[GitHub] [spark] HyukjinKwon commented on a diff in pull request #38158: [DOCS] Fixed a small typo in cluster-overview.md doc
HyukjinKwon commented on code in PR #38158: URL: https://github.com/apache/spark/pull/38158#discussion_r990598920 ## docs/cluster-overview.md: ## @@ -104,7 +104,7 @@ The following table summarizes terms you'll see used to refer to cluster concept Application jar A jar containing the user's Spark application. In some cases users will want to create -an "uber jar" containing their application along with its dependencies. The user's jar +an "user jar" containing their application along with its dependencies. The user's jar Review Comment: I think uber jar is correct? which means contains dependencies (fat jar) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Santhoshkumard11 opened a new pull request, #38158: ixed a small typo in cluster-overview doc
Santhoshkumard11 opened a new pull request, #38158: URL: https://github.com/apache/spark/pull/38158 ### What changes were proposed in this pull request? ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #38061: [SPARK-40448][CONNECT][FOLLOWUP] Use more suitable variable name and fix code style.
beliefer commented on PR #38061: URL: https://github.com/apache/spark/pull/38061#issuecomment-1272226935 ping @grundprinzip -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #38150: [SPARK-40699][DOCS] Supplement undocumented yarn configurations in documentation
AmplabJenkins commented on PR #38150: URL: https://github.com/apache/spark/pull/38150#issuecomment-1272219195 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on pull request #38157: [SPARK-40534][CONNECT] Extend the support for Join with different join types
amaliujia commented on PR #38157: URL: https://github.com/apache/spark/pull/38157#issuecomment-1272214857 R: @cloud-fan -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia opened a new pull request, #38157: [SPARK-40534][CONNECT] Extend the support for Join with different join types
amaliujia opened a new pull request, #38157: URL: https://github.com/apache/spark/pull/38157 ### What changes were proposed in this pull request? 1. Extend the support for Join with different join types. Before this PR, all joins are hardcoded `inner` type. So this PR supports other join types. 2. Add join to connect DSL. 3. Update a few Join proto fields to better reflect the semantic. ### Why are the changes needed? Extend the support for Join in connect. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? UT -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dcoliversun opened a new pull request, #38156: [SPARK-40709][DOCS] Supplement undocumented avro configurations in documentation
dcoliversun opened a new pull request, #38156: URL: https://github.com/apache/spark/pull/38156 ### What changes were proposed in this pull request? This PR aims to supplement undocumented avro configurations in documentation. ### Why are the changes needed? Help users to confirm configuration through documentation instead of code. ### Does this PR introduce _any_ user-facing change? Yes, more configurations in documentation ### How was this patch tested? Pass the GA -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38046: [SPARK-40611][SQL] Improve the performance of `setInterval` & `getInterval` for `UnsafeRow`
beliefer commented on code in PR #38046:
URL: https://github.com/apache/spark/pull/38046#discussion_r990576459
##
sql/catalyst/src/test/scala/org/apache/spark/sql/CalendarIntervalBenchmark.scala:
##
@@ -0,0 +1,84 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql
+
+import org.apache.spark.benchmark.{Benchmark, BenchmarkBase}
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.encoders.RowEncoder
+import org.apache.spark.sql.catalyst.expressions.UnsafeProjection
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateSafeProjection
+import org.apache.spark.sql.types.{CalendarIntervalType, DataType, StructType}
+import org.apache.spark.unsafe.types.CalendarInterval
+
+/**
+ * Benchmark for read/write CalendarInterval with two int vs
+ * read/write CalendarInterval with one long.
+ * To run this benchmark:
+ * {{{
+ * 1. without sbt:
+ * bin/spark-submit --class --jars
+ * 2. build/sbt "catalyst/Test/runMain "
+ * 3. generate result:
+ * SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "catalyst/Test/runMain
"
+ * Results will be written to
"benchmarks/CalendarIntervalBenchmark-results.txt".
+ * }}}
+ */
+object CalendarIntervalBenchmark extends BenchmarkBase {
+
+ def test(name: String, schema: StructType, numRows: Int, iters: Int): Unit =
{
+assert(schema.length == 1)
+assert(schema.head.dataType.isInstanceOf[CalendarIntervalType])
+runBenchmark(name) {
+ val generator = RandomDataGenerator.forType(schema, nullable = false).get
+ val toRow = RowEncoder(schema).createSerializer()
+ val attrs = schema.toAttributes
+ val safeProjection = GenerateSafeProjection.generate(attrs, attrs)
Review Comment:
OK
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #38153: [SPARK-39876][FOLLOW-UP][SQL] Add parser and Dataset tests for SQL UNPIVOT
AmplabJenkins commented on PR #38153: URL: https://github.com/apache/spark/pull/38153#issuecomment-1272199368 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #38154: [SPARK-40705] Handle case of using mutable array when converting Row to JSON for Scala 2.13
AmplabJenkins commented on PR #38154: URL: https://github.com/apache/spark/pull/38154#issuecomment-1272199335 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #38155: [SPARK-40707][CONNECT] Add groupby to connect DSL and test more than one grouping expressions
AmplabJenkins commented on PR #38155: URL: https://github.com/apache/spark/pull/38155#issuecomment-1272199312 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #38061: [SPARK-40448][CONNECT][FOLLOWUP] Use more suitable message name.
beliefer commented on PR #38061: URL: https://github.com/apache/spark/pull/38061#issuecomment-1272192076 > Before that is achieved, the idea could be that we limit changes on the proto to only core API coverage to unblock other pieces (DataFrame API support in clients etc.) Thank you. I will revert the changes on the proto. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen closed pull request #38129: [MINOR][DOCS] Reviews and updates the doc links for running-on-yarn
srowen closed pull request #38129: [MINOR][DOCS] Reviews and updates the doc links for running-on-yarn URL: https://github.com/apache/spark/pull/38129 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on pull request #38129: [MINOR][DOCS] Reviews and updates the doc links for running-on-yarn
srowen commented on PR #38129: URL: https://github.com/apache/spark/pull/38129#issuecomment-1272192003 Merged to master -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #37825: [WIP][SPARK-40382][SQL] Group distinct aggregate expressions by semantically equivalent children in `RewriteDistinctAggregates`
beliefer commented on code in PR #37825:
URL: https://github.com/apache/spark/pull/37825#discussion_r990569446
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/RewriteDistinctAggregates.scala:
##
@@ -254,7 +254,9 @@ object RewriteDistinctAggregates extends Rule[LogicalPlan] {
// Setup unique distinct aggregate children.
