[GitHub] [spark] HeartSaVioR commented on a diff in pull request #38503: [SPARK-40940] Remove Multi-stateful operator checkers for streaming queries.
HeartSaVioR commented on code in PR #38503:
URL: https://github.com/apache/spark/pull/38503#discussion_r1023563189
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/UnsupportedOperationChecker.scala:
##
@@ -42,40 +43,101 @@ object UnsupportedOperationChecker extends Logging {
}
/**
- * Checks for possible correctness issue in chained stateful operators. The
behavior is
- * controlled by SQL config
`spark.sql.streaming.statefulOperator.checkCorrectness.enabled`.
- * Once it is enabled, an analysis exception will be thrown. Otherwise,
Spark will just
- * print a warning message.
+ * Checks if the expression has a event time column
+ * @param exp the expression to be checked
+ * @return true if it is a event time column.
*/
- def checkStreamingQueryGlobalWatermarkLimit(
- plan: LogicalPlan,
- outputMode: OutputMode): Unit = {
-def isStatefulOperationPossiblyEmitLateRows(p: LogicalPlan): Boolean = p
match {
- case s: Aggregate
-if s.isStreaming && outputMode == InternalOutputModes.Append => true
- case Join(left, right, joinType, _, _)
-if left.isStreaming && right.isStreaming && joinType != Inner => true
- case f: FlatMapGroupsWithState
-if f.isStreaming && f.outputMode == OutputMode.Append() => true
- case _ => false
+ private def hasEventTimeCol(exp: Expression): Boolean = exp.exists {
+case a: AttributeReference =>
a.metadata.contains(EventTimeWatermark.delayKey)
+case _ => false
+ }
+
+ /**
+ * Checks if the expression contains a range comparison, in which
+ * either side of the comparison is an event-time column. This is used for
checking
+ * stream-stream time interval join.
+ * @param e the expression to be checked
+ * @return true if there is a time-interval join.
+ */
+ private def hasRangeExprAgainstEventTimeCol(e: Expression): Boolean = {
+def hasEventTimeColBinaryComp(neq: Expression): Boolean = {
+ val exp = neq.asInstanceOf[BinaryComparison]
+ hasEventTimeCol(exp.left) || hasEventTimeCol(exp.right)
}
-def isStatefulOperation(p: LogicalPlan): Boolean = p match {
- case s: Aggregate if s.isStreaming => true
- case _ @ Join(left, right, _, _, _) if left.isStreaming &&
right.isStreaming => true
- case f: FlatMapGroupsWithState if f.isStreaming => true
- case f: FlatMapGroupsInPandasWithState if f.isStreaming => true
- case d: Deduplicate if d.isStreaming => true
+e.exists {
+ case neq @ (_: LessThanOrEqual | _: LessThan | _: GreaterThanOrEqual |
_: GreaterThan) =>
+hasEventTimeColBinaryComp(neq)
case _ => false
}
+ }
-val failWhenDetected = SQLConf.get.statefulOperatorCorrectnessCheckEnabled
+ /**
+ * This method, combined with isStatefulOperationPossiblyEmitLateRows,
determines all disallowed
+ * behaviors in multiple stateful operators.
+ * Concretely, All conditions defined below cannot be followed by any
streaming stateful
+ * operator as defined in isStatefulOperationPossiblyEmitLateRows.
+ * @param p logical plan to be checked
+ * @param outputMode query output mode
+ * @return true if it is not allowed when followed by any streaming stateful
+ * operator as defined in isStatefulOperationPossiblyEmitLateRows.
+ */
+ private def ifCannotBeFollowedByStatefulOperation(
+ p: LogicalPlan, outputMode: OutputMode): Boolean = p match {
+case ExtractEquiJoinKeys(_, _, _, otherCondition, _, left, right, _) =>
+ left.isStreaming && right.isStreaming &&
+otherCondition.isDefined &&
hasRangeExprAgainstEventTimeCol(otherCondition.get)
+// FlatMapGroupsWithState configured with event time
+case f @ FlatMapGroupsWithState(_, _, _, _, _, _, _, _, _, timeout, _, _,
_, _, _, _)
+ if f.isStreaming && timeout == GroupStateTimeout.EventTimeTimeout => true
+case p @ FlatMapGroupsInPandasWithState(_, _, _, _, _, timeout, _)
+ if p.isStreaming && timeout == GroupStateTimeout.EventTimeTimeout => true
+case a: Aggregate if a.isStreaming && outputMode !=
InternalOutputModes.Append => true
+// Since the Distinct node will be replaced to Aggregate in the optimizer
rule
+// [[ReplaceDistinctWithAggregate]], here we also need to check all
Distinct node by
+// assuming it as Aggregate.
+case d @ Distinct(_: LogicalPlan) if d.isStreaming
+ && outputMode != InternalOutputModes.Append => true
+case _ => false
+ }
+ /**
+ * This method is only used with ifCannotBeFollowedByStatefulOperation.
+ * As can tell from the name, it doesn't contain ALL streaming stateful
operations,
+ * only the stateful operations that are possible to emit late rows.
+ * for example, a Deduplicate without a event time column is still a
stateful operation
+ * but of less interested because it won't emit late records because of
watermark.
+ * @param p the logical plan to be checked
+ * @return true
[GitHub] [spark] dongjoon-hyun commented on pull request #38352: [SPARK-40801][BUILD][3.2] Upgrade `Apache commons-text` to 1.10
dongjoon-hyun commented on PR #38352: URL: https://github.com/apache/spark/pull/38352#issuecomment-1316546164 +1 for @sunchao 's comment. To @bsikander , it would be great if you can participate [[VOTE] Release Spark 3.2.3 (RC1)](https://lists.apache.org/thread/gh2oktrndxopqnyxbsvp2p0k6jk1n9fs). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a diff in pull request #38503: [SPARK-40940] Remove Multi-stateful operator checkers for streaming queries.
HeartSaVioR commented on code in PR #38503:
URL: https://github.com/apache/spark/pull/38503#discussion_r1023563189
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/UnsupportedOperationChecker.scala:
##
@@ -42,40 +43,101 @@ object UnsupportedOperationChecker extends Logging {
}
/**
- * Checks for possible correctness issue in chained stateful operators. The
behavior is
- * controlled by SQL config
`spark.sql.streaming.statefulOperator.checkCorrectness.enabled`.
- * Once it is enabled, an analysis exception will be thrown. Otherwise,
Spark will just
- * print a warning message.
+ * Checks if the expression has a event time column
+ * @param exp the expression to be checked
+ * @return true if it is a event time column.
*/
- def checkStreamingQueryGlobalWatermarkLimit(
- plan: LogicalPlan,
- outputMode: OutputMode): Unit = {
-def isStatefulOperationPossiblyEmitLateRows(p: LogicalPlan): Boolean = p
match {
- case s: Aggregate
-if s.isStreaming && outputMode == InternalOutputModes.Append => true
- case Join(left, right, joinType, _, _)
-if left.isStreaming && right.isStreaming && joinType != Inner => true
- case f: FlatMapGroupsWithState
-if f.isStreaming && f.outputMode == OutputMode.Append() => true
- case _ => false
+ private def hasEventTimeCol(exp: Expression): Boolean = exp.exists {
+case a: AttributeReference =>
a.metadata.contains(EventTimeWatermark.delayKey)
+case _ => false
+ }
+
+ /**
+ * Checks if the expression contains a range comparison, in which
+ * either side of the comparison is an event-time column. This is used for
checking
+ * stream-stream time interval join.
+ * @param e the expression to be checked
+ * @return true if there is a time-interval join.
+ */
+ private def hasRangeExprAgainstEventTimeCol(e: Expression): Boolean = {
+def hasEventTimeColBinaryComp(neq: Expression): Boolean = {
+ val exp = neq.asInstanceOf[BinaryComparison]
+ hasEventTimeCol(exp.left) || hasEventTimeCol(exp.right)
}
-def isStatefulOperation(p: LogicalPlan): Boolean = p match {
- case s: Aggregate if s.isStreaming => true
- case _ @ Join(left, right, _, _, _) if left.isStreaming &&
right.isStreaming => true
- case f: FlatMapGroupsWithState if f.isStreaming => true
- case f: FlatMapGroupsInPandasWithState if f.isStreaming => true
- case d: Deduplicate if d.isStreaming => true
+e.exists {
+ case neq @ (_: LessThanOrEqual | _: LessThan | _: GreaterThanOrEqual |
_: GreaterThan) =>
+hasEventTimeColBinaryComp(neq)
case _ => false
}
+ }
-val failWhenDetected = SQLConf.get.statefulOperatorCorrectnessCheckEnabled
+ /**
+ * This method, combined with isStatefulOperationPossiblyEmitLateRows,
determines all disallowed
+ * behaviors in multiple stateful operators.
+ * Concretely, All conditions defined below cannot be followed by any
streaming stateful
+ * operator as defined in isStatefulOperationPossiblyEmitLateRows.
+ * @param p logical plan to be checked
+ * @param outputMode query output mode
+ * @return true if it is not allowed when followed by any streaming stateful
+ * operator as defined in isStatefulOperationPossiblyEmitLateRows.
+ */
+ private def ifCannotBeFollowedByStatefulOperation(
+ p: LogicalPlan, outputMode: OutputMode): Boolean = p match {
+case ExtractEquiJoinKeys(_, _, _, otherCondition, _, left, right, _) =>
+ left.isStreaming && right.isStreaming &&
+otherCondition.isDefined &&
hasRangeExprAgainstEventTimeCol(otherCondition.get)
+// FlatMapGroupsWithState configured with event time
+case f @ FlatMapGroupsWithState(_, _, _, _, _, _, _, _, _, timeout, _, _,
_, _, _, _)
+ if f.isStreaming && timeout == GroupStateTimeout.EventTimeTimeout => true
+case p @ FlatMapGroupsInPandasWithState(_, _, _, _, _, timeout, _)
+ if p.isStreaming && timeout == GroupStateTimeout.EventTimeTimeout => true
+case a: Aggregate if a.isStreaming && outputMode !=
InternalOutputModes.Append => true
+// Since the Distinct node will be replaced to Aggregate in the optimizer
rule
+// [[ReplaceDistinctWithAggregate]], here we also need to check all
Distinct node by
+// assuming it as Aggregate.
+case d @ Distinct(_: LogicalPlan) if d.isStreaming
+ && outputMode != InternalOutputModes.Append => true
+case _ => false
+ }
+ /**
+ * This method is only used with ifCannotBeFollowedByStatefulOperation.
+ * As can tell from the name, it doesn't contain ALL streaming stateful
operations,
+ * only the stateful operations that are possible to emit late rows.
+ * for example, a Deduplicate without a event time column is still a
stateful operation
+ * but of less interested because it won't emit late records because of
watermark.
+ * @param p the logical plan to be checked
+ * @return true
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #38651: [SPARK-41136][K8S] Shorten graceful shutdown time of ExecutorPodsSnapshotsStoreImpl to prevent blocking shutdown process
dongjoon-hyun commented on code in PR #38651: URL: https://github.com/apache/spark/pull/38651#discussion_r1023621416 ## resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/KubernetesClusterManager.scala: ## @@ -103,7 +103,7 @@ private[spark] class KubernetesClusterManager extends ExternalClusterManager wit val subscribersExecutor = ThreadUtils .newDaemonThreadPoolScheduledExecutor( "kubernetes-executor-snapshots-subscribers", 2) -val snapshotsStore = new ExecutorPodsSnapshotsStoreImpl(subscribersExecutor) +val snapshotsStore = new ExecutorPodsSnapshotsStoreImpl(sc.conf, subscribersExecutor) Review Comment: BTW, it seems that we don't need to hand over the whole `SparkConf` here. What we need is only `sc.conf.get(KUBERNETES_EXECUTOR_SNAPSHOTS_SUBSCRIBERS_GRACE_PERIOD)`, isnt' it? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #38651: [SPARK-41136][K8S] Shorten graceful shutdown time of ExecutorPodsSnapshotsStoreImpl to prevent blocking shutdown process
dongjoon-hyun commented on code in PR #38651: URL: https://github.com/apache/spark/pull/38651#discussion_r1023621416 ## resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/KubernetesClusterManager.scala: ## @@ -103,7 +103,7 @@ private[spark] class KubernetesClusterManager extends ExternalClusterManager wit val subscribersExecutor = ThreadUtils .newDaemonThreadPoolScheduledExecutor( "kubernetes-executor-snapshots-subscribers", 2) -val snapshotsStore = new ExecutorPodsSnapshotsStoreImpl(subscribersExecutor) +val snapshotsStore = new ExecutorPodsSnapshotsStoreImpl(sc.conf, subscribersExecutor) Review Comment: BTW, it seems that we don't need to hand over the whole `SparkConf` here. What we need is only `conf.get(KUBERNETES_EXECUTOR_SNAPSHOTS_SUBSCRIBERS_GRACE_PERIOD)`, isnt' it? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #38651: [SPARK-41136][K8S] Shorten graceful shutdown time of ExecutorPodsSnapshotsStoreImpl to prevent blocking shutdown process
dongjoon-hyun commented on code in PR #38651:
URL: https://github.com/apache/spark/pull/38651#discussion_r1023614721
##
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsSnapshotsStoreImpl.scala:
##
@@ -57,10 +60,22 @@ import org.apache.spark.util.ThreadUtils
* The subscriber notification callback is guaranteed to be called from a
single thread at a time.
