[GitHub] [spark] HeartSaVioR commented on a change in pull request #31986: [SPARK-34888][SS] Introduce UpdatingSessionIterator adjusting session window on elements
HeartSaVioR commented on a change in pull request #31986:
URL: https://github.com/apache/spark/pull/31986#discussion_r629900130
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/aggregate/UpdatingSessionsExec.scala
##
@@ -0,0 +1,77 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.aggregate
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute,
SortOrder}
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples,
ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+/**
+ * This node updates the session window spec of each input rows via analyzing
neighbor rows and
+ * determining rows belong to the same session window. The number of input
rows remains the same.
+ * This node requires sort on input rows by group keys + the start time of
session window.
+ *
+ * There are lots of overhead compared to [[MergingSessionsExec]]. Use
[[MergingSessionsExec]]
+ * instead whenever possible. Use this node only when we cannot apply both
calculations
+ * determining session windows and aggregating rows in session window
altogether.
+ *
+ * Refer [[UpdatingSessionsIterator]] for more details.
+ */
+case class UpdatingSessionsExec(
+keyExpressions: Seq[Attribute],
+sessionExpression: Attribute,
+child: SparkPlan) extends UnaryExecNode {
+
+ private val groupingWithoutSessionExpression = keyExpressions.filterNot {
+p => p.semanticEquals(sessionExpression)
+ }
+ private val groupingWithoutSessionAttributes =
+groupingWithoutSessionExpression.map(_.toAttribute)
+
+ override protected def doExecute(): RDD[InternalRow] = {
+val inMemoryThreshold =
sqlContext.conf.sessionWindowBufferInMemoryThreshold
+val spillThreshold = sqlContext.conf.sessionWindowBufferSpillThreshold
+
+child.execute().mapPartitions { iter =>
+ new UpdatingSessionsIterator(iter, keyExpressions, sessionExpression,
+child.output, inMemoryThreshold, spillThreshold)
+}
+ }
+
+ override def output: Seq[Attribute] = child.output
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ override def requiredChildDistribution: Seq[Distribution] = {
+if (groupingWithoutSessionExpression.isEmpty) {
+ AllTuples :: Nil
+} else {
+ ClusteredDistribution(groupingWithoutSessionExpression) :: Nil
+}
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] = {
+Seq((groupingWithoutSessionAttributes ++ Seq(sessionExpression))
Review comment:
We don't reorder the columns if I remember correctly, but I might be
wrong as the overall code is quite ancient even for me. At least it's more
natural not to reorder - if we reorder the columns in whole picture, I'd rather
want to fix that.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #31986: [SPARK-34888][SS] Introduce UpdatingSessionIterator adjusting session window on elements
HeartSaVioR commented on a change in pull request #31986:
URL: https://github.com/apache/spark/pull/31986#discussion_r629900797
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/aggregate/UpdatingSessionsExec.scala
##
@@ -0,0 +1,77 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.aggregate
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute,
SortOrder}
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples,
ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+/**
+ * This node updates the session window spec of each input rows via analyzing
neighbor rows and
+ * determining rows belong to the same session window. The number of input
rows remains the same.
+ * This node requires sort on input rows by group keys + the start time of
session window.
+ *
+ * There are lots of overhead compared to [[MergingSessionsExec]]. Use
[[MergingSessionsExec]]
+ * instead whenever possible. Use this node only when we cannot apply both
calculations
+ * determining session windows and aggregating rows in session window
altogether.
+ *
+ * Refer [[UpdatingSessionsIterator]] for more details.
+ */
+case class UpdatingSessionsExec(
+keyExpressions: Seq[Attribute],
+sessionExpression: Attribute,
+child: SparkPlan) extends UnaryExecNode {
+
+ private val groupingWithoutSessionExpression = keyExpressions.filterNot {
+p => p.semanticEquals(sessionExpression)
+ }
+ private val groupingWithoutSessionAttributes =
+groupingWithoutSessionExpression.map(_.toAttribute)
+
+ override protected def doExecute(): RDD[InternalRow] = {
+val inMemoryThreshold =
sqlContext.conf.sessionWindowBufferInMemoryThreshold
+val spillThreshold = sqlContext.conf.sessionWindowBufferSpillThreshold
+
+child.execute().mapPartitions { iter =>
+ new UpdatingSessionsIterator(iter, keyExpressions, sessionExpression,
+child.output, inMemoryThreshold, spillThreshold)
+}
+ }
+
+ override def output: Seq[Attribute] = child.output
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ override def requiredChildDistribution: Seq[Distribution] = {
+if (groupingWithoutSessionExpression.isEmpty) {
+ AllTuples :: Nil
+} else {
+ ClusteredDistribution(groupingWithoutSessionExpression) :: Nil
+}
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] = {
+Seq((groupingWithoutSessionAttributes ++ Seq(sessionExpression))
Review comment:
That said, other parts should be checked as well - probably it has some
logic relying on this.
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/aggregate/UpdatingSessionsExec.scala
##
@@ -0,0 +1,77 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.aggregate
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute,
SortOrder}
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples,
ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+/**
+ * This node updates the session window spec of each i
[GitHub] [spark] HeartSaVioR commented on a change in pull request #31986: [SPARK-34888][SS] Introduce UpdatingSessionIterator adjusting session window on elements
HeartSaVioR commented on a change in pull request #31986:
URL: https://github.com/apache/spark/pull/31986#discussion_r629900797
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/aggregate/UpdatingSessionsExec.scala
##
@@ -0,0 +1,77 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.aggregate
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute,
SortOrder}
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples,
ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+/**
+ * This node updates the session window spec of each input rows via analyzing
neighbor rows and
+ * determining rows belong to the same session window. The number of input
rows remains the same.
+ * This node requires sort on input rows by group keys + the start time of
session window.
+ *
+ * There are lots of overhead compared to [[MergingSessionsExec]]. Use
[[MergingSessionsExec]]
+ * instead whenever possible. Use this node only when we cannot apply both
calculations
+ * determining session windows and aggregating rows in session window
altogether.
+ *
+ * Refer [[UpdatingSessionsIterator]] for more details.
