[GitHub] [spark] beliefer commented on pull request #36521: [SPARK-39162][SQL] Jdbc dialect should decide which function could be pushed down
beliefer commented on PR #36521: URL: https://github.com/apache/spark/pull/36521#issuecomment-1125684110 ping @huaxingao cc @cloud-fan -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang closed pull request #36525: [SPARK-39166][SQL] Provide runtime error query context for binary arithmetic when WSCG is off
gengliangwang closed pull request #36525: [SPARK-39166][SQL] Provide runtime error query context for binary arithmetic when WSCG is off URL: https://github.com/apache/spark/pull/36525 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on pull request #36525: [SPARK-39166][SQL] Provide runtime error query context for binary arithmetic when WSCG is off
gengliangwang commented on PR #36525: URL: https://github.com/apache/spark/pull/36525#issuecomment-1125680090 Merging to master/3.3 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a diff in pull request #36445: [SPARK-39096][SQL] Support MERGE commands with DEFAULT values
gengliangwang commented on code in PR #36445:
URL: https://github.com/apache/spark/pull/36445#discussion_r871990905
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala:
##
@@ -1552,7 +1553,8 @@ class Analyzer(override val catalogManager:
CatalogManager)
private def resolveMergeExprOrFail(e: Expression, p: LogicalPlan):
Expression = {
val resolved = resolveExpressionByPlanChildren(e, p)
- resolved.references.filter(!_.resolved).foreach { a =>
+ resolved.references.filter { attribute: Attribute =>
+!attribute.resolved && attribute.name != CURRENT_DEFAULT_COLUMN_NAME
}.foreach { a =>
Review Comment:
What if there is an unresolved column "default" which is not default
expression in the query?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #36519: [SPARK-39159][SQL] Add new Dataset API for Offset
beliefer commented on code in PR #36519:
URL: https://github.com/apache/spark/pull/36519#discussion_r871986222
##
sql/core/src/test/scala/org/apache/spark/sql/DataFrameSuite.scala:
##
@@ -605,6 +605,20 @@ class DataFrameSuite extends QueryTest
)
}
+ test("offset") {
+checkAnswer(
+ testData.offset(90),
+ testData.collect().drop(90).toSeq)
+
+checkAnswer(
+ arrayData.toDF().offset(99),
+ arrayData.collect().drop(99).map(r =>
Row.fromSeq(r.productIterator.toSeq)))
+
+checkAnswer(
+ mapData.toDF().offset(99),
+ mapData.collect().drop(99).map(r =>
Row.fromSeq(r.productIterator.toSeq)))
Review Comment:
OK
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ulysses-you opened a new pull request, #36530: [SPARK-39172][SQL] Remove outer join if all output come from streamed side and buffered side keys exist unique key
ulysses-you opened a new pull request, #36530: URL: https://github.com/apache/spark/pull/36530 ### What changes were proposed in this pull request? Improve `EliminateOuterJoin` that support Remove outer join if all output come from streamed side and buffered side keys exist unique key. ### Why are the changes needed? Improve the optimzation case using the distinct keys framework. For example: ```sql SELECT t1.* FROM t1 LEFT JOIN (SELECT distinct c1 as c1 FROM t)t2 ON t1.c1 = t2.c1 ==> SELECT t1.* FROM t1 ``` ### Does this PR introduce _any_ user-facing change? no, improve performance ### How was this patch tested? add test -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #36365: [SPARK-28516][SQL] Implement `to_char` and `try_to_char` functions to format Decimal values as strings
cloud-fan closed pull request #36365: [SPARK-28516][SQL] Implement `to_char` and `try_to_char` functions to format Decimal values as strings URL: https://github.com/apache/spark/pull/36365 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #36365: [SPARK-28516][SQL] Implement `to_char` and `try_to_char` functions to format Decimal values as strings
cloud-fan commented on PR #36365: URL: https://github.com/apache/spark/pull/36365#issuecomment-1125625678 thanks, merging to maseter! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xiuzhu9527 commented on pull request #36217: [BUILD] When building spark project, remove spark-tags-tests.jar from…
xiuzhu9527 commented on PR #36217: URL: https://github.com/apache/spark/pull/36217#issuecomment-1125602279 @kiszk Hello, can I ask you a question? Why didn't you set the scope to test when you introduced the spark-tags dependency in the kubernetes module? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #36529: [SPARK-39102][CORE][SQL] Add checkstyle rules to disabled use of Guava's `Files.createTempDir()`
LuciferYang commented on code in PR #36529:
URL: https://github.com/apache/spark/pull/36529#discussion_r871954838
##
common/network-common/src/main/java/org/apache/spark/network/util/JavaUtils.java:
##
@@ -362,6 +364,18 @@ public static byte[] bufferToArray(ByteBuffer buffer) {
}
}
+ /**
+ * Create a temporary directory inside `java.io.tmpdir`. The directory will
be
+ * automatically deleted when the VM shuts down.
+ */
+ public static File createTempDir() throws IOException {
Review Comment:
This method is added instead of using `Utils.createTempDir()` directly
because `Utils.createTempDir()` defined in `core` module.
Does this method need to maintain exactly the same logic as
`Utils.createTempDir()`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang opened a new pull request, #36529: [SPARK-39102][CORE][SQL] Add checkstyle rules to disabled use of Guava's `Files.createTempDir()`
LuciferYang opened a new pull request, #36529: URL: https://github.com/apache/spark/pull/36529 ### What changes were proposed in this pull request? The main change of this pr as follows: - Add a checkstyle to `scalastyle-config.xml` to disabled use of Guava's `Files.createTempDir()` for Scala - Add a checkstyle to `dev/checkstyle.xml` to disabled use of Guava's `Files.createTempDir()` for Java - Introduce `JavaUtils.createTempDir()` method to replace the use of Guava's `Files.createTempDir()` in Java code - Use `Utils.createTempDir()` to replace the use of Guava's `Files.createTempDir()` in Scala code ### Why are the changes needed? Avoid the use of Guava's `Files.createTempDir()` in Spark code due to [CVE-2020-8908](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-8908) ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass GA -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn commented on pull request #36373: [SPARK-39041][SQL] Mapping Spark Query ResultSet/Schema to TRowSet/TTableSchema directly
yaooqinn commented on PR #36373: URL: https://github.com/apache/spark/pull/36373#issuecomment-1125599377 thanks, merged to master -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn closed pull request #36373: [SPARK-39041][SQL] Mapping Spark Query ResultSet/Schema to TRowSet/TTableSchema directly
yaooqinn closed pull request #36373: [SPARK-39041][SQL] Mapping Spark Query ResultSet/Schema to TRowSet/TTableSchema directly URL: https://github.com/apache/spark/pull/36373 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dependabot[bot] opened a new pull request, #36528: Bump xercesImpl from 2.12.0 to 2.12.2
dependabot[bot] opened a new pull request, #36528: URL: https://github.com/apache/spark/pull/36528 Bumps xercesImpl from 2.12.0 to 2.12.2. [](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores) Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`. [//]: # (dependabot-automerge-start) [//]: # (dependabot-automerge-end) --- Dependabot commands and options You can trigger Dependabot actions by commenting on this PR: - `@dependabot rebase` will rebase this PR - `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it - `@dependabot merge` will merge this PR after your CI passes on it - `@dependabot squash and merge` will squash and merge this PR after your CI passes on it - `@dependabot cancel merge` will cancel a previously requested merge and block automerging - `@dependabot reopen` will reopen this PR if it is closed - `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually - `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself) - `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself) - `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself) - `@dependabot use these labels` will set the current labels as the default for future PRs for this repo and language - `@dependabot use these reviewers` will set the current reviewers as the default for future PRs for this repo and language - `@dependabot use these assignees` will set the current assignees as the default for future PRs for this repo and language - `@dependabot use this milestone` will set the current milestone as the default for future PRs for this repo and language You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/apache/spark/network/alerts). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #36526: [SPARK-38850][BUILD] Upgrade Kafka to 3.2.0
dongjoon-hyun closed pull request #36526: [SPARK-38850][BUILD] Upgrade Kafka to 3.2.0 URL: https://github.com/apache/spark/pull/36526 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #36526: [SPARK-38850][BUILD] Upgrade Kafka to 3.2.0
dongjoon-hyun commented on PR #36526: URL: https://github.com/apache/spark/pull/36526#issuecomment-1125596757 Merged to master. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #36521: [SPARK-39162][SQL] Jdbc dialect should decide which function could be pushed down
beliefer commented on code in PR #36521:
URL: https://github.com/apache/spark/pull/36521#discussion_r871950705
##
sql/core/src/main/scala/org/apache/spark/sql/jdbc/JdbcDialects.scala:
##
@@ -240,8 +240,31 @@ abstract class JdbcDialect extends Serializable with
Logging{
getJDBCType(dataType).map(_.databaseTypeDefinition).getOrElse(dataType.typeName)
s"CAST($l AS $databaseTypeDefinition)"
}
+
+override def visitSQLFunction(funcName: String, inputs: Array[String]):
String = {
+ if (isSupportedFunction(funcName)) {
+s"""$funcName(${inputs.mkString(", ")})"""
+ } else {
+throw QueryCompilationErrors.noSuchFunctionError(dialectName, funcName)
+ }
+}
}
+ /**
+ * Returns whether the database supports function.
+ * @param funcName Function name
+ * @return True if the database supports function.
+ */
+ @Since("3.4.0")
Review Comment:
OK
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikun commented on a diff in pull request #36509: [SPARK-38961][PYTHON][DOCS] Enhance to automatically generate the the pandas API support list
Yikun commented on code in PR #36509:
URL: https://github.com/apache/spark/pull/36509#discussion_r871949310
##
python/pyspark/pandas/supported_api_gen.py:
##
@@ -0,0 +1,363 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+"""
+Generate 'Supported pandas APIs' documentation file
+"""
+import os
+from enum import Enum, unique
+from inspect import getmembers, isclass, isfunction, signature
+from typing import Any, Callable, Dict, List, Set, TextIO, Tuple
+
+import pyspark.pandas as ps
+import pyspark.pandas.groupby as psg
+import pyspark.pandas.window as psw
+from pyspark.find_spark_home import _find_spark_home
+from pyspark.sql.pandas.utils import require_minimum_pandas_version
+
+import pandas as pd
+import pandas.core.groupby as pdg
+import pandas.core.window as pdw
+
+MAX_MISSING_PARAMS_SIZE = 5
+COMMON_PARAMETER_SET = {"kwargs", "args", "cls"}
+MODULE_GROUP_MATCH = [(pd, ps), (pdw, psw), (pdg, psg)]
+
+SPARK_HOME = _find_spark_home()
+TARGET_RST_FILE = os.path.join(
+SPARK_HOME,
"python/docs/source/user_guide/pandas_on_spark/supported_pandas_api.rst"
+)
+RST_HEADER = """
+=
+Supported pandas APIs
+=
+
+.. currentmodule:: pyspark.pandas
+
+The following table shows the pandas APIs that implemented or non-implemented
from pandas API on
+Spark.
+
+Some pandas APIs do not implement full parameters, so the third column shows
missing parameters for
+each API.
+
+'Y' in the second column means it's implemented including its whole parameter.
+'N' means it's not implemented yet.
+'P' means it's partially implemented with the missing of some parameters.
+
+If there is non-implemented pandas API or parameter you want, you can create
an `Apache Spark
+JIRA `__ to request or
to contribute by your
+own.
+
+The API list is updated based on the `latest pandas official API
+reference `__.
+
+All implemented APIs listed here are distributed except the ones that requires
the local
+computation by design. For example, `DataFrame.to_numpy()
`__ requires to collect the data to the driver side.
+
+"""
+
+
+@unique
+class Implemented(Enum):
+IMPLEMENTED = "Y"
+NOT_IMPLEMENTED = "N"
+PARTIALLY_IMPLEMENTED = "P"
+
+
+class SupportedStatus:
+"""
+SupportedStatus class that defines a supported status for a specific
pandas API
+"""
+
+def __init__(self, implemented: str, missing: str = ""):
+self.implemented = implemented
+self.missing = missing
+
+
+def generate_supported_api() -> None:
+"""
+Generate supported APIs status dictionary.
+
+Write supported APIs documentation.
+"""
+require_minimum_pandas_version()
Review Comment:
> Can we just print out the warning if pandas is lower than 1.4.0 for now?
++,if needed, we can add strict validate `warning` later once we complete
[SPARK-38819](https://issues.apache.org/jira/browse/SPARK-38819)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beobest2 commented on a diff in pull request #36509: [SPARK-38961][PYTHON][DOCS] Enhance to automatically generate the the pandas API support list
beobest2 commented on code in PR #36509:
URL: https://github.com/apache/spark/pull/36509#discussion_r871947591
##
python/pyspark/pandas/supported_api_gen.py:
##
@@ -0,0 +1,363 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+"""
+Generate 'Supported pandas APIs' documentation file
+"""
+import os
+from enum import Enum, unique
+from inspect import getmembers, isclass, isfunction, signature
+from typing import Any, Callable, Dict, List, Set, TextIO, Tuple
+
+import pyspark.pandas as ps
+import pyspark.pandas.groupby as psg
+import pyspark.pandas.window as psw
+from pyspark.find_spark_home import _find_spark_home
+from pyspark.sql.pandas.utils import require_minimum_pandas_version
+
+import pandas as pd
+import pandas.core.groupby as pdg
+import pandas.core.window as pdw
+
+MAX_MISSING_PARAMS_SIZE = 5
+COMMON_PARAMETER_SET = {"kwargs", "args", "cls"}
+MODULE_GROUP_MATCH = [(pd, ps), (pdw, psw), (pdg, psg)]
+
+SPARK_HOME = _find_spark_home()
+TARGET_RST_FILE = os.path.join(
+SPARK_HOME,
"python/docs/source/user_guide/pandas_on_spark/supported_pandas_api.rst"
+)
+RST_HEADER = """
+=
+Supported pandas APIs
+=
+
+.. currentmodule:: pyspark.pandas
+
+The following table shows the pandas APIs that implemented or non-implemented
from pandas API on
+Spark.
+
+Some pandas APIs do not implement full parameters, so the third column shows
missing parameters for
+each API.
+
+'Y' in the second column means it's implemented including its whole parameter.
+'N' means it's not implemented yet.
+'P' means it's partially implemented with the missing of some parameters.
+
+If there is non-implemented pandas API or parameter you want, you can create
an `Apache Spark
+JIRA `__ to request or
to contribute by your
+own.
+
+The API list is updated based on the `latest pandas official API
+reference `__.
+
+All implemented APIs listed here are distributed except the ones that requires
the local
+computation by design. For example, `DataFrame.to_numpy()
`__ requires to collect the data to the driver side.