val distinctAggChildren = distinctAggGroups.keySet.flatten.toSeq.distinct
- val distinctAggChildAttrMap =
distinctAggChildren.map(expressionAttributePair)
+ val distinctAggChildAttrMap = distinctAggChildren.map { e =>
+e.canonicalized -> AttributeReference(e.sql, e.dataType, nullable =
true)()
Review Comment:
It seems we can update `expressionAttributePair`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ulysses-you commented on pull request #37641: [SPARK-40201][SQL][TESTS] Improve v1 write test coverage
ulysses-you commented on PR #37641: URL: https://github.com/apache/spark/pull/37641#issuecomment-1272190902 @allisonwang-db thank you for review. There are two cases that the ordering does not match: - the added sort will be removed in Optimizer, e.g. the plan has one row or the dynamic partition column is foldable - the added sort ordering expression has an alias which will be replaced by `AliasAwareOutputExpression`, then the ordering does not match I have a pr for case 1 about foldable see https://github.com/apache/spark/pull/37831, but need to simplify a bit more. I think pr https://github.com/apache/spark/pull/37525 can save the case 2, although I do not looked it deeply. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #37993: [SPARK-40557][CONNECT] Update generated proto files for Spark Connect
beliefer commented on code in PR #37993: URL: https://github.com/apache/spark/pull/37993#discussion_r990568669 ## python/pyspark/sql/connect/proto/base_pb2.py: ## @@ -28,26 +28,20 @@ _sym_db = _symbol_database.Default() -from pyspark.sql.connect.proto import ( -commands_pb2 as spark_dot_connect_dot_commands__pb2, -) -from pyspark.sql.connect.proto import ( -relations_pb2 as spark_dot_connect_dot_relations__pb2, -) +from pyspark.sql.connect.proto import commands_pb2 as spark_dot_connect_dot_commands__pb2 Review Comment: > I think this is the script that was checked in: https://github.com/apache/spark/blob/master/connector/connect/dev/generate_protos.sh Thank you. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] github-actions[bot] commented on pull request #37015: [SPARK-39628][CORE] Fix a race condition when handling of IdleStateEvent again
github-actions[bot] commented on PR #37015: URL: https://github.com/apache/spark/pull/37015#issuecomment-1272175950 We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. If you'd like to revive this PR, please reopen it and ask a committer to remove the Stale tag! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SandishKumarHN commented on a diff in pull request #37972: [SPARK-40654][SQL] Protobuf support for Spark - from_protobuf AND to_protobuf
SandishKumarHN commented on code in PR #37972:
URL: https://github.com/apache/spark/pull/37972#discussion_r990555942
##
connector/protobuf/pom.xml:
##
@@ -0,0 +1,115 @@
+
+
+
+http://maven.apache.org/POM/4.0.0";
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance";
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd";>
+ 4.0.0
+
+org.apache.spark
+spark-parent_2.12
+3.4.0-SNAPSHOT
+../../pom.xml
+
+
+ spark-protobuf_2.12
+
+protobuf
+3.21.1
+
+ jar
+ Spark Protobuf
+ https://spark.apache.org/
+
+
+
+ org.apache.spark
+ spark-sql_${scala.binary.version}
+ ${project.version}
+ provided
+
+
+ org.apache.spark
+ spark-core_${scala.binary.version}
+ ${project.version}
+ test-jar
+ test
+
+
+ org.apache.spark
+ spark-catalyst_${scala.binary.version}
+ ${project.version}
+ test-jar
+ test
+
+
+ org.apache.spark
+ spark-sql_${scala.binary.version}
+ ${project.version}
+ test-jar
+ test
+
+
+ org.scalacheck
+ scalacheck_${scala.binary.version}
+ test
+
+
+ org.apache.spark
+ spark-tags_${scala.binary.version}
+
+
+
+ com.google.protobuf
+ protobuf-java
+ ${protobuf.version}
+ compile
+
Review Comment:
@rangadi after packaging if spark apps imports "spark-protobuf" jar, it
won't find a "spark-protobuf" specific version of "com.google.protobuf:*",
instead it will have relocated one "org.sparkproject.spark-protobuf.protobuf:*"
and no one will be using the "spark-protobuf" protobuf version other than the
"spark-protobuf" module. shading is just making an uber jar with the relocated
classes. The shaded classes will be available for import only after the shaded
jar has been added as a dependency in pom.xml, correct?
found this online
```
If the uber JAR is reused as a dependency of some other project, directly
including classes
from the artifact's dependencies in the uber JAR can cause class loading
conflicts due to duplicate
classes on the class path. To address this issue, one can relocate the
classes which get included
in the shaded artifact in order to create a private copy of their bytecode
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SandishKumarHN commented on a diff in pull request #37972: [SPARK-40654][SQL] Protobuf support for Spark - from_protobuf AND to_protobuf
SandishKumarHN commented on code in PR #37972:
URL: https://github.com/apache/spark/pull/37972#discussion_r990555942
##
connector/protobuf/pom.xml:
##
@@ -0,0 +1,115 @@
+
+
+
+http://maven.apache.org/POM/4.0.0";
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance";
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd";>
+ 4.0.0
+
+org.apache.spark
+spark-parent_2.12
+3.4.0-SNAPSHOT
+../../pom.xml
+
+
+ spark-protobuf_2.12
+
+protobuf
+3.21.1
+
+ jar
+ Spark Protobuf
+ https://spark.apache.org/
+
+
+
+ org.apache.spark
+ spark-sql_${scala.binary.version}
+ ${project.version}
+ provided
+
+
+ org.apache.spark
+ spark-core_${scala.binary.version}
+ ${project.version}
+ test-jar
+ test
+
+
+ org.apache.spark
+ spark-catalyst_${scala.binary.version}
+ ${project.version}
+ test-jar
+ test
+
+
+ org.apache.spark
+ spark-sql_${scala.binary.version}
+ ${project.version}
+ test-jar
+ test
+
+
+ org.scalacheck
+ scalacheck_${scala.binary.version}
+ test
+
+
+ org.apache.spark
+ spark-tags_${scala.binary.version}
+
+
+
+ com.google.protobuf
+ protobuf-java
+ ${protobuf.version}
+ compile
+
Review Comment:
@rangadi after packaging if spark apps imports "spark-protobuf" jar, it
won't find a "spark-protobuf" specific version of "com.google.protobuf:*",
instead it will have relocated one "org.sparkproject.spark-protobuf.protobuf:*"
and no one will be using the "spark-protobuf" protobuf version other than the
"spark-protobuf" module. shading is just making an uber jar with the relocated
classes. The shaded classes will be available for import only after the shaded
jar has been added as a dependency in pom.xml, correct?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on pull request #38155: [SPARK-40707] Add groupby to connect DSL and test more than one grouping expressions
amaliujia commented on PR #38155: URL: https://github.com/apache/spark/pull/38155#issuecomment-1272167709 R: @cloud-fan -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia opened a new pull request, #38155: [SPARK-40707] Add groupby to connect DSL and test more than one grouping expressions
amaliujia opened a new pull request, #38155: URL: https://github.com/apache/spark/pull/38155 ### What changes were proposed in this pull request? 1. Add `groupby` to connect DSL and test more than one grouping expressions 2. Pass limited data types through connect proto for LocalRelation's attributes. ### Why are the changes needed? Enhance connect's support for GROUP BY. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? UT -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] rangadi commented on a diff in pull request #37972: [SPARK-40654][SQL] Protobuf support for Spark - from_protobuf AND to_protobuf
rangadi commented on code in PR #37972:
URL: https://github.com/apache/spark/pull/37972#discussion_r990551174
##
connector/protobuf/pom.xml:
##
@@ -0,0 +1,115 @@
+
+
+
+http://maven.apache.org/POM/4.0.0";
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance";
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd";>
+ 4.0.0
+
+org.apache.spark
+spark-parent_2.12
+3.4.0-SNAPSHOT
+../../pom.xml
+
+
+ spark-protobuf_2.12
+
+protobuf
+3.21.1
+
+ jar
+ Spark Protobuf
+ https://spark.apache.org/
+
+
+
+ org.apache.spark
+ spark-sql_${scala.binary.version}
+ ${project.version}
+ provided
+
+
+ org.apache.spark
+ spark-core_${scala.binary.version}
+ ${project.version}
+ test-jar
+ test
+
+
+ org.apache.spark
+ spark-catalyst_${scala.binary.version}
+ ${project.version}
+ test-jar
+ test
+
+
+ org.apache.spark
+ spark-sql_${scala.binary.version}
+ ${project.version}
+ test-jar
+ test
+
+
+ org.scalacheck
+ scalacheck_${scala.binary.version}
+ test
+
+
+ org.apache.spark
+ spark-tags_${scala.binary.version}
+
+
+
+ com.google.protobuf
+ protobuf-java
+ ${protobuf.version}
+ compile
+
Review Comment:
hmm.. wonder how it works without importing the shaded library. When we
shade, it is like a new package. If we don't import it, then we are using the
default one.