+ */
+case class UpdatingSessionsExec(
+keyExpressions: Seq[Attribute],
+sessionExpression: Attribute,
+child: SparkPlan) extends UnaryExecNode {
+
+ private val groupingWithoutSessionExpression = keyExpressions.filterNot {
+p => p.semanticEquals(sessionExpression)
+ }
+ private val groupingWithoutSessionAttributes =
+groupingWithoutSessionExpression.map(_.toAttribute)
+
+ override protected def doExecute(): RDD[InternalRow] = {
+val inMemoryThreshold =
sqlContext.conf.sessionWindowBufferInMemoryThreshold
+val spillThreshold = sqlContext.conf.sessionWindowBufferSpillThreshold
+
+child.execute().mapPartitions { iter =>
+ new UpdatingSessionsIterator(iter, keyExpressions, sessionExpression,
+child.output, inMemoryThreshold, spillThreshold)
+}
+ }
+
+ override def output: Seq[Attribute] = child.output
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ override def requiredChildDistribution: Seq[Distribution] = {
+if (groupingWithoutSessionExpression.isEmpty) {
+ AllTuples :: Nil
+} else {
+ ClusteredDistribution(groupingWithoutSessionExpression) :: Nil
+}
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] = {
+Seq((groupingWithoutSessionAttributes ++ Seq(sessionExpression))
Review comment:
That said, other parts should be checked as well - probably they might
have some logic relying on this.
EDIT: probably it might be OK to reorder at first, and leverage the fact,
and reorder back later. My preference is still not to reorder, but if it brings
some benefits then we could do.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] shahidki31 opened a new pull request #32498: [SPARK-35368][SQL]Update histogram statistics for RANGE operator stats estimation
shahidki31 opened a new pull request #32498: URL: https://github.com/apache/spark/pull/32498 ### What changes were proposed in this pull request? Update histogram statistics for RANGE operator stats estimation ### Why are the changes needed? If histogram optimization is enabled, this statistics can be used in various cost based optimizations. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added UTs. Manual test. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32476: [SPARK-35349][SQL] Add code-gen for left/right outer sort merge join
SparkQA commented on pull request #32476: URL: https://github.com/apache/spark/pull/32476#issuecomment-837966094 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32464: [SPARK-35062][SQL] Group exception messages in sql/streaming
SparkQA commented on pull request #32464: URL: https://github.com/apache/spark/pull/32464#issuecomment-837967685 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32464: [SPARK-35062][SQL] Group exception messages in sql/streaming
AmplabJenkins commented on pull request #32464: URL: https://github.com/apache/spark/pull/32464#issuecomment-837972338 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42884/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32476: [SPARK-35349][SQL] Add code-gen for left/right outer sort merge join
AmplabJenkins commented on pull request #32476: URL: https://github.com/apache/spark/pull/32476#issuecomment-837972336 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42883/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32476: [SPARK-35349][SQL] Add code-gen for left/right outer sort merge join
AmplabJenkins removed a comment on pull request #32476: URL: https://github.com/apache/spark/pull/32476#issuecomment-837972336 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42883/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32464: [SPARK-35062][SQL] Group exception messages in sql/streaming
AmplabJenkins removed a comment on pull request #32464: URL: https://github.com/apache/spark/pull/32464#issuecomment-837972338 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42884/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32478: [SPARK-35063][SQL] Group exception messages in sql/catalyst
SparkQA commented on pull request #32478: URL: https://github.com/apache/spark/pull/32478#issuecomment-837973163 **[Test build #138363 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138363/testReport)** for PR 32478 at commit [`840c0cc`](https://github.com/apache/spark/commit/840c0cc823b63b9d917ac9283a78c647cc5b34f8). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32498: [SPARK-35368][SQL]Update histogram statistics for RANGE operator for stats estimation
SparkQA commented on pull request #32498: URL: https://github.com/apache/spark/pull/32498#issuecomment-837972977 **[Test build #138362 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138362/testReport)** for PR 32498 at commit [`5191d9f`](https://github.com/apache/spark/commit/5191d9f8398abf5a49695eaa3ea1f2340623a596). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32461: [SPARK-35146][SQL] Migrate to transformWithPruning or resolveWithPruning for rules in finishAnalysis.scala
SparkQA commented on pull request #32461: URL: https://github.com/apache/spark/pull/32461#issuecomment-837973217 **[Test build #138364 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138364/testReport)** for PR 32461 at commit [`a5f4fee`](https://github.com/apache/spark/commit/a5f4feea4d0b7e68e6632b168568b4ea0be4). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32439: [SPARK-35298][SQL] Migrate to transformWithPruning for rules in Optimizer.scala
SparkQA commented on pull request #32439: URL: https://github.com/apache/spark/pull/32439#issuecomment-837973357 **[Test build #138365 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138365/testReport)** for PR 32439 at commit [`27e92ea`](https://github.com/apache/spark/commit/27e92ea64de3757fea289d1a2a193af015149c8c). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32478: [SPARK-35063][SQL] Group exception messages in sql/catalyst