+
+"""
+
+
+@unique
+class Implemented(Enum):
+IMPLEMENTED = "Y"
+NOT_IMPLEMENTED = "N"
+PARTIALLY_IMPLEMENTED = "P"
+
+
+class SupportedStatus:
+"""
+SupportedStatus class that defines a supported status for a specific
pandas API
+"""
+
+def __init__(self, implemented: str, missing: str = ""):
+self.implemented = implemented
+self.missing = missing
+
+
+def generate_supported_api() -> None:
+"""
+Generate supported APIs status dictionary.
+
+Write supported APIs documentation.
+"""
+require_minimum_pandas_version()
Review Comment:
I've filed a child JIRA (https://issues.apache.org/jira/browse/SPARK-39170)
for the future and fixed it into a warning for now.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #36517: Revert "[SPARK-36837][BUILD] Upgrade Kafka to 3.1.0"
HeartSaVioR commented on PR #36517: URL: https://github.com/apache/spark/pull/36517#issuecomment-1125586451 Thanks for the detailed explanation! Much appreciated. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #36522: [SPARK-39161][BUILD] Upgrade rocksdbjni to 7.2.2
LuciferYang commented on PR #36522: URL: https://github.com/apache/spark/pull/36522#issuecomment-1125580153 thanks @srowen @dongjoon-hyun -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on pull request #36503: [SPARK-39144][SQL] Nested subquery expressions deduplicate relations should be done bottom up
amaliujia commented on PR #36503: URL: https://github.com/apache/spark/pull/36503#issuecomment-1125579500 R: @cloud-fan -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] huaxingao commented on a diff in pull request #36521: [SPARK-39162][SQL] Jdbc dialect should decide which function could be pushed down
huaxingao commented on code in PR #36521:
URL: https://github.com/apache/spark/pull/36521#discussion_r871917477
##
sql/core/src/main/scala/org/apache/spark/sql/jdbc/JdbcDialects.scala:
##
@@ -240,8 +240,31 @@ abstract class JdbcDialect extends Serializable with
Logging{
getJDBCType(dataType).map(_.databaseTypeDefinition).getOrElse(dataType.typeName)
s"CAST($l AS $databaseTypeDefinition)"
}
+
+override def visitSQLFunction(funcName: String, inputs: Array[String]):
String = {
+ if (isSupportedFunction(funcName)) {
+s"""$funcName(${inputs.mkString(", ")})"""
+ } else {
+throw QueryCompilationErrors.noSuchFunctionError(dialectName, funcName)
+ }
+}
}
+ /**
+ * Returns whether the database supports function.
+ * @param funcName Function name
+ * @return True if the database supports function.
+ */
+ @Since("3.4.0")
Review Comment:
Should we include this change in 3.3.0? The function push down is in 3.3.0.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] attilapiros commented on a diff in pull request #35683: [SPARK-30835][SPARK-39018][CORE][YARN] Add support for YARN decommissioning when ESS is disabled
attilapiros commented on code in PR #35683:
URL: https://github.com/apache/spark/pull/35683#discussion_r871915524
##
resource-managers/yarn/src/test/scala/org/apache/spark/deploy/yarn/YarnAllocatorSuite.scala:
##
@@ -735,4 +744,77 @@ class YarnAllocatorSuite extends SparkFunSuite with
Matchers with BeforeAndAfter
sparkConf.set(EXECUTOR_MEMORY_OVERHEAD_FACTOR, 0.1)
}
}
+
+ test("Test YARN container decommissioning") {
+
Review Comment:
Nit: remove empty line
##
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnAllocator.scala:
##
@@ -422,6 +446,27 @@ private[yarn] class YarnAllocator(
}
}
+ private def handleNodesInDecommissioningState(allocateResponse:
AllocateResponse): Unit = {
+try {
+ // Some of the nodes are put in decommissioning state where RM did
allocate
+ // resources on those nodes for earlier allocateResource calls, so
notifying driver
+ // to put those executors in decommissioning state
+ allocateResponse.getUpdatedNodes.asScala.filter (node =>
+node.getNodeState == NodeState.DECOMMISSIONING &&
+ !decommissioningNodesCache.containsKey(getHostAddress(node)))
+.foreach { node =>
+ val host = getHostAddress(node)
+ driverRef.send(DecommissionExecutorsOnHost(host))
+ decommissioningNodesCache.put(host, true)
+}
+} catch {
+ case e: Exception => logError("Sending Message to Driver to Decommission
Executors" +
Review Comment:
Without the extra space it will be "... Executorson Decommissioning Nodes
failed":
```suggestion
case e: Exception => logError("Sending Message to Driver to
Decommission Executors " +
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #36514: [SPARK-39078][SQL] Fix a bug in UPDATE commands with DEFAULT values
AmplabJenkins commented on PR #36514: URL: https://github.com/apache/spark/pull/36514#issuecomment-1125551261 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #36526: [SPARK-38850][BUILD] Upgrade Kafka to 3.2.0
dongjoon-hyun commented on PR #36526: URL: https://github.com/apache/spark/pull/36526#issuecomment-1125544531 Thank you for review and approval, @HyukjinKwon . -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] vli-databricks opened a new pull request, #36527: [SPARK-39169][SQL] Optimize FIRST when used as a single aggregate fun…
vli-databricks opened a new pull request, #36527: URL: https://github.com/apache/spark/pull/36527 …ction ### What changes were proposed in this pull request? Rewrite aggregate with single `FIRST` function when grouping is absent. In that case the query is equivalent to projection with limit. ### Why are the changes needed? Avoid scanning large tables. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit testing. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #36501: [SPARK-39143][SQL] Support CSV scans with DEFAULT values
HyukjinKwon commented on PR #36501: URL: https://github.com/apache/spark/pull/36501#issuecomment-1125535738 cc @MaxGekk FYI -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #36501: [SPARK-39143][SQL] Support CSV scans with DEFAULT values
HyukjinKwon commented on code in PR #36501:
URL: https://github.com/apache/spark/pull/36501#discussion_r871905486
##
sql/catalyst/src/main/scala/org/apache/spark/sql/types/StructField.scala:
##
@@ -118,6 +118,17 @@ case class StructField(
}
}
+ /**
+ * Return the existence default value of this StructField.
+ */
+ def getExistenceDefaultValue(): Option[String] = {
Review Comment:
Also should probably protect this via `private[sql]` because `StructField`
is an API.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #36501: [SPARK-39143][SQL] Support CSV scans with DEFAULT values
HyukjinKwon commented on code in PR #36501: URL: https://github.com/apache/spark/pull/36501#discussion_r871905184 ## sql/catalyst/src/main/scala/org/apache/spark/sql/types/StructType.scala: ## @@ -511,6 +511,30 @@ case class StructType(fields: Array[StructField]) extends DataType with Seq[Stru @transient private[sql] lazy val interpretedOrdering = InterpretedOrdering.forSchema(this.fields.map(_.dataType)) + + /** + * Parses the text representing constant-folded default column literal values. + * @return a sequence of either (1) NULL, if the column had no default value, or (2) an object of + * Any type suitable for assigning into a row using the InternalRow.update method. + */ + lazy val defaultValues: Array[Any] = Review Comment: Should probably protect this via `private[sql]` because `StructType` is an API. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #36501: [SPARK-39143][SQL] Support CSV scans with DEFAULT values
HyukjinKwon commented on code in PR #36501: URL: https://github.com/apache/spark/pull/36501#discussion_r871904967 ## sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityParser.scala: ## @@ -318,7 +318,8 @@ class UnivocityParser( case e: SparkUpgradeException => throw e case NonFatal(e) => badRecordException = badRecordException.orElse(Some(e)) - row.setNullAt(i) + // Use the corresponding DEFAULT value associated with the column, if any. + row.update(i, parsedSchema.defaultValues(i)) Review Comment: BTW, would have to use `requiredSchema` instead of `parsedSchema`. When `CSVOptions.columnPruning` is disabled, `parsedSchema` becomes `dataSchema`. However, `getToken` reorders tokens to parse according to `requiredSchema` if I didn't misread the code path. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #36501: [SPARK-39143][SQL] Support CSV scans with DEFAULT values
HyukjinKwon commented on code in PR #36501: URL: https://github.com/apache/spark/pull/36501#discussion_r871903016 ## sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityParser.scala: ## @@ -318,7 +318,8 @@ class UnivocityParser( case e: SparkUpgradeException => throw e case NonFatal(e) => badRecordException = badRecordException.orElse(Some(e)) - row.setNullAt(i) + // Use the corresponding DEFAULT value associated with the column, if any. + row.update(i, parsedSchema.defaultValues(i)) Review Comment: Maybe we should do similar things at L286 too. The given `tokens` can be `null`, for example, when the input line is empty (this CSV code path is a bit convoluted) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dtenedor commented on a diff in pull request #36501: [SPARK-39143][SQL] Support CSV scans with DEFAULT values
dtenedor commented on code in PR #36501: URL: https://github.com/apache/spark/pull/36501#discussion_r871901106 ## sql/catalyst/src/main/scala/org/apache/spark/sql/types/StructType.scala: ## @@ -511,6 +511,30 @@ case class StructType(fields: Array[StructField]) extends DataType with Seq[Stru @transient private[sql] lazy val interpretedOrdering = InterpretedOrdering.forSchema(this.fields.map(_.dataType)) + + /** + * Parses the text representing constant-folded default column literal values. + * @return a sequence of either (1) NULL, if the column had no default value, or (2) an object of + * Any type suitable for assigning into a row using the InternalRow.update method. + */ + lazy val defaultValues: Seq[Any] = Review Comment: Yeah, that's not a bad idea since we will be accessing this for every row of data source scans. Done. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #36501: [SPARK-39143][SQL] Support CSV scans with DEFAULT values
HyukjinKwon commented on code in PR #36501: URL: https://github.com/apache/spark/pull/36501#discussion_r871900359 ## sql/catalyst/src/main/scala/org/apache/spark/sql/types/StructType.scala: ## @@ -511,6 +511,30 @@ case class StructType(fields: Array[StructField]) extends DataType with Seq[Stru @transient private[sql] lazy val interpretedOrdering = InterpretedOrdering.forSchema(this.fields.map(_.dataType)) + + /** + * Parses the text representing constant-folded default column literal values. + * @return a sequence of either (1) NULL, if the column had no default value, or (2) an object of + * Any type suitable for assigning into a row using the InternalRow.update method. + */ + lazy val defaultValues: Seq[Any] = Review Comment: Should probably use `Array[Any]` or `IndexedSeq[Any]` because it can be a view instance that causes loop-up cost via iteration. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #36509: [SPARK-38961][PYTHON][DOCS] Enhance to automatically generate the the pandas API support list
HyukjinKwon commented on code in PR #36509:
URL: https://github.com/apache/spark/pull/36509#discussion_r871898675
##
python/pyspark/pandas/supported_api_gen.py:
##
@@ -0,0 +1,363 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+"""
+Generate 'Supported pandas APIs' documentation file
+"""
+import os
+from enum import Enum, unique
+from inspect import getmembers, isclass, isfunction, signature
+from typing import Any, Callable, Dict, List, Set, TextIO, Tuple
+
+import pyspark.pandas as ps
+import pyspark.pandas.groupby as psg
+import pyspark.pandas.window as psw
+from pyspark.find_spark_home import _find_spark_home
+from pyspark.sql.pandas.utils import require_minimum_pandas_version
+
+import pandas as pd
+import pandas.core.groupby as pdg
+import pandas.core.window as pdw
+
+MAX_MISSING_PARAMS_SIZE = 5
+COMMON_PARAMETER_SET = {"kwargs", "args", "cls"}
+MODULE_GROUP_MATCH = [(pd, ps), (pdw, psw), (pdg, psg)]
+
+SPARK_HOME = _find_spark_home()
+TARGET_RST_FILE = os.path.join(
+SPARK_HOME,
"python/docs/source/user_guide/pandas_on_spark/supported_pandas_api.rst"
+)
+RST_HEADER = """
+=
+Supported pandas APIs
+=
+
+.. currentmodule:: pyspark.pandas
+
+The following table shows the pandas APIs that implemented or non-implemented
from pandas API on
+Spark.
+
+Some pandas APIs do not implement full parameters, so the third column shows
missing parameters for
+each API.
+
+'Y' in the second column means it's implemented including its whole parameter.
+'N' means it's not implemented yet.
+'P' means it's partially implemented with the missing of some parameters.
+
+If there is non-implemented pandas API or parameter you want, you can create
an `Apache Spark
+JIRA `__ to request or
to contribute by your
+own.
+
+The API list is updated based on the `latest pandas official API
+reference `__.
+
+All implemented APIs listed here are distributed except the ones that requires
the local
+computation by design. For example, `DataFrame.to_numpy()
`__ requires to collect the data to the driver side.
+
+"""
+
+
+@unique
+class Implemented(Enum):
+IMPLEMENTED = "Y"
+NOT_IMPLEMENTED = "N"
+PARTIALLY_IMPLEMENTED = "P"
+
+
+class SupportedStatus:
+"""
+SupportedStatus class that defines a supported status for a specific
pandas API
+"""
+
+def __init__(self, implemented: str, missing: str = ""):
+self.implemented = implemented
+self.missing = missing
+
+
+def generate_supported_api() -> None:
+"""
+Generate supported APIs status dictionary.
+
+Write supported APIs documentation.
+"""
+require_minimum_pandas_version()
Review Comment:
That docker file will be planned to be migrated to Apache Spark repo in the
future. Feel free to directly create a PR there too.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #36517: Revert "[SPARK-36837][BUILD] Upgrade Kafka to 3.1.0"
dongjoon-hyun commented on PR #36517: URL: https://github.com/apache/spark/pull/36517#issuecomment-1125525626 For master branch, we are starting to pursue Apache Kafka 3.2.x in Apache Spark 3.4 timeframe. - https://github.com/apache/spark/pull/36526 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #36509: [SPARK-38961][PYTHON][DOCS] Enhance to automatically generate the the pandas API support list
HyukjinKwon commented on code in PR #36509:
URL: https://github.com/apache/spark/pull/36509#discussion_r871898406
##
python/pyspark/pandas/supported_api_gen.py:
##
@@ -0,0 +1,363 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+"""
+Generate 'Supported pandas APIs' documentation file
+"""
+import os
+from enum import Enum, unique
+from inspect import getmembers, isclass, isfunction, signature
+from typing import Any, Callable, Dict, List, Set, TextIO, Tuple
+
+import pyspark.pandas as ps
+import pyspark.pandas.groupby as psg
+import pyspark.pandas.window as psw
+from pyspark.find_spark_home import _find_spark_home
+from pyspark.sql.pandas.utils import require_minimum_pandas_version
+
+import pandas as pd
+import pandas.core.groupby as pdg
+import pandas.core.window as pdw
+
+MAX_MISSING_PARAMS_SIZE = 5
+COMMON_PARAMETER_SET = {"kwargs", "args", "cls"}
+MODULE_GROUP_MATCH = [(pd, ps), (pdw, psw), (pdg, psg)]
+
+SPARK_HOME = _find_spark_home()
+TARGET_RST_FILE = os.path.join(
+SPARK_HOME,
"python/docs/source/user_guide/pandas_on_spark/supported_pandas_api.rst"
+)
+RST_HEADER = """
+=
+Supported pandas APIs
+=
+
+.. currentmodule:: pyspark.pandas
+
+The following table shows the pandas APIs that implemented or non-implemented
from pandas API on
+Spark.