*/
private[spark] class ExecutorPodsSnapshotsStoreImpl(
+conf: SparkConf,
subscribersExecutor: ScheduledExecutorService,
clock: Clock = new SystemClock)
extends ExecutorPodsSnapshotsStore with Logging {
+ private[spark] def this(
+ subscribersExecutor: ScheduledExecutorService) = {
+this(new SparkConf, subscribersExecutor, new SystemClock)
+ }
+
+ private[spark] def this(
+ subscribersExecutor: ScheduledExecutorService,
+ clock: Clock) = {
+this(new SparkConf, subscribersExecutor, clock)
+ }
Review Comment:
Oh, interesting.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #38669: [SPARK-41155][SQL] Add error message to SchemaColumnConvertNotSupportedException
dongjoon-hyun commented on code in PR #38669:
URL: https://github.com/apache/spark/pull/38669#discussion_r1023607778
##
sql/core/src/main/java/org/apache/spark/sql/execution/datasources/SchemaColumnConvertNotSupportedException.java:
##
@@ -54,7 +54,8 @@ public SchemaColumnConvertNotSupportedException(
String column,
String physicalType,
String logicalType) {
-super();
+super("column: " + column + ", physicalType: " + physicalType +
+", logicalType: " + logicalType);
Review Comment:
Is the indentation correct, @viirya ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #38668: [SPARK-41153][CORE] Log migrated shuffle data size and migration time
LuciferYang commented on code in PR #38668: URL: https://github.com/apache/spark/pull/38668#discussion_r1023595740 ## core/src/main/scala/org/apache/spark/storage/BlockManagerDecommissioner.scala: ## @@ -125,7 +127,11 @@ private[storage] class BlockManagerDecommissioner( logDebug(s"Migrated sub-block $blockId") } } - logInfo(s"Migrated $shuffleBlockInfo to $peer") + val endTime = System.nanoTime() Review Comment: Why do we need take `nanoTime()` then convert it `toMillis`? What is the problem of directly getting `System.currentTimeMillis()` for calculation? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on a diff in pull request #38644: [SPARK-41130][SQL] Rename `OUT_OF_DECIMAL_TYPE_RANGE` to `NUMERIC_OUT_OF_SUPPORTED_RANGE`
itholic commented on code in PR #38644:
URL: https://github.com/apache/spark/pull/38644#discussion_r1021424319
##
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CastWithAnsiOnSuite.scala:
##
@@ -242,9 +242,13 @@ class CastWithAnsiOnSuite extends CastSuiteBase with
QueryErrorsBase {
test("Fast fail for cast string type to decimal type in ansi mode") {
checkEvaluation(cast("12345678901234567890123456789012345678",
DecimalType(38, 0)),
Decimal("12345678901234567890123456789012345678"))
-checkExceptionInExpression[ArithmeticException](
- cast("123456789012345678901234567890123456789", DecimalType(38, 0)),
- "Out of decimal type range")
+checkError(
+ exception = intercept[SparkArithmeticException] {
+evaluateWithoutCodegen(cast("123456789012345678901234567890123456789",
DecimalType(38, 0)))
+ },
+ errorClass = "NUMERIC_OUT_OF_SUPPORTED_RANGE",
+ parameters = Map("value" -> "123456789012345678901234567890123456789")
+)
Review Comment:
CI complains `org.scalatest.exceptions.TestFailedException: Expected
exception org.apache.spark.SparkArithmeticException to be thrown, but no
exception was thrown
`, but this is passed in my local test env both with/without ANSI mode.
Any suggestion for this fix? or we should just use
`checkExceptionInExpression` for now ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38495: [SPARK-35531][SQL] Update hive table stats without unnecessary convert
cloud-fan commented on code in PR #38495:
URL: https://github.com/apache/spark/pull/38495#discussion_r1023592944
##
sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala:
##
@@ -609,6 +609,20 @@ private[hive] class HiveClientImpl(
shim.alterTable(client, qualifiedTableName, hiveTable)
}
+ override def alterTableStats(
+ dbName: String,
+ tableName: String,
+ stats: Map[String, String]): Unit = withHiveState {
+val hiveTable = getRawHiveTable(dbName,
tableName).rawTable.asInstanceOf[HiveTable]
+val newParameters = new JHashMap[String, String]()
+
hiveTable.getParameters.asScala.toMap.filterNot(_._1.startsWith(STATISTICS_PREFIX))
Review Comment:
It's a bit tricky to make `HiveClient` handle this `STATISTICS_PREFIX`. It
should be the responsibility of `HiveExternalCatalog`. `HiveClient` should only
take care of the communication with HMS.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #38668: [SPARK-41153][CORE] Log migrated shuffle data size and migration time
LuciferYang commented on code in PR #38668: URL: https://github.com/apache/spark/pull/38668#discussion_r1023590958 ## core/src/main/scala/org/apache/spark/storage/BlockManagerDecommissioner.scala: ## @@ -125,7 +127,11 @@ private[storage] class BlockManagerDecommissioner( logDebug(s"Migrated sub-block $blockId") } } - logInfo(s"Migrated $shuffleBlockInfo to $peer") + val endTime = System.nanoTime() + val duration = Duration(endTime - startTime, NANOSECONDS) + val totalBlockSize = Utils.bytesToString(blocks.map(b => b._2.size()).sum) Review Comment: hmm... if `duration` and `totalBlockSize` are defined as `val`, they will be calculated even if `log.isInfoEnabled` is `false` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #38665: [SPARK-41156][SQL] Remove the class `TypeCheckFailure`
cloud-fan commented on PR #38665: URL: https://github.com/apache/spark/pull/38665#issuecomment-1316496874 I'm OK to reuse the usage of `TypeCheckFailure`, but many advanced users use catalyst plans/expressions directly. It's frustrating to remove it and break third party Spark extensions. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #38262: [SPARK-40801][BUILD] Upgrade `Apache commons-text` to 1.10
dongjoon-hyun commented on PR #38262: URL: https://github.com/apache/spark/pull/38262#issuecomment-1316472970 @Stycos SPARK-40801 is arrived after 3.3.1 release.  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng opened a new pull request, #38670: [SPARK-41157][CONNECT][PYTHON][TEST] Show detailed differences in test
zhengruifeng opened a new pull request, #38670: URL: https://github.com/apache/spark/pull/38670 ### What changes were proposed in this pull request? use `assert_eq` in `PandasOnSparkTestCase` to compare dataframes ### Why are the changes needed? show detailed error message before: ``` Traceback (most recent call last): File "/home/jenkins/python/pyspark/sql/tests/connect/test_connect_basic.py", line 244, in test_fill_na self.assertTrue( AssertionError: False is not true ``` after: ``` AssertionError: DataFrame.iloc[:, 0] (column name="id") are different DataFrame.iloc[:, 0] (column name="id") values are different (100.0 %) [index]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] [left]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] [right]: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] Left: id idint64 dtype: object Right: id idint64 dtype: object ``` ### Does this PR introduce _any_ user-facing change? No, test only ### How was this patch tested? existing UT -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #38635: [SPARK-41118][SQL] `to_number`/`try_to_number` should return `null` when format is `null`
LuciferYang commented on code in PR #38635:
URL: https://github.com/apache/spark/pull/38635#discussion_r1023569619
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/numberFormatExpressions.scala:
##
@@ -26,6 +26,62 @@ import org.apache.spark.sql.catalyst.util.ToNumberParser
import org.apache.spark.sql.types.{AbstractDataType, DataType, Decimal,
DecimalType, StringType}
import org.apache.spark.unsafe.types.UTF8String
+abstract class ToNumberBase(left: Expression, right: Expression, errorOnFail:
Boolean)
+ extends BinaryExpression with Serializable with ImplicitCastInputTypes with
NullIntolerant {
+
+ private lazy val numberFormatter = {
+val value = right.eval()
+if (value != null) {
+ new ToNumberParser(value.toString.toUpperCase(Locale.ROOT), errorOnFail)
+} else {
+ null
+}
+ }
+
+ override def dataType: DataType = if (numberFormatter != null) {
+numberFormatter.parsedDecimalType
+ } else {
+DecimalType.USER_DEFAULT
+ }
+
+ override def inputTypes: Seq[DataType] = Seq(StringType, StringType)
+
+ override def checkInputDataTypes(): TypeCheckResult = {
+val inputTypeCheck = super.checkInputDataTypes()
+if (inputTypeCheck.isSuccess) {
+ if (numberFormatter == null) {
+TypeCheckResult.TypeCheckSuccess
+ } else if (right.foldable) {
+numberFormatter.check()
+ } else {
+TypeCheckResult.TypeCheckFailure(s"Format expression must be foldable,
but got $right")
Review Comment:
https://github.com/apache/spark/pull/38531 is merged
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #34367: [SPARK-37099][SQL] Introduce a rank-based filter to optimize top-k computation
beliefer commented on PR #34367: URL: https://github.com/apache/spark/pull/34367#issuecomment-1316464454 > It is a long time since I initially sent this PR, and I don't have time to work on it, if any guys are interested in this optimization, feel free to take over it. cc @beliefer OK. Let me see. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a diff in pull request #38649: [SPARK-41132][SQL] Convert LikeAny and NotLikeAny to InSet if no pattern contains wildcards
wangyum commented on code in PR #38649:
URL: https://github.com/apache/spark/pull/38649#discussion_r1023546094
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/expressions.scala:
##
@@ -780,6 +780,13 @@ object LikeSimplification extends Rule[LogicalPlan] {
} else {
simplifyLike(input, pattern.toString, escapeChar).getOrElse(l)
}
+case LikeAny(child, patterns)
+ if patterns.map(_.toString).forall { case equalTo(_) => true case _ =>
false } =>
+ InSet(child, patterns.toSet)
Review Comment:
Could we also support this case?
```sql
SELECT * FROM tab WHERE trim(addr) LIKE ANY ('5000', '5001', '5002%',
'5003%', '5004')
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on pull request #38665: [SPARK-41156][SQL] Remove the class `TypeCheckFailure`
MaxGekk commented on PR #38665: URL: https://github.com/apache/spark/pull/38665#issuecomment-1316427566 @LuciferYang @panbingkun @itholic @cloud-fan @srielau @anchovYu Could you review this PR, please. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sunchao commented on pull request #38352: [SPARK-40801][BUILD][3.2] Upgrade `Apache commons-text` to 1.10
sunchao commented on PR #38352: URL: https://github.com/apache/spark/pull/38352#issuecomment-1316416703 @bsikander again, pls check [d...@spark.apache.org](mailto:d...@spark.apache.org) - it's being voted. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] bsikander commented on pull request #38352: [SPARK-40801][BUILD][3.2] Upgrade `Apache commons-text` to 1.10
bsikander commented on PR #38352: URL: https://github.com/apache/spark/pull/38352#issuecomment-1316415618 @sunchao @bjornjorgensen any update on this release? As internal alarms are going off continuously, i am desperately looking for the release. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on a diff in pull request #38576: [SPARK-41062][SQL] Rename `UNSUPPORTED_CORRELATED_REFERENCE` to `CORRELATED_REFERENCE`
itholic commented on code in PR #38576:
URL: https://github.com/apache/spark/pull/38576#discussion_r1023536354
##
core/src/main/resources/error/error-classes.json:
##
@@ -1277,6 +1277,11 @@
"A correlated outer name reference within a subquery expression body
was not found in the enclosing query: "
]
},
+ "CORRELATED_REFERENCE" : {
+"message" : [
+ "Expressions referencing the outer query are not supported outside
of WHERE/HAVING clauses"