SparkQA commented on pull request #32478: URL: https://github.com/apache/spark/pull/32478#issuecomment-837974936 **[Test build #138363 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138363/testReport)** for PR 32478 at commit [`840c0cc`](https://github.com/apache/spark/commit/840c0cc823b63b9d917ac9283a78c647cc5b34f8). * This patch **fails Scala style tests**. * This patch merges cleanly. * This patch adds no public classes. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32478: [SPARK-35063][SQL] Group exception messages in sql/catalyst
AmplabJenkins commented on pull request #32478: URL: https://github.com/apache/spark/pull/32478#issuecomment-837974982 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138363/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32478: [SPARK-35063][SQL] Group exception messages in sql/catalyst
SparkQA removed a comment on pull request #32478: URL: https://github.com/apache/spark/pull/32478#issuecomment-837973163 **[Test build #138363 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138363/testReport)** for PR 32478 at commit [`840c0cc`](https://github.com/apache/spark/commit/840c0cc823b63b9d917ac9283a78c647cc5b34f8). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32478: [SPARK-35063][SQL] Group exception messages in sql/catalyst
AmplabJenkins removed a comment on pull request #32478: URL: https://github.com/apache/spark/pull/32478#issuecomment-837974982 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138363/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32497: [SPARK-35366][SQL] Avoid using deprecated `buildForBatch` and `buildForStreaming`
SparkQA commented on pull request #32497: URL: https://github.com/apache/spark/pull/32497#issuecomment-837991589 **[Test build #138366 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138366/testReport)** for PR 32497 at commit [`aa51f84`](https://github.com/apache/spark/commit/aa51f84e0bef9e078683b29ff489a81d5e6baf35). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] JkSelf commented on a change in pull request #31756: [SPARK-34637] [SQL] Support DPP + AQE when the broadcast exchange can be reused
JkSelf commented on a change in pull request #31756:
URL: https://github.com/apache/spark/pull/31756#discussion_r629918664
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/DynamicPartitionPruningSuite.scala
##
@@ -1463,6 +1474,37 @@ abstract class DynamicPartitionPruningSuiteBase
}
}
}
+
+ test("SPARK-34637: test DPP side broadcast query stage is created firstly") {
+withSQLConf(SQLConf.DYNAMIC_PARTITION_PRUNING_REUSE_BROADCAST_ONLY.key ->
"true") {
+ val df = sql(
+""" WITH view1 as (
+ | SELECT f.store_id FROM fact_stats f WHERE f.units_sold = 70
group by f.store_id
+ | )
+ |
+ | SELECT * FROM view1 v1 join view1 v2 WHERE v1.store_id =
v2.store_id
+""".stripMargin)
+
+ // A possible resulting query plan:
+ // BroadcastHashJoin
+ // +- HashAggregate
+ //+- ShuffleQueryStage
+ // +- Exchange
+ // +- HashAggregate
+ // +- Filter
+ //+- FileScan
+ // Dynamicpruning Subquery
Review comment:
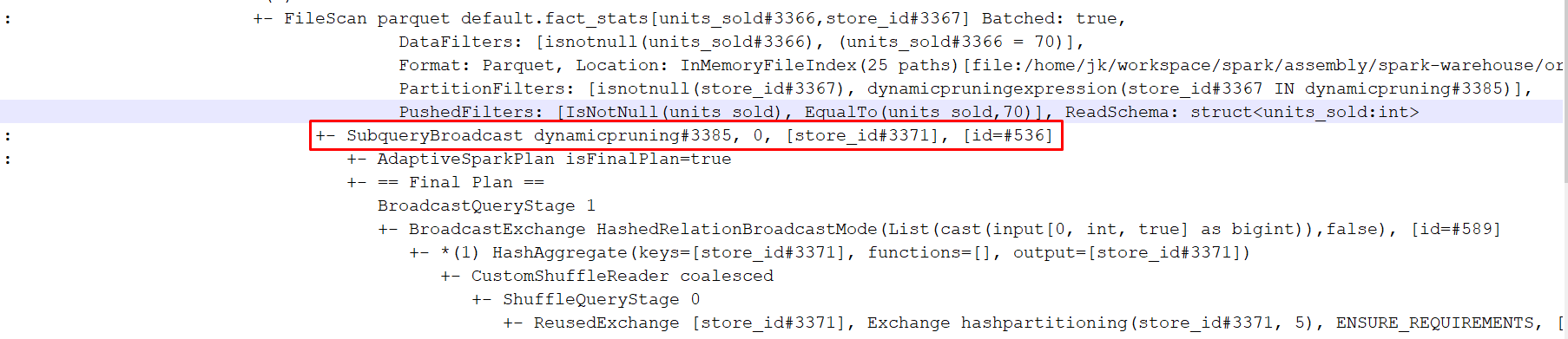
Yes. In this case, it looks like the following:
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31756: [SPARK-34637] [SQL] Support DPP + AQE when the broadcast exchange can be reused
SparkQA commented on pull request #31756: URL: https://github.com/apache/spark/pull/31756#issuecomment-837993646 **[Test build #138367 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138367/testReport)** for PR 31756 at commit [`4ccd4b8`](https://github.com/apache/spark/commit/4ccd4b8b1d2604f05a4564303d0b8aa65ea5dfa3). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] JkSelf commented on a change in pull request #31756: [SPARK-34637] [SQL] Support DPP + AQE when the broadcast exchange can be reused
JkSelf commented on a change in pull request #31756:
URL: https://github.com/apache/spark/pull/31756#discussion_r629918830
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/PlanAdaptiveDynamicPruningFilters.scala
##
@@ -44,12 +42,23 @@ case class PlanAdaptiveDynamicPruningFilters(
val mode = HashedRelationBroadcastMode(packedKeys)
// plan a broadcast exchange of the build side of the join
val exchange = BroadcastExchangeExec(mode, adaptivePlan.executedPlan)
-val existingStage = stageCache.get(exchange.canonicalized)
-if (existingStage.nonEmpty && conf.exchangeReuseEnabled) {
- val name = s"dynamicpruning#${exprId.id}"
- val reuseQueryStage = existingStage.get.newReuseInstance(0,
exchange.output)
- val broadcastValues =
-SubqueryBroadcastExec(name, index, buildKeys, reuseQueryStage)
+
+val canReuseExchange = conf.exchangeReuseEnabled && buildKeys.nonEmpty
&&
+ rootPlan.find {
+case BroadcastHashJoinExec(_, _, _, BuildLeft, _, left, _, _) =>
+ left.sameResult(exchange)
+case BroadcastHashJoinExec(_, _, _, BuildRight, _, _, right, _) =>
+ right.sameResult(exchange)
+case _ => false
+ }.isDefined
+
+if (canReuseExchange) {
+ exchange.setLogicalLink(adaptivePlan.executedPlan.logicalLink.get)
+ val newAdaptivePlan = AdaptiveSparkPlanExec(
+exchange, adaptivePlan.context, adaptivePlan.preprocessingRules,
true)
Review comment:
updated.
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/DynamicPartitionPruningSuite.scala
##
@@ -1463,6 +1474,37 @@ abstract class DynamicPartitionPruningSuiteBase
}
}
}
+
+ test("SPARK-34637: test DPP side broadcast query stage is created firstly") {
Review comment:
updated.