Yeah, `MapEntry` does not exist in v2 library I guess.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #36304: [SPARK-38959][SQL] DS V2: Support runtime group filtering in row-level commands
dongjoon-hyun commented on code in PR #36304:
URL: https://github.com/apache/spark/pull/36304#discussion_r990544792
##
sql/core/src/test/scala/org/apache/spark/sql/connector/DeleteFromTableSuite.scala:
##
@@ -626,4 +633,142 @@ abstract class DeleteFromTableSuiteBase
}
}
-class GroupBasedDeleteFromTableSuite extends DeleteFromTableSuiteBase
+class GroupBasedDeleteFromTableSuite extends DeleteFromTableSuiteBase {
Review Comment:
Yes~
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Amraneze opened a new pull request, #38154: [SPARK-40705] Handle case of using mutable array when converting Row to JSON for Scala 2.13
Amraneze opened a new pull request, #38154: URL: https://github.com/apache/spark/pull/38154 ### What changes were proposed in this pull request? I encountered an issue using Spark while reading JSON files based on a schema it throws every time an exception related to conversion of types. >Note: This issue can be reproduced only with Scala `2.13`, I'm not having this issue with `2.12` Failed to convert value ArraySeq(1, 2, 3) (class of class scala.collection.mutable.ArraySeq$ofRef}) with the type of ArrayType(StringType,true) to JSON. java.lang.IllegalArgumentException: Failed to convert value ArraySeq(1, 2, 3) (class of class scala.collection.mutable.ArraySeq$ofRef}) with the type of ArrayType(StringType,true) to JSON. If I add ArraySeq to the matching cases, the test that I added passed successfully 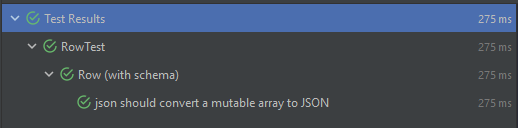 With the current code source, the test fails and we have this following error  ### Why are the changes needed? If the person is using Scala 2.13, they can't parse an array. Which means they need to fallback to 2.12 to keep the project functioning ### How was this patch tested? I added a sample unit test for the case, but I can add more if you want to. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a diff in pull request #38147: [SPARK-40585][SQL] Double-quoted identifiers should be available only in ANSI mode
gengliangwang commented on code in PR #38147: URL: https://github.com/apache/spark/pull/38147#discussion_r990522343 ## sql/core/src/test/resources/sql-tests/results/double-quoted-identifiers.sql.out: ## @@ -277,74 +277,110 @@ SELECT 1 FROM "not_exist" -- !query schema struct<> -- !query output -org.apache.spark.sql.AnalysisException -Table or view not found: not_exist; line 1 pos 14 +org.apache.spark.sql.catalyst.parser.ParseException Review Comment: Again, the test set is small. I don't see the downside of testing all the combinations. Let's consider about reducing the tests when it becomes bigger, which is quite unlikely. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on a diff in pull request #38147: [SPARK-40585][SQL] Double-quoted identifiers should be available only in ANSI mode
amaliujia commented on code in PR #38147: URL: https://github.com/apache/spark/pull/38147#discussion_r990493388 ## sql/core/src/test/resources/sql-tests/results/double-quoted-identifiers.sql.out: ## @@ -277,74 +277,110 @@ SELECT 1 FROM "not_exist" -- !query schema struct<> -- !query output -org.apache.spark.sql.AnalysisException -Table or view not found: not_exist; line 1 pos 14 +org.apache.spark.sql.catalyst.parser.ParseException Review Comment: I am seeing there is an extra testing here: so this test file itself contains both `double_quoted_identifiers=false` and `double_quoted_identifiers=true` and now we run it into both ANSI and non-ANSI. So I think what the unique testing coverage is: 1. non-ANSI and `double_quoted_identifiers=false`, so double quoted is still a string. 2. non-ANSI and `double_quoted_identifiers=true`, so we see parser exception. 3. ANSI and `double_quoted_identifiers=true`, this feature is on and being tested. But for ANSI and `double_quoted_identifiers=false` which seems to be the same as number 2 above? ## sql/core/src/test/resources/sql-tests/results/double-quoted-identifiers.sql.out: ## @@ -277,74 +277,110 @@ SELECT 1 FROM "not_exist" -- !query schema struct<> -- !query output -org.apache.spark.sql.AnalysisException -Table or view not found: not_exist; line 1 pos 14 +org.apache.spark.sql.catalyst.parser.ParseException Review Comment: I am seeing there might be an extra testing here: so this test file itself contains both `double_quoted_identifiers=false` and `double_quoted_identifiers=true` and now we run it into both ANSI and non-ANSI. So I think what the unique testing coverage is: 1. non-ANSI and `double_quoted_identifiers=false`, so double quoted is still a string. 2. non-ANSI and `double_quoted_identifiers=true`, so we see parser exception. 3. ANSI and `double_quoted_identifiers=true`, this feature is on and being tested. But for ANSI and `double_quoted_identifiers=false` which seems to be the same as number 2 above? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xiaonanyang-db commented on pull request #38113: [SPARK-40667][SQL] Refactor File Data Source Options
xiaonanyang-db commented on PR #38113: URL: https://github.com/apache/spark/pull/38113#issuecomment-1272057226 @brkyvz @sadikovi @cloud-fan comments addressed, please take another look. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] allisonwang-db commented on a diff in pull request #38050: [SPARK-40615][SQL] Check unsupported data types when decorrelating subqueries
allisonwang-db commented on code in PR #38050:
URL: https://github.com/apache/spark/pull/38050#discussion_r990447400
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/DecorrelateInnerQuery.scala:
##
@@ -369,7 +370,7 @@ object DecorrelateInnerQuery extends PredicateHelper {
throw
QueryCompilationErrors.unsupportedCorrelatedReferenceDataTypeError(
o, a.dataType, plan.origin)
} else {
- throw new IllegalStateException(s"Unable to decorrelate
subquery: " +
+ throw SparkException.internalError(s"Unable to decorrelate
subquery: " +
Review Comment:
See https://github.com/apache/spark/pull/38050#discussion_r990171074
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] vinodkc commented on pull request #38146: [SPARK-40687][SQL] Support data masking built-in Function 'mask'
vinodkc commented on PR #38146: URL: https://github.com/apache/spark/pull/38146#issuecomment-1272016984 @HyukjinKwon , this PR is a generic approach to mask the string based on the arguments. This mask function can be applied to any string value and it does not expect a pattern on the input string. Apache Hive **mask** function has the same logic. Eg: Arguments: * input - string value to mask. Supported types: STRING, VARCHAR, CHAR * upperChar - character to replace upper-case characters with. Specify -1 to retain the original character. Default value: 'X' * lowerChar - character to replace lower-case characters with. Specify -1 to retain the original character. Default value: 'x' * digitChar - character to replace digit characters with. Specify -1 to retain the original character. Default value: 'n' * otherChar - character to replace all other characters with. Specify -1 to retain the original character. Default value: -1 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on a diff in pull request #38050: [SPARK-40615][SQL] Check unsupported data types when decorrelating subqueries