+
+Some pandas APIs do not implement full parameters, so the third column shows
missing parameters for
+each API.
+
+'Y' in the second column means it's implemented including its whole parameter.
+'N' means it's not implemented yet.
+'P' means it's partially implemented with the missing of some parameters.
+
+If there is non-implemented pandas API or parameter you want, you can create
an `Apache Spark
+JIRA `__ to request or
to contribute by your
+own.
+
+The API list is updated based on the `latest pandas official API
+reference `__.
+
+All implemented APIs listed here are distributed except the ones that requires
the local
+computation by design. For example, `DataFrame.to_numpy()
`__ requires to collect the data to the driver side.
+
+"""
+
+
+@unique
+class Implemented(Enum):
+IMPLEMENTED = "Y"
+NOT_IMPLEMENTED = "N"
+PARTIALLY_IMPLEMENTED = "P"
+
+
+class SupportedStatus:
+"""
+SupportedStatus class that defines a supported status for a specific
pandas API
+"""
+
+def __init__(self, implemented: str, missing: str = ""):
+self.implemented = implemented
+self.missing = missing
+
+
+def generate_supported_api() -> None:
+"""
+Generate supported APIs status dictionary.
+
+Write supported APIs documentation.
+"""
+require_minimum_pandas_version()
Review Comment:
Feel free to file a child JIRA under
https://issues.apache.org/jira/browse/SPARK-38819. We should upgrade the Docker
image and republish at
https://github.com/dongjoon-hyun/ApacheSparkGitHubActionImage (cc
@dongjoon-hyun FYI)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #36509: [SPARK-38961][PYTHON][DOCS] Enhance to automatically generate the the pandas API support list
HyukjinKwon commented on code in PR #36509:
URL: https://github.com/apache/spark/pull/36509#discussion_r871897725
##
python/pyspark/pandas/supported_api_gen.py:
##
@@ -0,0 +1,363 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+"""
+Generate 'Supported pandas APIs' documentation file
+"""
+import os
+from enum import Enum, unique
+from inspect import getmembers, isclass, isfunction, signature
+from typing import Any, Callable, Dict, List, Set, TextIO, Tuple
+
+import pyspark.pandas as ps
+import pyspark.pandas.groupby as psg
+import pyspark.pandas.window as psw
+from pyspark.find_spark_home import _find_spark_home
+from pyspark.sql.pandas.utils import require_minimum_pandas_version
+
+import pandas as pd
+import pandas.core.groupby as pdg
+import pandas.core.window as pdw
+
+MAX_MISSING_PARAMS_SIZE = 5
+COMMON_PARAMETER_SET = {"kwargs", "args", "cls"}
+MODULE_GROUP_MATCH = [(pd, ps), (pdw, psw), (pdg, psg)]
+
+SPARK_HOME = _find_spark_home()
+TARGET_RST_FILE = os.path.join(
+SPARK_HOME,
"python/docs/source/user_guide/pandas_on_spark/supported_pandas_api.rst"
+)
+RST_HEADER = """
+=
+Supported pandas APIs
+=
+
+.. currentmodule:: pyspark.pandas
+
+The following table shows the pandas APIs that implemented or non-implemented
from pandas API on
+Spark.
+
+Some pandas APIs do not implement full parameters, so the third column shows
missing parameters for
+each API.
+
+'Y' in the second column means it's implemented including its whole parameter.
+'N' means it's not implemented yet.
+'P' means it's partially implemented with the missing of some parameters.
+
+If there is non-implemented pandas API or parameter you want, you can create
an `Apache Spark
+JIRA `__ to request or
to contribute by your
+own.
+
+The API list is updated based on the `latest pandas official API
+reference `__.
+
+All implemented APIs listed here are distributed except the ones that requires
the local
+computation by design. For example, `DataFrame.to_numpy()
`__ requires to collect the data to the driver side.
+
+"""
+
+
+@unique
+class Implemented(Enum):
+IMPLEMENTED = "Y"
+NOT_IMPLEMENTED = "N"
+PARTIALLY_IMPLEMENTED = "P"
+
+
+class SupportedStatus:
+"""
+SupportedStatus class that defines a supported status for a specific
pandas API
+"""
+
+def __init__(self, implemented: str, missing: str = ""):
+self.implemented = implemented
+self.missing = missing
+
+
+def generate_supported_api() -> None:
+"""
+Generate supported APIs status dictionary.
+
+Write supported APIs documentation.
+"""
+require_minimum_pandas_version()
Review Comment:
Ah, it's my bad. Can we just print out the warning if pandas is lower than
1.4.0 for now?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #36135: [WIP][SPARK-38850][BUILD] Upgrade Kafka to 3.1.1
dongjoon-hyun closed pull request #36135: [WIP][SPARK-38850][BUILD] Upgrade Kafka to 3.1.1 URL: https://github.com/apache/spark/pull/36135 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #36135: [WIP][SPARK-38850][BUILD] Upgrade Kafka to 3.1.1
dongjoon-hyun commented on PR #36135: URL: https://github.com/apache/spark/pull/36135#issuecomment-1125523557 This is superseded by https://github.com/apache/spark/pull/36526 . -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun opened a new pull request, #36526: [SPARK-38850][BUILD] Upgrade Kafka to 3.2.0
dongjoon-hyun opened a new pull request, #36526: URL: https://github.com/apache/spark/pull/36526 ### What changes were proposed in this pull request? ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] BryanCutler commented on pull request #36518: [SPARK-39160][SQL] Remove workaround for ARROW-1948
BryanCutler commented on PR #36518: URL: https://github.com/apache/spark/pull/36518#issuecomment-1125504062 merged to master, thanks @pan3793 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] BryanCutler closed pull request #36518: [SPARK-39160][SQL] Remove workaround for ARROW-1948
BryanCutler closed pull request #36518: [SPARK-39160][SQL] Remove workaround for ARROW-1948 URL: https://github.com/apache/spark/pull/36518 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] attilapiros commented on a diff in pull request #36512: [SPARK-39152][CORE] Deregistering disk persisted local RDD blocks in case of IO related errors
attilapiros commented on code in PR #36512:
URL: https://github.com/apache/spark/pull/36512#discussion_r871823407
##
core/src/main/scala/org/apache/spark/storage/BlockManager.scala:
##
@@ -933,10 +933,29 @@ private[spark] class BlockManager(
})
Some(new BlockResult(ci, DataReadMethod.Memory, info.size))
} else if (level.useDisk && diskStore.contains(blockId)) {
- try {
-val diskData = diskStore.getBytes(blockId)
-val iterToReturn: Iterator[Any] = {
- if (level.deserialized) {
+ var retryCount = 0
+ val retryLimit = 3
Review Comment:
As I know in case of bad sectors retries might help although I am uncertain
whether this already done in a lower level of the IO operation (but this 3
retries is close to the old behaviour when by default Spark retried the task 4
times).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #36518: [SPARK-39160][SQL] Remove workaround for ARROW-1948
AmplabJenkins commented on PR #36518: URL: https://github.com/apache/spark/pull/36518#issuecomment-1125423319 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk closed pull request #36500: [SPARK-39164][SQL] Wrap asserts/illegal state exceptions by the INTERNAL_ERROR exception in actions
MaxGekk closed pull request #36500: [SPARK-39164][SQL] Wrap asserts/illegal state exceptions by the INTERNAL_ERROR exception in actions URL: https://github.com/apache/spark/pull/36500 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on pull request #36500: [SPARK-39164][SQL] Wrap asserts/illegal state exceptions by the INTERNAL_ERROR exception in actions
MaxGekk commented on PR #36500: URL: https://github.com/apache/spark/pull/36500#issuecomment-1125412163 Merging to master. Thank you, @cloud-fan for review. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on pull request #36500: [SPARK-39164][SQL] Wrap asserts/illegal state exceptions by the INTERNAL_ERROR exception in actions
MaxGekk commented on PR #36500: URL: https://github.com/apache/spark/pull/36500#issuecomment-1125377146 All GAs except of [Run Docker integration tests](https://github.com/MaxGekk/spark/runs/6411188536?check_suite_focus=true) passed. I will re-run and wait for the docker tests only. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dtenedor commented on a diff in pull request #36365: [SPARK-28516][SQL] Implement `to_char` and `try_to_char` functions to format Decimal values as strings
dtenedor commented on code in PR #36365:
URL: https://github.com/apache/spark/pull/36365#discussion_r871723562
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/numberFormatExpressions.scala:
##
@@ -168,3 +168,159 @@ case class TryToNumber(left: Expression, right:
Expression)
newRight: Expression): TryToNumber =
copy(left = newLeft, right = newRight)
}
+
+/**
+ * A function that converts decimal values to strings, returning NULL if the
decimal value fails to
+ * match the format string.
+ */
+@ExpressionDescription(
+ usage = """
+_FUNC_(numberExpr, formatExpr) - Convert `numberExpr` to a string based on
the `formatExpr`.
+ Throws an exception if the conversion fails. The format can consist of
the following
+ characters, case insensitive:
+'0' or '9': Specifies an expected digit between 0 and 9. A sequence of
0 or 9 in the format
+ string matches a sequence of digits in the input value, generating a
result string of the
+ same length as the corresponding sequence in the format string. The
result string is
+ left-padded with zeros if the 0/9 sequence comprises more digits
than the matching part of
+ the decimal value, starts with 0, and is before the decimal point.
Otherwise, it is
+ padded with spaces.
+'.' or 'D': Specifies the position of the decimal point (optional,
only allowed once).
+',' or 'G': Specifies the position of the grouping (thousands)
separator (,). There must be
+ a 0 or 9 to the left and right of each grouping separator.
+'$': Specifies the location of the $ currency sign. This character may
only be specified
+ once.
+'S' or 'MI': Specifies the position of a '-' or '+' sign (optional,
only allowed once at
+ the beginning or end of the format string). Note that 'S' prints '+'
for positive values
+ but 'MI' prints a space.
+'PR': Only allowed at the end of the format string; specifies that the
result string will be
+ wrapped by angle brackets if the input value is negative.
+ ('<1>').
+ """,
+ examples = """
+Examples:
+ > SELECT _FUNC_(454, '999');
+ 454
+ > SELECT _FUNC_(454.00, '000D00');
+ 454.00
+ > SELECT _FUNC_(12454, '99G999');
+ 12,454
+ > SELECT _FUNC_(78.12, '$99.99');
+ $78.12
+ > SELECT _FUNC_(-12454.8, '99G999D9S');
+ 12,454.8-
+ """,
+ since = "3.3.0",
Review Comment:
Done.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dtenedor commented on a diff in pull request #36365: [SPARK-28516][SQL] Implement `to_char` and `try_to_char` functions to format Decimal values as strings
dtenedor commented on code in PR #36365:
URL: https://github.com/apache/spark/pull/36365#discussion_r871723101
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/ToNumberParser.scala:
##
@@ -599,4 +614,250 @@ class ToNumberParser(numberFormat: String, errorOnFail:
Boolean) extends Seriali
Decimal(javaDecimal, precision, scale)
}
}
+
+ /**
+ * Converts a decimal value to a string based on the given number format.
+ *
+ * Iterates through the [[formatTokens]] obtained from processing the format
string, while also
+ * inspecting the input decimal value.
+ *
+ * @param input the decimal value that needs to be converted
+ * @return the result String value obtained from string formatting
+ */
+ def format(input: Decimal): UTF8String = {
+val result = new StringBuilder()
+// These are string representations of the input Decimal value.
+val (inputBeforeDecimalPoint: String,
+ inputAfterDecimalPoint: String) =
+ formatSplitInputBeforeAndAfterDecimalPoint(input)
+// These are indexes into the characters of the input string before and
after the decimal point.
+formattingBeforeDecimalPointIndex = 0
+formattingAfterDecimalPointIndex = 0
+var reachedDecimalPoint = false
+
+// Iterate through the tokens representing the provided format string, in
order.
+for (formatToken: InputToken <- formatTokens) {
+ formatToken match {
+case groups: DigitGroups =>
+ formatDigitGroups(
+groups, inputBeforeDecimalPoint, inputAfterDecimalPoint,
reachedDecimalPoint, result)
+case DecimalPoint() =>
+ // If the last character so far is a space, change it to a zero.
This means the input
+ // decimal does not have an integer part.
+ if (result.nonEmpty && result.last == SPACE) {
+result(result.length - 1) = ZERO_DIGIT
+ }
+ result.append(POINT_SIGN)
+ reachedDecimalPoint = true
+case DollarSign() =>
+ result.append(DOLLAR_SIGN)
+case _: OptionalPlusOrMinusSign =>
+ stripTrailingLoneDecimalPoint(result)
+ if (input < Decimal.ZERO) {
+addCharacterCheckingTrailingSpaces(result, MINUS_SIGN)
+ } else {
+addCharacterCheckingTrailingSpaces(result, PLUS_SIGN)
+ }
+case _: OptionalMinusSign =>
+ if (input < Decimal.ZERO) {
+stripTrailingLoneDecimalPoint(result)
+addCharacterCheckingTrailingSpaces(result, MINUS_SIGN)
+// Add a second space to account for the "MI" sequence comprising
two characters in the
+// format string.
+result.append(SPACE)
+ } else {
+result.append(SPACE)
+result.append(SPACE)
+ }
+case OpeningAngleBracket() =>
+ if (input < Decimal.ZERO) {
+result.append(ANGLE_BRACKET_OPEN)
+ }
+case ClosingAngleBracket() =>
+ stripTrailingLoneDecimalPoint(result)
+ if (input < Decimal.ZERO) {
+addCharacterCheckingTrailingSpaces(result, ANGLE_BRACKET_CLOSE)
+ } else {
+result.append(SPACE)
+result.append(SPACE)
+ }
+ }
+}
+
+if (formattingBeforeDecimalPointIndex < inputBeforeDecimalPoint.length ||
+ formattingAfterDecimalPointIndex < inputAfterDecimalPoint.length) {
+ // Remaining digits before or after the decimal point exist in the
decimal value but not in
+ // the format string.