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/DynamicPartitionPruningSuite.scala
##
@@ -1463,6 +1474,37 @@ abstract class DynamicPartitionPruningSuiteBase
}
}
}
+
+ test("SPARK-34637: test DPP side broadcast query stage is created firstly") {
+withSQLConf(SQLConf.DYNAMIC_PARTITION_PRUNING_REUSE_BROADCAST_ONLY.key ->
"true") {
+ val df = sql(
+""" WITH view1 as (
Review comment:
updated.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #25854: [SPARK-29145][SQL] Support sub-queries in join conditions
AngersZh commented on a change in pull request #25854: URL: https://github.com/apache/spark/pull/25854#discussion_r629920695 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala ## @@ -1697,6 +1697,8 @@ class Analyzer( // Only a few unary nodes (Project/Filter/Aggregate) can contain subqueries. case q: UnaryNode if q.childrenResolved => resolveSubQueries(q, q.children) + case j: Join if j.childrenResolved => +resolveSubQueries(j, Seq(j, j.left, j.right)) Review comment: > Can't recall the details, but why it's not `Seq(j.left, j.right)`? Should be a mistake, raise a pr and remove this? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu opened a new pull request #32499: [SPARK-29145][SQL][FOLLOWUP] Support sub-queries in join conditions
AngersZh opened a new pull request #32499: URL: https://github.com/apache/spark/pull/32499 ### What changes were proposed in this pull request? According to discuss https://github.com/apache/spark/pull/25854#discussion_r629451135 ### Why are the changes needed? Clean code ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existed UT -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #32499: [SPARK-29145][SQL][FOLLOWUP] Support sub-queries in join conditions
AngersZh commented on pull request #32499: URL: https://github.com/apache/spark/pull/32499#issuecomment-838005959 FYI @cloud-fan -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32494: [Minor][SPARK-35362][SQL]Update null count in the column stats for UNION operator stats estimation
SparkQA commented on pull request #32494: URL: https://github.com/apache/spark/pull/32494#issuecomment-838017318 **[Test build #138351 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138351/testReport)** for PR 32494 at commit [`8e02f19`](https://github.com/apache/spark/commit/8e02f1937d1c725d8fa3d95a90d9b22d82d7b01d). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32494: [Minor][SPARK-35362][SQL]Update null count in the column stats for UNION operator stats estimation
SparkQA removed a comment on pull request #32494: URL: https://github.com/apache/spark/pull/32494#issuecomment-837716583 **[Test build #138351 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138351/testReport)** for PR 32494 at commit [`8e02f19`](https://github.com/apache/spark/commit/8e02f1937d1c725d8fa3d95a90d9b22d82d7b01d). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32365: [SPARK-35228][SQL] Add expression ToPrettyString for keep consistent between hive/spark format in df.show and transform
SparkQA commented on pull request #32365: URL: https://github.com/apache/spark/pull/32365#issuecomment-838019181 **[Test build #138354 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138354/testReport)** for PR 32365 at commit [`1994dfd`](https://github.com/apache/spark/commit/1994dfde6fc3f21709b4e968c42d85d063e882cc). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32365: [SPARK-35228][SQL] Add expression ToPrettyString for keep consistent between hive/spark format in df.show and transform
SparkQA removed a comment on pull request #32365: URL: https://github.com/apache/spark/pull/32365#issuecomment-837727960 **[Test build #138354 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138354/testReport)** for PR 32365 at commit [`1994dfd`](https://github.com/apache/spark/commit/1994dfde6fc3f21709b4e968c42d85d063e882cc). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32399: [SPARK-35271][ML][PYSPARK] Fix: After CrossValidator/TrainValidationSplit fit raised error, some backgroud threads may still continue run or
SparkQA commented on pull request #32399: URL: https://github.com/apache/spark/pull/32399#issuecomment-838019712 **[Test build #138359 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138359/testReport)** for PR 32399 at commit [`35872b7`](https://github.com/apache/spark/commit/35872b7b0bdc435fa93439aaa957a718f3d3f8f4). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32399: [SPARK-35271][ML][PYSPARK] Fix: After CrossValidator/TrainValidationSplit fit raised error, some backgroud threads may still continue
SparkQA removed a comment on pull request #32399: URL: https://github.com/apache/spark/pull/32399#issuecomment-837836414 **[Test build #138359 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138359/testReport)** for PR 32399 at commit [`35872b7`](https://github.com/apache/spark/commit/35872b7b0bdc435fa93439aaa957a718f3d3f8f4). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32461: [SPARK-35146][SQL] Migrate to transformWithPruning or resolveWithPruning for rules in finishAnalysis.scala
SparkQA commented on pull request #32461: URL: https://github.com/apache/spark/pull/32461#issuecomment-838036498 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/42887/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32478: [SPARK-35063][SQL] Group exception messages in sql/catalyst
SparkQA commented on pull request #32478: URL: https://github.com/apache/spark/pull/32478#issuecomment-838036929 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32439: [SPARK-35298][SQL] Migrate to transformWithPruning for rules in Optimizer.scala
SparkQA commented on pull request #32439: URL: https://github.com/apache/spark/pull/32439#issuecomment-838038403 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32498: [SPARK-35368][SQL]Update histogram statistics for RANGE operator for stats estimation
SparkQA commented on pull request #32498: URL: https://github.com/apache/spark/pull/32498#issuecomment-838044831 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32461: [SPARK-35146][SQL] Migrate to transformWithPruning or resolveWithPruning for rules in finishAnalysis.scala
SparkQA commented on pull request #32461: URL: https://github.com/apache/spark/pull/32461#issuecomment-838044876 Kubernetes integration test status failure URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/42887/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32497: [SPARK-35366][SQL] Avoid using deprecated `buildForBatch` and `buildForStreaming`
SparkQA commented on pull request #32497: URL: https://github.com/apache/spark/pull/32497#issuecomment-838048190 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32494: [Minor][SPARK-35362][SQL]Update null count in the column stats for UNION operator stats estimation
AmplabJenkins commented on pull request #32494: URL: https://github.com/apache/spark/pull/32494#issuecomment-838050119 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138351/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32497: [SPARK-35366][SQL] Avoid using deprecated `buildForBatch` and `buildForStreaming`