Review Comment:
Yes, just fixed it to show SQL expression!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on pull request #38669: [SPARK-41155][SQL] Add error message to SchemaColumnConvertNotSupportedException
viirya commented on PR #38669: URL: https://github.com/apache/spark/pull/38669#issuecomment-1316408322 Thank you @sunchao ! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yabola commented on pull request #38560: [WIP][SPARK-38005][core] Support cleaning up merged shuffle files and state from external shuffle service
yabola commented on PR #38560: URL: https://github.com/apache/spark/pull/38560#issuecomment-1316389795 @mridulm as your comment said https://github.com/apache/spark/pull/37922#discussion_r990763769 , I want to Improve this part of the deletion logic -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #34367: [SPARK-37099][SQL] Introduce a rank-based filter to optimize top-k computation
zhengruifeng commented on PR #34367: URL: https://github.com/apache/spark/pull/34367#issuecomment-1316354088 It is a long time since I initially sent this PR, and I don't have time to work on it, if any guys are interested in this optimization, feel free to take over it. cc @beliefer -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on pull request #38669: [SPARK-41155][SQL] Add error message to SchemaColumnConvertNotSupportedException
viirya commented on PR #38669: URL: https://github.com/apache/spark/pull/38669#issuecomment-1316351255 Thank you @dongjoon-hyun ! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on pull request #38669: [SPARK-41155][SQL] Add error message to SchemaColumnConvertNotSupportedException
viirya commented on PR #38669: URL: https://github.com/apache/spark/pull/38669#issuecomment-1316348790 cc @dongjoon-hyun @sunchao -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #38666: [CONENCT][PYTHON][DOC] Document how to run the module of tests for Spark Connect Python tests
zhengruifeng commented on code in PR #38666: URL: https://github.com/apache/spark/pull/38666#discussion_r1023503919 ## connector/connect/README.md: ## @@ -52,9 +52,15 @@ To use the release version of Spark Connect: ### Run Tests ```bash +# Run a single Python test. ./python/run-tests --testnames 'pyspark.sql.tests.connect.test_connect_basic' Review Comment: ```suggestion # Run a single Python class. ./python/run-tests --testnames 'pyspark.sql.tests.connect.test_connect_basic' # Run a single test case in a specific class: ./python/run-tests --testnames 'pyspark.sql.tests.connect.test_connect_basic SparkConnectTests.test_schema' ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya opened a new pull request, #38669: [SPARK-41155][SQL] Add error message to SchemaColumnConvertNotSupportedException
viirya opened a new pull request, #38669: URL: https://github.com/apache/spark/pull/38669 ### What changes were proposed in this pull request? This patch adds error message to `SchemaColumnConvertNotSupportedException`. ### Why are the changes needed? Just found the fact that `SchemaColumnConvertNotSupportedException` doesn't have any error message is annoying for debugging. In stack trace, we only see `SchemaColumnConvertNotSupportedException` but don't know what column is wrong. After this change, we should be able to see it, e.g., ``` org.apache.spark.sql.execution.datasources.SchemaColumnConvertNotSupportedException: column: [_1], physicalType: INT32, logicalType: bigint ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #38666: [CONENCT][PYTHON][DOC] Document how to run the module of tests for Spark Connect Python tests
zhengruifeng commented on code in PR #38666: URL: https://github.com/apache/spark/pull/38666#discussion_r1023503919 ## connector/connect/README.md: ## @@ -52,9 +52,15 @@ To use the release version of Spark Connect: ### Run Tests ```bash +# Run a single Python test. ./python/run-tests --testnames 'pyspark.sql.tests.connect.test_connect_basic' Review Comment: ```suggestion # Run a single Python class. ./python/run-tests --testnames 'pyspark.sql.tests.connect.test_connect_basic' # Run a single test case in a specific class: ./python/run-tests --testnames 'pyspark.sql.tests.connect.test_connect_basic SparkConnectTests.test_schema' ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #38667: [SPARK-40798][DOCS][FOLLOW-UP] Fix a typo in the configuration name at migration guide
HyukjinKwon closed pull request #38667: [SPARK-40798][DOCS][FOLLOW-UP] Fix a typo in the configuration name at migration guide URL: https://github.com/apache/spark/pull/38667 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #38667: [SPARK-40798][DOCS][FOLLOW-UP] Fix a typo in the configuration name at migration guide
HyukjinKwon commented on PR #38667: URL: https://github.com/apache/spark/pull/38667#issuecomment-1316341751 Merged to master. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on pull request #38630: [SPARK-41115][CONNECT] Add ClientType to proto to indicate which client sends a request
grundprinzip commented on PR #38630: URL: https://github.com/apache/spark/pull/38630#issuecomment-1316339424 @amaliujia can you please update the pr description to remove the enum part. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wankunde commented on a diff in pull request #38495: [SPARK-35531][SQL] Update hive table stats without unnecessary convert
wankunde commented on code in PR #38495:
URL: https://github.com/apache/spark/pull/38495#discussion_r1023487514
##
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveExternalCatalog.scala:
##
@@ -722,18 +722,15 @@ private[spark] class HiveExternalCatalog(conf: SparkConf,
hadoopConf: Configurat
stats: Option[CatalogStatistics]): Unit = withClient {
requireTableExists(db, table)
val rawTable = getRawTable(db, table)
Review Comment:
If we can call client.getRawHiveTable here, will throw exception
`java.lang.LinkageError: loader constraint violation: loader (instance of
sun/misc/Launcher$AppClassLoader) previously initiated loading for a different
type with name "org/apache/hadoop/hive/ql/metadata/Table"`
Detail stack:
```
[info]
org.apache.spark.sql.hive.execution.command.AlterTableDropPartitionSuite ***
ABORTED *** (18 seconds, 552 milliseconds)
[info] java.lang.LinkageError: loader constraint violation: loader
(instance of sun/misc/Launcher$AppClassLoader) previously initiated loading for
a different type with name "org/apache/hadoop/hive/ql/metadata/Table"
[info] at java.lang.ClassLoader.defineClass1(Native Method)
[info] at java.lang.ClassLoader.defineClass(ClassLoader.java:756)
[info] at
java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
[info] at java.net.URLClassLoader.defineClass(URLClassLoader.java:468)
[info] at java.net.URLClassLoader.access$100(URLClassLoader.java:74)
[info] at java.net.URLClassLoader$1.run(URLClassLoader.java:369)
[info] at java.net.URLClassLoader$1.run(URLClassLoader.java:363)
[info] at java.security.AccessController.doPrivileged(Native Method)
[info] at java.net.URLClassLoader.findClass(URLClassLoader.java:362)
[info] at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
[info] at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)
[info] at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
[info] at
org.apache.spark.sql.hive.client.HiveClientImpl$.toHiveTable(HiveClientImpl.scala:1115)
[info] at
org.apache.spark.sql.hive.execution.V1WritesHiveUtils.getDynamicPartitionColumns(V1WritesHiveUtils.scala:51)
[info] at
org.apache.spark.sql.hive.execution.V1WritesHiveUtils.getDynamicPartitionColumns$(V1WritesHiveUtils.scala:43)
[info] at
org.apache.spark.sql.hive.execution.InsertIntoHiveTable.getDynamicPartitionColumns(InsertIntoHiveTable.scala:70)
[info] at
org.apache.spark.sql.hive.execution.InsertIntoHiveTable.partitionColumns$lzycompute(InsertIntoHiveTable.scala:80)
[info] at
org.apache.spark.sql.hive.execution.InsertIntoHiveTable.partitionColumns(InsertIntoHiveTable.scala:79)
[info] at
org.apache.spark.sql.execution.datasources.V1Writes$.org$apache$spark$sql$execution$datasources$V1Writes$$prepareQuery(V1Writes.scala:75)
[info] at
org.apache.spark.sql.execution.datasources.V1Writes$$anonfun$apply$1.applyOrElse(V1Writes.scala:57)
[info] at
org.apache.spark.sql.execution.datasources.V1Writes$$anonfun$apply$1.applyOrElse(V1Writes.scala:55)
[info] at
org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:512)
[info] at
org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:104)
[info] at
org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:512)
[info] at
org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:30)
[info] at
org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:267)
[info] at
org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:263)
[info] at
org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
[info] at
org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
[info] at
org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:488)
[info] at
org.apache.spark.sql.execution.datasources.V1Writes$.apply(V1Writes.scala:55)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] warrenzhu25 opened a new pull request, #38668: [SPARK-41153][CORE] Log migrated shuffle data size and migration time
warrenzhu25 opened a new pull request, #38668: URL: https://github.com/apache/spark/pull/38668 ### What changes were proposed in this pull request? Log migrated shuffle data size and migration time ### Why are the changes needed? Get info about migrated shuffle data size and migration time ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Manually tested -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] pan3793 commented on a diff in pull request #38651: [SPARK-41136][K8S] Shorten graceful shutdown time of ExecutorPodsSnapshotsStoreImpl to prevent blocking shutdown process
pan3793 commented on code in PR #38651:
URL: https://github.com/apache/spark/pull/38651#discussion_r1023478697
##
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsSnapshotsStoreImpl.scala:
##
@@ -57,6 +60,7 @@ import org.apache.spark.util.ThreadUtils
* The subscriber notification callback is guaranteed to be called from a
single thread at a time.
*/
private[spark] class ExecutorPodsSnapshotsStoreImpl(
+conf: SparkConf,
Review Comment:
the backward-compatible constructors were added
##
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/Config.scala:
##
@@ -723,6 +723,18 @@ private[spark] object Config extends Logging {
.checkValue(value => value > 0, "Maximum number of pending pods should
be a positive integer")
.createWithDefault(Int.MaxValue)
+ val KUBERNETES_EXECUTOR_SNAPSHOTS_SUBSCRIBERS_GRACE_PERIOD =
+
ConfigBuilder("spark.kubernetes.executorSnapshotsSubscribersShutdownGracePeriod")
+ .doc("Time to wait for graceful shutdown
kubernetes-executor-snapshots-subscribers " +
+"thread pool. Since it may be called by ShutdownHookManager, where
timeout is " +
+"controlled by hadoop configuration `hadoop.service.shutdown.timeout`
" +
+"(default is 30s). As the whole Spark shutdown procedure shares the
above timeout, " +
+"this value should be short than that to prevent blocking the
following shutdown " +
+"procedures.")
+ .version("3.4.0")
+ .timeConf(TimeUnit.SECONDS)
Review Comment:
added
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] pan3793 commented on pull request #38651: [SPARK-41136][K8S] Shorten graceful shutdown time of ExecutorPodsSnapshotsStoreImpl to prevent blocking shutdown process