+ formatMatchFailure(input, numberFormat)
+} else {
+ stripTrailingLoneDecimalPoint(result)
+ val str = result.toString
+ if (result.isEmpty || str == "+" || str == "-") {
+UTF8String.fromString("0")
+ } else {
+UTF8String.fromString(str)
+ }
+}
+ }
+
+ /**
+ * Splits the provided Decimal value's string representation by the decimal
point, if any.
+ * @param input the Decimal value to consume
+ * @return two strings representing the contents before and after the
decimal point (if any)
+ */
+ private def formatSplitInputBeforeAndAfterDecimalPoint(input: Decimal):
(String, String) = {
+// Convert the input Decimal value to a string (without exponent notation).
+val inputString = input.toJavaBigDecimal.toPlainString
+// Split the digits before and after the decimal point.
+val tokens: Array[String] = inputString.split(POINT_SIGN)
+var beforeDecimalPoint: String = tokens(0)
+var afterDecimalPoint: String = if (tokens.length > 1) tokens(1) else ""
+// Strip any leading minus sign to consider the digits only.
+// Strip leading and trailing zeros to match cases when the format string
begins with a decimal
+// point.
+beforeDecimalPoint = beforeDecimalPoint.dropWhile(c => c == MINUS_SIGN ||
c == ZERO_DIGIT)
+afterDecimalPoint = afterDecimalPoint.reverse.dropWhile(_ ==
ZERO_DIGIT).reverse
+
+
[GitHub] [spark] dtenedor commented on a diff in pull request #36365: [SPARK-28516][SQL] Implement `to_char` and `try_to_char` functions to format Decimal values as strings
dtenedor commented on code in PR #36365:
URL: https://github.com/apache/spark/pull/36365#discussion_r871722008
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/ToNumberParser.scala:
##
@@ -599,4 +614,250 @@ class ToNumberParser(numberFormat: String, errorOnFail:
Boolean) extends Seriali
Decimal(javaDecimal, precision, scale)
}
}
+
+ /**
+ * Converts a decimal value to a string based on the given number format.
+ *
+ * Iterates through the [[formatTokens]] obtained from processing the format
string, while also
+ * inspecting the input decimal value.
+ *
+ * @param input the decimal value that needs to be converted
+ * @return the result String value obtained from string formatting
+ */
+ def format(input: Decimal): UTF8String = {
+val result = new StringBuilder()
+// These are string representations of the input Decimal value.
+val (inputBeforeDecimalPoint: String,
+ inputAfterDecimalPoint: String) =
+ formatSplitInputBeforeAndAfterDecimalPoint(input)
+// These are indexes into the characters of the input string before and
after the decimal point.
+formattingBeforeDecimalPointIndex = 0
+formattingAfterDecimalPointIndex = 0
+var reachedDecimalPoint = false
+
+// Iterate through the tokens representing the provided format string, in
order.
+for (formatToken: InputToken <- formatTokens) {
+ formatToken match {
+case groups: DigitGroups =>
+ formatDigitGroups(
+groups, inputBeforeDecimalPoint, inputAfterDecimalPoint,
reachedDecimalPoint, result)
+case DecimalPoint() =>
+ // If the last character so far is a space, change it to a zero.
This means the input
+ // decimal does not have an integer part.
+ if (result.nonEmpty && result.last == SPACE) {
+result(result.length - 1) = ZERO_DIGIT
+ }
+ result.append(POINT_SIGN)
+ reachedDecimalPoint = true
+case DollarSign() =>
+ result.append(DOLLAR_SIGN)
+case _: OptionalPlusOrMinusSign =>
+ stripTrailingLoneDecimalPoint(result)
+ if (input < Decimal.ZERO) {
+addCharacterCheckingTrailingSpaces(result, MINUS_SIGN)
+ } else {
+addCharacterCheckingTrailingSpaces(result, PLUS_SIGN)
+ }
+case _: OptionalMinusSign =>
+ if (input < Decimal.ZERO) {
+stripTrailingLoneDecimalPoint(result)
+addCharacterCheckingTrailingSpaces(result, MINUS_SIGN)
+// Add a second space to account for the "MI" sequence comprising
two characters in the
+// format string.
+result.append(SPACE)
+ } else {
+result.append(SPACE)
+result.append(SPACE)
+ }
+case OpeningAngleBracket() =>
+ if (input < Decimal.ZERO) {
+result.append(ANGLE_BRACKET_OPEN)
+ }
+case ClosingAngleBracket() =>
+ stripTrailingLoneDecimalPoint(result)
+ if (input < Decimal.ZERO) {
+addCharacterCheckingTrailingSpaces(result, ANGLE_BRACKET_CLOSE)
+ } else {
+result.append(SPACE)
+result.append(SPACE)
+ }
+ }
+}
+
+if (formattingBeforeDecimalPointIndex < inputBeforeDecimalPoint.length ||
+ formattingAfterDecimalPointIndex < inputAfterDecimalPoint.length) {
+ // Remaining digits before or after the decimal point exist in the
decimal value but not in
+ // the format string.
+ formatMatchFailure(input, numberFormat)
+} else {
+ stripTrailingLoneDecimalPoint(result)
+ val str = result.toString
+ if (result.isEmpty || str == "+" || str == "-") {
+UTF8String.fromString("0")
+ } else {
+UTF8String.fromString(str)
+ }
+}
+ }
+
+ /**
+ * Splits the provided Decimal value's string representation by the decimal
point, if any.
+ * @param input the Decimal value to consume
+ * @return two strings representing the contents before and after the
decimal point (if any)
+ */
+ private def formatSplitInputBeforeAndAfterDecimalPoint(input: Decimal):
(String, String) = {
+// Convert the input Decimal value to a string (without exponent notation).
+val inputString = input.toJavaBigDecimal.toPlainString
+// Split the digits before and after the decimal point.
+val tokens: Array[String] = inputString.split(POINT_SIGN)
+var beforeDecimalPoint: String = tokens(0)
+var afterDecimalPoint: String = if (tokens.length > 1) tokens(1) else ""
+// Strip any leading minus sign to consider the digits only.
+// Strip leading and trailing zeros to match cases when the format string
begins with a decimal
+// point.
+beforeDecimalPoint = beforeDecimalPoint.dropWhile(c => c == MINUS_SIGN ||
c == ZERO_DIGIT)
+afterDecimalPoint = afterDecimalPoint.reverse.dropWhile(_ ==
ZERO_DIGIT).reverse
+
+
[GitHub] [spark] dtenedor commented on a diff in pull request #36445: [SPARK-39096][SQL] Support MERGE commands with DEFAULT values
dtenedor commented on code in PR #36445:
URL: https://github.com/apache/spark/pull/36445#discussion_r871717000
##
sql/core/src/test/scala/org/apache/spark/sql/execution/command/PlanResolutionSuite.scala:
##
@@ -1510,6 +1510,151 @@ class PlanResolutionSuite extends AnalysisTest {
case other => fail("Expect MergeIntoTable, but got:\n" +
other.treeString)
}
+
+// DEFAULT columns (implicit):
+// All cases of the $target table lack any explicitly-defined DEFAULT
columns. Therefore any
+// DEFAULT column references in the below MERGE INTO command should
resolve to literal NULL.
+// This test case covers that behavior.
+val sql6 =
+ s"""
+ |MERGE INTO $target AS target
+ |USING $source AS source
+ |ON target.i = source.i
+ |WHEN MATCHED AND (target.s='delete') THEN DELETE
+ |WHEN MATCHED AND (target.s='update')
+ |THEN UPDATE SET target.s = DEFAULT, target.i = target.i
+ |WHEN NOT MATCHED AND (source.s='insert')
+ | THEN INSERT (target.i, target.s) values (DEFAULT, DEFAULT)
+ """.stripMargin
+parseAndResolve(sql6) match {
+ case m: MergeIntoTable =>
+val source = m.sourceTable
+val target = m.targetTable
+val ti = target.output.find(_.name ==
"i").get.asInstanceOf[AttributeReference]
+val si = source.output.find(_.name ==
"i").get.asInstanceOf[AttributeReference]
+m.mergeCondition match {
+ case EqualTo(l: AttributeReference, r: AttributeReference) =>
+assert(l.sameRef(ti) && r.sameRef(si))
+ case Literal(_, BooleanType) => // this is acceptable as a merge
condition
+ case other => fail("unexpected merge condition " + other)
+}
+assert(m.matchedActions.length == 2)
+val first = m.matchedActions(0)
+first match {
+ case DeleteAction(Some(EqualTo(_: AttributeReference,
StringLiteral("delete" =>
+ case other => fail("unexpected first matched action " + other)
+}
+val second = m.matchedActions(1)
+second match {
+ case UpdateAction(Some(EqualTo(_: AttributeReference,
StringLiteral("update"))),
+Seq(
+ Assignment(_: AttributeReference, AnsiCast(Literal(null, _),
StringType, _)),
+ Assignment(_: AttributeReference, _: AttributeReference))) =>
+ case other => fail("unexpected second matched action " + other)
+}
+assert(m.notMatchedActions.length == 1)
+val negative = m.notMatchedActions(0)
+negative match {
+ case InsertAction(Some(EqualTo(_: AttributeReference,
StringLiteral("insert"))),
+ Seq(Assignment(i: AttributeReference, AnsiCast(Literal(null, _),
IntegerType, _)),
+ Assignment(s: AttributeReference, AnsiCast(Literal(null, _),
StringType, _ =>
+assert(i.name == "i")
+assert(s.name == "s")
+ case other => fail("unexpected not matched action " + other)
+}
+
+ case other =>
+fail("Expect MergeIntoTable, but got:\n" + other.treeString)
+}
+
+// DEFAULT column reference in the merge condition:
+// This MERGE INTO command includes an ON clause with a DEFAULT column
reference. This is
+// invalid and returns an error message.
+val mergeWithDefaultReferenceInMergeCondition =
+s"""
Review Comment:
Done.
##
sql/core/src/test/scala/org/apache/spark/sql/execution/command/PlanResolutionSuite.scala:
##
@@ -1510,6 +1510,151 @@ class PlanResolutionSuite extends AnalysisTest {
case other => fail("Expect MergeIntoTable, but got:\n" +
other.treeString)
}
+
+// DEFAULT columns (implicit):
+// All cases of the $target table lack any explicitly-defined DEFAULT
columns. Therefore any
+// DEFAULT column references in the below MERGE INTO command should
resolve to literal NULL.
+// This test case covers that behavior.
+val sql6 =
+ s"""
+ |MERGE INTO $target AS target
+ |USING $source AS source
+ |ON target.i = source.i
+ |WHEN MATCHED AND (target.s='delete') THEN DELETE
+ |WHEN MATCHED AND (target.s='update')
+ |THEN UPDATE SET target.s = DEFAULT, target.i = target.i
+ |WHEN NOT MATCHED AND (source.s='insert')
+ | THEN INSERT (target.i, target.s) values (DEFAULT, DEFAULT)
+ """.stripMargin
+parseAndResolve(sql6) match {
+ case m: MergeIntoTable =>
+val source = m.sourceTable
+val target = m.targetTable
+val ti = target.output.find(_.name ==
[GitHub] [spark] dtenedor commented on a diff in pull request #36445: [SPARK-39096][SQL] Support MERGE commands with DEFAULT values
dtenedor commented on code in PR #36445: URL: https://github.com/apache/spark/pull/36445#discussion_r871714091 ## sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala: ## @@ -287,6 +287,7 @@ class Analyzer(override val catalogManager: CatalogManager) ResolveFieldNameAndPosition :: AddMetadataColumns :: DeduplicateRelations :: + ResolveDefaultColumns(this, v1SessionCatalog) :: Review Comment: The `resolveMergeExprOrFail` method was returning errors on the DEFAULT column attribute reference. Moving the rule earlier processed the DEFAULT column before that. However, I am able to just update that method to skip errors for DEFAULT column references anyway. That works because all DEFAULT column references should either get replaced by the `ResolveDefaultColumns` rule, or otherwise return some kind of `not implemented` error (e.g. may not appear in the merge condition). https://user-images.githubusercontent.com/99207096/168148277-109c238e-afa0-48ec-b75f-a1594f5c9f95.png;> -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beobest2 commented on a diff in pull request #36509: [SPARK-38961][PYTHON][DOCS] Enhance to automatically generate the the pandas API support list
beobest2 commented on code in PR #36509:
URL: https://github.com/apache/spark/pull/36509#discussion_r871692740
##
python/pyspark/pandas/supported_api_gen.py:
##
@@ -0,0 +1,363 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+"""
+Generate 'Supported pandas APIs' documentation file
+"""
+import os
+from enum import Enum, unique
+from inspect import getmembers, isclass, isfunction, signature
+from typing import Any, Callable, Dict, List, Set, TextIO, Tuple
+
+import pyspark.pandas as ps
+import pyspark.pandas.groupby as psg
+import pyspark.pandas.window as psw
+from pyspark.find_spark_home import _find_spark_home
+from pyspark.sql.pandas.utils import require_minimum_pandas_version
+
+import pandas as pd
+import pandas.core.groupby as pdg
+import pandas.core.window as pdw
+
+MAX_MISSING_PARAMS_SIZE = 5
+COMMON_PARAMETER_SET = {"kwargs", "args", "cls"}
+MODULE_GROUP_MATCH = [(pd, ps), (pdw, psw), (pdg, psg)]
+
+SPARK_HOME = _find_spark_home()
+TARGET_RST_FILE = os.path.join(
+SPARK_HOME,
"python/docs/source/user_guide/pandas_on_spark/supported_pandas_api.rst"
+)
+RST_HEADER = """
+=
+Supported pandas APIs
+=
+
+.. currentmodule:: pyspark.pandas
+
+The following table shows the pandas APIs that implemented or non-implemented
from pandas API on
+Spark.
+
+Some pandas APIs do not implement full parameters, so the third column shows
missing parameters for
+each API.
+
+'Y' in the second column means it's implemented including its whole parameter.
+'N' means it's not implemented yet.
+'P' means it's partially implemented with the missing of some parameters.
+
+If there is non-implemented pandas API or parameter you want, you can create
an `Apache Spark
+JIRA `__ to request or
to contribute by your
+own.
+
+The API list is updated based on the `latest pandas official API
+reference `__.
+
+All implemented APIs listed here are distributed except the ones that requires
the local
+computation by design. For example, `DataFrame.to_numpy()
`__ requires to collect the data to the driver side.
+
+"""
+
+
+@unique
+class Implemented(Enum):
+IMPLEMENTED = "Y"
+NOT_IMPLEMENTED = "N"
+PARTIALLY_IMPLEMENTED = "P"
+
+
+class SupportedStatus:
+"""
+SupportedStatus class that defines a supported status for a specific
pandas API
+"""
+
+def __init__(self, implemented: str, missing: str = ""):
+self.implemented = implemented
+self.missing = missing
+
+
+def generate_supported_api() -> None:
+"""
+Generate supported APIs status dictionary.