AmplabJenkins commented on pull request #32497: URL: https://github.com/apache/spark/pull/32497#issuecomment-838050120 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42889/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32399: [SPARK-35271][ML][PYSPARK] Fix: After CrossValidator/TrainValidationSplit fit raised error, some backgroud threads may still continue r
AmplabJenkins commented on pull request #32399: URL: https://github.com/apache/spark/pull/32399#issuecomment-838050122 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138359/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32498: [SPARK-35368][SQL]Update histogram statistics for RANGE operator for stats estimation
AmplabJenkins commented on pull request #32498: URL: https://github.com/apache/spark/pull/32498#issuecomment-838050118 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42885/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32439: [SPARK-35298][SQL] Migrate to transformWithPruning for rules in Optimizer.scala
AmplabJenkins commented on pull request #32439: URL: https://github.com/apache/spark/pull/32439#issuecomment-838050123 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42888/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32365: [SPARK-35228][SQL] Add expression ToPrettyString for keep consistent between hive/spark format in df.show and transform
AmplabJenkins commented on pull request #32365: URL: https://github.com/apache/spark/pull/32365#issuecomment-838050137 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138354/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32478: [SPARK-35063][SQL] Group exception messages in sql/catalyst
AmplabJenkins commented on pull request #32478: URL: https://github.com/apache/spark/pull/32478#issuecomment-838050133 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42886/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32461: [SPARK-35146][SQL] Migrate to transformWithPruning or resolveWithPruning for rules in finishAnalysis.scala
AmplabJenkins commented on pull request #32461: URL: https://github.com/apache/spark/pull/32461#issuecomment-838050124 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42887/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32461: [SPARK-35146][SQL] Migrate to transformWithPruning or resolveWithPruning for rules in finishAnalysis.scala
AmplabJenkins removed a comment on pull request #32461: URL: https://github.com/apache/spark/pull/32461#issuecomment-838050124 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42887/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32497: [SPARK-35366][SQL] Avoid using deprecated `buildForBatch` and `buildForStreaming`
AmplabJenkins removed a comment on pull request #32497: URL: https://github.com/apache/spark/pull/32497#issuecomment-838050120 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42889/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32365: [SPARK-35228][SQL] Add expression ToPrettyString for keep consistent between hive/spark format in df.show and transform
AmplabJenkins removed a comment on pull request #32365: URL: https://github.com/apache/spark/pull/32365#issuecomment-838050137 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138354/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32439: [SPARK-35298][SQL] Migrate to transformWithPruning for rules in Optimizer.scala
AmplabJenkins removed a comment on pull request #32439: URL: https://github.com/apache/spark/pull/32439#issuecomment-838050123 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42888/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32494: [Minor][SPARK-35362][SQL]Update null count in the column stats for UNION operator stats estimation
AmplabJenkins removed a comment on pull request #32494: URL: https://github.com/apache/spark/pull/32494#issuecomment-838050119 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138351/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32498: [SPARK-35368][SQL]Update histogram statistics for RANGE operator for stats estimation
AmplabJenkins removed a comment on pull request #32498: URL: https://github.com/apache/spark/pull/32498#issuecomment-838050118 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42885/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32478: [SPARK-35063][SQL] Group exception messages in sql/catalyst
AmplabJenkins removed a comment on pull request #32478: URL: https://github.com/apache/spark/pull/32478#issuecomment-838050133 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42886/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32399: [SPARK-35271][ML][PYSPARK] Fix: After CrossValidator/TrainValidationSplit fit raised error, some backgroud threads may still co
AmplabJenkins removed a comment on pull request #32399: URL: https://github.com/apache/spark/pull/32399#issuecomment-838050122 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138359/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32499: [SPARK-29145][SQL][FOLLOWUP] Support sub-queries in join conditions
SparkQA commented on pull request #32499: URL: https://github.com/apache/spark/pull/32499#issuecomment-838055316 **[Test build #138368 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138368/testReport)** for PR 32499 at commit [`504f821`](https://github.com/apache/spark/commit/504f82183f416a1794541e38863228bdb63f2f7f). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32478: [SPARK-35063][SQL] Group exception messages in sql/catalyst
SparkQA commented on pull request #32478: URL: https://github.com/apache/spark/pull/32478#issuecomment-838055562 **[Test build #138369 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138369/testReport)** for PR 32478 at commit [`f9275a0`](https://github.com/apache/spark/commit/f9275a0d6a2868e8df5a77f9774a28e6ee1bb5e7). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31756: [SPARK-34637] [SQL] Support DPP + AQE when the broadcast exchange can be reused
AmplabJenkins commented on pull request #31756: URL: https://github.com/apache/spark/pull/31756#issuecomment-838063439 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42890/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31756: [SPARK-34637] [SQL] Support DPP + AQE when the broadcast exchange can be reused
SparkQA commented on pull request #31756: URL: https://github.com/apache/spark/pull/31756#issuecomment-838063341 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #32499: [SPARK-29145][SQL][FOLLOWUP] Support sub-queries in join conditions
cloud-fan commented on a change in pull request #32499: URL: https://github.com/apache/spark/pull/32499#discussion_r629957216 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala ## @@ -2353,7 +2353,7 @@ class Analyzer(override val catalogManager: CatalogManager) case q: UnaryNode if q.childrenResolved => resolveSubQueries(q, q.children) case j: Join if j.childrenResolved => -resolveSubQueries(j, Seq(j, j.left, j.right)) +resolveSubQueries(j, Seq(j.left, j.right)) Review comment: nit: `j.children` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31756: [SPARK-34637] [SQL] Support DPP + AQE when the broadcast exchange can be reused