amaliujia commented on code in PR #38050:
URL: https://github.com/apache/spark/pull/38050#discussion_r990420325
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/DecorrelateInnerQuery.scala:
##
@@ -369,7 +370,7 @@ object DecorrelateInnerQuery extends PredicateHelper {
throw
QueryCompilationErrors.unsupportedCorrelatedReferenceDataTypeError(
o, a.dataType, plan.origin)
} else {
- throw new IllegalStateException(s"Unable to decorrelate
subquery: " +
+ throw SparkException.internalError(s"Unable to decorrelate
subquery: " +
Review Comment:
oh I saw Wenchen's comment above.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on pull request #38050: [SPARK-40615][SQL] Check unsupported data types when decorrelating subqueries
amaliujia commented on PR #38050: URL: https://github.com/apache/spark/pull/38050#issuecomment-1271995077 LGTM -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] aokolnychyi commented on a diff in pull request #36304: [SPARK-38959][SQL] DS V2: Support runtime group filtering in row-level commands
aokolnychyi commented on code in PR #36304:
URL: https://github.com/apache/spark/pull/36304#discussion_r990419267
##
sql/core/src/test/scala/org/apache/spark/sql/connector/DeleteFromTableSuite.scala:
##
@@ -626,4 +633,142 @@ abstract class DeleteFromTableSuiteBase
}
}
-class GroupBasedDeleteFromTableSuite extends DeleteFromTableSuiteBase
+class GroupBasedDeleteFromTableSuite extends DeleteFromTableSuiteBase {
Review Comment:
@dongjoon-hyun, do you mean move this class into its own file? I can surely
do that.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on a diff in pull request #38050: [SPARK-40615][SQL] Check unsupported data types when decorrelating subqueries
amaliujia commented on code in PR #38050: URL: https://github.com/apache/spark/pull/38050#discussion_r990410429 ## core/src/main/resources/error/error-classes.json: ## @@ -3138,4 +3138,4 @@ " must override either or " ] } -} +} Review Comment: Nit: revert this. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srielau commented on a diff in pull request #37887: [SPARK-40360] ALREADY_EXISTS and NOT_FOUND exceptions
srielau commented on code in PR #37887:
URL: https://github.com/apache/spark/pull/37887#discussion_r990410856
##
sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryCompilationErrors.scala:
##
@@ -784,21 +784,17 @@ private[sql] object QueryCompilationErrors extends
QueryErrorsBase {
}
def renameTempViewToExistingViewError(oldName: String, newName: String):
Throwable = {
-new AnalysisException(
- errorClass = "_LEGACY_ERROR_TEMP_1062",
Review Comment:
Done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on a diff in pull request #38050: [SPARK-40615][SQL] Check unsupported data types when decorrelating subqueries
amaliujia commented on code in PR #38050:
URL: https://github.com/apache/spark/pull/38050#discussion_r990410758
##
core/src/main/resources/error/error-classes.json:
##
@@ -879,6 +879,11 @@
"Expressions referencing the outer query are not supported outside
of WHERE/HAVING clauses"
]
},
+ "UNSUPPORTED_CORRELATED_REFERENCE_DATA_TYPE" : {
+"message" : [
+ "Correlated column reference '' cannot be type"
Review Comment:
+1 this is better!
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/DecorrelateInnerQuery.scala:
##
@@ -369,7 +370,7 @@ object DecorrelateInnerQuery extends PredicateHelper {
throw
QueryCompilationErrors.unsupportedCorrelatedReferenceDataTypeError(
o, a.dataType, plan.origin)
} else {
- throw new IllegalStateException(s"Unable to decorrelate
subquery: " +
+ throw SparkException.internalError(s"Unable to decorrelate
subquery: " +
Review Comment:
Why this change?
##
core/src/main/resources/error/error-classes.json:
##
@@ -3138,4 +3138,4 @@
" must override either or "
]
}
-}
+}
Review Comment:
Bit revert this.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srielau commented on a diff in pull request #37887: [SPARK-40360] ALREADY_EXISTS and NOT_FOUND exceptions
srielau commented on code in PR #37887:
URL: https://github.com/apache/spark/pull/37887#discussion_r990410098
##
core/src/main/resources/error/error-classes.json:
##
@@ -536,12 +563,71 @@
"Failed to set original permission back to the created
path: . Exception: "
]
},
+ "ROUTINE_ALREADY_EXISTS" : {
+"message" : [
+ "Cannot create the function because it already exists.",
+ "Choose a different name, drop or replace the existing function, or add
the IF NOT EXISTS clause to tolerate a pre-existing function."
+],
+"sqlState" : "42000"
+ },
+ "ROUTINE_NOT_FOUND" : {
+"message" : [
+ "The function cannot be found. Verify the spelling and
correctness of the schema and catalog.",
+ "If you did not qualify the name with a schema and catalog, verify the
current_schema() output, or qualify the name with the correct schema and
catalog.",
+ "To tolerate the error on drop use DROP FUNCTION IF EXISTS."
+],
+"sqlState" : "42000"
+ },
+ "SCHEMA_ALREADY_EXISTS" : {
Review Comment:
I have added these error classes. need to figure out how to drive them
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] EnricoMi commented on pull request #38153: [SPARK-39876][FOLLOW-UP][SQL] Add parser and Dataset tests for SQL UNPIVOT
EnricoMi commented on PR #38153: URL: https://github.com/apache/spark/pull/38153#issuecomment-1271927034 @cloud-fan here is `UnpivotParserSuite` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] EnricoMi opened a new pull request, #38153: [SPARK-39876][FOLLOW-UP][SQL] Add parser and Dataset tests for SQL UNPIVOT
EnricoMi opened a new pull request, #38153: URL: https://github.com/apache/spark/pull/38153 ### What changes were proposed in this pull request? Adds more tests for the SQL `UNPIVOT` clause. https://github.com/apache/spark/pull/37407#discussion_r988768918 ### Why are the changes needed? Better test coverage. ### Does this PR introduce _any_ user-facing change? No, only more tests and fixing one issue. SQL `UNPIVOT` has not been released yet. ### How was this patch tested? In `UnpivotParserSuite` and `DatasetUnpivotSuite`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srielau commented on a diff in pull request #37887: [SPARK-40360] ALREADY_EXISTS and NOT_FOUND exceptions
srielau commented on code in PR #37887:
URL: https://github.com/apache/spark/pull/37887#discussion_r990390889
##
sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryCompilationErrors.scala:
##
@@ -2319,20 +2307,19 @@ private[sql] object QueryCompilationErrors extends
QueryErrorsBase {
"dataType" -> dataType.toString))
}
- def tableAlreadyExistsError(table: String, guide: String = ""): Throwable = {
-new AnalysisException(
- errorClass = "_LEGACY_ERROR_TEMP_1240",
- messageParameters = Map(
-"table" -> table,
-"guide" -> guide))
+ def tableAlreadyExistsError(table: String): Throwable = {
+new TableAlreadyExistsException(table)
}
def createTableAsSelectWithNonEmptyDirectoryError(tablePath: String):
Throwable = {
new AnalysisException(
- errorClass = "_LEGACY_ERROR_TEMP_1241",
- messageParameters = Map(
-"tablePath" -> tablePath,
-"config" -> SQLConf.ALLOW_NON_EMPTY_LOCATION_IN_CTAS.key))
+ s"CREATE-TABLE-AS-SELECT cannot create table with location to a
non-empty directory " +
+s"${tablePath} . To allow overwriting the existing non-empty
directory, " +
+s"set '${SQLConf.ALLOW_NON_EMPTY_LOCATION_IN_CTAS.key}' to true.")