+
+Write supported APIs documentation.
+"""
+require_minimum_pandas_version()
Review Comment:
@HyukjinKwon Should I lower the check version? Or should I wait for the
pandas version of the github action's Docker to be updated?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beobest2 commented on a diff in pull request #36509: [SPARK-38961][PYTHON][DOCS] Enhance to automatically generate the the pandas API support list
beobest2 commented on code in PR #36509:
URL: https://github.com/apache/spark/pull/36509#discussion_r871689321
##
python/pyspark/pandas/supported_api_gen.py:
##
@@ -0,0 +1,366 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+"""
+Generate 'Supported pandas APIs' documentation file
+"""
+import os
+from distutils.version import LooseVersion
+from enum import Enum, unique
+from inspect import getmembers, isclass, isfunction, signature
+from typing import Any, Callable, Dict, List, Set, TextIO, Tuple
+
+import pyspark.pandas as ps
+import pyspark.pandas.groupby as psg
+import pyspark.pandas.window as psw
+from pyspark.find_spark_home import _find_spark_home
+
+import pandas as pd
+import pandas.core.groupby as pdg
+import pandas.core.window as pdw
+
+MAX_MISSING_PARAMS_SIZE = 5
+COMMON_PARAMETER_SET = {"kwargs", "args", "cls"}
Review Comment:
@xinrong-databricks Good idea! I've just added the comment.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xinrong-databricks commented on a diff in pull request #36509: [SPARK-38961][PYTHON][DOCS] Enhance to automatically generate the the pandas API support list
xinrong-databricks commented on code in PR #36509:
URL: https://github.com/apache/spark/pull/36509#discussion_r871683780
##
python/pyspark/pandas/supported_api_gen.py:
##
@@ -0,0 +1,366 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+"""
+Generate 'Supported pandas APIs' documentation file
+"""
+import os
+from distutils.version import LooseVersion
+from enum import Enum, unique
+from inspect import getmembers, isclass, isfunction, signature
+from typing import Any, Callable, Dict, List, Set, TextIO, Tuple
+
+import pyspark.pandas as ps
+import pyspark.pandas.groupby as psg
+import pyspark.pandas.window as psw
+from pyspark.find_spark_home import _find_spark_home
+
+import pandas as pd
+import pandas.core.groupby as pdg
+import pandas.core.window as pdw
+
+MAX_MISSING_PARAMS_SIZE = 5
+COMMON_PARAMETER_SET = {"kwargs", "args", "cls"}
Review Comment:
nit: Shall we comment that elements in `COMMON_PARAMETER_SET` are not
counted as missing parameters?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #36522: [SPARK-39161][BUILD] Upgrade rocksdbjni to 7.2.2
dongjoon-hyun closed pull request #36522: [SPARK-39161][BUILD] Upgrade rocksdbjni to 7.2.2 URL: https://github.com/apache/spark/pull/36522 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #36517: Revert "[SPARK-36837][BUILD] Upgrade Kafka to 3.1.0"
dongjoon-hyun closed pull request #36517: Revert "[SPARK-36837][BUILD] Upgrade Kafka to 3.1.0" URL: https://github.com/apache/spark/pull/36517 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #36517: Revert "[SPARK-36837][BUILD] Upgrade Kafka to 3.1.0"
dongjoon-hyun commented on PR #36517: URL: https://github.com/apache/spark/pull/36517#issuecomment-1125272185 Thank you, @HeartSaVioR and all. - I've been using Kafka 3.1.0 internally to consume the latest updates and there was no serious issue from our side with our setup so far. On top of that, we are going to use Apache Kafka 3.1.1 (with RC1) and catch up 3.2.0 internally in separate Spark versions because we can adapt easily internally if something happens. - Apache Spark community has enough discussions from the initial Kafka 3.1 PR and on the mailing list (Thanks to you). I have been agreed all colleagues' valid concerns and grateful to have this trial together. This reverting has been also one of options which was proposed by me from the beginning. - This PR adopts all your concerns and tries to choose the best combination of AS-OF-TODAY in terms of the new features, stability and maintainability not only Apache Spark 3.3.0, but also upcoming maintenance versions like Apache Spark 3.3.1, 3.3.2, and 3.3.4. - AFAIK, the latest Kafka 3.2 is worth of re-trying in `master` branch (Apache Spark 3.4 timeframe) because Apache Kafka community is really moving fast toward. Merged to branch-3.3. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beobest2 commented on a diff in pull request #36509: [SPARK-38961][PYTHON][DOCS] Enhance to automatically generate the the pandas API support list
beobest2 commented on code in PR #36509:
URL: https://github.com/apache/spark/pull/36509#discussion_r871643023
##
python/pyspark/pandas/supported_api_gen.py:
##
@@ -0,0 +1,363 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+"""
+Generate 'Supported pandas APIs' documentation file
+"""
+import os
+from enum import Enum, unique
+from inspect import getmembers, isclass, isfunction, signature
+from typing import Any, Callable, Dict, List, Set, TextIO, Tuple
+
+import pyspark.pandas as ps
+import pyspark.pandas.groupby as psg
+import pyspark.pandas.window as psw
+from pyspark.find_spark_home import _find_spark_home
+from pyspark.sql.pandas.utils import require_minimum_pandas_version
+
+import pandas as pd
+import pandas.core.groupby as pdg
+import pandas.core.window as pdw
+
+MAX_MISSING_PARAMS_SIZE = 5
+COMMON_PARAMETER_SET = {"kwargs", "args", "cls"}
+MODULE_GROUP_MATCH = [(pd, ps), (pdw, psw), (pdg, psg)]
+
+SPARK_HOME = _find_spark_home()
+TARGET_RST_FILE = os.path.join(
+SPARK_HOME,
"python/docs/source/user_guide/pandas_on_spark/supported_pandas_api.rst"
+)
+RST_HEADER = """
+=
+Supported pandas APIs
+=
+
+.. currentmodule:: pyspark.pandas
+
+The following table shows the pandas APIs that implemented or non-implemented
from pandas API on
+Spark.
+
+Some pandas APIs do not implement full parameters, so the third column shows
missing parameters for
+each API.
+
+'Y' in the second column means it's implemented including its whole parameter.
+'N' means it's not implemented yet.
+'P' means it's partially implemented with the missing of some parameters.
+
+If there is non-implemented pandas API or parameter you want, you can create
an `Apache Spark
+JIRA `__ to request or
to contribute by your
+own.
+
+The API list is updated based on the `latest pandas official API
+reference `__.
+
+All implemented APIs listed here are distributed except the ones that requires
the local
+computation by design. For example, `DataFrame.to_numpy()
`__ requires to collect the data to the driver side.
+
+"""
+
+
+@unique
+class Implemented(Enum):
+IMPLEMENTED = "Y"
+NOT_IMPLEMENTED = "N"
+PARTIALLY_IMPLEMENTED = "P"
+
+
+class SupportedStatus:
+"""
+SupportedStatus class that defines a supported status for a specific
pandas API
+"""
+
+def __init__(self, implemented: str, missing: str = ""):
+self.implemented = implemented
+self.missing = missing
+
+
+def generate_supported_api() -> None:
+"""
+Generate supported APIs status dictionary.
+
+Write supported APIs documentation.
+"""
+require_minimum_pandas_version()
Review Comment:
After adding this
[code](https://github.com/apache/spark/pull/36509/files#diff-514ad07071095eb4dd210dc4360962858cb3412bc867bac6ae1e06cbbff0cd96R99),
build doc from [github action
failed](https://github.com/beobest2/spark/runs/6409608100?check_suite_focus=true).
The pandas version of Docker image
`dongjoon/apache-spark-github-action-image:20220207` seems "1.3.5"
```
Configuration error:
There is a programmable error in your configuration file:
Traceback (most recent call last):
File "/usr/local/lib/python3.9/dist-packages/sphinx/config.py", line 319,
in eval_config_file
execfile_(filename, namespace)
File "/usr/local/lib/python3.9/dist-packages/sphinx/util/pycompat.py",
line 81, in execfile_
exec(code, _globals)
File "/__w/spark/spark/python/docs/source/conf.py", line 27, in
generate_supported_api()
File "/__w/spark/spark/python/pyspark/pandas/supported_api_gen.py", line
100, in generate_supported_api
raise ImportError(
ImportError: Pandas >= 1.4.0 must be installed; however, your version was
1.3.5.
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail:
[GitHub] [spark] beobest2 commented on a diff in pull request #36509: [SPARK-38961][PYTHON][DOCS] Enhance to automatically generate the the pandas API support list
beobest2 commented on code in PR #36509:
URL: https://github.com/apache/spark/pull/36509#discussion_r871643023
##
python/pyspark/pandas/supported_api_gen.py:
##
@@ -0,0 +1,363 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+"""
+Generate 'Supported pandas APIs' documentation file
+"""
+import os
+from enum import Enum, unique
+from inspect import getmembers, isclass, isfunction, signature
+from typing import Any, Callable, Dict, List, Set, TextIO, Tuple
+
+import pyspark.pandas as ps
+import pyspark.pandas.groupby as psg
+import pyspark.pandas.window as psw
+from pyspark.find_spark_home import _find_spark_home
+from pyspark.sql.pandas.utils import require_minimum_pandas_version
+
+import pandas as pd
+import pandas.core.groupby as pdg
+import pandas.core.window as pdw
+
+MAX_MISSING_PARAMS_SIZE = 5
+COMMON_PARAMETER_SET = {"kwargs", "args", "cls"}
+MODULE_GROUP_MATCH = [(pd, ps), (pdw, psw), (pdg, psg)]
+
+SPARK_HOME = _find_spark_home()
+TARGET_RST_FILE = os.path.join(
+SPARK_HOME,
"python/docs/source/user_guide/pandas_on_spark/supported_pandas_api.rst"
+)
+RST_HEADER = """
+=
+Supported pandas APIs
+=
+
+.. currentmodule:: pyspark.pandas
+
+The following table shows the pandas APIs that implemented or non-implemented
from pandas API on
+Spark.
+
+Some pandas APIs do not implement full parameters, so the third column shows
missing parameters for
+each API.
+
+'Y' in the second column means it's implemented including its whole parameter.
+'N' means it's not implemented yet.
+'P' means it's partially implemented with the missing of some parameters.
+
+If there is non-implemented pandas API or parameter you want, you can create
an `Apache Spark
+JIRA `__ to request or
to contribute by your
+own.
+
+The API list is updated based on the `latest pandas official API
+reference `__.
+
+All implemented APIs listed here are distributed except the ones that requires
the local
+computation by design. For example, `DataFrame.to_numpy()
`__ requires to collect the data to the driver side.
+
+"""
+
+
+@unique
+class Implemented(Enum):
+IMPLEMENTED = "Y"
+NOT_IMPLEMENTED = "N"
+PARTIALLY_IMPLEMENTED = "P"
+
+
+class SupportedStatus:
+"""
+SupportedStatus class that defines a supported status for a specific
pandas API
+"""
+
+def __init__(self, implemented: str, missing: str = ""):
+self.implemented = implemented
+self.missing = missing
+
+
+def generate_supported_api() -> None:
+"""
+Generate supported APIs status dictionary.
+
+Write supported APIs documentation.
+"""
+require_minimum_pandas_version()
Review Comment:
After adding this
[code](https://github.com/apache/spark/pull/36509/files#diff-514ad07071095eb4dd210dc4360962858cb3412bc867bac6ae1e06cbbff0cd96R99),
build doc from [github action
failed](https://github.com/beobest2/spark/runs/6409608100?check_suite_focus=true).
The pandas version of `dongjoon/apache-spark-github-action-image:20220207`
seems "1.3.5"
```
Configuration error:
There is a programmable error in your configuration file:
Traceback (most recent call last):
File "/usr/local/lib/python3.9/dist-packages/sphinx/config.py", line 319,
in eval_config_file
execfile_(filename, namespace)
File "/usr/local/lib/python3.9/dist-packages/sphinx/util/pycompat.py",
line 81, in execfile_
exec(code, _globals)
File "/__w/spark/spark/python/docs/source/conf.py", line 27, in
generate_supported_api()
File "/__w/spark/spark/python/pyspark/pandas/supported_api_gen.py", line
100, in generate_supported_api
raise ImportError(
ImportError: Pandas >= 1.4.0 must be installed; however, your version was
1.3.5.
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail:
[GitHub] [spark] beobest2 commented on a diff in pull request #36509: [SPARK-38961][PYTHON][DOCS] Enhance to automatically generate the the pandas API support list
beobest2 commented on code in PR #36509:
URL: https://github.com/apache/spark/pull/36509#discussion_r871643023
##
python/pyspark/pandas/supported_api_gen.py:
##
@@ -0,0 +1,363 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+"""
+Generate 'Supported pandas APIs' documentation file
+"""
+import os
+from enum import Enum, unique
+from inspect import getmembers, isclass, isfunction, signature
+from typing import Any, Callable, Dict, List, Set, TextIO, Tuple
+
+import pyspark.pandas as ps
+import pyspark.pandas.groupby as psg
+import pyspark.pandas.window as psw
+from pyspark.find_spark_home import _find_spark_home
+from pyspark.sql.pandas.utils import require_minimum_pandas_version
+
+import pandas as pd
+import pandas.core.groupby as pdg
+import pandas.core.window as pdw
+
+MAX_MISSING_PARAMS_SIZE = 5
+COMMON_PARAMETER_SET = {"kwargs", "args", "cls"}
+MODULE_GROUP_MATCH = [(pd, ps), (pdw, psw), (pdg, psg)]
+
+SPARK_HOME = _find_spark_home()
+TARGET_RST_FILE = os.path.join(
+SPARK_HOME,
"python/docs/source/user_guide/pandas_on_spark/supported_pandas_api.rst"
+)
+RST_HEADER = """
+=
+Supported pandas APIs
+=
+
+.. currentmodule:: pyspark.pandas
+
+The following table shows the pandas APIs that implemented or non-implemented
from pandas API on
+Spark.
+
+Some pandas APIs do not implement full parameters, so the third column shows
missing parameters for
+each API.
+
+'Y' in the second column means it's implemented including its whole parameter.
+'N' means it's not implemented yet.
+'P' means it's partially implemented with the missing of some parameters.
+
+If there is non-implemented pandas API or parameter you want, you can create
an `Apache Spark
+JIRA `__ to request or
to contribute by your
+own.
+
+The API list is updated based on the `latest pandas official API
+reference `__.
+
+All implemented APIs listed here are distributed except the ones that requires
the local
+computation by design. For example, `DataFrame.to_numpy()
`__ requires to collect the data to the driver side.