AmplabJenkins removed a comment on pull request #31756: URL: https://github.com/apache/spark/pull/31756#issuecomment-838063439 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42890/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32482: [SPARK-35332][SQL] Make cache plan disable configs configurable
SparkQA commented on pull request #32482: URL: https://github.com/apache/spark/pull/32482#issuecomment-838066417 **[Test build #138371 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138371/testReport)** for PR 32482 at commit [`a83e9cf`](https://github.com/apache/spark/commit/a83e9cfc40cc4b80385e23c180363fe1b5b09d13). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32499: [SPARK-29145][SQL][FOLLOWUP] Support sub-queries in join conditions
SparkQA commented on pull request #32499: URL: https://github.com/apache/spark/pull/32499#issuecomment-838066402 **[Test build #138370 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138370/testReport)** for PR 32499 at commit [`3aa629b`](https://github.com/apache/spark/commit/3aa629bfc182daed79b0e35643296221ad75726e). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #32482: [SPARK-35332][SQL] Make cache plan disable configs configurable
cloud-fan commented on a change in pull request #32482:
URL: https://github.com/apache/spark/pull/32482#discussion_r629962413
##
File path: sql/core/src/test/scala/org/apache/spark/sql/CachedTableSuite.scala
##
@@ -1554,4 +1554,63 @@ class CachedTableSuite extends QueryTest with
SQLTestUtils
assert(!spark.catalog.isCached(viewName))
}
}
+
+ test("SPARK-35332: Make cache plan disable configs configurable - check
AQE") {
+withSQLConf(SQLConf.SHUFFLE_PARTITIONS.key -> "2",
+ SQLConf.COALESCE_PARTITIONS_MIN_PARTITION_NUM.key -> "1",
+ SQLConf.ADAPTIVE_EXECUTION_ENABLED.key -> "true") {
+
+ withTempView("t1", "t2", "t3") {
+withCache("t1", "t2", "t3") {
+ withSQLConf(SQLConf.CAN_CHANGE_CACHED_PLAN_OUTPUT_PARTITIONING.key
-> "false") {
+sql("CACHE TABLE t1 as SELECT /*+ REPARTITION */ * FROM values(1)
as t(c)")
+assert(spark.table("t1").rdd.partitions.length == 2)
+
+sql(s"SET
${SQLConf.CAN_CHANGE_CACHED_PLAN_OUTPUT_PARTITIONING.key} = true")
Review comment:
let's turn each of these `SET ...` to `withSQLConf`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LucaCanali opened a new pull request #32500: [SPARK-35369][DOC] Document ExecutorAllocationManager metrics
LucaCanali opened a new pull request #32500: URL: https://github.com/apache/spark/pull/32500 ### What changes were proposed in this pull request? This proposes to document the available metrics for ExecutorAllocationManager in the Spark monitoring documentation. ### Why are the changes needed? The ExecutorAllocationManager is instrumented with metrics using the Spark metrics system. The relevant work is in SPARK-7007 and SPARK-33763 ExecutorAllocationManager metrics are currently undocumented. ### Does this PR introduce _any_ user-facing change? This PR adds documentation only. ### How was this patch tested? na -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a change in pull request #32439: [SPARK-35298][SQL] Migrate to transformWithPruning for rules in Optimizer.scala
gengliangwang commented on a change in pull request #32439: URL: https://github.com/apache/spark/pull/32439#discussion_r629963033 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala ## @@ -1235,6 +1244,7 @@ case class Repartition(numPartitions: Int, shuffle: Boolean, child: LogicalPlan) case _ => RoundRobinPartitioning(numPartitions) } } + Review comment: nit: unnecessary change. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32500: [SPARK-35369][DOC] Document ExecutorAllocationManager metrics
AmplabJenkins commented on pull request #32500: URL: https://github.com/apache/spark/pull/32500#issuecomment-838076380 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32482: [SPARK-35332][SQL] Make cache plan disable configs configurable
SparkQA commented on pull request #32482: URL: https://github.com/apache/spark/pull/32482#issuecomment-838086072 **[Test build #138355 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138355/testReport)** for PR 32482 at commit [`708bb0c`](https://github.com/apache/spark/commit/708bb0c78256256043b14ecfa7b62a6cb96fea6a). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31986: [SPARK-34888][SS] Introduce UpdatingSessionIterator adjusting session window on elements
SparkQA commented on pull request #31986: URL: https://github.com/apache/spark/pull/31986#issuecomment-838086565 **[Test build #138356 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138356/testReport)** for PR 31986 at commit [`7764c72`](https://github.com/apache/spark/commit/7764c72a932aa058f9c864c8da8a5479c2be0c68). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32482: [SPARK-35332][SQL] Make cache plan disable configs configurable
SparkQA removed a comment on pull request #32482: URL: https://github.com/apache/spark/pull/32482#issuecomment-837774793 **[Test build #138355 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138355/testReport)** for PR 32482 at commit [`708bb0c`](https://github.com/apache/spark/commit/708bb0c78256256043b14ecfa7b62a6cb96fea6a). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31986: [SPARK-34888][SS] Introduce UpdatingSessionIterator adjusting session window on elements
SparkQA removed a comment on pull request #31986: URL: https://github.com/apache/spark/pull/31986#issuecomment-837775575 **[Test build #138356 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138356/testReport)** for PR 31986 at commit [`7764c72`](https://github.com/apache/spark/commit/7764c72a932aa058f9c864c8da8a5479c2be0c68). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #31756: [SPARK-34637] [SQL] Support DPP + AQE when the broadcast exchange can be reused
cloud-fan commented on a change in pull request #31756:
URL: https://github.com/apache/spark/pull/31756#discussion_r629983300
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/AdaptiveSparkPlanExec.scala
##
@@ -91,10 +91,15 @@ case class AdaptiveSparkPlanExec(
DisableUnnecessaryBucketedScan
) ++ context.session.sessionState.queryStagePrepRules
+ @transient private val initialPlan = context.session.withActive {
+applyPhysicalRules(
+ inputPlan, queryStagePreparationRules, Some((planChangeLogger, "AQE
Preparations")))
+ }
+
// A list of physical optimizer rules to be applied to a new stage before
its execution. These
// optimizations should be stage-independent.
@transient private val queryStageOptimizerRules: Seq[Rule[SparkPlan]] = Seq(
-PlanAdaptiveDynamicPruningFilters(context.stageCache),
+PlanAdaptiveDynamicPruningFilters(initialPlan),
Review comment:
I think it's better to pass `this` as the root plan.