Review Comment:
```suggestion
errorClass = "_LEGACY_ERROR_TEMP_1241",
messageParameters = Map(
"tablePath" -> tablePath,
"config" -> SQLConf.ALLOW_NON_EMPTY_LOCATION_IN_CTAS.key))
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srielau commented on a diff in pull request #37887: [SPARK-40360] ALREADY_EXISTS and NOT_FOUND exceptions
srielau commented on code in PR #37887:
URL: https://github.com/apache/spark/pull/37887#discussion_r990390889
##
sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryCompilationErrors.scala:
##
@@ -2319,20 +2307,19 @@ private[sql] object QueryCompilationErrors extends
QueryErrorsBase {
"dataType" -> dataType.toString))
}
- def tableAlreadyExistsError(table: String, guide: String = ""): Throwable = {
-new AnalysisException(
- errorClass = "_LEGACY_ERROR_TEMP_1240",
- messageParameters = Map(
-"table" -> table,
-"guide" -> guide))
+ def tableAlreadyExistsError(table: String): Throwable = {
+new TableAlreadyExistsException(table)
}
def createTableAsSelectWithNonEmptyDirectoryError(tablePath: String):
Throwable = {
new AnalysisException(
- errorClass = "_LEGACY_ERROR_TEMP_1241",
- messageParameters = Map(
-"tablePath" -> tablePath,
-"config" -> SQLConf.ALLOW_NON_EMPTY_LOCATION_IN_CTAS.key))
+ s"CREATE-TABLE-AS-SELECT cannot create table with location to a
non-empty directory " +
+s"${tablePath} . To allow overwriting the existing non-empty
directory, " +
+s"set '${SQLConf.ALLOW_NON_EMPTY_LOCATION_IN_CTAS.key}' to true.")
Review Comment:
```suggestion
errorClass = "_LEGACY_ERROR_TEMP_1241",
messageParameters = Map(
"tablePath" -> tablePath,
"config" -> SQLConf.ALLOW_NON_EMPTY_LOCATION_IN_CTAS.key))
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #38084: [SPARK-40640][CORE] SparkHadoopUtil to set origin of hadoop/hive config options
dongjoon-hyun commented on code in PR #38084:
URL: https://github.com/apache/spark/pull/38084#discussion_r990388866
##
sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala:
##
@@ -1299,7 +1299,8 @@ private[hive] object HiveClientImpl extends Logging {
// 3: we set all entries in config to this hiveConf.
val confMap = (hadoopConf.iterator().asScala.map(kv => kv.getKey ->
kv.getValue) ++
sparkConf.getAll.toMap ++ extraConfig).toMap
-confMap.foreach { case (k, v) => hiveConf.set(k, v) }
+val fromSpark = "Set by Spark"
Review Comment:
Since this is non-test code string, we should have in the same place with
the others.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #38084: [SPARK-40640][CORE] SparkHadoopUtil to set origin of hadoop/hive config options
dongjoon-hyun commented on code in PR #38084:
URL: https://github.com/apache/spark/pull/38084#discussion_r990388488
##
sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala:
##
@@ -1299,7 +1299,8 @@ private[hive] object HiveClientImpl extends Logging {
// 3: we set all entries in config to this hiveConf.
val confMap = (hadoopConf.iterator().asScala.map(kv => kv.getKey ->
kv.getValue) ++
sparkConf.getAll.toMap ++ extraConfig).toMap
-confMap.foreach { case (k, v) => hiveConf.set(k, v) }
+val fromSpark = "Set by Spark"
Review Comment:
Gentle ping about this leftover.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #38084: [SPARK-40640][CORE] SparkHadoopUtil to set origin of hadoop/hive config options
dongjoon-hyun commented on code in PR #38084:
URL: https://github.com/apache/spark/pull/38084#discussion_r990387422
##
core/src/test/scala/org/apache/spark/deploy/SparkHadoopUtilSuite.scala:
##
@@ -80,17 +87,100 @@ class SparkHadoopUtilSuite extends SparkFunSuite {
assertConfigValue(hadoopConf, "fs.s3a.endpoint", null)
}
+ /**
+ * spark.hive.* is passed to the hadoop config as hive.*.
+ */
+ test("spark.hive propagation") {
+val sc = new SparkConf()
+val hadoopConf = new Configuration(false)
+sc.set("spark.hive.hiveoption", "value")
+new SparkHadoopUtil().appendS3AndSparkHadoopHiveConfigurations(sc,
hadoopConf)
+assertConfigMatches(hadoopConf, "hive.hiveoption", "value",
+ SOURCE_SPARK_HIVE)
+ }
+
+ /**
+ * The explicit buffer size propagation records this.
+ */
+ test("SPARK-40640: buffer size propagation") {
+val sc = new SparkConf()
+val hadoopConf = new Configuration(false)
+sc.set(BUFFER_SIZE.key, "123")
+new SparkHadoopUtil().appendS3AndSparkHadoopHiveConfigurations(sc,
hadoopConf)
+assertConfigMatches(hadoopConf, "io.file.buffer.size", "123",
BUFFER_SIZE.key)
+ }
+
+ test("SPARK-40640: aws credentials from environment variables") {
+val env = new java.util.HashMap[String, String]
+env.put(ENV_VAR_AWS_ACCESS_KEY, "access-key")
+env.put(ENV_VAR_AWS_SECRET_KEY, "secret-key")
+env.put(ENV_VAR_AWS_SESSION_TOKEN, "session-token")
+val hadoopConf = new Configuration(false)
+SparkHadoopUtil.appendS3CredentialsFromEnvironment(hadoopConf, env)
+val source = "Set by Spark on " + InetAddress.getLocalHost + " from "
+assertConfigMatches(hadoopConf, "fs.s3a.access.key", "access-key", source)
+assertConfigMatches(hadoopConf, "fs.s3a.secret.key", "secret-key", source)
+assertConfigMatches(hadoopConf, "fs.s3a.session.token", "session-token",
source)
+ }
+
+ test("SPARK-19739: S3 session token propagation requires access and secret
keys") {
Review Comment:
I understand what you mean, but you should not add irrelevant test cover in
this PR. You don't use `assertConfigMatches` or `assertConfigSourceContains`
here. So, it looks like completely independent test case. Please proceed this
as a separate test case PR.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #38084: [SPARK-40640][CORE] SparkHadoopUtil to set origin of hadoop/hive config options
dongjoon-hyun commented on code in PR #38084:
URL: https://github.com/apache/spark/pull/38084#discussion_r990385167
##
core/src/test/scala/org/apache/spark/deploy/SparkHadoopUtilSuite.scala:
##
@@ -80,17 +87,100 @@ class SparkHadoopUtilSuite extends SparkFunSuite {
assertConfigValue(hadoopConf, "fs.s3a.endpoint", null)
}
+ /**
+ * spark.hive.* is passed to the hadoop config as hive.*.