+
+"""
+
+
+@unique
+class Implemented(Enum):
+IMPLEMENTED = "Y"
+NOT_IMPLEMENTED = "N"
+PARTIALLY_IMPLEMENTED = "P"
+
+
+class SupportedStatus:
+"""
+SupportedStatus class that defines a supported status for a specific
pandas API
+"""
+
+def __init__(self, implemented: str, missing: str = ""):
+self.implemented = implemented
+self.missing = missing
+
+
+def generate_supported_api() -> None:
+"""
+Generate supported APIs status dictionary.
+
+Write supported APIs documentation.
+"""
+require_minimum_pandas_version()
Review Comment:
After adding this
[code](https://github.com/apache/spark/pull/36509/files#diff-514ad07071095eb4dd210dc4360962858cb3412bc867bac6ae1e06cbbff0cd96R99),
build doc from github action failed.
The pandas version of `dongjoon/apache-spark-github-action-image:20220207`
seems "1.3.5"
```
Configuration error:
There is a programmable error in your configuration file:
Traceback (most recent call last):
File "/usr/local/lib/python3.9/dist-packages/sphinx/config.py", line 319,
in eval_config_file
execfile_(filename, namespace)
File "/usr/local/lib/python3.9/dist-packages/sphinx/util/pycompat.py",
line 81, in execfile_
exec(code, _globals)
File "/__w/spark/spark/python/docs/source/conf.py", line 27, in
generate_supported_api()
File "/__w/spark/spark/python/pyspark/pandas/supported_api_gen.py", line
100, in generate_supported_api
raise ImportError(
ImportError: Pandas >= 1.4.0 must be installed; however, your version was
1.3.5.
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
[GitHub] [spark] gengliangwang commented on a diff in pull request #36445: [SPARK-39096][SQL] Support MERGE commands with DEFAULT values
gengliangwang commented on code in PR #36445:
URL: https://github.com/apache/spark/pull/36445#discussion_r871614908
##
sql/core/src/test/scala/org/apache/spark/sql/execution/command/PlanResolutionSuite.scala:
##
@@ -1510,6 +1510,151 @@ class PlanResolutionSuite extends AnalysisTest {
case other => fail("Expect MergeIntoTable, but got:\n" +
other.treeString)
}
+
+// DEFAULT columns (implicit):
+// All cases of the $target table lack any explicitly-defined DEFAULT
columns. Therefore any
+// DEFAULT column references in the below MERGE INTO command should
resolve to literal NULL.
+// This test case covers that behavior.
+val sql6 =
+ s"""
+ |MERGE INTO $target AS target
+ |USING $source AS source
+ |ON target.i = source.i
+ |WHEN MATCHED AND (target.s='delete') THEN DELETE
+ |WHEN MATCHED AND (target.s='update')
+ |THEN UPDATE SET target.s = DEFAULT, target.i = target.i
+ |WHEN NOT MATCHED AND (source.s='insert')
+ | THEN INSERT (target.i, target.s) values (DEFAULT, DEFAULT)
+ """.stripMargin
+parseAndResolve(sql6) match {
+ case m: MergeIntoTable =>
+val source = m.sourceTable
+val target = m.targetTable
+val ti = target.output.find(_.name ==
"i").get.asInstanceOf[AttributeReference]
+val si = source.output.find(_.name ==
"i").get.asInstanceOf[AttributeReference]
+m.mergeCondition match {
+ case EqualTo(l: AttributeReference, r: AttributeReference) =>
+assert(l.sameRef(ti) && r.sameRef(si))
+ case Literal(_, BooleanType) => // this is acceptable as a merge
condition
+ case other => fail("unexpected merge condition " + other)
+}
+assert(m.matchedActions.length == 2)
+val first = m.matchedActions(0)
+first match {
+ case DeleteAction(Some(EqualTo(_: AttributeReference,
StringLiteral("delete" =>
+ case other => fail("unexpected first matched action " + other)
+}
+val second = m.matchedActions(1)
+second match {
+ case UpdateAction(Some(EqualTo(_: AttributeReference,
StringLiteral("update"))),
+Seq(
+ Assignment(_: AttributeReference, AnsiCast(Literal(null, _),
StringType, _)),
+ Assignment(_: AttributeReference, _: AttributeReference))) =>
+ case other => fail("unexpected second matched action " + other)
+}
+assert(m.notMatchedActions.length == 1)
+val negative = m.notMatchedActions(0)
+negative match {
+ case InsertAction(Some(EqualTo(_: AttributeReference,
StringLiteral("insert"))),
+ Seq(Assignment(i: AttributeReference, AnsiCast(Literal(null, _),
IntegerType, _)),
+ Assignment(s: AttributeReference, AnsiCast(Literal(null, _),
StringType, _ =>
+assert(i.name == "i")
+assert(s.name == "s")
+ case other => fail("unexpected not matched action " + other)
+}
+
+ case other =>
+fail("Expect MergeIntoTable, but got:\n" + other.treeString)
+}
+
+// DEFAULT column reference in the merge condition:
+// This MERGE INTO command includes an ON clause with a DEFAULT column
reference. This is
+// invalid and returns an error message.
+val mergeWithDefaultReferenceInMergeCondition =
+s"""
Review Comment:
nit: indent
##
sql/core/src/test/scala/org/apache/spark/sql/execution/command/PlanResolutionSuite.scala:
##
@@ -1510,6 +1510,151 @@ class PlanResolutionSuite extends AnalysisTest {
case other => fail("Expect MergeIntoTable, but got:\n" +
other.treeString)
}
+
+// DEFAULT columns (implicit):
+// All cases of the $target table lack any explicitly-defined DEFAULT
columns. Therefore any
+// DEFAULT column references in the below MERGE INTO command should
resolve to literal NULL.
+// This test case covers that behavior.
+val sql6 =
+ s"""
+ |MERGE INTO $target AS target
+ |USING $source AS source
+ |ON target.i = source.i
+ |WHEN MATCHED AND (target.s='delete') THEN DELETE
+ |WHEN MATCHED AND (target.s='update')
+ |THEN UPDATE SET target.s = DEFAULT, target.i = target.i
+ |WHEN NOT MATCHED AND (source.s='insert')
+ | THEN INSERT (target.i, target.s) values (DEFAULT, DEFAULT)
+ """.stripMargin
+parseAndResolve(sql6) match {
+ case m: MergeIntoTable =>
+val source = m.sourceTable
+val target = m.targetTable
+val ti = target.output.find(_.name
[GitHub] [spark] gengliangwang commented on a diff in pull request #36445: [SPARK-39096][SQL] Support MERGE commands with DEFAULT values
gengliangwang commented on code in PR #36445: URL: https://github.com/apache/spark/pull/36445#discussion_r871610688 ## sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala: ## @@ -287,6 +287,7 @@ class Analyzer(override val catalogManager: CatalogManager) ResolveFieldNameAndPosition :: AddMetadataColumns :: DeduplicateRelations :: + ResolveDefaultColumns(this, v1SessionCatalog) :: Review Comment: Why change the order of the rule? The order within one Batch should not matter except that it can avoid extra loops. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srielau commented on pull request #36151: WIP: [SPARK-27998] [SQL] Add support for double-quoted named expressions
srielau commented on PR #36151: URL: https://github.com/apache/spark/pull/36151#issuecomment-1125216782 > > I think this this is worrysome for two reasons > > ``` > > 1. It adds confusion between what is a string and what is an identifier. > > > > 2. It singles out a specific kind of an identifier (column) and a specific narrow kind of context (column aliasing in the select list). > > ``` > > > > > > > > > > > > > > > > > > > > > > > > I'm totally for a switch that sets whether double quotes are used for identifiers or strings. but it should be: > > ``` > > 1. Pick one > > > > 2. Holistic > > ``` > > My original PR was to change the meaning of double quotes to be identifiers instead of strings but the [feedback](https://github.com/apache/spark/pull/35853#issuecomment-1093676903) was that it was too late to make a change this large. However, maybe we can introduce a configuration option to determine how this is handled, as suggested [here](https://github.com/apache/spark/pull/35853#issuecomment-1095156190). I think a config would be appropriate. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang closed pull request #36514: [SPARK-39078][SQL] Fix a bug in UPDATE commands with DEFAULT values
gengliangwang closed pull request #36514: [SPARK-39078][SQL] Fix a bug in UPDATE commands with DEFAULT values URL: https://github.com/apache/spark/pull/36514 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on pull request #36514: [SPARK-39078][SQL] Fix a bug in UPDATE commands with DEFAULT values
gengliangwang commented on PR #36514: URL: https://github.com/apache/spark/pull/36514#issuecomment-1125211927 Thanks, merging to master -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xinrong-databricks commented on pull request #36464: [SPARK-38947][PYTHON] Supports groupby positional indexing
xinrong-databricks commented on PR #36464: URL: https://github.com/apache/spark/pull/36464#issuecomment-1125199936 LGTM! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] mridulm commented on a diff in pull request #36512: [SPARK-39152][CORE] Deregistering disk persisted local RDD blocks in case of IO related errors
mridulm commented on code in PR #36512:
URL: https://github.com/apache/spark/pull/36512#discussion_r871575182
##
core/src/main/scala/org/apache/spark/storage/BlockManager.scala:
##
@@ -347,7 +347,7 @@ private[spark] class BlockManager(
case ex: KryoException if ex.getCause.isInstanceOf[IOException] =>
// We need to have detailed log message to catch environmental
problems easily.
// Further details: https://issues.apache.org/jira/browse/SPARK-37710
Review Comment:
nit: We can remove this comment from here, since it is in
`processIORelatedException`.
##
core/src/main/scala/org/apache/spark/storage/BlockManager.scala:
##
@@ -933,10 +933,29 @@ private[spark] class BlockManager(
})
Some(new BlockResult(ci, DataReadMethod.Memory, info.size))
} else if (level.useDisk && diskStore.contains(blockId)) {
- try {
-val diskData = diskStore.getBytes(blockId)
-val iterToReturn: Iterator[Any] = {
- if (level.deserialized) {
+ var retryCount = 0
+ val retryLimit = 3
Review Comment:
What kind of transient failures do you expect would recover on retry ? To
get a sense of why/how many retries help.
##
core/src/main/scala/org/apache/spark/storage/BlockManager.scala:
##
@@ -947,27 +966,42 @@ private[spark] class BlockManager(
.getOrElse { diskData.toInputStream() }
serializerManager.dataDeserializeStream(blockId,
stream)(info.classTag)
}
+} catch {
+ case e: KryoException if e.getCause.isInstanceOf[IOException] =>
+handleRetriableException(e)
+ case e: IOException =>
+handleRetriableException(e)
+ case t: Throwable =>
+if (diskData != null) {
+ diskData.dispose()
+}
+// not a retriable exception
Review Comment:
We were not doing it earlier, but release lock here ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36500: [SPARK-39164][SQL] Wrap asserts/illegal state exceptions by the INTERNAL_ERROR exception in actions
cloud-fan commented on code in PR #36500:
URL: https://github.com/apache/spark/pull/36500#discussion_r871526333
##
sql/core/src/main/scala/org/apache/spark/sql/execution/DataSourceScanExec.scala:
##
@@ -618,6 +618,7 @@ case class FileSourceScanExec(
}.groupBy { f =>
BucketingUtils
.getBucketId(new Path(f.filePath).getName)
+ // TODO(SPARK-39163): Throw an exception w/ error class for an
invalid bucket file
Review Comment:
makes sense!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a diff in pull request #36525: [SPARK-39166] Provide runtime error query context for binary arithmetic when WSCG is off
gengliangwang commented on code in PR #36525:
URL: https://github.com/apache/spark/pull/36525#discussion_r871525344
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/arithmetic.scala:
##
@@ -418,9 +428,11 @@ case class Multiply(
protected override def nullSafeEval(input1: Any, input2: Any): Any =
dataType match {
case _: IntegerType if failOnError =>
- MathUtils.multiplyExact(input1.asInstanceOf[Int],
input2.asInstanceOf[Int], origin.context)
+ MathUtils.multiplyExact(input1.asInstanceOf[Int],
input2.asInstanceOf[Int],
+queryContext)
Review Comment:
```suggestion
MathUtils.multiplyExact(input1.asInstanceOf[Int],
input2.asInstanceOf[Int], queryContext)
```
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/arithmetic.scala:
##
@@ -418,9 +428,11 @@ case class Multiply(
protected override def nullSafeEval(input1: Any, input2: Any): Any =
dataType match {
case _: IntegerType if failOnError =>
- MathUtils.multiplyExact(input1.asInstanceOf[Int],
input2.asInstanceOf[Int], origin.context)
+ MathUtils.multiplyExact(input1.asInstanceOf[Int],
input2.asInstanceOf[Int],
+queryContext)
case _: LongType if failOnError =>
- MathUtils.multiplyExact(input1.asInstanceOf[Long],
input2.asInstanceOf[Long], origin.context)
+ MathUtils.multiplyExact(input1.asInstanceOf[Long],
input2.asInstanceOf[Long],
+queryContext)
Review Comment:
```suggestion
MathUtils.multiplyExact(input1.asInstanceOf[Long],
input2.asInstanceOf[Long], queryContext)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a diff in pull request #36525: [SPARK-39166] Provide runtime error query context for binary arithmetic when WSCG is off
gengliangwang commented on code in PR #36525: URL: https://github.com/apache/spark/pull/36525#discussion_r871524691 ## sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/arithmetic.scala: ## @@ -381,9 +389,11 @@ case class Subtract( case _: YearMonthIntervalType => MathUtils.subtractExact(input1.asInstanceOf[Int], input2.asInstanceOf[Int]) case _: IntegerType if failOnError => - MathUtils.subtractExact(input1.asInstanceOf[Int], input2.asInstanceOf[Int], origin.context) + MathUtils.subtractExact(input1.asInstanceOf[Int], input2.asInstanceOf[Int], +queryContext) case _: LongType if failOnError => - MathUtils.subtractExact(input1.asInstanceOf[Long], input2.asInstanceOf[Long], origin.context) + MathUtils.subtractExact(input1.asInstanceOf[Long], input2.asInstanceOf[Long], +queryContext) Review Comment: ```suggestion MathUtils.subtractExact(input1.asInstanceOf[Long], input2.asInstanceOf[Long], queryContext) ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a diff in pull request #36525: [SPARK-39166] Provide runtime error query context for binary arithmetic when WSCG is off