`AdaptiveSparkPlanExec` keeps changing when more and more query stages are
completed. So it's better that `PlanAdaptiveDynamicPruningFilters` always look
at the latest plan.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32478: [SPARK-35063][SQL] Group exception messages in sql/catalyst
SparkQA commented on pull request #32478: URL: https://github.com/apache/spark/pull/32478#issuecomment-838116391 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ggershinsky commented on pull request #32473: [SPARK-35345][SQL] Add Parquet tests to BloomFilterBenchmark
ggershinsky commented on pull request #32473: URL: https://github.com/apache/spark/pull/32473#issuecomment-838117882 Thanks @huaxingao . I think my basic question is about the extent to which these results are representative for a typical user. If the default block size is 128MB, providing numbers for 0.5-10MB blocks might seem to be unhelpful. If the recommendation is to use 1 MB or 4MB block size, this is a problem, because the default page size in Parquet is 1MB; having a very small block with one or a few pages might be good for bloom filtering, but is bad for other performance optimizations. The 128MB blocks could be bad for bloom filtering because there is just one row group when you write 100M records. And there are other parameters, like the `DEFAULT_MAX_BLOOM_FILTER_BYTES` mentioned by @sunchao . So this is not a comprehensive benchmark. But maybe it's ok. Still, at a minimum, I would recommend removing the results for 0.5MB and 1MB block sizes- because row groups that small, with just one data page, don't make much sense. I would also suggest adding measurements for 16, 64 and 128MB; this might be of some help for the users of parquet bloom filters. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32499: [SPARK-29145][SQL][FOLLOWUP] Support sub-queries in join conditions
SparkQA commented on pull request #32499: URL: https://github.com/apache/spark/pull/32499#issuecomment-838124924 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #32499: [SPARK-29145][SQL][FOLLOWUP] Support sub-queries in join conditions
AngersZh commented on a change in pull request #32499: URL: https://github.com/apache/spark/pull/32499#discussion_r629990828 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala ## @@ -2353,7 +2353,7 @@ class Analyzer(override val catalogManager: CatalogManager) case q: UnaryNode if q.childrenResolved => resolveSubQueries(q, q.children) case j: Join if j.childrenResolved => -resolveSubQueries(j, Seq(j, j.left, j.right)) +resolveSubQueries(j, Seq(j.left, j.right)) Review comment: > nit: `j.children` Done -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on pull request #32461: [SPARK-35146][SQL] Migrate to transformWithPruning or resolveWithPruning for rules in finishAnalysis.scala
gengliangwang commented on pull request #32461: URL: https://github.com/apache/spark/pull/32461#issuecomment-838126462 Thanks, merging to master -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32470: [WIP] Simplify ResolveAggregateFunctions
SparkQA commented on pull request #32470: URL: https://github.com/apache/spark/pull/32470#issuecomment-838127291 **[Test build #138358 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138358/testReport)** for PR 32470 at commit [`c0bb807`](https://github.com/apache/spark/commit/c0bb8070cbb52f9a20da0c5e3e791db72ea4bf04). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32470: [WIP] Simplify ResolveAggregateFunctions
SparkQA removed a comment on pull request #32470: URL: https://github.com/apache/spark/pull/32470#issuecomment-837836239 **[Test build #138358 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138358/testReport)** for PR 32470 at commit [`c0bb807`](https://github.com/apache/spark/commit/c0bb8070cbb52f9a20da0c5e3e791db72ea4bf04). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang closed pull request #32461: [SPARK-35146][SQL] Migrate to transformWithPruning or resolveWithPruning for rules in finishAnalysis.scala
gengliangwang closed pull request #32461: URL: https://github.com/apache/spark/pull/32461 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32499: [SPARK-29145][SQL][FOLLOWUP] Support sub-queries in join conditions
SparkQA commented on pull request #32499: URL: https://github.com/apache/spark/pull/32499#issuecomment-838129809 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] fhygh opened a new pull request #32501: [SPARK-35359][SQL]Insert data with char/varchar datatype will fail when data length exceed length limitation
fhygh opened a new pull request #32501: URL: https://github.com/apache/spark/pull/32501 ### What changes were proposed in this pull request? This PR is used to fix this bug: set spark.sql.legacy.charVarcharAsString=true; create table chartb01(a char(3)); insert into chartb01 select 'a'; here we expect the data of table chartb01 is 'aaa', but it runs failed. ### Why are the changes needed? Improve backward compatibility ‘‘‘spark-sql spark-sql> > create table tchar01(col char(2)) using parquet; Time taken: 0.767 seconds spark-sql> > insert into tchar01 select 'aaa'; ERROR | Executor task launch worker for task 0.0 in stage 0.0 (TID 0) | Aborting task | org.apache.spark.util.Utils.logError(Logging.scala:94) java.lang.RuntimeException: Exceeds char/varchar type length limitation: 2 at org.apache.spark.sql.catalyst.util.CharVarcharCodegenUtils.trimTrailingSpaces(CharVarcharCodegenUtils.java:31) at org.apache.spark.sql.catalyst.util.CharVarcharCodegenUtils.charTypeWriteSideCheck(CharVarcharCodegenUtils.java:44) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.project_doConsume_0$(Unknown Source) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:755) at org.apache.spark.sql.execution.datasources.FileFormatWriter$.$anonfun$executeTask$1(FileFormatWriter.scala:279) at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1500) at org.apache.spark.sql.execution.datasources.FileFormatWriter$.executeTask(FileFormatWriter.scala:288) at org.apache.spark.sql.execution.datasources.FileFormatWriter$.$anonfun$write$15(FileFormatWriter.scala:212) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90) at org.apache.spark.scheduler.Task.run(Task.scala:131) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:497) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1466) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:500) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) ‘‘‘ ### Does this PR introduce _any_ user-facing change? No (the legacy config is false by default). ### How was this patch tested? Added unit tests. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32482: [SPARK-35332][SQL] Make cache plan disable configs configurable
SparkQA commented on pull request #32482: URL: https://github.com/apache/spark/pull/32482#issuecomment-838134956 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32499: [SPARK-29145][SQL][FOLLOWUP] Support sub-queries in join conditions
AmplabJenkins commented on pull request #32499: URL: https://github.com/apache/spark/pull/32499#issuecomment-838135138 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32478: [SPARK-35063][SQL] Group exception messages in sql/catalyst
AmplabJenkins commented on pull request #32478: URL: https://github.com/apache/spark/pull/32478#issuecomment-838135137 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42892/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31986: [SPARK-34888][SS] Introduce UpdatingSessionIterator adjusting session window on elements
AmplabJenkins commented on pull request #31986: URL: https://github.com/apache/spark/pull/31986#issuecomment-838135143 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138356/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32482: [SPARK-35332][SQL] Make cache plan disable configs configurable
AmplabJenkins commented on pull request #32482: URL: https://github.com/apache/spark/pull/32482#issuecomment-838135026 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32470: [WIP] Simplify ResolveAggregateFunctions
AmplabJenkins commented on pull request #32470: URL: https://github.com/apache/spark/pull/32470#issuecomment-838135134 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138358/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] c21 commented on a change in pull request #32476: [SPARK-35349][SQL] Add code-gen for left/right outer sort merge join
c21 commented on a change in pull request #32476:
URL: https://github.com/apache/spark/pull/32476#discussion_r629996554
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/joins/SortMergeJoinExec.scala
##
@@ -431,6 +433,41 @@ case class SortMergeJoinExec(
// Copy the streamed keys as class members so they could be used in next
function call.
val matchedKeyVars = copyKeys(ctx, streamedKeyVars)
+// Handle the case when streamed rows has any NULL keys.