+ */
+ test("spark.hive propagation") {
Review Comment:
Please add a test case prefix, `SPARK-40640: `.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #38084: [SPARK-40640][CORE] SparkHadoopUtil to set origin of hadoop/hive config options
dongjoon-hyun commented on code in PR #38084:
URL: https://github.com/apache/spark/pull/38084#discussion_r990384704
##
core/src/test/scala/org/apache/spark/deploy/SparkHadoopUtilSuite.scala:
##
@@ -32,9 +36,12 @@ class SparkHadoopUtilSuite extends SparkFunSuite {
val hadoopConf = new Configuration(false)
sc.set("spark.hadoop.orc.filterPushdown", "true")
new SparkHadoopUtil().appendSparkHadoopConfigs(sc, hadoopConf)
-assertConfigValue(hadoopConf, "orc.filterPushdown", "true" )
-assertConfigValue(hadoopConf, "fs.s3a.downgrade.syncable.exceptions",
"true")
-assertConfigValue(hadoopConf, "fs.s3a.endpoint", "s3.amazonaws.com")
+assertConfigMatches(hadoopConf, "orc.filterPushdown", "true",
+ SOURCE_SPARK_HADOOP)
Review Comment:
Do we need to split the line? Otherwise, please make it as a single line.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #38084: [SPARK-40640][CORE] SparkHadoopUtil to set origin of hadoop/hive config options
dongjoon-hyun commented on code in PR #38084:
URL: https://github.com/apache/spark/pull/38084#discussion_r990383278
##
core/src/main/scala/org/apache/spark/deploy/SparkHadoopUtil.scala:
##
@@ -474,40 +553,79 @@ private[spark] object SparkHadoopUtil extends Logging {
private def appendHiveConfigs(hadoopConf: Configuration): Unit = {
hiveConfKeys.foreach { kv =>
- hadoopConf.set(kv.getKey, kv.getValue)
+ hadoopConf.set(kv.getKey, kv.getValue, SOURCE_HIVE_SITE)
}
}
private def appendSparkHadoopConfigs(conf: SparkConf, hadoopConf:
Configuration): Unit = {
// Copy any "spark.hadoop.foo=bar" spark properties into conf as "foo=bar"
for ((key, value) <- conf.getAll if key.startsWith("spark.hadoop.")) {
- hadoopConf.set(key.substring("spark.hadoop.".length), value)
+ hadoopConf.set(key.substring("spark.hadoop.".length), value,
+SOURCE_SPARK_HADOOP)
}
+val setBySpark = SET_TO_DEFAULT_VALUES
if
(conf.getOption("spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version").isEmpty)
{
- hadoopConf.set("mapreduce.fileoutputcommitter.algorithm.version", "1")
+ hadoopConf.set("mapreduce.fileoutputcommitter.algorithm.version", "1",
setBySpark)
}
-// Since Hadoop 3.3.1, HADOOP-17597 starts to throw exceptions by default
+// In Hadoop 3.3.1, HADOOP-17597 starts to throw exceptions by default
+// this has been reverted in 3.3.2 (HADOOP-17928); setting it to
+// true here is harmless
if
(conf.getOption("spark.hadoop.fs.s3a.downgrade.syncable.exceptions").isEmpty) {
- hadoopConf.set("fs.s3a.downgrade.syncable.exceptions", "true")
+ hadoopConf.set("fs.s3a.downgrade.syncable.exceptions", "true",
setBySpark)
}
// In Hadoop 3.3.1, AWS region handling with the default "" endpoint only
works
// in EC2 deployments or when the AWS CLI is installed.
// The workaround is to set the name of the S3 endpoint explicitly,
// if not already set. See HADOOP-17771.
-// This change is harmless on older versions and compatible with
-// later Hadoop releases
if (hadoopConf.get("fs.s3a.endpoint", "").isEmpty &&
hadoopConf.get("fs.s3a.endpoint.region") == null) {
// set to US central endpoint which can also connect to buckets
// in other regions at the expense of a HEAD request during fs creation
- hadoopConf.set("fs.s3a.endpoint", "s3.amazonaws.com")
+ hadoopConf.set("fs.s3a.endpoint", "s3.amazonaws.com", setBySpark)
}
}
private def appendSparkHiveConfigs(conf: SparkConf, hadoopConf:
Configuration): Unit = {
// Copy any "spark.hive.foo=bar" spark properties into conf as
"hive.foo=bar"
for ((key, value) <- conf.getAll if key.startsWith("spark.hive.")) {
- hadoopConf.set(key.substring("spark.".length), value)
+ hadoopConf.set(key.substring("spark.".length), value,
+SOURCE_SPARK_HIVE)
+}
+ }
+
+ /**
+ * Return a hostname without throwing an exception if the system
+ * does not know its own name.
Review Comment:
I'm wondering when does this happen? Apache Spark has the following codes.
```
core/src/main/scala/org/apache/spark/util/Utils.scala: val address =
InetAddress.getLocalHost
core/src/main/scala/org/apache/spark/util/Utils.scala:
logWarning("Your hostname, " + InetAddress.getLocalHost.getHostName + "
resolves to" +
core/src/main/scala/org/apache/spark/util/Utils.scala:
logWarning("Your hostname, " + InetAddress.getLocalHost.getHostName + "
resolves to" +
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #38084: [SPARK-40640][CORE] SparkHadoopUtil to set origin of hadoop/hive config options
dongjoon-hyun commented on code in PR #38084:
URL: https://github.com/apache/spark/pull/38084#discussion_r990379772
##
core/src/main/scala/org/apache/spark/deploy/SparkHadoopUtil.scala:
##
@@ -437,27 +490,53 @@ private[spark] object SparkHadoopUtil extends Logging {
// Note: this null check is around more than just access to the "conf"
object to maintain
// the behavior of the old implementation of this code, for backwards
compatibility.
if (conf != null) {
- // Explicitly check for S3 environment variables
- val keyId = System.getenv("AWS_ACCESS_KEY_ID")
- val accessKey = System.getenv("AWS_SECRET_ACCESS_KEY")
- if (keyId != null && accessKey != null) {
-hadoopConf.set("fs.s3.awsAccessKeyId", keyId)
-hadoopConf.set("fs.s3n.awsAccessKeyId", keyId)
-hadoopConf.set("fs.s3a.access.key", keyId)
-hadoopConf.set("fs.s3.awsSecretAccessKey", accessKey)
-hadoopConf.set("fs.s3n.awsSecretAccessKey", accessKey)
-hadoopConf.set("fs.s3a.secret.key", accessKey)
-
-val sessionToken = System.getenv("AWS_SESSION_TOKEN")
-if (sessionToken != null) {
- hadoopConf.set("fs.s3a.session.token", sessionToken)
-}
- }
+ appendS3CredentialsFromEnvironment(hadoopConf, System.getenv)
Review Comment:
If you really want to hand over a map as a dependency injection, can you
build a small one by reusing the existing logic only like
`System.getenv("AWS_ACCESS_KEY_ID")`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #38084: [SPARK-40640][CORE] SparkHadoopUtil to set origin of hadoop/hive config options
dongjoon-hyun commented on code in PR #38084:
URL: https://github.com/apache/spark/pull/38084#discussion_r990377021
##
core/src/main/scala/org/apache/spark/deploy/SparkHadoopUtil.scala:
##
@@ -437,27 +490,53 @@ private[spark] object SparkHadoopUtil extends Logging {
// Note: this null check is around more than just access to the "conf"
object to maintain
// the behavior of the old implementation of this code, for backwards
compatibility.
if (conf != null) {
- // Explicitly check for S3 environment variables
- val keyId = System.getenv("AWS_ACCESS_KEY_ID")
- val accessKey = System.getenv("AWS_SECRET_ACCESS_KEY")
- if (keyId != null && accessKey != null) {
-hadoopConf.set("fs.s3.awsAccessKeyId", keyId)
-hadoopConf.set("fs.s3n.awsAccessKeyId", keyId)
-hadoopConf.set("fs.s3a.access.key", keyId)
-hadoopConf.set("fs.s3.awsSecretAccessKey", accessKey)
-hadoopConf.set("fs.s3n.awsSecretAccessKey", accessKey)
-hadoopConf.set("fs.s3a.secret.key", accessKey)
-
-val sessionToken = System.getenv("AWS_SESSION_TOKEN")
-if (sessionToken != null) {
- hadoopConf.set("fs.s3a.session.token", sessionToken)
-}
- }
+ appendS3CredentialsFromEnvironment(hadoopConf, System.getenv)
Review Comment:
I'm still worrying about the chance of the regression of getting and passing
a large map of strings here. There were some reports like this.