pan3793 commented on PR #38651: URL: https://github.com/apache/spark/pull/38651#issuecomment-1316286965 @dongjoon-hyun thanks for review, I addressed your comments. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] pan3793 commented on a diff in pull request #38651: [SPARK-41136][K8S] Shorten graceful shutdown time of ExecutorPodsSnapshotsStoreImpl to prevent blocking shutdown process
pan3793 commented on code in PR #38651:
URL: https://github.com/apache/spark/pull/38651#discussion_r1023477562
##
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsSnapshotsStoreImpl.scala:
##
@@ -57,10 +60,22 @@ import org.apache.spark.util.ThreadUtils
* The subscriber notification callback is guaranteed to be called from a
single thread at a time.
*/
private[spark] class ExecutorPodsSnapshotsStoreImpl(
+conf: SparkConf,
subscribersExecutor: ScheduledExecutorService,
clock: Clock = new SystemClock)
extends ExecutorPodsSnapshotsStore with Logging {
+ private[spark] def this(
+ subscribersExecutor: ScheduledExecutorService) = {
+this(new SparkConf, subscribersExecutor, new SystemClock)
+ }
+
+ private[spark] def this(
+ subscribersExecutor: ScheduledExecutorService,
+ clock: Clock) = {
+this(new SparkConf, subscribersExecutor, clock)
+ }
Review Comment:
I can not merge these two constructers into one,
```
private[spark] def this(
subscribersExecutor: ScheduledExecutorService,
clock: Clock = new SystemClock) = {
this(new SparkConf, subscribersExecutor, clock)
}
```
it fails compilation
```
[error]
/Users/chengpan/Projects/apache-spark/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/KubernetesClusterManager.scala:106:64:
type mismatch;
[error] found : org.apache.spark.SparkConf
[error] required: java.util.concurrent.ScheduledExecutorService
[error] val snapshotsStore = new ExecutorPodsSnapshotsStoreImpl(sc.conf,
subscribersExecutor)
[error]
``
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ulysses-you commented on pull request #38667: [SPARK-40798][DOCS][FOLLOW-UP] Fix a typo in the configuration name at migration guide
ulysses-you commented on PR #38667: URL: https://github.com/apache/spark/pull/38667#issuecomment-1316283965 thank you @HyukjinKwon @anchovYu -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #38620: [SPARK-41113][BUILD] Upgrade sbt to 1.8.0
LuciferYang commented on PR #38620: URL: https://github.com/apache/spark/pull/38620#issuecomment-1316264566 Thanks @dongjoon-hyun @HyukjinKwon -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wankunde commented on pull request #38495: [SPARK-35531][SQL] Update hive table stats without unnecessary convert
wankunde commented on PR #38495: URL: https://github.com/apache/spark/pull/38495#issuecomment-1316254348 Retest this please -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng opened a new pull request, #34367: [SPARK-37099][SQL] Introduce a rank-based filter to optimize top-k computation
zhengruifeng opened a new pull request, #34367: URL: https://github.com/apache/spark/pull/34367 ### What changes were proposed in this pull request? introduce a new node `RankLimit` to filter out uncessary rows based on rank computed on partial dataset. it supports following pattern: ``` select (... (row_number|rank|dense_rank)() over ( [partition by ...] order by ... ) as rn) where rn (==|<|<=) k and other conditions ``` For these three rank functions (row_number|rank|dense_rank), the rank of a key computed on partitial dataset always <= its final rank computed on the whole dataset,so we can safely discard rows with partitial rank > `k`, anywhere. ### Why are the changes needed? 1, reduce the shuffle write; 2, solve skewed-window problem, a practical case was optimized from 2.5h to 26min ### Does this PR introduce _any_ user-facing change? a new config is added ### How was this patch tested? 1, added testsuits, practical cases on our production system 2, 10TiB TPC-DS - q67: Before this PR | After this PR --- | --- Job Duration=58min|Job Duration=11min Stage Duration=50min|Stage Duration=3sec Stage Shuffle=58.0 GiB|Stage Shuffle=9.9 MiB 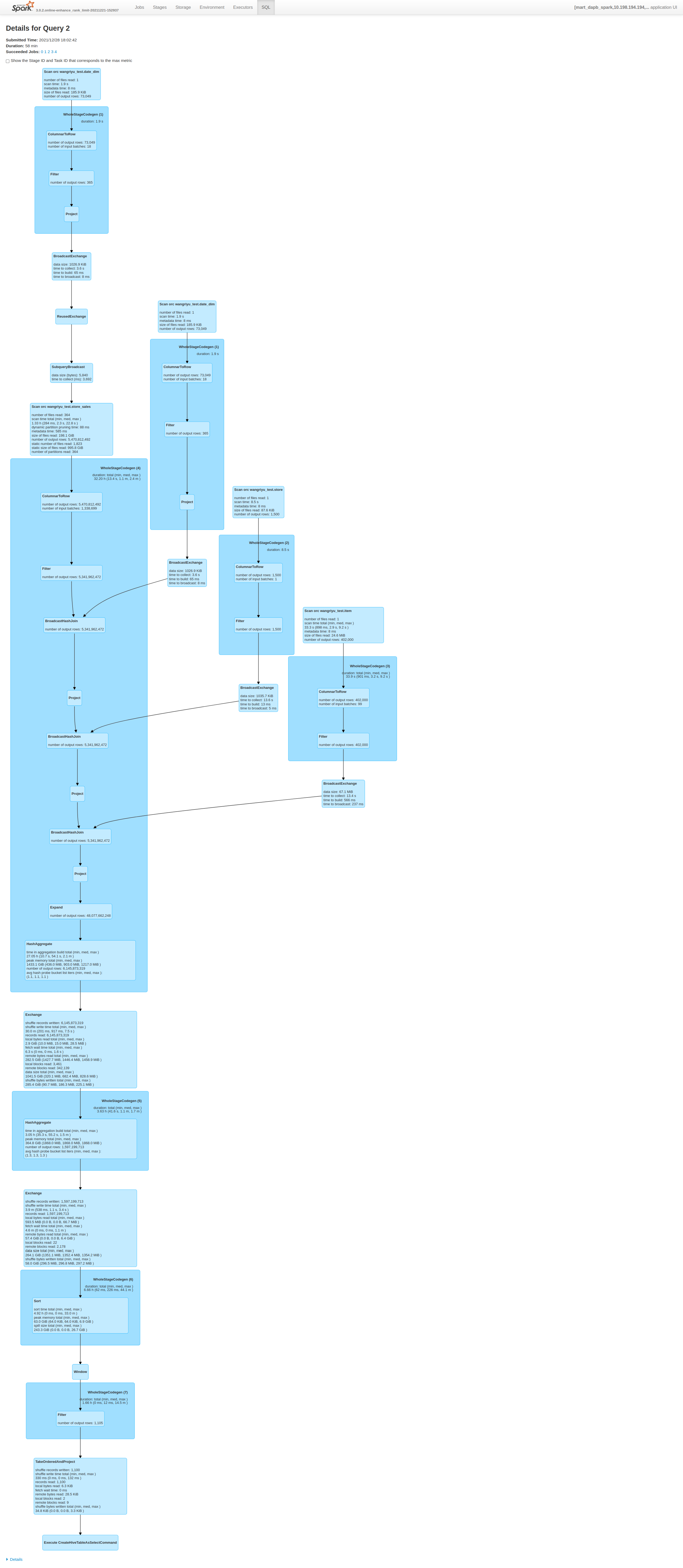|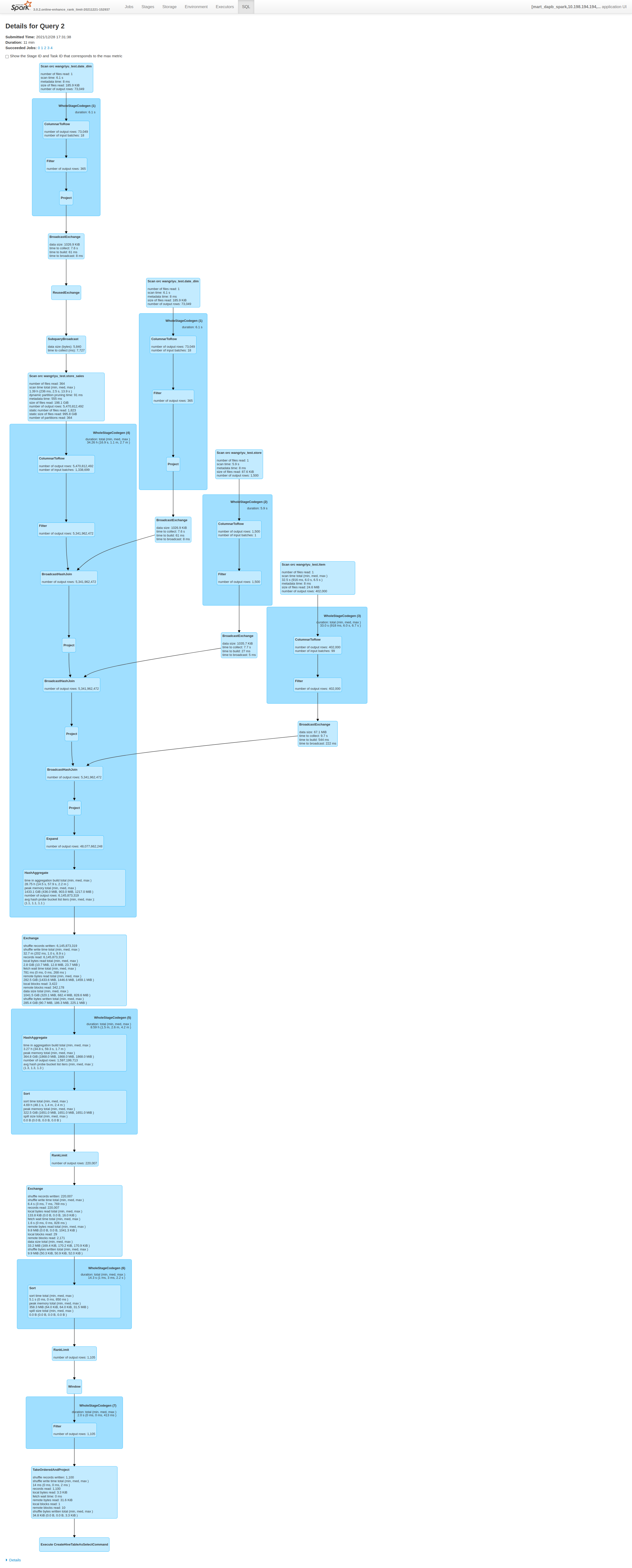 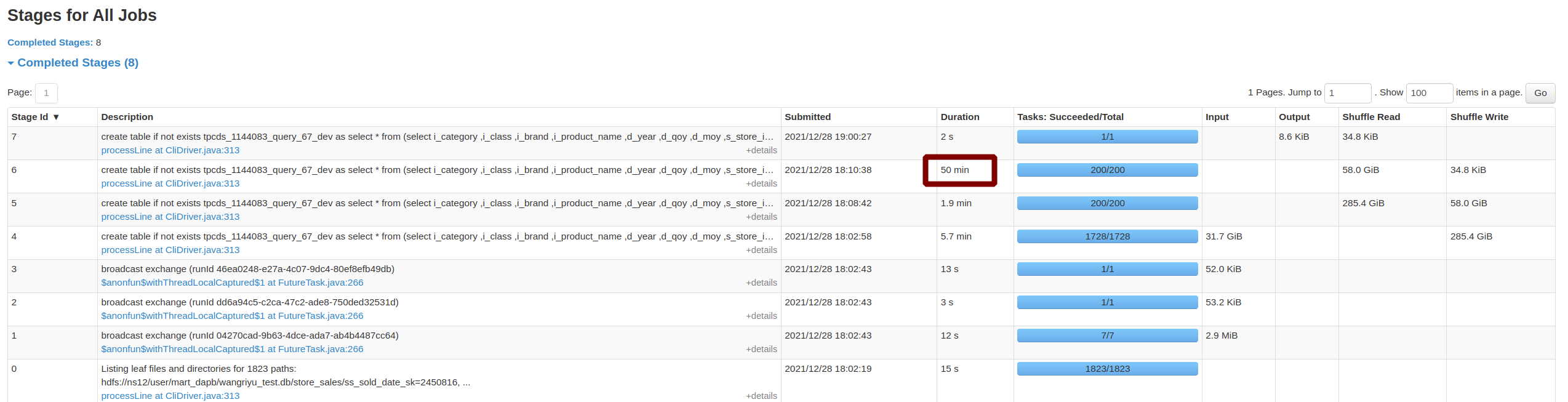|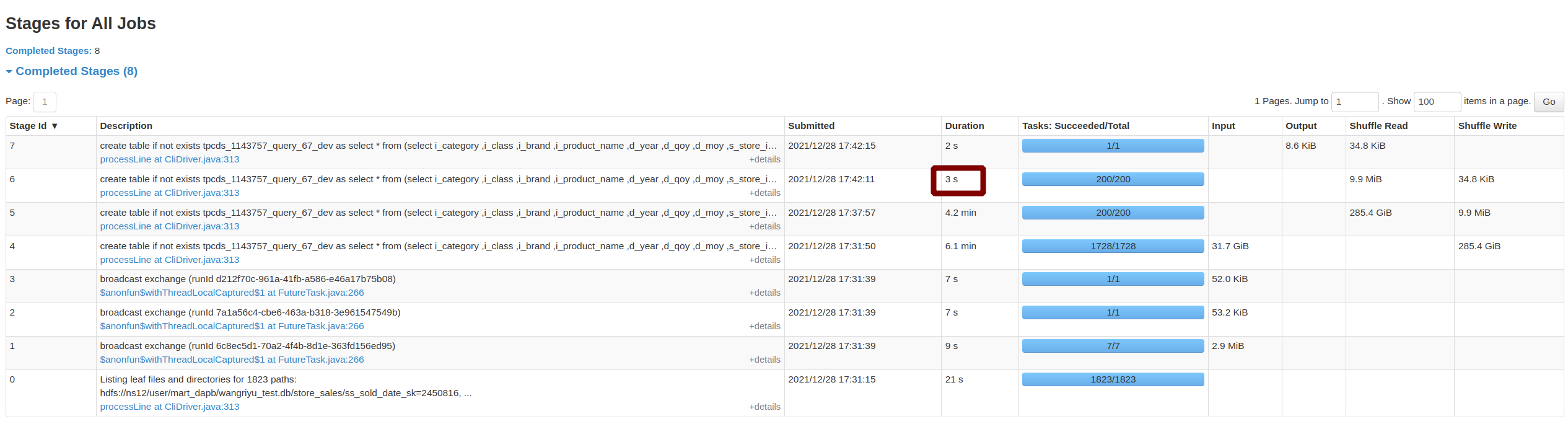 3, added benchmark: ``` [info] Java HotSpot(TM) 64-Bit Server VM 1.8.0_301-b09 on Linux 5.11.0-41-generic [info] Intel(R) Core(TM) i7-8850H CPU @ 2.60GHz [info] Benchmark Top-K: Best Time(ms) Avg Time(ms) Stdev(ms)Rate(M/s) Per Row(ns) Relative [info] [info] ROW_NUMBER WITHOUT PARTITION 10688 11377 664 2.0 509.6 1.0X [info] ROW_NUMBER WITHOUT PARTITION (RANKLIMIT Sorting) 2678 2962 137 7.8 127.7 4.0X [info] ROW_NUMBER WITHOUT PARTITION (RANKLIMIT TakeOrdered) 1585 1611 19 13.2 75.6 6.7X [info] RANK WITHOUT PARTITION11504 12056 406 1.8 548.6 0.9X [info] RANK WITHOUT PARTITION (RANKLIMIT) 3020 3148 89 6.9 144.0 3.5X [info] DENSE_RANK WITHOUT PARTITION 11728 11915 216 1.8 559.3 0.9X [info] DENSE_RANK WITHOUT PARTITION (RANKLIMIT) 2632 2906 182 8.0 125.5 4.1X [info] ROW_NUMBER WITH PARTITION 23139 24025 500 0.91103.4 0.5X [info] ROW_NUMBER WITH PARTITION (RANKLIMIT Sorting) 7034 7575 361 3.0 335.4 1.5X [info] ROW_NUMBER WITH PARTITION (RANKLIMIT TakeOrdered) 5958 6391 311 3.5 284.1 1.8X [info] RANK WITH PARTITION 24942 26005 795 0.81189.4 0.4X [info] RANK WITH PARTITION (RANKLIMIT)7217 7517 219 2.9 344.1 1.5X [info] DENSE_RANK WITH PARTITION 24843 26726 221 0.81184.6 0.4X [info] DENSE_RANK WITH PARTITION (RANKLIMIT) 7455 7978 560 2.8 355.5 1.4X ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #38257: [SPARK-40798][SQL] Alter partition should verify value follow storeAssignmentPolicy
HyukjinKwon commented on code in PR #38257: URL: https://github.com/apache/spark/pull/38257#discussion_r1023455115 ## docs/sql-migration-guide.md: ## @@ -34,6 +34,7 @@ license: | - Valid hexadecimal strings should include only allowed symbols (0-9A-Fa-f). - Valid values for `fmt` are case-insensitive `hex`, `base64`, `utf-8`, `utf8`. - Since Spark 3.4, Spark throws only `PartitionsAlreadyExistException` when it creates partitions but some of them exist already. In Spark 3.3 or earlier, Spark can throw either `PartitionsAlreadyExistException` or `PartitionAlreadyExistsException`. + - Since Spark 3.4, Spark will do validation for partition spec in ALTER PARTITION to follow the behavior of `spark.sql.storeAssignmentPolicy` which may cause an exception if type conversion fails, e.g. `ALTER TABLE .. ADD PARTITION(p='a')` if column `p` is int type. To restore the legacy behavior, set `spark.sql.legacy.skipPartitionSpecTypeValidation` to `true`. Review Comment: just made a PR :-) https://github.com/apache/spark/pull/38667 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon opened a new pull request, #38667: [SPARK-40798][DOCS] Fix a typo in the configuration name at migration guide
HyukjinKwon opened a new pull request, #38667: URL: https://github.com/apache/spark/pull/38667 ### What changes were proposed in this pull request? This PR is a followup of https://github.com/apache/spark/pull/38257 to fix a typo from `spark.sql.legacy.skipPartitionSpecTypeValidation` to `spark.sql.legacy.skipTypeValidationOnAlterPartition`. ### Why are the changes needed? To show users the correct configuration name for legacy behaviours. ### Does this PR introduce _any_ user-facing change? No, doc-only. ### How was this patch tested? N/A -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] mridulm commented on pull request #38064: [SPARK-40622][SQL][CORE]Remove the limitation that single task result must fit in 2GB
mridulm commented on PR #38064: URL: https://github.com/apache/spark/pull/38064#issuecomment-1316229029 Merged to master. Thanks for fixing this @liuzqt ! Thanks for the reviews @Ngone51, @sadikovi, @jiangxb1987 :-) And thanks for help with GA @HyukjinKwon and @Yikun ! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #38257: [SPARK-40798][SQL] Alter partition should verify value follow storeAssignmentPolicy
HyukjinKwon commented on code in PR #38257: URL: https://github.com/apache/spark/pull/38257#discussion_r1023453997 ## docs/sql-migration-guide.md: ## @@ -34,6 +34,7 @@ license: | - Valid hexadecimal strings should include only allowed symbols (0-9A-Fa-f). - Valid values for `fmt` are case-insensitive `hex`, `base64`, `utf-8`, `utf8`. - Since Spark 3.4, Spark throws only `PartitionsAlreadyExistException` when it creates partitions but some of them exist already. In Spark 3.3 or earlier, Spark can throw either `PartitionsAlreadyExistException` or `PartitionAlreadyExistsException`. + - Since Spark 3.4, Spark will do validation for partition spec in ALTER PARTITION to follow the behavior of `spark.sql.storeAssignmentPolicy` which may cause an exception if type conversion fails, e.g. `ALTER TABLE .. ADD PARTITION(p='a')` if column `p` is int type. To restore the legacy behavior, set `spark.sql.legacy.skipPartitionSpecTypeValidation` to `true`. Review Comment: nice catch -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] asfgit closed pull request #38064: [SPARK-40622][SQL][CORE]Remove the limitation that single task result must fit in 2GB
asfgit closed pull request #38064: [SPARK-40622][SQL][CORE]Remove the limitation that single task result must fit in 2GB URL: https://github.com/apache/spark/pull/38064 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #38609: [SPARK-40593][BUILD][CONNECT] Make user can build and test `connect` module by specifying the user-defined `protoc` and `protoc
LuciferYang commented on code in PR #38609:
URL: https://github.com/apache/spark/pull/38609#discussion_r1023446576
##
project/SparkBuild.scala:
##
@@ -109,6 +109,14 @@ object SparkBuild extends PomBuild {
if (profiles.contains("jdwp-test-debug")) {
sys.props.put("test.jdwp.enabled", "true")
}
+if (profiles.contains("user-defined-pb")) {
Review Comment:
done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #38609: [SPARK-40593][BUILD][CONNECT] Make user can build and test `connect` module by specifying the user-defined `protoc` and `protoc
LuciferYang commented on code in PR #38609:
URL: https://github.com/apache/spark/pull/38609#discussion_r1023446458
##
connector/connect/pom.xml:
##
@@ -371,4 +350,68 @@
+
+
+ official-pb
Review Comment:
done
##
connector/connect/pom.xml:
##
@@ -371,4 +350,68 @@
+
+
+ official-pb
+
+true
+
+
+
+
+
+org.xolstice.maven.plugins
+protobuf-maven-plugin
+0.6.1
+
+
com.google.protobuf:protoc:${protobuf.version}:exe:${os.detected.classifier}
+ grpc-java
+
io.grpc:protoc-gen-grpc-java:${io.grpc.version}:exe:${os.detected.classifier}
+ src/main/protobuf
+
+
+
+
+ compile
+ compile-custom
+ test-compile
+
+
+
+
+
+
+
+
+ user-defined-pb
Review Comment:
done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #38609: [SPARK-40593][BUILD][CONNECT] Make user can build and test `connect` module by specifying the user-defined `protoc` and `protoc
