the task-local state of the latest checkpoint. + +- For recovery, Flink will always *attempt to restore from task-local state first*, if a matching secondary copy is available. If any problem occurs during +the recovery from the secondary copy, Flink will *transparently retry to recovery the task from the primary copy*. Recovery only fails, if primary +and the (optional) secondary copy failed. In this case, depending on the configuration Flink could still fall back to an older checkpoint. + +- It is possible that the task-local copy contains only parts of the full task state (e.g. exception
[GitHub] flink pull request #5500: [FLINK-8667] expose key in KeyedBroadcastProcessFu...
Github user bowenli86 commented on a diff in the pull request:
https://github.com/apache/flink/pull/5500#discussion_r168855562
--- Diff:
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/operators/co/CoBroadcastWithKeyedOperator.java
---
@@ -324,6 +324,11 @@ public TimeDomain timeDomain() {
return timeDomain;
}
+ @Override
+ public KS getCurrentKey() {
--- End diff --
added
---
[GitHub] flink issue #5500: [FLINK-8667] expose key in KeyedBroadcastProcessFunction#...
Github user bowenli86 commented on the issue: https://github.com/apache/flink/pull/5500 cc @aljoscha @pnowojski ---