- https://github.com/apache/spark/pull/31244/files
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xiaonanyang-db commented on a diff in pull request #38113: [SPARK-40667][SQL] Refactor File Data Source Options
xiaonanyang-db commented on code in PR #38113:
URL: https://github.com/apache/spark/pull/38113#discussion_r990374003
##
connector/avro/src/test/scala/org/apache/spark/sql/avro/AvroSuite.scala:
##
@@ -2272,6 +2272,10 @@ abstract class AvroSuite
checkAnswer(df2, df.collect().toSeq)
}
}
+
+ test("SPARK-40667: Check the number of valid Avro options") {
+assert(AvroOptions.getAllValidOptionNames.size == 9)
Review Comment:
Originally we want use this simple test to remind developers of what should
be done when introducing a new option, but I just realized it will not serve
that purpose but just piss off developers. Let me remove them.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xiaonanyang-db commented on a diff in pull request #38113: [SPARK-40667][SQL] Refactor File Data Source Options
xiaonanyang-db commented on code in PR #38113:
URL: https://github.com/apache/spark/pull/38113#discussion_r990367969
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala:
##
@@ -327,3 +329,45 @@ class CSVOptions(
settings
}
}
+
+object CSVOptions extends DataSourceOptions {
+ val HEADER = newOption("header")
+ val INFER_SCHEMA = newOption("inferSchema")
+ val IGNORE_LEADING_WHITESPACE = newOption("ignoreLeadingWhiteSpace")
+ val IGNORE_TRAILING_WHITESPACE = newOption("ignoreTrailingWhiteSpace")
+ val PREFERS_DATE = newOption("prefersDate")
+ val ESCAPE_QUOTES = newOption("escapeQuotes")
+ val QUOTE_ALL = newOption("quoteAll")
+ val ENFORCE_SCHEMA = newOption("enforceSchema")
+ val QUOTE = newOption("quote")
+ val ESCAPE = newOption("escape")
+ val COMMENT = newOption("comment")
+ val MAX_COLUMNS = newOption("maxColumns")
+ val MAX_CHARS_PER_COLUMN = newOption("maxCharsPerColumn")
+ val MODE = newOption("mode")
+ val CHAR_TO_ESCAPE_QUOTE_ESCAPING = newOption("charToEscapeQuoteEscaping")
+ val LOCALE = newOption("locale")
+ val DATE_FORMAT = newOption("dateFormat")
+ val TIMESTAMP_FORMAT = newOption("timestampFormat")
+ val TIMESTAMP_NTZ_FORMAT = newOption("timestampNTZFormat")
+ val ENABLE_DATETIME_PARSING_FALLBACK =
newOption("enableDateTimeParsingFallback")
+ val MULTI_LINE = newOption("multiLine")
+ val SAMPLING_RATIO = newOption("samplingRatio")
+ val EMPTY_VALUE = newOption("emptynewOption")
+ val LINE_SEP = newOption("lineSep")
+ val INPUT_BUFFER_SIZE = newOption("inputBufferSize")
+ val COLUMN_NAME_OF_CORRUPT_RECORD = newOption("columnNameOfCorruptRecord")
+ val NULL_VALUE = newOption("nullValue")
+ val NAN_VALUE = newOption("nanValue")
+ val POSITIVE_INF = newOption("positiveInf")
+ val NEGATIVE_INF = newOption("negativeInf")
+ val TIME_ZONE = newOption("timeZone")
+ val UNESCAPED_QUOTE_HANDLING = newOption("unescapedQuoteHandling")
+ // Options with alternative
+ val CHARSET = newOption("charset")
+ val ENCODING = newOption("encoding", Some(CHARSET))
+ val CODEC = newOption("codec")
+ val COMPRESSION = newOption("compression", Some(CODEC))
+ val DELIMITER = newOption("delimiter")
+ val SEP = newOption("sep", Some(DELIMITER))
Review Comment:
Alternative way could be
```
val ENCODING = "encoding"
val CHARSET = "charset"
newOption(ENCODING, CHARSET)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xiaonanyang-db commented on a diff in pull request #38113: [SPARK-40667][SQL] Refactor File Data Source Options
xiaonanyang-db commented on code in PR #38113:
URL: https://github.com/apache/spark/pull/38113#discussion_r990367237
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala:
##
@@ -327,3 +329,45 @@ class CSVOptions(
settings
}
}
+
+object CSVOptions extends DataSourceOptions {
+ val HEADER = newOption("header")
+ val INFER_SCHEMA = newOption("inferSchema")
+ val IGNORE_LEADING_WHITESPACE = newOption("ignoreLeadingWhiteSpace")
+ val IGNORE_TRAILING_WHITESPACE = newOption("ignoreTrailingWhiteSpace")
+ val PREFERS_DATE = newOption("prefersDate")
+ val ESCAPE_QUOTES = newOption("escapeQuotes")
+ val QUOTE_ALL = newOption("quoteAll")
+ val ENFORCE_SCHEMA = newOption("enforceSchema")
+ val QUOTE = newOption("quote")
+ val ESCAPE = newOption("escape")
+ val COMMENT = newOption("comment")
+ val MAX_COLUMNS = newOption("maxColumns")
+ val MAX_CHARS_PER_COLUMN = newOption("maxCharsPerColumn")
+ val MODE = newOption("mode")
+ val CHAR_TO_ESCAPE_QUOTE_ESCAPING = newOption("charToEscapeQuoteEscaping")
+ val LOCALE = newOption("locale")
+ val DATE_FORMAT = newOption("dateFormat")
+ val TIMESTAMP_FORMAT = newOption("timestampFormat")
+ val TIMESTAMP_NTZ_FORMAT = newOption("timestampNTZFormat")
+ val ENABLE_DATETIME_PARSING_FALLBACK =
newOption("enableDateTimeParsingFallback")
+ val MULTI_LINE = newOption("multiLine")
+ val SAMPLING_RATIO = newOption("samplingRatio")
+ val EMPTY_VALUE = newOption("emptynewOption")
+ val LINE_SEP = newOption("lineSep")
+ val INPUT_BUFFER_SIZE = newOption("inputBufferSize")
+ val COLUMN_NAME_OF_CORRUPT_RECORD = newOption("columnNameOfCorruptRecord")
+ val NULL_VALUE = newOption("nullValue")
+ val NAN_VALUE = newOption("nanValue")
+ val POSITIVE_INF = newOption("positiveInf")
+ val NEGATIVE_INF = newOption("negativeInf")
+ val TIME_ZONE = newOption("timeZone")
+ val UNESCAPED_QUOTE_HANDLING = newOption("unescapedQuoteHandling")
+ // Options with alternative
+ val CHARSET = newOption("charset")
+ val ENCODING = newOption("encoding", Some(CHARSET))
+ val CODEC = newOption("codec")
+ val COMPRESSION = newOption("compression", Some(CODEC))
+ val DELIMITER = newOption("delimiter")
+ val SEP = newOption("sep", Some(DELIMITER))
Review Comment:
One tricky thing about the second method is that, the following constants
declaration will fail
```
val (ENCODING, CHARSET) = newOption("encoding", "charset")
```
Because `Pattern variables must start with a lower-case letter. (SLS 8.1.1.)`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #38084: [SPARK-40640][CORE] SparkHadoopUtil to set origin of hadoop/hive config options
dongjoon-hyun commented on code in PR #38084:
URL: https://github.com/apache/spark/pull/38084#discussion_r990366656
##
core/src/main/scala/org/apache/spark/deploy/SparkHadoopUtil.scala:
##
@@ -474,40 +553,79 @@ private[spark] object SparkHadoopUtil extends Logging {
private def appendHiveConfigs(hadoopConf: Configuration): Unit = {
hiveConfKeys.foreach { kv =>
- hadoopConf.set(kv.getKey, kv.getValue)
+ hadoopConf.set(kv.getKey, kv.getValue, SOURCE_HIVE_SITE)
}
}
private def appendSparkHadoopConfigs(conf: SparkConf, hadoopConf:
Configuration): Unit = {
// Copy any "spark.hadoop.foo=bar" spark properties into conf as "foo=bar"
for ((key, value) <- conf.getAll if key.startsWith("spark.hadoop.")) {
- hadoopConf.set(key.substring("spark.hadoop.".length), value)
+ hadoopConf.set(key.substring("spark.hadoop.".length), value,
+SOURCE_SPARK_HADOOP)
}
+val setBySpark = SET_TO_DEFAULT_VALUES
if
(conf.getOption("spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version").isEmpty)
{
- hadoopConf.set("mapreduce.fileoutputcommitter.algorithm.version", "1")
+ hadoopConf.set("mapreduce.fileoutputcommitter.algorithm.version", "1",
setBySpark)
}
-// Since Hadoop 3.3.1, HADOOP-17597 starts to throw exceptions by default
+// In Hadoop 3.3.1, HADOOP-17597 starts to throw exceptions by default
+// this has been reverted in 3.3.2 (HADOOP-17928); setting it to
+// true here is harmless
if
(conf.getOption("spark.hadoop.fs.s3a.downgrade.syncable.exceptions").isEmpty) {
- hadoopConf.set("fs.s3a.downgrade.syncable.exceptions", "true")
+ hadoopConf.set("fs.s3a.downgrade.syncable.exceptions", "true",
setBySpark)
}
// In Hadoop 3.3.1, AWS region handling with the default "" endpoint only
works
// in EC2 deployments or when the AWS CLI is installed.