LuciferYang commented on code in PR #38609: URL: https://github.com/apache/spark/pull/38609#discussion_r1023446300 ## connector/connect/README.md: ## @@ -24,7 +24,31 @@ or ```bash ./build/sbt -Phive clean package ``` - + +### Build with user-defined `protoc` and `protoc-gen-grpc-java` + +When the user cannot use the official `protoc` and `protoc-gen-grpc-java` binary files to build the `connect` module in the compilation environment, +for example, compiling `connect` module on CentOS 6 or CentOS 7 which the default `glibc` version is less than 2.14, we can try to compile and test by +specifying the user-defined `protoc` and `protoc-gen-grpc-java` binary files as follows: + +```bash +export CONNECT_PROTOC_EXEC_PATH=/path-to-protoc-exe +export CONNECT_PLUGIN_EXEC_PATH=/path-to-protoc-gen-grpc-java-exe +./build/mvn -Phive -Puser-defined-pb clean package Review Comment: done ## connector/connect/README.md: ## @@ -24,7 +24,31 @@ or ```bash ./build/sbt -Phive clean package ``` - + +### Build with user-defined `protoc` and `protoc-gen-grpc-java` + +When the user cannot use the official `protoc` and `protoc-gen-grpc-java` binary files to build the `connect` module in the compilation environment, +for example, compiling `connect` module on CentOS 6 or CentOS 7 which the default `glibc` version is less than 2.14, we can try to compile and test by +specifying the user-defined `protoc` and `protoc-gen-grpc-java` binary files as follows: + +```bash +export CONNECT_PROTOC_EXEC_PATH=/path-to-protoc-exe +export CONNECT_PLUGIN_EXEC_PATH=/path-to-protoc-gen-grpc-java-exe +./build/mvn -Phive -Puser-defined-pb clean package +``` + +or + +```bash +export CONNECT_PROTOC_EXEC_PATH=/path-to-protoc-exe +export CONNECT_PLUGIN_EXEC_PATH=/path-to-protoc-gen-grpc-java-exe +./build/sbt -Puser-defined-pb clean package Review Comment: done -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yaohua628 commented on a diff in pull request #38663: [SPARK-41143][SQL] Add named argument function syntax support
Yaohua628 commented on code in PR #38663:
URL: https://github.com/apache/spark/pull/38663#discussion_r1023434857
##
sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryCompilationErrors.scala:
##
@@ -3380,4 +3380,20 @@ private[sql] object QueryCompilationErrors extends
QueryErrorsBase {
"unsupported" -> unsupported.toString,
"class" -> unsupported.getClass.toString))
}
+
+ def tableFunctionDuplicateNamedArguments(name: String, pos: Int): Throwable
= {
+new AnalysisException(
Review Comment:
Thanks for the feedback!
Honestly, I think the specific error is more like a compilation error
instead of a parsing error?
We can parse it correctly, there is no syntax error, it is more like failing
to resolve/compile the given `UnresolvedTableValuedFunction` into an actual
resolved function.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yaohua628 commented on a diff in pull request #38663: [SPARK-41143][SQL] Add named argument function syntax support
Yaohua628 commented on code in PR #38663:
URL: https://github.com/apache/spark/pull/38663#discussion_r1023431618
##
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/parser/PlanParserSuite.scala:
##
@@ -852,6 +852,31 @@ class PlanParserSuite extends AnalysisTest {
stop = 43))
}
+ test("table valued function with named arguments") {
+// All named arguments
+assertEqual(
+ "select * from my_tvf(arg1 => 'value1', arg2 => true)",
+ UnresolvedTableValuedFunction("my_tvf",
+NamedArgumentExpression("arg1", Literal("value1")) ::
+ NamedArgumentExpression("arg2", Literal(true)) :: Nil,
Seq.empty).select(star()))
+
+// Unnamed and named arguments
+assertEqual(
+ "select * from my_tvf(2, arg1 => 'value1', arg2 => true)",
+ UnresolvedTableValuedFunction("my_tvf",
+Literal(2) ::
+ NamedArgumentExpression("arg1", Literal("value1")) ::
+ NamedArgumentExpression("arg2", Literal(true)) :: Nil,
Seq.empty).select(star()))
+
+// Mixed arguments
+assertEqual(
+ "select * from my_tvf(arg1 => 'value1', 2, arg2 => true)",
Review Comment:
Got it! Good point, added a test, it will throw:
```
org.apache.spark.sql.AnalysisException: could not resolve `my_func` to a
table-valued function; line 1 pos 14;
'Project [*]
+- 'UnresolvedTableValuedFunction [my_func], [jack, age => 18]
```
And the next step, we need to resolve this `UnresolvedTableValuedFunction`
plan to actual function.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yaohua628 commented on a diff in pull request #38663: [SPARK-41143][SQL] Add named argument function syntax support
Yaohua628 commented on code in PR #38663:
URL: https://github.com/apache/spark/pull/38663#discussion_r1023428966
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/NamedArgumentFunction.scala:
##
@@ -0,0 +1,92 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.plans.logical
+
+import java.util.Locale
+
+import scala.collection.mutable
+
+import org.apache.spark.sql.catalyst.expressions.{Expression,
NamedArgumentExpression}
+import
org.apache.spark.sql.errors.QueryCompilationErrors.{tableFunctionDuplicateNamedArguments,
tableFunctionUnexpectedArgument}
+import org.apache.spark.sql.types._
+
+/**
+ * A trait to define a named argument function:
+ * Usage: _FUNC_(arg0, arg1, arg2, arg5 => value5, arg8 => value8)
+ *
+ * - Arguments can be passed positionally or by name
+ * - Positional arguments cannot come after a named argument
+ */
+trait NamedArgumentFunction {
+ /**
+ * A trait [[Param]] that is used to define function parameter
+ * - name: case insensitive name
Review Comment:
Thanks for your feedback!
I think function parameters (identifier) have to be case insensitive:
https://spark.apache.org/docs/latest/sql-ref-identifier.html
Also, from a UX perspective, a named argument function with case-sensitive
parameters will be pretty hard to use? WDYT
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #37630: [SPARK-40193][SQL] Merge subquery plans with different filters
beliefer commented on PR #37630: URL: https://github.com/apache/spark/pull/37630#issuecomment-1316166252 @peter-toth Could you fix the conflicts again? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #37630: [SPARK-40193][SQL] Merge subquery plans with different filters
beliefer commented on PR #37630: URL: https://github.com/apache/spark/pull/37630#issuecomment-1316165732 We tested this PR and the results is:  cc @sigmod too. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia opened a new pull request, #38666: [CONENCT][PYTHON][DOC] Document how to run the module of tests for Spark Connect Python tests
amaliujia opened a new pull request, #38666: URL: https://github.com/apache/spark/pull/38666 ### What changes were proposed in this pull request? Improve developer documentation for Connect project for how to run `pyspark-connect` module which runs all existing Connect Python tests. ### Why are the changes needed? Developer facing documentation improvement. ### Does this PR introduce _any_ user-facing change? NO ### How was this patch tested? N/A -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on pull request #38666: [CONENCT][PYTHON][DOC] Document how to run the module of tests for Spark Connect Python tests
amaliujia commented on PR #38666: URL: https://github.com/apache/spark/pull/38666#issuecomment-1316126191 R: @zhengruifeng -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] bersprockets commented on a diff in pull request #38635: [SPARK-41118][SQL] `to_number`/`try_to_number` should return `null` when format is `null`
bersprockets commented on code in PR #38635:
URL: https://github.com/apache/spark/pull/38635#discussion_r1020798321
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/numberFormatExpressions.scala:
##
@@ -26,6 +26,62 @@ import org.apache.spark.sql.catalyst.util.ToNumberParser
import org.apache.spark.sql.types.{AbstractDataType, DataType, Decimal,
DecimalType, StringType}
import org.apache.spark.unsafe.types.UTF8String
+abstract class ToNumberBase(left: Expression, right: Expression, errorOnFail:
Boolean)
Review Comment:
*Edit: I updated the diff below after rebase.*
I moved common code to an abstract class to avoid making the same bug fix
twice.
However, that makes it hard to see the actual bug fix, so I can unwind this
change if needed.
The difference between the old `ToNumber` to new `ToNumberBase` is the way
the `numberFormatter` in initialized, how the `dataType` is chosen, the
`checkInputDataTypes` method, and a line in the `doGenCode` method:
```
1,4c1,17
< case class ToNumber(left: Expression, right: Expression)
< extends BinaryExpression with ImplicitCastInputTypes with NullIntolerant
{
< private lazy val numberFormat =
right.eval().toString.toUpperCase(Locale.ROOT)
< private lazy val numberFormatter = new ToNumberParser(numberFormat, true)
---
> abstract class ToNumberBase(left: Expression, right: Expression,
errorOnFail: Boolean)
> extends BinaryExpression with Serializable with ImplicitCastInputTypes
with NullIntolerant {
>
> private lazy val numberFormatter = {
> val value = right.eval()
> if (value != null) {
> new ToNumberParser(value.toString.toUpperCase(Locale.ROOT),
errorOnFail)
> } else {
> null
> }
> }
>
> override def dataType: DataType = if (numberFormatter != null) {
> numberFormatter.parsedDecimalType
> } else {
> DecimalType.USER_DEFAULT
> }
6d18
< override def dataType: DataType = numberFormatter.parsedDecimalType
7a20
>
11,13c24
< if (right.foldable) {
< numberFormatter.checkInputDataTypes()
< } else {
---
> if (!right.foldable) {
21a33,36
> } else if (numberFormatter == null) {
> TypeCheckResult.TypeCheckSuccess
> } else {
> numberFormatter.checkInputDataTypes()
27c42
< override def prettyName: String = "to_number"
---
>
31a47
>
39c55
< |boolean ${ev.isNull} = ${eval.isNull};
---
> |boolean ${ev.isNull} = ${eval.isNull} || ($builder == null);
46,48d61
< override protected def withNewChildrenInternal(
< newLeft: Expression, newRight: Expression): ToNumber =
< copy(left = newLeft, right = newRight)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Stycos commented on pull request #38262: [SPARK-40801][BUILD] Upgrade `Apache commons-text` to 1.10
Stycos commented on PR #38262: URL: https://github.com/apache/spark/pull/38262#issuecomment-1316090923 When I execute `pip install pyspark` I still get commons-text-1.9.jar in the jars folder. Shouldn't I get 1.10 now? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] github-actions[bot] closed pull request #37409: [SPARK-39970][CORE] Introduce ThrottledLogger to prevent log message flooding caused by network issues
github-actions[bot] closed pull request #37409: [SPARK-39970][CORE] Introduce ThrottledLogger to prevent log message flooding caused by network issues URL: https://github.com/apache/spark/pull/37409 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] rangadi commented on a diff in pull request #38384: [SPARK-40657][PROTOBUF] Require shading for Java class jar, improve error handling
rangadi commented on code in PR #38384:
URL: https://github.com/apache/spark/pull/38384#discussion_r1023371786
##
connector/protobuf/src/main/scala/org/apache/spark/sql/protobuf/utils/ProtobufUtils.scala:
##
@@ -155,21 +155,52 @@ private[sql] object ProtobufUtils extends Logging {
* Loads the given protobuf class and returns Protobuf descriptor for it.
*/
def buildDescriptorFromJavaClass(protobufClassName: String): Descriptor = {
+
+// Default 'Message' class here is shaded while using the package (as in
production).
+// The incoming classes might not be shaded. Check both.
+val shadedMessageClass = classOf[Message] // Shaded in prod, not in unit
tests.
+val missingShadingErrorMessage = "The jar with Protobuf classes needs to
be shaded " +
+ s"(com.google.protobuf.* --> ${shadedMessageClass.getPackage.getName}.*)"
+
val protobufClass = try {
Utils.classForName(protobufClassName)
} catch {
case e: ClassNotFoundException =>
-throw QueryCompilationErrors.protobufClassLoadError(protobufClassName,
e)
+val explanation =
+ if (protobufClassName.contains(".")) "Ensure the class include in
the jar"
+ else "Ensure the class name includes package prefix"
+throw QueryCompilationErrors.protobufClassLoadError(protobufClassName,
explanation, e)
+
+ case e: NoClassDefFoundError if
e.getMessage.matches("com/google/proto.*Generated.*") =>
+// This indicates the the the Java classes are not shaded.