gengliangwang commented on code in PR #36525: URL: https://github.com/apache/spark/pull/36525#discussion_r871524308 ## sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/arithmetic.scala: ## @@ -381,9 +389,11 @@ case class Subtract( case _: YearMonthIntervalType => MathUtils.subtractExact(input1.asInstanceOf[Int], input2.asInstanceOf[Int]) case _: IntegerType if failOnError => - MathUtils.subtractExact(input1.asInstanceOf[Int], input2.asInstanceOf[Int], origin.context) + MathUtils.subtractExact(input1.asInstanceOf[Int], input2.asInstanceOf[Int], +queryContext) Review Comment: ```suggestion MathUtils.subtractExact(input1.asInstanceOf[Int], input2.asInstanceOf[Int], queryContext) ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36525: [SPARK-39166] Provide runtime error query context for binary arithmetic when WSCG is off
cloud-fan commented on code in PR #36525: URL: https://github.com/apache/spark/pull/36525#discussion_r871522379 ## sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/arithmetic.scala: ## @@ -381,9 +389,11 @@ case class Subtract( case _: YearMonthIntervalType => MathUtils.subtractExact(input1.asInstanceOf[Int], input2.asInstanceOf[Int]) case _: IntegerType if failOnError => - MathUtils.subtractExact(input1.asInstanceOf[Int], input2.asInstanceOf[Int], origin.context) + MathUtils.subtractExact(input1.asInstanceOf[Int], input2.asInstanceOf[Int], +queryContext) Review Comment: style nit: do we need a new line here? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk closed pull request #36524: [SPARK-39165][SQL] Replace `sys.error` by `IllegalStateException`
MaxGekk closed pull request #36524: [SPARK-39165][SQL] Replace `sys.error` by `IllegalStateException` URL: https://github.com/apache/spark/pull/36524 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #36523: [SPARK-37956][DOCS] Add Python and Java examples of Parquet encryption in Spark SQL to documentation
AmplabJenkins commented on PR #36523: URL: https://github.com/apache/spark/pull/36523#issuecomment-1125115130 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on pull request #36524: [SPARK-39165][SQL] Replace `sys.error` by `IllegalStateException`
MaxGekk commented on PR #36524: URL: https://github.com/apache/spark/pull/36524#issuecomment-1125114545 Merging to master. Thank you, @srowen for review. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn commented on a diff in pull request #36373: [SPARK-39041][SQL] Mapping Spark Query ResultSet/Schema to TRowSet/TTableSchema directly
yaooqinn commented on code in PR #36373: URL: https://github.com/apache/spark/pull/36373#discussion_r871502997 ## sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/session/HiveSession.java: ## @@ -182,11 +184,11 @@ OperationHandle getCrossReference(String primaryCatalog, void closeOperation(OperationHandle opHandle) throws HiveSQLException; - TableSchema getResultSetMetadata(OperationHandle opHandle) + TTableSchema getResultSetMetadata(OperationHandle opHandle) throws HiveSQLException; - RowSet fetchResults(OperationHandle opHandle, FetchOrientation orientation, - long maxRows, FetchType fetchType) throws HiveSQLException; + TRowSet fetchResults(OperationHandle opHandle, FetchOrientation orientation, + long maxRows, FetchType fetchType) throws HiveSQLException; Review Comment: ```suggestion long maxRows, FetchType fetchType) throws HiveSQLException; ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn commented on a diff in pull request #36373: [SPARK-39041][SQL] Mapping Spark Query ResultSet/Schema to TRowSet/TTableSchema directly
yaooqinn commented on code in PR #36373:
URL: https://github.com/apache/spark/pull/36373#discussion_r871496811
##
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala:
##
@@ -373,17 +306,69 @@ private[hive] class SparkExecuteStatementOperation(
}
object SparkExecuteStatementOperation {
- def getTableSchema(structType: StructType): TableSchema = {
-val schema = structType.map { field =>
- val attrTypeString = field.dataType match {
-case CalendarIntervalType => StringType.catalogString
-case _: YearMonthIntervalType => "interval_year_month"
-case _: DayTimeIntervalType => "interval_day_time"
-case _: TimestampNTZType => "timestamp"
-case other => other.catalogString
- }
- new FieldSchema(field.name, attrTypeString,
field.getComment.getOrElse(""))
+
+ def toTTypeId(typ: DataType): TTypeId = typ match {
+case NullType => TTypeId.NULL_TYPE
+case BooleanType => TTypeId.BOOLEAN_TYPE
+case ByteType => TTypeId.TINYINT_TYPE
+case ShortType => TTypeId.SMALLINT_TYPE
+case IntegerType => TTypeId.INT_TYPE
+case LongType => TTypeId.BIGINT_TYPE
+case FloatType => TTypeId.FLOAT_TYPE
+case DoubleType => TTypeId.DOUBLE_TYPE
+case StringType => TTypeId.STRING_TYPE
+case _: DecimalType => TTypeId.DECIMAL_TYPE
+case DateType => TTypeId.DATE_TYPE
+// TODO: Shall use TIMESTAMPLOCALTZ_TYPE, keep AS-IS now for
+// unnecessary behavior change
+case TimestampType => TTypeId.TIMESTAMP_TYPE
+case TimestampNTZType => TTypeId.TIMESTAMP_TYPE
Review Comment:
this is for rowset schema. jdbc client side can call getString to get the
raw string or getObject to get an java object where it is used
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a diff in pull request #36525: [SPARK-39166] Provide runtime error query context for binary arithmetic when WSCG is off
gengliangwang commented on code in PR #36525:
URL: https://github.com/apache/spark/pull/36525#discussion_r871497091
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Expression.scala:
##
@@ -588,6 +588,28 @@ abstract class UnaryExpression extends Expression with
UnaryLike[Expression] {
}
}
+/**
+ * An expression with SQL query context. The context string can be serialized
from the Driver
+ * to executors. It will also be kept after rule transforms.
+ */
+trait SupportQueryContext extends Expression with Serializable {
+ protected var queryContext: String = initQueryContext()
+
+ def initQueryContext(): String
+
+ // Note: Even though query contexts are serialized to executors, it will be
regenerated from an
+ // empty "Origin" during rule transforms since "Origin"s are not
serialized to executors
+ // for better performance. Thus, we need to copy the original query
context during
+ // transforms. The query context string is considered as a "tag" on
the expression here.
+ override def copyTagsFrom(other: Expression): Unit = {
Review Comment:
@cloud-fan If you find this weird, we can consider changing the method name
as `copyTagsAndContextFrom`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang opened a new pull request, #36525: [SPARK-39166] Provide runtime error query context for binary arithmetic when WSCG is off
gengliangwang opened a new pull request, #36525:
URL: https://github.com/apache/spark/pull/36525
### What changes were proposed in this pull request?
Currently, for most of the cases, the project
https://issues.apache.org/jira/browse/SPARK-38615 is able to show where the
runtime errors happen within the original query.
However, after trying on production, I found that the following queries
won't show where the divide by 0 error happens
```
create table aggTest(i int, j int, k int, d date) using parquet
insert into aggTest values(1, 2, 0, date'2022-01-01')
select sum(j)/sum(k),percentile(i, 0.9) from aggTest group by d
```
With `percentile` function in the query, the plan can't execute with whole
stage codegen. Thus the child plan of `Project` is serialized to executors for
execution, from ProjectExec:
```
protected override def doExecute(): RDD[InternalRow] = {
child.execute().mapPartitionsWithIndexInternal { (index, iter) =>
val project = UnsafeProjection.create(projectList, child.output)
project.initialize(index)
iter.map(project)
}
}
```
Note that the `TreeNode.origin` is not serialized to executors since
`TreeNode` doesn't extend the trait `Serializable`, which results in an empty
query context on errors. For more details, please read
https://issues.apache.org/jira/browse/SPARK-39140
A dummy fix is to make `TreeNode` extend the trait `Serializable`. However,
it can be performance regression if the query text is long (every `TreeNode`
carries it for serialization).
A better fix is to introduce a new trait `SupportQueryContext` and
materialize the truncated query context for special expressions. This PR
targets on binary arithmetic expressions only. I will create follow-ups for the
remaining expressions which support runtime error query context.
### Why are the changes needed?
Improve the error context framework and make sure it works when whole stage
codegen is not available.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit tests
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36373: [SPARK-39041][SQL] Mapping Spark Query ResultSet/Schema to TRowSet/TTableSchema directly
cloud-fan commented on code in PR #36373:
URL: https://github.com/apache/spark/pull/36373#discussion_r871485266
##
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala:
##
@@ -373,17 +306,69 @@ private[hive] class SparkExecuteStatementOperation(
}
object SparkExecuteStatementOperation {
- def getTableSchema(structType: StructType): TableSchema = {
-val schema = structType.map { field =>
- val attrTypeString = field.dataType match {
-case CalendarIntervalType => StringType.catalogString
-case _: YearMonthIntervalType => "interval_year_month"
-case _: DayTimeIntervalType => "interval_day_time"
-case _: TimestampNTZType => "timestamp"
-case other => other.catalogString
- }
- new FieldSchema(field.name, attrTypeString,
field.getComment.getOrElse(""))
+
+ def toTTypeId(typ: DataType): TTypeId = typ match {
+case NullType => TTypeId.NULL_TYPE
+case BooleanType => TTypeId.BOOLEAN_TYPE
+case ByteType => TTypeId.TINYINT_TYPE
+case ShortType => TTypeId.SMALLINT_TYPE
+case IntegerType => TTypeId.INT_TYPE
+case LongType => TTypeId.BIGINT_TYPE
+case FloatType => TTypeId.FLOAT_TYPE
+case DoubleType => TTypeId.DOUBLE_TYPE
+case StringType => TTypeId.STRING_TYPE
+case _: DecimalType => TTypeId.DECIMAL_TYPE
+case DateType => TTypeId.DATE_TYPE
+// TODO: Shall use TIMESTAMPLOCALTZ_TYPE, keep AS-IS now for
+// unnecessary behavior change
+case TimestampType => TTypeId.TIMESTAMP_TYPE
+case TimestampNTZType => TTypeId.TIMESTAMP_TYPE
Review Comment:
Maybe I'm missing some context here. Looking at `RowSetUtils`, datetime
types are use String as result. Where do we use `TTypeId`?
##
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala:
##
@@ -373,17 +306,69 @@ private[hive] class SparkExecuteStatementOperation(
}
object SparkExecuteStatementOperation {
- def getTableSchema(structType: StructType): TableSchema = {
-val schema = structType.map { field =>
- val attrTypeString = field.dataType match {
-case CalendarIntervalType => StringType.catalogString
-case _: YearMonthIntervalType => "interval_year_month"
-case _: DayTimeIntervalType => "interval_day_time"
-case _: TimestampNTZType => "timestamp"
-case other => other.catalogString
- }
- new FieldSchema(field.name, attrTypeString,
field.getComment.getOrElse(""))
+
+ def toTTypeId(typ: DataType): TTypeId = typ match {
+case NullType => TTypeId.NULL_TYPE
+case BooleanType => TTypeId.BOOLEAN_TYPE
+case ByteType => TTypeId.TINYINT_TYPE
+case ShortType => TTypeId.SMALLINT_TYPE
+case IntegerType => TTypeId.INT_TYPE
+case LongType => TTypeId.BIGINT_TYPE
+case FloatType => TTypeId.FLOAT_TYPE
+case DoubleType => TTypeId.DOUBLE_TYPE
+case StringType => TTypeId.STRING_TYPE
+case _: DecimalType => TTypeId.DECIMAL_TYPE
+case DateType => TTypeId.DATE_TYPE
+// TODO: Shall use TIMESTAMPLOCALTZ_TYPE, keep AS-IS now for
+// unnecessary behavior change
+case TimestampType => TTypeId.TIMESTAMP_TYPE
+case TimestampNTZType => TTypeId.TIMESTAMP_TYPE
Review Comment:
Maybe I'm missing some context here. Looking at `RowSetUtils`, datetime
types are using String as result. Where do we use `TTypeId`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on pull request #36500: [SPARK-39164][SQL] Wrap asserts/illegal state exceptions by the INTERNAL_ERROR exception in actions
MaxGekk commented on PR #36500: URL: https://github.com/apache/spark/pull/36500#issuecomment-1125097534 > shall we handle internal errors in the query compilation phase? like parser, analyzer, optimizer, planner. Yep, I plan to wrap asserts/illegal state exceptions by internal errors at all user-facing APIs including the Thrift server, explain() and so on. For instance, Spark providers could extend the `INTERNAL_ERROR` error class, and ask their customers to contact to their support if they faced to any internal errors. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36373: [SPARK-39041][SQL] Mapping Spark Query ResultSet/Schema to TRowSet/TTableSchema directly
cloud-fan commented on code in PR #36373: URL: https://github.com/apache/spark/pull/36373#discussion_r871477878 ## sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/session/HiveSession.java: ## @@ -182,11 +184,11 @@ OperationHandle getCrossReference(String primaryCatalog, void closeOperation(OperationHandle opHandle) throws HiveSQLException; - TableSchema getResultSetMetadata(OperationHandle opHandle) + TTableSchema getResultSetMetadata(OperationHandle opHandle) throws HiveSQLException; - RowSet fetchResults(OperationHandle opHandle, FetchOrientation orientation, - long maxRows, FetchType fetchType) throws HiveSQLException; + TRowSet fetchResults(OperationHandle opHandle, FetchOrientation orientation, + long maxRows, FetchType fetchType) throws HiveSQLException; Review Comment: the previous indentation was correct. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on pull request #36524: [SPARK-39165][SQL] Replace `sys.error` by `IllegalStateException`