+val handleStreamedAnyNull = joinType match {
+ case _: InnerLike =>
+// Skip streamed row.
+s"""
+ |$streamedRow = null;
+ |continue;
+ """.stripMargin
+ case LeftOuter | RightOuter =>
+// Eagerly return streamed row. Only call `matches.clear()` when
`matches.isEmpty()` is
+// false, to reduce unnecessary computation.
+s"""
+ |if (!$matches.isEmpty()) {
+ | $matches.clear();
+ |}
+ |return false;
+ """.stripMargin
+ case x =>
+throw new IllegalArgumentException(
+ s"SortMergeJoin.genScanner should not take $x as the JoinType")
+}
+
+// Handle the case when streamed keys less than buffered keys.
+val handleStreamedLessThanBuffered = joinType match {
+ case _: InnerLike =>
+// Skip streamed row.
+s"$streamedRow = null;"
+ case LeftOuter | RightOuter =>
+// Eagerly return with streamed row.
+"return false;"
+ case x =>
+throw new IllegalArgumentException(
+ s"SortMergeJoin.genScanner should not take $x as the JoinType")
+}
+
ctx.addNewFunction("findNextJoinRows",
Review comment:
@cloud-fan - sure, updated with comment.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31986: [SPARK-34888][SS] Introduce UpdatingSessionIterator adjusting session window on elements
AmplabJenkins removed a comment on pull request #31986: URL: https://github.com/apache/spark/pull/31986#issuecomment-838135143 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138356/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32478: [SPARK-35063][SQL] Group exception messages in sql/catalyst
AmplabJenkins removed a comment on pull request #32478: URL: https://github.com/apache/spark/pull/32478#issuecomment-838135137 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42892/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32470: [WIP] Simplify ResolveAggregateFunctions
AmplabJenkins removed a comment on pull request #32470: URL: https://github.com/apache/spark/pull/32470#issuecomment-838135134 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138358/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32499: [SPARK-29145][SQL][FOLLOWUP] Support sub-queries in join conditions
AmplabJenkins removed a comment on pull request #32499: URL: https://github.com/apache/spark/pull/32499#issuecomment-838135138 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32482: [SPARK-35332][SQL] Make cache plan disable configs configurable
AmplabJenkins removed a comment on pull request #32482: URL: https://github.com/apache/spark/pull/32482#issuecomment-838135026 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32501: [SPARK-35359][SQL]Insert data with char/varchar datatype will fail when data length exceed length limitation
AmplabJenkins commented on pull request #32501: URL: https://github.com/apache/spark/pull/32501#issuecomment-838136549 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] kyoty removed a comment on pull request #32224: [SPARK-35128][UI] Some columns in table Data Distribution of storage page shows incorrectly when sorted
kyoty removed a comment on pull request #32224: URL: https://github.com/apache/spark/pull/32224#issuecomment-825400146 @gengliangwang @sarutak Thanks for your review, the code has been updated, please have a look when your are free. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] kyoty commented on pull request #32224: [SPARK-35128][UI] Some columns in table Data Distribution of storage page shows incorrectly when sorted
kyoty commented on pull request #32224: URL: https://github.com/apache/spark/pull/32224#issuecomment-838140166 @gengliangwang @sarutak Thanks for your review, the code has been updated, please have a look when your are free. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32482: [SPARK-35332][SQL] Make cache plan disable configs configurable
SparkQA commented on pull request #32482: URL: https://github.com/apache/spark/pull/32482#issuecomment-838140394 **[Test build #138373 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138373/testReport)** for PR 32482 at commit [`515aeba`](https://github.com/apache/spark/commit/515aeba746164ab652f01107019a656190682a35). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32476: [SPARK-35349][SQL] Add code-gen for left/right outer sort merge join
SparkQA commented on pull request #32476: URL: https://github.com/apache/spark/pull/32476#issuecomment-838140683 **[Test build #138374 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138374/testReport)** for PR 32476 at commit [`765b247`](https://github.com/apache/spark/commit/765b2471ee05c64c41bd450081a4c27a40857384). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32497: [SPARK-35366][SQL] Avoid using deprecated `buildForBatch` and `buildForStreaming`
SparkQA commented on pull request #32497: URL: https://github.com/apache/spark/pull/32497#issuecomment-838140355 **[Test build #138372 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138372/testReport)** for PR 32497 at commit [`41a46f5`](https://github.com/apache/spark/commit/41a46f5a7b4f43e69f632575c9d1981b07384721). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32497: [SPARK-35366][SQL] Avoid using deprecated `buildForBatch` and `buildForStreaming`
SparkQA commented on pull request #32497: URL: https://github.com/apache/spark/pull/32497#issuecomment-838165578 **[Test build #138357 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138357/testReport)** for PR 32497 at commit [`d078953`](https://github.com/apache/spark/commit/d078953d3b3b6e14b7f51ee3fd321cd892da02d5). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32497: [SPARK-35366][SQL] Avoid using deprecated `buildForBatch` and `buildForStreaming`
SparkQA removed a comment on pull request #32497: URL: https://github.com/apache/spark/pull/32497#issuecomment-837836024 **[Test build #138357 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138357/testReport)** for PR 32497 at commit [`d078953`](https://github.com/apache/spark/commit/d078953d3b3b6e14b7f51ee3fd321cd892da02d5). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org