+throw QueryCompilationErrors.protobufClassLoadError(
+ protobufClassName, missingShadingErrorMessage, e)
}
-if (!classOf[Message].isAssignableFrom(protobufClass)) {
- throw QueryCompilationErrors.protobufMessageTypeError(protobufClassName)
- // TODO: Need to support V2. This might work with V2 classes too.
+if (!shadedMessageClass.isAssignableFrom(protobufClass)) {
+ // Check if this extends 2.x Message class included in spark, that does
not work.
+ val unshadedMessageClass = Utils.classForName(
+
"com.escape-shading.google.protobuf.Message".replace("escape-shading.", "")
+ )
+ val explanation =
+if (unshadedMessageClass.isAssignableFrom(protobufClass)) {
+ s"$protobufClassName does not extend shaded Protobuf Message class "
+
+ s"${shadedMessageClass.getName}. $missingShadingErrorMessage"
+} else s"$protobufClassName is not a Protobuf Message type"
+ throw QueryCompilationErrors.protobufClassLoadError(protobufClassName,
explanation)
}
// Extract the descriptor from Protobuf message.
-protobufClass
- .getDeclaredMethod("getDescriptor")
+val getDescriptorMethod = try {
+ protobufClass
+.getDeclaredMethod("getDescriptor")
+} catch {
+ case _: NoSuchMethodError => // This is usually not expected.
+throw new IllegalArgumentException(
Review Comment:
Done.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] warrenzhu25 commented on pull request #38441: [SPARK-40979][CORE] Keep removed executor info due to decommission
warrenzhu25 commented on PR #38441: URL: https://github.com/apache/spark/pull/38441#issuecomment-1315971701 > Can you move `SCHEDULER_MAX_RETAINED_REMOVED_EXECUTORS` to below `STAGE_IGNORE_DECOMMISSION_FETCH_FAILURE` ? This is causing the build failure. Updated. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #38539: [SPARK-41030][BUILD] Upgrade `Apache Ivy` to 2.5.1
dongjoon-hyun commented on PR #38539: URL: https://github.com/apache/spark/pull/38539#issuecomment-1315901316 We need to validate this dependency change in `master` (for Apache Spark 3.4.0) first. Did you use this in your production environment? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #38651: [SPARK-41136][K8S] Shorten graceful shutdown time of ExecutorPodsSnapshotsStoreImpl to prevent blocking shutdown process
dongjoon-hyun commented on code in PR #38651:
URL: https://github.com/apache/spark/pull/38651#discussion_r1023278795
##
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/Config.scala:
##
@@ -723,6 +723,18 @@ private[spark] object Config extends Logging {
.checkValue(value => value > 0, "Maximum number of pending pods should
be a positive integer")
.createWithDefault(Int.MaxValue)
+ val KUBERNETES_EXECUTOR_SNAPSHOTS_SUBSCRIBERS_GRACE_PERIOD =
+
ConfigBuilder("spark.kubernetes.executorSnapshotsSubscribersShutdownGracePeriod")
+ .doc("Time to wait for graceful shutdown
kubernetes-executor-snapshots-subscribers " +
+"thread pool. Since it may be called by ShutdownHookManager, where
timeout is " +
+"controlled by hadoop configuration `hadoop.service.shutdown.timeout`
" +
+"(default is 30s). As the whole Spark shutdown procedure shares the
above timeout, " +
+"this value should be short than that to prevent blocking the
following shutdown " +
+"procedures.")
+ .version("3.4.0")
+ .timeConf(TimeUnit.SECONDS)
Review Comment:
Please add `checkValue`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk opened a new pull request, #38665: [WIP][SQL] Remove the class `TypeCheckFailure`
MaxGekk opened a new pull request, #38665: URL: https://github.com/apache/spark/pull/38665 ### What changes were proposed in this pull request? ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #38651: [SPARK-41136][K8S] Shorten graceful shutdown time of ExecutorPodsSnapshotsStoreImpl to prevent blocking shutdown process
dongjoon-hyun commented on code in PR #38651: URL: https://github.com/apache/spark/pull/38651#discussion_r1023277805 ## resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsSnapshotsStoreImpl.scala: ## @@ -57,6 +60,7 @@ import org.apache.spark.util.ThreadUtils * The subscriber notification callback is guaranteed to be called from a single thread at a time. */ private[spark] class ExecutorPodsSnapshotsStoreImpl( +conf: SparkConf, Review Comment: Although this is a `private`, please provide a backward-compatibility in this case by keeping the existing constructor and adding a new one with new parameter `conf`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #38620: [SPARK-41113][BUILD] Upgrade sbt to 1.8.0
dongjoon-hyun closed pull request #38620: [SPARK-41113][BUILD] Upgrade sbt to 1.8.0 URL: https://github.com/apache/spark/pull/38620 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #38620: [SPARK-41113][BUILD] Upgrade sbt to 1.8.0
dongjoon-hyun commented on PR #38620: URL: https://github.com/apache/spark/pull/38620#issuecomment-1315885828 That will be enough, @LuciferYang . Thank you, @LuciferYang and @HyukjinKwon . Merged to master. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on a diff in pull request #38595: [SPARK-41090][SQL] Throw Exception for `db_name.view_name` when creating temp view by Dataset API
amaliujia commented on code in PR #38595:
URL: https://github.com/apache/spark/pull/38595#discussion_r1023261314
##
sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryParsingErrors.scala:
##
@@ -542,11 +542,11 @@ private[sql] object QueryParsingErrors extends
QueryErrorsBase {
}
def notAllowedToAddDBPrefixForTempViewError(
- database: String,
+ viewName: String,
Review Comment:
Good idea. Done.
##
core/src/main/resources/error/error-classes.json:
##
@@ -933,6 +933,11 @@
],
"sqlState" : "42000"
},
+ "TEMP_VIEW_NAME_CONTAINS_UNSUPPORTED_NAME_PARTS" : {
Review Comment:
I see. Updated
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on a diff in pull request #38630: [SPARK-41115][CONNECT] Add ClientType to proto to indicate which client sends a request
grundprinzip commented on code in PR #38630:
URL: https://github.com/apache/spark/pull/38630#discussion_r1023255565
##
connector/connect/src/main/protobuf/spark/connect/base.proto:
##
@@ -48,6 +48,11 @@ message Request {
// The logical plan to be executed / analyzed.
Plan plan = 3;
+ // Provides optional information about the client sending the request. This
field
+ // can be used for language or version specific information and is only
intended for
+ // logging purposes and will not be interpreted by the server.
+ optional string client_type = 4;
Review Comment:
No, this is purely a string and not an extension type based on `Any`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on a diff in pull request #38609: [SPARK-40593][BUILD][CONNECT] Make user can build and test `connect` module by specifying the user-defined `protoc` and `proto
grundprinzip commented on code in PR #38609:
URL: https://github.com/apache/spark/pull/38609#discussion_r1023252592
##
connector/connect/README.md:
##
@@ -24,7 +24,31 @@ or
```bash
./build/sbt -Phive clean package
```
-
+
+### Build with user-defined `protoc` and `protoc-gen-grpc-java`
+
+When the user cannot use the official `protoc` and `protoc-gen-grpc-java`
binary files to build the `connect` module in the compilation environment,
+for example, compiling `connect` module on CentOS 6 or CentOS 7 which the
default `glibc` version is less than 2.14, we can try to compile and test by
+specifying the user-defined `protoc` and `protoc-gen-grpc-java` binary files
as follows:
+
+```bash
+export CONNECT_PROTOC_EXEC_PATH=/path-to-protoc-exe
+export CONNECT_PLUGIN_EXEC_PATH=/path-to-protoc-gen-grpc-java-exe
+./build/mvn -Phive -Puser-defined-pb clean package
Review Comment:
From a consistency perspective I'm suggesting to actually call the profile
`user-defined-protoc` because it points to the `protoc` compiler.
```suggestion
./build/mvn -Phive -Puser-defined-protoc clean package
```
##
connector/connect/pom.xml:
##
@@ -371,4 +350,68 @@
+
+
+ official-pb
Review Comment:
```suggestion
default-protoc
```
##
connector/connect/README.md:
##
@@ -24,7 +24,31 @@ or
```bash
./build/sbt -Phive clean package
```
-
+
+### Build with user-defined `protoc` and `protoc-gen-grpc-java`
+
+When the user cannot use the official `protoc` and `protoc-gen-grpc-java`
binary files to build the `connect` module in the compilation environment,
+for example, compiling `connect` module on CentOS 6 or CentOS 7 which the
default `glibc` version is less than 2.14, we can try to compile and test by
+specifying the user-defined `protoc` and `protoc-gen-grpc-java` binary files
as follows:
+
+```bash
+export CONNECT_PROTOC_EXEC_PATH=/path-to-protoc-exe
+export CONNECT_PLUGIN_EXEC_PATH=/path-to-protoc-gen-grpc-java-exe
+./build/mvn -Phive -Puser-defined-pb clean package
+```
+
+or
+
+```bash
+export CONNECT_PROTOC_EXEC_PATH=/path-to-protoc-exe
+export CONNECT_PLUGIN_EXEC_PATH=/path-to-protoc-gen-grpc-java-exe
+./build/sbt -Puser-defined-pb clean package
Review Comment:
```suggestion
./build/sbt -Puser-defined-protoc clean package
```
##
connector/connect/pom.xml:
##
@@ -371,4 +350,68 @@
+
+
+ official-pb
+
+true
+
+
+
+
+
+org.xolstice.maven.plugins
+protobuf-maven-plugin
+0.6.1
+
+
com.google.protobuf:protoc:${protobuf.version}:exe:${os.detected.classifier}
+ grpc-java
+
io.grpc:protoc-gen-grpc-java:${io.grpc.version}:exe:${os.detected.classifier}
+ src/main/protobuf
+
+
+
+
+ compile
+ compile-custom
+ test-compile
+
+
+
+
+
+
+
+
+ user-defined-pb
Review Comment:
```suggestion
user-defined-protoc
```
##
project/SparkBuild.scala:
##
@@ -109,6 +109,14 @@ object SparkBuild extends PomBuild {
if (profiles.contains("jdwp-test-debug")) {
sys.props.put("test.jdwp.enabled", "true")
}
+if (profiles.contains("user-defined-pb")) {
Review Comment:
```suggestion
if (profiles.contains("user-defined-protoc")) {
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a diff in pull request #38511: [SPARK-41017][SQL] Support column pruning with multiple nondeterministic Filters
gengliangwang commented on code in PR #38511:
URL: https://github.com/apache/spark/pull/38511#discussion_r1023241331
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/planning/patterns.scala:
##
@@ -29,26 +29,13 @@ import org.apache.spark.sql.errors.QueryCompilationErrors
import org.apache.spark.sql.execution.datasources.v2.{DataSourceV2Relation,
DataSourceV2ScanRelation}
import org.apache.spark.sql.internal.SQLConf
-/**
- * A pattern that matches any number of project or filter operations even if
they are
- * non-deterministic, as long as they satisfy the requirement of
CollapseProject and CombineFilters.
- * All filter operators are collected and their conditions are broken up and
returned
- * together with the top project operator. [[Alias Aliases]] are
in-lined/substituted if
- * necessary.
- */
-object PhysicalOperation extends AliasHelper with PredicateHelper {
+trait OperationHelper extends AliasHelper with PredicateHelper {
import
org.apache.spark.sql.catalyst.optimizer.CollapseProject.canCollapseExpressions
- type ReturnType =
-(Seq[NamedExpression], Seq[Expression], LogicalPlan)
type IntermediateType =
-(Option[Seq[NamedExpression]], Seq[Expression], LogicalPlan,
AttributeMap[Alias])
+(Option[Seq[NamedExpression]], Seq[Seq[Expression]], LogicalPlan,
AttributeMap[Alias])
- def unapply(plan: LogicalPlan): Option[ReturnType] = {
-val alwaysInline =
SQLConf.get.getConf(SQLConf.COLLAPSE_PROJECT_ALWAYS_INLINE)
-val (fields, filters, child, _) = collectProjectsAndFilters(plan,
alwaysInline)
-Some((fields.getOrElse(child.output), filters, child))
- }
+ protected def canKeepMultipleFilters: Boolean
Review Comment:
Nit: add a simple comment
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a diff in pull request #38511: [SPARK-41017][SQL] Support column pruning with multiple nondeterministic Filters
gengliangwang commented on code in PR #38511:
URL: https://github.com/apache/spark/pull/38511#discussion_r1023241088
##
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileSourceStrategy.scala:
##
@@ -146,8 +146,12 @@ object FileSourceStrategy extends Strategy with
PredicateHelper with Logging {
}
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
-case PhysicalOperation(projects, filters,
+case ScanOperation(projects, allFilters,
l @ LogicalRelation(fsRelation: HadoopFsRelation, _, table, _)) =>
+ // We can only push down the bottom-most filter to the relation, as
`ScanOperation` decided to
+ // not merge these filters and we need to keep their evaluation order.
+ val filters = allFilters.lastOption.getOrElse(Nil)
Review Comment:
So for filter pushdown, we will use the last filter. For schema pruning, we
will use all the filters.
I wonder if we should return both `allFilters` and `pushdownFilters` to make
the syntax clear.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a diff in pull request #38647: [SPARK-41133][SQL] Integrate `UNSCALED_VALUE_TOO_LARGE_FOR_PRECISION` into `NUMERIC_VALUE_OUT_OF_RANGE`
MaxGekk commented on code in PR #38647:
URL: https://github.com/apache/spark/pull/38647#discussion_r1023238958
##
connector/avro/src/test/scala/org/apache/spark/sql/avro/AvroLogicalTypeSuite.scala:
##
@@ -436,7 +436,7 @@ abstract class AvroLogicalTypeSuite extends QueryTest with
SharedSparkSession {
val msg = intercept[SparkException] {
spark.read.format("avro").load(s"$dir.avro").collect()
}.getCause.getCause.getMessage
- assert(msg.contains("Unscaled value too large for precision"))
+ assert(msg.contains("[NUMERIC_VALUE_OUT_OF_RANGE]"))
Review Comment:
Could you use `checkError()`, please.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk closed pull request #38531: [SPARK-40755][SQL] Migrate type check failures of number formatting onto error classes
MaxGekk closed pull request #38531: [SPARK-40755][SQL] Migrate type check failures of number formatting onto error classes URL: https://github.com/apache/spark/pull/38531 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on pull request #38531: [SPARK-40755][SQL] Migrate type check failures of number formatting onto error classes
MaxGekk commented on PR #38531: URL: https://github.com/apache/spark/pull/38531#issuecomment-1315834870 +1, LGTM. Merging to master. Thank you, @panbingkun and @cloud-fan @srielau for review. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a diff in pull request #38531: [SPARK-40755][SQL] Migrate type check failures of number formatting onto error classes
MaxGekk commented on code in PR #38531:
URL: https://github.com/apache/spark/pull/38531#discussion_r1023233663
##
core/src/main/resources/error/error-classes.json:
##
@@ -290,6 +290,46 @@
"Null typed values cannot be used as arguments of ."