MaxGekk commented on PR #36524: URL: https://github.com/apache/spark/pull/36524#issuecomment-1125083351 @cloud-fan @srielau FYI -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a diff in pull request #36500: [SPARK-39164][SQL] Wrap asserts/illegal state exceptions by the INTERNAL_ERROR exception in actions
MaxGekk commented on code in PR #36500:
URL: https://github.com/apache/spark/pull/36500#discussion_r871467515
##
sql/core/src/main/scala/org/apache/spark/sql/execution/DataSourceScanExec.scala:
##
@@ -618,6 +618,7 @@ case class FileSourceScanExec(
}.groupBy { f =>
BucketingUtils
.getBucketId(new Path(f.filePath).getName)
+ // TODO(SPARK-39163): Throw an exception w/ error class for an
invalid bucket file
Review Comment:
It captures the exception, actually. That's why I have to change the related
tests. But I do believe we should throw another exception here because this
case is not an illegal state. The bucket can be removed from the file system by
someone else, and Spark shouldn't consider this as its illegal state and show
an internal error to users.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a diff in pull request #36500: [SPARK-39164][SQL] Wrap asserts/illegal state exceptions by the INTERNAL_ERROR exception in actions
MaxGekk commented on code in PR #36500:
URL: https://github.com/apache/spark/pull/36500#discussion_r871467515
##
sql/core/src/main/scala/org/apache/spark/sql/execution/DataSourceScanExec.scala:
##
@@ -618,6 +618,7 @@ case class FileSourceScanExec(
}.groupBy { f =>
BucketingUtils
.getBucketId(new Path(f.filePath).getName)
+ // TODO(SPARK-39163): Throw an exception w/ error class for an
invalid bucket file
Review Comment:
They capture the exception, actually. That's why I have to change the
related tests. But I do believe we should throw another exception here because
this case is not an illegal state. The bucket can be removed from the file
system by someone else, and Spark shouldn't consider this as its illegal state
and show an internal error to users.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a diff in pull request #36500: [SPARK-39164][SQL] Wrap asserts/illegal state exceptions by the INTERNAL_ERROR exception in actions
MaxGekk commented on code in PR #36500:
URL: https://github.com/apache/spark/pull/36500#discussion_r871467515
##
sql/core/src/main/scala/org/apache/spark/sql/execution/DataSourceScanExec.scala:
##
@@ -618,6 +618,7 @@ case class FileSourceScanExec(
}.groupBy { f =>
BucketingUtils
.getBucketId(new Path(f.filePath).getName)
+ // TODO(SPARK-39163): Throw an exception w/ error class for an
invalid bucket file
Review Comment:
They capture the exception, actually. That's why I have to change the
related tests. But I do believe we should throw another exception here because
this case is not an illegal state. The bucket can be removed from the file
system by someone else, and Spark shouldn't consider this as an illegal state
and show an internal error to users.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a diff in pull request #36500: [SPARK-39164][SQL] Wrap asserts/illegal state exceptions by the INTERNAL_ERROR exception in actions
MaxGekk commented on code in PR #36500:
URL: https://github.com/apache/spark/pull/36500#discussion_r871467515
##
sql/core/src/main/scala/org/apache/spark/sql/execution/DataSourceScanExec.scala:
##
@@ -618,6 +618,7 @@ case class FileSourceScanExec(
}.groupBy { f =>
BucketingUtils
.getBucketId(new Path(f.filePath).getName)
+ // TODO(SPARK-39163): Throw an exception w/ error class for an
invalid bucket file
Review Comment:
They capture the exception, actually. That's why I have to change related
tests. But I do believe we should throw another exception here because this
case is not an illegal state. The bucket can be removed from the file system by
someone else, and Spark shouldn't consider this as an illegal state and show an
internal error to users.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36519: [SPARK-39159][SQL] Add new Dataset API for Offset
cloud-fan commented on code in PR #36519:
URL: https://github.com/apache/spark/pull/36519#discussion_r871440865
##
sql/core/src/test/scala/org/apache/spark/sql/DataFrameSuite.scala:
##
@@ -605,6 +605,20 @@ class DataFrameSuite extends QueryTest
)
}
+ test("offset") {
+checkAnswer(
+ testData.offset(90),
+ testData.collect().drop(90).toSeq)
+
+checkAnswer(
+ arrayData.toDF().offset(99),
+ arrayData.collect().drop(99).map(r =>
Row.fromSeq(r.productIterator.toSeq)))
+
+checkAnswer(
+ mapData.toDF().offset(99),
+ mapData.collect().drop(99).map(r =>
Row.fromSeq(r.productIterator.toSeq)))
Review Comment:
can we test a few combinations? like limit followed by offset, and offset
followed by limit.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #36500: [SPARK-39164][SQL] Wrap asserts/illegal state exceptions by the INTERNAL_ERROR exception in actions
cloud-fan commented on code in PR #36500:
URL: https://github.com/apache/spark/pull/36500#discussion_r871426136
##
sql/core/src/main/scala/org/apache/spark/sql/execution/DataSourceScanExec.scala:
##
@@ -618,6 +618,7 @@ case class FileSourceScanExec(
}.groupBy { f =>
BucketingUtils
.getBucketId(new Path(f.filePath).getName)
+ // TODO(SPARK-39163): Throw an exception w/ error class for an
invalid bucket file
Review Comment:
The change in `Dataset` can't capture this error?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #36500: [SPARK-39164][SQL] Wrap asserts/illegal state exceptions by the INTERNAL_ERROR exception in actions
cloud-fan commented on PR #36500: URL: https://github.com/apache/spark/pull/36500#issuecomment-1125039012 shall we handle internal errors in the query compilation phase? like parser, analyzer, optimizer, planner. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk opened a new pull request, #36524: [WIP][SPARK-39165][SQL] Replace `sys.error` by `IllegalStateException`
MaxGekk opened a new pull request, #36524: URL: https://github.com/apache/spark/pull/36524 ### What changes were proposed in this pull request? Replace all invokes of `sys.error()` by throwing of `IllegalStateException` in the `sql` namespace. ### Why are the changes needed? In the context of wrapping all internal errors like asserts/illegal state exceptions (see https://github.com/apache/spark/pull/36500), it is impossible to distinguish `RuntimeException` of `sys.error()` from Spark's exceptions like `SparkRuntimeException`. The last one can be propagated to the user space but `sys.error` exceptions shouldn't be visible to users in regular cases. ### Does this PR introduce _any_ user-facing change? No, shouldn't. sys.error shouldn't propagate exception to user space in regular cases. ### How was this patch tested? By running the existing test suites. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] runitao commented on pull request #36151: WIP: [SPARK-27998] [SQL] Add support for double-quoted named expressions
runitao commented on PR #36151: URL: https://github.com/apache/spark/pull/36151#issuecomment-1124883543 please retest -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #36523: [SPARK-37956][DOCS] Add Python and Java examples of Parquet encryption in Spark SQL to documentation
HyukjinKwon commented on code in PR #36523:
URL: https://github.com/apache/spark/pull/36523#discussion_r871229825
##
docs/sql-data-sources-parquet.md:
##
@@ -288,6 +290,64 @@ val df2 =
spark.read.parquet("/path/to/table.parquet.encrypted")
+
+{% highlight java %}
+
+sc.hadoopConfiguration().set("parquet.encryption.kms.client.class" ,
+ "org.apache.parquet.crypto.keytools.mocks.InMemoryKMS");
+
+// Explicit master keys (base64 encoded) - required only for mock InMemoryKMS
+sc.hadoopConfiguration().set("parquet.encryption.key.list" ,
+ "keyA:AAECAwQFBgcICQoLDA0ODw== , keyB:AAECAAECAAECAAECAAECAA==");
+
+// Activate Parquet encryption, driven by Hadoop properties
+sc.hadoopConfiguration().set("parquet.crypto.factory.class" ,
+ "org.apache.parquet.crypto.keytools.PropertiesDrivenCryptoFactory");
+
+// Write encrypted dataframe files.
+// Column "square" will be protected with master key "keyA".
+// Parquet file footers will be protected with master key "keyB"
+squaresDF.write().
+ option("parquet.encryption.column.keys" , "keyA:square").
+ option("parquet.encryption.footer.key" , "keyB").
+ parquet("/path/to/table.parquet.encrypted");
+
+// Read encrypted dataframe files
+Dataset df2 = spark.read().parquet("/path/to/table.parquet.encrypted");
+
+{% endhighlight %}
+
+
+
+
+{% highlight python %}
+
+sc._jsc.hadoopConfiguration().set("parquet.encryption.kms.client.class" ,
Review Comment:
Just dropping a comment: we shouldn't use `_jsc`. This isn't an API.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #36518: [SPARK-39160][SQL] Remove workaround for ARROW-1948
HyukjinKwon commented on PR #36518: URL: https://github.com/apache/spark/pull/36518#issuecomment-1124834672 cc @BryanCutler -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] andersonm-ibm opened a new pull request, #36523: [SPARK-37956][DOCS] Add Python and Java examples of Parquet encryption in Spark SQL to documentation
andersonm-ibm opened a new pull request, #36523: URL: https://github.com/apache/spark/pull/36523 ### What changes were proposed in this pull request? Add Java and Python examples based on the Scala example for the use of Parquet encryption in Spark. ### Why are the changes needed? To provide information on how to use Parquet column encryption in Spark SQL in additional languages: in Python and Java, based on the Scala example. ### Does this PR introduce _any_ user-facing change? Yes, it adds Parquet encryption usage examples in Python and Java to the documentation, which currently provides only a scala example. ### How was this patch tested? SKIP_API=1 bundle exec jekyll build Python tab: 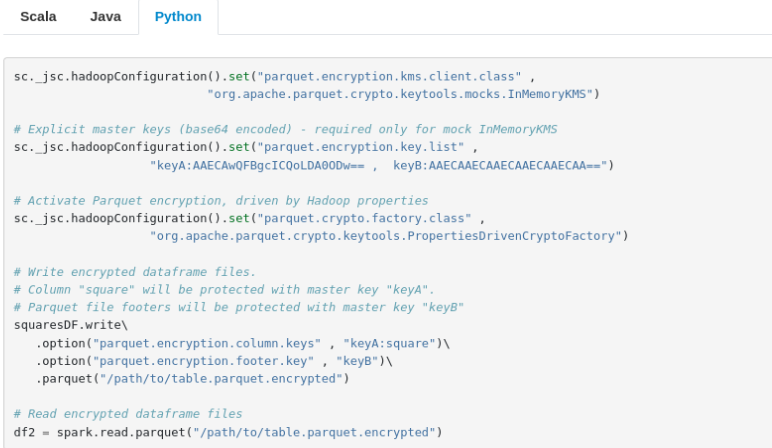 Java tab: 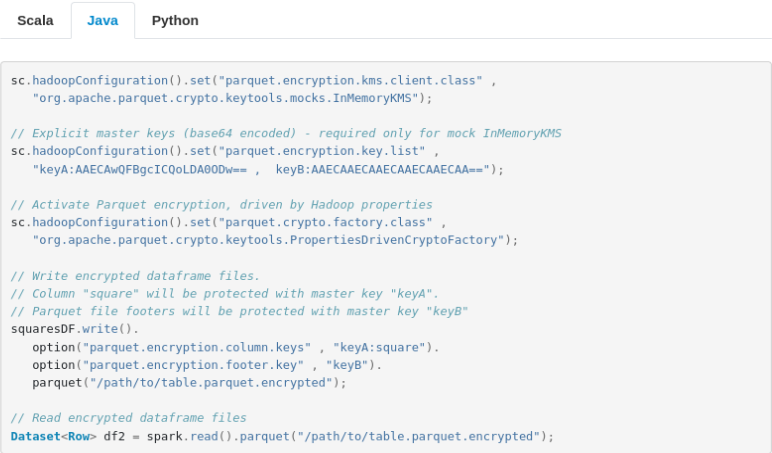 CC @ggershinsky -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on pull request #36500: [SPARK-39164][SQL] Wrap asserts/illegal state exceptions by the INTERNAL_ERROR exception in actions
MaxGekk commented on PR #36500: URL: https://github.com/apache/spark/pull/36500#issuecomment-1124832137 @srielau @panbingkun @lvshaokang Please, take a look at the PR. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] pan3793 commented on pull request #36518: [SPARK-39160][SQL] Remove workaround for ARROW-1948
pan3793 commented on PR #36518: URL: https://github.com/apache/spark/pull/36518#issuecomment-1124802352 cc @HyukjinKwon @sunchao -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang opened a new pull request, #36522: [SPARK-39161][BUILD] Upgrade rocksdbjni to 7.2.2
LuciferYang opened a new pull request, #36522: URL: https://github.com/apache/spark/pull/36522 ### What changes were proposed in this pull request? This PR aims to upgrade RocksDB JNI library from 7.1.2 to 7.2.2. ### Why are the changes needed? This will bring improvements and bug fix of RocksDB JNI. - https://github.com/facebook/rocksdb/releases/tag/v7.2.2 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass GA The benchmark result : **Before 7.1.2** ``` [INFO] Running org.apache.spark.util.kvstore.RocksDBBenchmark count meanmin max 95th dbClose 4 0.285 0.199 0.492 0.492 dbCreation 4 76.967 3.187 300.938 300.938 naturalIndexCreateIterator 10240.006 0.002 1.391 0.007 naturalIndexDescendingCreateIterator 10240.005 0.005 0.063 0.007 naturalIndexDescendingIteration 10240.006 0.004 0.247 0.008 naturalIndexIteration10240.006 0.004 0.053 0.009 randomDeleteIndexed 10240.027 0.019 0.277 0.037 randomDeletesNoIndex 10240.015 0.013 0.031 0.017 randomUpdatesIndexed 10240.081 0.033 30.561 0.085 randomUpdatesNoIndex 10240.036 0.033 0.465 0.039 randomWritesIndexed 10240.118 0.035 52.557 0.123 randomWritesNoIndex 10240.042 0.036 1.439 0.048 refIndexCreateIterator 10240.004 0.004 0.017 0.006 refIndexDescendingCreateIterator 10240.003 0.003 0.028 0.004 refIndexDescendingIteration 10240.006 0.005 0.045 0.008 refIndexIteration10240.007 0.005 0.073 0.009 sequentialDeleteIndexed 10240.021 0.018 0.108 0.025 sequentialDeleteNoIndex 10240.015 0.012 0.039 0.017 sequentialUpdatesIndexed 10240.045 0.039 0.732 0.056 sequentialUpdatesNoIndex 10240.042 0.031 0.812 0.054 sequentialWritesIndexed 10240.050 0.044 1.881 0.057 sequentialWritesNoIndex 10240.039 0.032 2.160 0.042 ``` **After 7.2.2** ``` [INFO] Running org.apache.spark.util.kvstore.RocksDBBenchmark count meanmin max 95th dbClose 4 0.397 0.280 0.719 0.719 dbCreation 4 77.931 3.410 300.959 300.959 naturalIndexCreateIterator 10240.006 0.002 1.433 0.007 naturalIndexDescendingCreateIterator 10240.005 0.005 0.064 0.007 naturalIndexDescendingIteration 10240.006 0.004 0.253 0.009 naturalIndexIteration10240.006 0.004 0.069 0.010 randomDeleteIndexed 10240.027 0.019 0.243 0.037 randomDeletesNoIndex 10240.015 0.013 0.042 0.017 randomUpdatesIndexed 10240.082 0.033 30.571 0.087 randomUpdatesNoIndex 10240.034 0.031 0.625 0.037 randomWritesIndexed 10240.118 0.034 52.687 0.128 randomWritesNoIndex 10240.040 0.034 1.923 0.045 refIndexCreateIterator 10240.004 0.004 0.018 0.006 refIndexDescendingCreateIterator 10240.003 0.002 0.033 0.004 refIndexDescendingIteration 10240.007 0.005 0.047 0.010 refIndexIteration10240.007 0.005 0.077 0.010 sequentialDeleteIndexed 10240.021 0.017 0.103 0.025 sequentialDeleteNoIndex 10240.015 0.012 0.067 0.017 sequentialUpdatesIndexed 10240.042 0.037 0.817 0.052 sequentialUpdatesNoIndex 10240.040 0.030 1.067 0.049 sequentialWritesIndexed 10240.048 0.039 2.049 0.055 sequentialWritesNoIndex 10240.039 0.032 2.421 0.041 ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For