]
},
+ "NUM_FORMAT_CONT_THOUSANDS_SEPS" : {
Review Comment:
> This must be fixed before we cut 12.0.
Definitely, it will be fixed before Spark 12.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] kyle-ai2 commented on pull request #38539: [SPARK-41030][BUILD] Upgrade `Apache Ivy` to 2.5.1
kyle-ai2 commented on PR #38539: URL: https://github.com/apache/spark/pull/38539#issuecomment-1315814385 Hello @dongjoon-hyun, Will this fix be backported for Spark 3.2 as well? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] WweiL commented on a diff in pull request #38503: [SPARK-40940] Remove Multi-stateful operator checkers for streaming queries.
WweiL commented on code in PR #38503:
URL: https://github.com/apache/spark/pull/38503#discussion_r1021870148
##
sql/core/src/test/scala/org/apache/spark/sql/streaming/StreamingDeduplicationSuite.scala:
##
@@ -190,20 +190,25 @@ class StreamingDeduplicationSuite extends
StateStoreMetricsTest {
.agg(sum("num"))
.as[(String, Long)]
-testStream(result, Update)(
- AddData(inputData, "a" -> 1),
- CheckLastBatch("a" -> 1L),
- assertNumStateRows(total = Seq(1L, 1L), updated = Seq(1L, 1L)),
- AddData(inputData, "a" -> 1), // Dropped
- CheckLastBatch(),
- assertNumStateRows(total = Seq(1L, 1L), updated = Seq(0L, 0L)),
- AddData(inputData, "a" -> 2),
- CheckLastBatch("a" -> 3L),
- assertNumStateRows(total = Seq(1L, 2L), updated = Seq(1L, 1L)),
- AddData(inputData, "b" -> 1),
- CheckLastBatch("b" -> 1L),
- assertNumStateRows(total = Seq(2L, 3L), updated = Seq(1L, 1L))
-)
+// As of [SPARK-40940], multiple state operator with Complete mode is
disabled by default
Review Comment:
I've made a list, let's discuss this later.
- Deduplication: Only counted as a streaming stateful operator when it has
event time column.
- In Complete, Update mode, Aggregations followed by any stateful operators
are disallowed
- Note that Dedup w/o event time is not counted here.
- flatMapGroupsWithState (and mapGroupWithState, also pandas version):
- If `flatMapGroupsWithState` is configured with processing time, don't
need to check.
- After this PR: `flatMapGroupsWithState`, `MapGroupsWithState` followed
by any stateful operator is disallowed.
- Note that Dedup w/o event time is not counted here.
- After this PR: agg followed by `flatMapGroupsWithState` in Append mode
is allowed.
- Currently: `flatMapGroupsWithState` with agg (no matter before or after
it) in Update mode is not allowed -> [keep this behavior]
- stream-stream join:
- Append mode: time interval join followed by any stateful ops:
disallowed;
- Append mode: equality inner & outer join followed by any stateful op:
supported
- Currently: Only allowed in append mode, inner join with equality ->
[keep this behavior]
- Currently: Outer join with equality and time-interval join are
disallowed -> [keep this behavior]
[Q] Why Dedup doesn't require event-time col? It should create some kind of
state store to do the deduplication, if no watermark are we holding these
states throughout the query?
[A] There may be some cases that key space is bounded. Also why Complete
mode makes sense.
##
sql/core/src/test/scala/org/apache/spark/sql/streaming/StreamingDeduplicationSuite.scala:
##
@@ -190,20 +190,25 @@ class StreamingDeduplicationSuite extends
StateStoreMetricsTest {
.agg(sum("num"))
.as[(String, Long)]
-testStream(result, Update)(
- AddData(inputData, "a" -> 1),
- CheckLastBatch("a" -> 1L),
- assertNumStateRows(total = Seq(1L, 1L), updated = Seq(1L, 1L)),
- AddData(inputData, "a" -> 1), // Dropped
- CheckLastBatch(),
- assertNumStateRows(total = Seq(1L, 1L), updated = Seq(0L, 0L)),
- AddData(inputData, "a" -> 2),
- CheckLastBatch("a" -> 3L),
- assertNumStateRows(total = Seq(1L, 2L), updated = Seq(1L, 1L)),
- AddData(inputData, "b" -> 1),
- CheckLastBatch("b" -> 1L),
- assertNumStateRows(total = Seq(2L, 3L), updated = Seq(1L, 1L))
-)
+// As of [SPARK-40940], multiple state operator with Complete mode is
disabled by default
Review Comment:
Eventually, the above boils down to the simple 3 golden rules:
1. `flatMapGroupsWithState`, `MapGroupsWithState` followed by any stateful
operator is disallowed.
2. Stream-stream time interval join followed by any stateful operator is
disallowed. Note that this is only allowed in Append mode.
3. Aggregation followed by any stateful operators is disallowed in Complete
and Update mode.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a diff in pull request #38511: [SPARK-41017][SQL] Support column pruning with multiple nondeterministic Filters
gengliangwang commented on code in PR #38511:
URL: https://github.com/apache/spark/pull/38511#discussion_r1023204106
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/planning/patterns.scala:
##
@@ -85,15 +72,25 @@ object PhysicalOperation extends AliasHelper with
PredicateHelper {
// projects. We need to meet the following conditions to do so:
// 1) no Project collected so far or the collected Projects are all
deterministic
// 2) the collected filters and this filter are all deterministic,
or this is the
-// first collected filter.
+// first collected filter. This condition can be relaxed if
`canKeepMultipleFilters` is
Review Comment:
TBH, the comment here is hard to understand..
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] anchovYu commented on a diff in pull request #38257: [SPARK-40798][SQL] Alter partition should verify value follow storeAssignmentPolicy
anchovYu commented on code in PR #38257: URL: https://github.com/apache/spark/pull/38257#discussion_r1023195030 ## docs/sql-migration-guide.md: ## @@ -34,6 +34,7 @@ license: | - Valid hexadecimal strings should include only allowed symbols (0-9A-Fa-f). - Valid values for `fmt` are case-insensitive `hex`, `base64`, `utf-8`, `utf8`. - Since Spark 3.4, Spark throws only `PartitionsAlreadyExistException` when it creates partitions but some of them exist already. In Spark 3.3 or earlier, Spark can throw either `PartitionsAlreadyExistException` or `PartitionAlreadyExistsException`. + - Since Spark 3.4, Spark will do validation for partition spec in ALTER PARTITION to follow the behavior of `spark.sql.storeAssignmentPolicy` which may cause an exception if type conversion fails, e.g. `ALTER TABLE .. ADD PARTITION(p='a')` if column `p` is int type. To restore the legacy behavior, set `spark.sql.legacy.skipPartitionSpecTypeValidation` to `true`. Review Comment: The conf should be `spark.sql.legacy.skipTypeValidationOnAlterPartition`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] WweiL commented on a diff in pull request #38503: [SPARK-40940] Remove Multi-stateful operator checkers for streaming queries.
WweiL commented on code in PR #38503:
URL: https://github.com/apache/spark/pull/38503#discussion_r1023192849
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/UnsupportedOperationChecker.scala:
##
@@ -41,41 +42,70 @@ object UnsupportedOperationChecker extends Logging {
}
}
+ private def hasRangeExprAgainstEventTimeCol(e: Expression): Boolean =
e.exists {
+case neq @ (_: LessThanOrEqual | _: LessThan | _: GreaterThanOrEqual | _:
GreaterThan) =>
+ hasEventTimeColNeq(neq)
+case _ => false
+ }
+
+ private def hasEventTimeColNeq(neq: Expression): Boolean = {
Review Comment:
This function is only used in `hasRangeExprAgainstEventTimeCol`. Yes it does
mean not equal, maybe rename it to `hasEventTimeColBinaryComp` makes more
sense.
I did try to change function signature to be `private def
hasEventTimeColNeq(neq: BinaryComparison): Boolean` but the compiler would
complain because here
```
case neq @ (_: LessThanOrEqual | _: LessThan | _: GreaterThanOrEqual | _:
GreaterThan)
```
neq can only be identified as Expression.
I'll just put these two helper functions under
`hasRangeExprAgainstEventTimeCol`, that makes the logic more clear.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] alex-balikov commented on a diff in pull request #38503: [SPARK-40940] Remove Multi-stateful operator checkers for streaming queries.
alex-balikov commented on code in PR #38503:
URL: https://github.com/apache/spark/pull/38503#discussion_r1023155184
##
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/analysis/UnsupportedOperationsSuite.scala:
##
@@ -940,22 +1056,22 @@ class UnsupportedOperationsSuite extends SparkFunSuite
with SQLHelper {
def assertPassOnGlobalWatermarkLimit(
testNamePostfix: String,
plan: LogicalPlan,
- outputMode: OutputMode): Unit = {
-testGlobalWatermarkLimit(testNamePostfix, plan, outputMode, expectFailure
= false)
+ outputMode: OutputMode = OutputMode.Append()): Unit = {
+testGlobalWatermarkLimit(testNamePostfix, plan, expectFailure = false,
outputMode)
}
def assertFailOnGlobalWatermarkLimit(
testNamePostfix: String,
plan: LogicalPlan,
- outputMode: OutputMode): Unit = {
-testGlobalWatermarkLimit(testNamePostfix, plan, outputMode, expectFailure
= true)
+ outputMode: OutputMode = OutputMode.Append()): Unit = {
Review Comment:
ditto
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/UnsupportedOperationChecker.scala:
##
@@ -41,41 +42,70 @@ object UnsupportedOperationChecker extends Logging {
}
}
+ private def hasRangeExprAgainstEventTimeCol(e: Expression): Boolean =
e.exists {
+case neq @ (_: LessThanOrEqual | _: LessThan | _: GreaterThanOrEqual | _:
GreaterThan) =>
+ hasEventTimeColNeq(neq)
+case _ => false
+ }
+
+ private def hasEventTimeColNeq(neq: Expression): Boolean = {
+val exp = neq.asInstanceOf[BinaryComparison]
+hasEventTimeCol(exp.left) || hasEventTimeCol(exp.right)
+ }
+
+ private def hasEventTimeCol(exps: Expression): Boolean =
+exps.exists {
+ case a: AttributeReference =>
a.metadata.contains(EventTimeWatermark.delayKey)
+ case _ => false
+}
+
+ private def isStatefulOperationPossiblyEmitLateRows(
+ p: LogicalPlan, outputMode: OutputMode): Boolean = p match {
+case ExtractEquiJoinKeys(_, _, _, otherCondition, _, left, right, _) =>
+ left.isStreaming && right.isStreaming &&
+otherCondition.isDefined &&
hasRangeExprAgainstEventTimeCol(otherCondition.get)
+// FlatMapGroupsWithState configured with event time
+case f @ FlatMapGroupsWithState(_, _, _, _, _, _, _, _, _, timeout, _, _,
_, _, _, _)
+ if f.isStreaming && timeout == GroupStateTimeout.EventTimeTimeout => true
+case p @ FlatMapGroupsInPandasWithState(_, _, _, _, _, timeout, _)
+ if p.isStreaming && timeout == GroupStateTimeout.EventTimeTimeout => true
+case a: Aggregate if a.isStreaming && outputMode !=
InternalOutputModes.Append => true
+// Since the Distinct node will be replaced to Aggregate in the optimizer
rule
+// [[ReplaceDistinctWithAggregate]], here we also need to check all
Distinct node by
+// assuming it as Aggregate.
+case d @ Distinct(_: LogicalPlan) if d.isStreaming
+ && outputMode != InternalOutputModes.Append => true
+case _ => false
+ }
+
+ private def isStreamingStatefulOperation(p: LogicalPlan): Boolean = p match {
+case s: Aggregate if s.isStreaming => true
+// Since the Distinct node will be replaced to Aggregate in the optimizer
rule
+// [[ReplaceDistinctWithAggregate]], here we also need to check all
Distinct node by
+// assuming it as Aggregate.
+case d @ Distinct(_: LogicalPlan) if d.isStreaming => true
+case _ @ Join(left, right, _, _, _) if left.isStreaming &&
right.isStreaming => true
+case f: FlatMapGroupsWithState if f.isStreaming => true
+case f: FlatMapGroupsInPandasWithState if f.isStreaming => true
+// Deduplicate also works without event time column even in streaming,
+// in such cases, although Dedup is still a stateful operation in a
streaming
+// query, it could be ignored in all checks below, so let it return false.
+case d: Deduplicate if d.isStreaming && d.keys.exists(hasEventTimeCol) =>
true
+case _ => false
+ }
/**
* Checks for possible correctness issue in chained stateful operators. The
behavior is
* controlled by SQL config
`spark.sql.streaming.statefulOperator.checkCorrectness.enabled`.
* Once it is enabled, an analysis exception will be thrown. Otherwise,
Spark will just
* print a warning message.
*/
- def checkStreamingQueryGlobalWatermarkLimit(
- plan: LogicalPlan,
- outputMode: OutputMode): Unit = {
-def isStatefulOperationPossiblyEmitLateRows(p: LogicalPlan): Boolean = p
match {
- case s: Aggregate
-if s.isStreaming && outputMode == InternalOutputModes.Append => true
- case Join(left, right, joinType, _, _)
-if left.isStreaming && right.isStreaming && joinType != Inner => true
- case f: FlatMapGroupsWithState
-if f.isStreaming && f.outputMode == OutputMode.Append() => true
- case _ => false
-}
-
-def isStatefulOperation(p: LogicalPlan): Boolean = p match {
- case
[GitHub] [spark] xinrong-meng commented on a diff in pull request #38611: [SPARK-41107][PYTHON][INFRA][TESTS] Install memory-profiler in the CI
xinrong-meng commented on code in PR #38611: URL: https://github.com/apache/spark/pull/38611#discussion_r1023163181 ## dev/infra/Dockerfile: ## @@ -32,7 +32,7 @@ RUN $APT_INSTALL software-properties-common git libxml2-dev pkg-config curl wget RUN update-alternatives --set java /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java RUN curl -sS https://bootstrap.pypa.io/get-pip.py | python3.9 -RUN python3.9 -m pip install numpy pyarrow 'pandas<=1.5.1' scipy unittest-xml-reporting plotly>=4.8 sklearn 'mlflow>=1.0' coverage matplotlib openpyxl +RUN python3.9 -m pip install numpy pyarrow 'pandas<=1.5.1' scipy unittest-xml-reporting plotly>=4.8 sklearn 'mlflow>=1.0' coverage matplotlib openpyxl 'memory-profiler==0.60.0' RUN add-apt-repository ppa:pypy/ppa Review Comment: Thanks! I'll retry. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on a diff in pull request #38605: [SPARK-41103][CONNECT][DOC] Document how to add a new proto field of messages
grundprinzip commented on code in PR #38605: URL: https://github.com/apache/spark/pull/38605#discussion_r1023155908 ## connector/connect/README.md: ## @@ -70,3 +70,4 @@ When contributing a new client please be aware that we strive to have a common user experience across all languages. Please follow the below guidelines: * [Connection string configuration](docs/client-connection-string.md) +* [Adding-proto-messages](docs/adding-proto-messages.md) Review Comment: ```suggestion * [Adding new messages](docs/adding-proto-messages.md) in the Spark Connect protocol. ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] WweiL commented on pull request #38503: [SPARK-40940] Remove Multi-stateful operator checkers for streaming queries.
WweiL commented on PR #38503: URL: https://github.com/apache/spark/pull/38503#issuecomment-1315727807 > Shouldn't you also fix https://github.com/apache/spark/blob/master/sql/core/src/test/scala/org/apache/spark/sql/streaming/MultiStatefulOperatorsSuite.scala to remove the flag->false setting? Oh I'm sorry. There were some problems when I'm rebasing the branch. I'll add it now. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] alex-balikov commented on pull request #38503: [SPARK-40940] Remove Multi-stateful operator checkers for streaming queries.
alex-balikov commented on PR #38503: URL: https://github.com/apache/spark/pull/38503#issuecomment-1315726141 Shouldn't you also fix https://github.com/apache/spark/blob/master/sql/core/src/test/scala/org/apache/spark/sql/streaming/MultiStatefulOperatorsSuite.scala to remove the flag->false setting? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on pull request #38605: [SPARK-41103][CONNECT][DOC] Document how to add a new proto field of messages
amaliujia commented on PR #38605: URL: https://github.com/apache/spark/pull/38605#issuecomment-1315721838 @grundprinzip suggestions applied. The doc look much better now with some more details filled in. Minding take another look? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] vinodkc commented on pull request #38608: [SPARK-41080][SQL] Support Bit manipulation function SETBIT
vinodkc commented on PR #38608: URL: https://github.com/apache/spark/pull/38608#issuecomment-1315718307 CC @cloud-fan , @HyukjinKwon , @dongjoon-hyun Can you please review this PR ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] vinodkc commented on pull request #38661: [SPARK-41085][SQL] Support Bit manipulation function COUNTSET
vinodkc commented on PR #38661: URL: https://github.com/apache/spark/pull/38661#issuecomment-1315717202 CC @cloud-fan , @HyukjinKwon Can you please review this PR? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] warrenzhu25 commented on a diff in pull request #38441: [SPARK-40979][CORE] Keep removed executor info due to decommission
warrenzhu25 commented on code in PR #38441: URL: https://github.com/apache/spark/pull/38441#discussion_r1023138870 ## core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala: ## @@ -2193,9 +2193,11 @@ private[spark] class DAGScheduler( * Return true when: * 1. Waiting for decommission start * 2. Under decommission process - * Return false when: - * 1. Stopped or terminated after finishing decommission - * 2. Under decommission process, then removed by driver with other reasons + * 3. Stopped or terminated after finishing decommission + * 4. Under decommission process, then removed by driver with other reasons Review Comment: Yes, upated. ## core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala: ## @@ -2193,9 +2193,11 @@ private[spark] class DAGScheduler( * Return true when: * 1. Waiting for decommission start * 2. Under decommission process - * Return false when: - * 1. Stopped or terminated after finishing decommission - * 2. Under decommission process, then removed by driver with other reasons + * 3. Stopped or terminated after finishing decommission + * 4. Under decommission process, then removed by driver with other reasons Review Comment: Yes, updated. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] vinodkc commented on pull request #38419: [SPARK-40945][SQL] Support built-in function to truncate numbers
vinodkc commented on PR #38419: URL: https://github.com/apache/spark/pull/38419#issuecomment-1315715844 @cloud-fan , yes we could share common code among 3 functions (trunc, floor, ceil). Updated the PR -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on pull request #38659: [SPARK-41114][CONNECT] Support local data for LocalRelation
amaliujia commented on PR #38659: URL: https://github.com/apache/spark/pull/38659#issuecomment-1315710131 @dengziming thanks! BTW you can try to covert this PR to `draft` then re-open when you think it is ready for review again. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] mridulm commented on pull request #38333: [SPARK-40872] Fallback to original shuffle block when a push-merged shuffle chunk is zero-size
mridulm commented on PR #38333: URL: https://github.com/apache/spark/pull/38333#issuecomment-1315695999 Also, can you please update to latest master @gaoyajun02 ? Not sure why we are seeing the linter failure in build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] mridulm commented on pull request #38333: [SPARK-40872] Fallback to original shuffle block when a push-merged shuffle chunk is zero-size
mridulm commented on PR #38333: URL: https://github.com/apache/spark/pull/38333#issuecomment-1315692121 There is a pending [comment](https://github.com/apache/spark/pull/38333/files#r1019735633), can you take a look at it @gaoyajun02 ? Thx -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] leewyang commented on pull request #37734: [SPARK-40264][ML] add batch_infer_udf function to pyspark.ml.functions
leewyang commented on PR #37734:
URL: https://github.com/apache/spark/pull/37734#issuecomment-1315678614
BTW, I'm seeing a change in behavior in the `pandas_udf` when used with
`limit` in the latest master branch of spark (vs. 3.3.1), per this example code:
```
import numpy as np
import pandas as pd
from pyspark.sql.functions import pandas_udf
from pyspark.sql.types import DoubleType
data = np.arange(0, 1000, dtype=np.float64)
pdf = pd.DataFrame(data, columns=['x'])
df = spark.createDataFrame(pdf)
@pandas_udf(returnType=DoubleType())
def times_two(x):
print(x.shape)
return x*2
# 3.3.1: shape = (10,)
# master: shape = (500,)
df.limit(10).withColumn("x2", times_two("x")).collect()
```
Not sure if this is a regression or an intentional change, but it does
impact performance for this PR, since a given model will be run against 500
rows instead of 10 (even though the final results show only 10 rows).
Basically, it looks like the `limit` function is being applied _after_ running
the `pandas_udf` on a full partition, whereas it used to be applied _before_
running the `pandas_udf`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] WweiL closed pull request #38503: [SPARK-40940] Remove Multi-stateful operator checkers for streaming queries.
WweiL closed pull request #38503: [SPARK-40940] Remove Multi-stateful operator checkers for streaming queries. URL: https://github.com/apache/spark/pull/38503 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dtenedor commented on a diff in pull request #38663: [SPARK-41143][SQL] Add named argument function syntax support
dtenedor commented on code in PR #38663: URL: https://github.com/apache/spark/pull/38663#discussion_r1023072531 ## sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBaseParser.g4: ## @@ -769,7 +769,7 @@ inlineTable ; functionTable -: funcName=functionName LEFT_PAREN (expression (COMMA expression)*)? RIGHT_PAREN tableAlias +: funcName=functionName LEFT_PAREN (functionArgument (COMMA functionArgument)*)? RIGHT_PAREN tableAlias Review Comment: here in the `.g4` file, we only change the syntax for table function calls, but the PR title and description mention general named argument support. Can we either: 1. update the PR description, or 2. update the `functionCall` rule to replace `argument+=expression` with `argument+=functionArgument`? Up to you, the latter would be nice since we can make all the parser changes in the same PR. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dtenedor commented on a diff in pull request #38663: [SPARK-41143][SQL] Add named argument function syntax support
dtenedor commented on code in PR #38663:
URL: https://github.com/apache/spark/pull/38663#discussion_r1023072531
##
sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBaseParser.g4:
##
@@ -769,7 +769,7 @@ inlineTable
;
functionTable
-: funcName=functionName LEFT_PAREN (expression (COMMA expression)*)?
RIGHT_PAREN tableAlias
+: funcName=functionName LEFT_PAREN (functionArgument (COMMA
functionArgument)*)? RIGHT_PAREN tableAlias
Review Comment:
here in the `.g4` file, we only change the syntax for table function calls,
but the PR title and description mention general named argument support. Can we
either update the PR description or else update the `functionCall` rule to
replace `argument+=expression` with `argument+=functionArgument`? The latter
would be nice since we can make all the parser changes in the same PR.
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/literals.scala:
##
@@ -324,6 +324,21 @@ object LiteralTreeBits {
val nullLiteralBits: BitSet = new ImmutableBitSet(TreePattern.maxId,
LITERAL.id, NULL_LITERAL.id)
}
+case class NamedArgumentExpression(key: String, value: Expression) extends
LeafExpression {
Review Comment:
this is in `literals.scala`, but this new expression is not really a literal
:) can we maybe put this into its own file with a class comment?
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/NamedArgumentFunction.scala:
##
@@ -0,0 +1,92 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.plans.logical
+
+import java.util.Locale
+
+import scala.collection.mutable
+
+import org.apache.spark.sql.catalyst.expressions.{Expression,
NamedArgumentExpression}
+import
org.apache.spark.sql.errors.QueryCompilationErrors.{tableFunctionDuplicateNamedArguments,
tableFunctionUnexpectedArgument}
+import org.apache.spark.sql.types._
+
+/**
+ * A trait to define a named argument function:
+ * Usage: _FUNC_(arg0, arg1, arg2, arg5 => value5, arg8 => value8)
+ *
+ * - Arguments can be passed positionally or by name
+ * - Positional arguments cannot come after a named argument
Review Comment:
from the example, named arguments can come after positional arguments. write
that in the comment too? also maybe we can add other constraints:
* no function call may include two arguments with the same name
* case sensitivity follows the SQLConf.CASE_SENSITIVE boolean configuration
* the function signature must specify the argument names, and the provided
argument names must match the names in the function signature
##
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/parser/PlanParserSuite.scala:
##
@@ -852,6 +852,31 @@ class PlanParserSuite extends AnalysisTest {
stop = 43))
}
+ test("table valued function with named arguments") {
+// All named arguments
+assertEqual(
+ "select * from my_tvf(arg1 => 'value1', arg2 => true)",
+ UnresolvedTableValuedFunction("my_tvf",
+NamedArgumentExpression("arg1", Literal("value1")) ::
+ NamedArgumentExpression("arg2", Literal(true)) :: Nil,
Seq.empty).select(star()))
+
+// Unnamed and named arguments
+assertEqual(
+ "select * from my_tvf(2, arg1 => 'value1', arg2 => true)",
+ UnresolvedTableValuedFunction("my_tvf",
+Literal(2) ::
+ NamedArgumentExpression("arg1", Literal("value1")) ::
+ NamedArgumentExpression("arg2", Literal(true)) :: Nil,
Seq.empty).select(star()))
+
+// Mixed arguments
+assertEqual(
+ "select * from my_tvf(arg1 => 'value1', 2, arg2 => true)",
Review Comment:
thanks for adding these parser tests! can we also add some query tests in
e.g. `SQLQuerySuite` that show what happens if we try to analyze such function
calls with named arguments? do we get an error message, or does the whole
feature work end-to-end?
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/NamedArgumentFunction.scala:
##
@@ -0,0 +1,92 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor licens
[GitHub] [spark] awdavidson commented on pull request #38312: [SPARK-40819][SQL] Timestamp nanos behaviour regression
awdavidson commented on PR #38312: URL: https://github.com/apache/spark/pull/38312#issuecomment-1315558808 > @awdavidson I would like to understand the use case a bit better. Is the parquet file was written by an earlier Spark (version < 3.2) and does the error comes when that parquet file is read back with a latter Spark? If yes this is clearly regression. Still in this case can you please show us how we can reproduce it manually (a small example code for write/read)? > > If it was written by another tool can we got an example parquet file with sample data where the old version works and the new version fails? @attilapiros so the parquet file is being wrote by another process. Spark uses this data to run aggregations and analysis over different time horizons where the nanosecond precision is required. Currently, when using earlier Spark versions (< 3.2) the `TIMESTAMP(NANOS, true)` in the parquet schema is automatically converted to a `LongType`, however, since the moving from parquet `1.10.1` to `1.12.3` and the changes to `ParquetSchemaConverter` an `illegalType()` is thrown. As soon as I have access this evening I will provide an example parquet file. Whilst I understand timestamps with nanosecond precision are not fully supported, this change in behaviour will prevent users from migrating to the latest spark version -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #38659: [SPARK-41114][CONNECT] Support local data for LocalRelation
AmplabJenkins commented on PR #38659: URL: https://github.com/apache/spark/pull/38659#issuecomment-1315548580 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org