// The workaround is to set the name of the S3 endpoint explicitly,
// if not already set. See HADOOP-17771.
-// This change is harmless on older versions and compatible with
-// later Hadoop releases
if (hadoopConf.get("fs.s3a.endpoint", "").isEmpty &&
hadoopConf.get("fs.s3a.endpoint.region") == null) {
// set to US central endpoint which can also connect to buckets
// in other regions at the expense of a HEAD request during fs creation
- hadoopConf.set("fs.s3a.endpoint", "s3.amazonaws.com")
+ hadoopConf.set("fs.s3a.endpoint", "s3.amazonaws.com", setBySpark)
}
}
private def appendSparkHiveConfigs(conf: SparkConf, hadoopConf:
Configuration): Unit = {
// Copy any "spark.hive.foo=bar" spark properties into conf as
"hive.foo=bar"
for ((key, value) <- conf.getAll if key.startsWith("spark.hive.")) {
- hadoopConf.set(key.substring("spark.".length), value)
+ hadoopConf.set(key.substring("spark.".length), value,
+SOURCE_SPARK_HIVE)
Review Comment:
Can we make it into a single line?
```scala
hadoopConf.set(key.substring("spark.".length), value, SOURCE_SPARK_HIVE)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xiaonanyang-db commented on a diff in pull request #38113: [SPARK-40667][SQL] Refactor File Data Source Options
xiaonanyang-db commented on code in PR #38113:
URL: https://github.com/apache/spark/pull/38113#discussion_r990306588
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala:
##
@@ -327,3 +329,45 @@ class CSVOptions(
settings
}
}
+
+object CSVOptions extends DataSourceOptions {
+ val HEADER = newOption("header")
+ val INFER_SCHEMA = newOption("inferSchema")
+ val IGNORE_LEADING_WHITESPACE = newOption("ignoreLeadingWhiteSpace")
+ val IGNORE_TRAILING_WHITESPACE = newOption("ignoreTrailingWhiteSpace")
+ val PREFERS_DATE = newOption("prefersDate")
+ val ESCAPE_QUOTES = newOption("escapeQuotes")
+ val QUOTE_ALL = newOption("quoteAll")
+ val ENFORCE_SCHEMA = newOption("enforceSchema")
+ val QUOTE = newOption("quote")
+ val ESCAPE = newOption("escape")
+ val COMMENT = newOption("comment")
+ val MAX_COLUMNS = newOption("maxColumns")
+ val MAX_CHARS_PER_COLUMN = newOption("maxCharsPerColumn")
+ val MODE = newOption("mode")
+ val CHAR_TO_ESCAPE_QUOTE_ESCAPING = newOption("charToEscapeQuoteEscaping")
+ val LOCALE = newOption("locale")
+ val DATE_FORMAT = newOption("dateFormat")
+ val TIMESTAMP_FORMAT = newOption("timestampFormat")
+ val TIMESTAMP_NTZ_FORMAT = newOption("timestampNTZFormat")
+ val ENABLE_DATETIME_PARSING_FALLBACK =
newOption("enableDateTimeParsingFallback")
+ val MULTI_LINE = newOption("multiLine")
+ val SAMPLING_RATIO = newOption("samplingRatio")
+ val EMPTY_VALUE = newOption("emptynewOption")
+ val LINE_SEP = newOption("lineSep")
+ val INPUT_BUFFER_SIZE = newOption("inputBufferSize")
+ val COLUMN_NAME_OF_CORRUPT_RECORD = newOption("columnNameOfCorruptRecord")
+ val NULL_VALUE = newOption("nullValue")
+ val NAN_VALUE = newOption("nanValue")
+ val POSITIVE_INF = newOption("positiveInf")
+ val NEGATIVE_INF = newOption("negativeInf")
+ val TIME_ZONE = newOption("timeZone")
+ val UNESCAPED_QUOTE_HANDLING = newOption("unescapedQuoteHandling")
+ // Options with alternative
+ val CHARSET = newOption("charset")
+ val ENCODING = newOption("encoding", Some(CHARSET))
+ val CODEC = newOption("codec")
+ val COMPRESSION = newOption("compression", Some(CODEC))
+ val DELIMITER = newOption("delimiter")
+ val SEP = newOption("sep", Some(DELIMITER))
Review Comment:
Looks like a good idea
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xiaonanyang-db commented on a diff in pull request #38113: [SPARK-40667][SQL] Refactor File Data Source Options
xiaonanyang-db commented on code in PR #38113:
URL: https://github.com/apache/spark/pull/38113#discussion_r990306588
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala:
##
@@ -327,3 +329,45 @@ class CSVOptions(
settings
}
}
+
+object CSVOptions extends DataSourceOptions {
+ val HEADER = newOption("header")
+ val INFER_SCHEMA = newOption("inferSchema")
+ val IGNORE_LEADING_WHITESPACE = newOption("ignoreLeadingWhiteSpace")
+ val IGNORE_TRAILING_WHITESPACE = newOption("ignoreTrailingWhiteSpace")
+ val PREFERS_DATE = newOption("prefersDate")
+ val ESCAPE_QUOTES = newOption("escapeQuotes")
+ val QUOTE_ALL = newOption("quoteAll")
+ val ENFORCE_SCHEMA = newOption("enforceSchema")
+ val QUOTE = newOption("quote")
+ val ESCAPE = newOption("escape")
+ val COMMENT = newOption("comment")
+ val MAX_COLUMNS = newOption("maxColumns")
+ val MAX_CHARS_PER_COLUMN = newOption("maxCharsPerColumn")
+ val MODE = newOption("mode")
+ val CHAR_TO_ESCAPE_QUOTE_ESCAPING = newOption("charToEscapeQuoteEscaping")
+ val LOCALE = newOption("locale")
+ val DATE_FORMAT = newOption("dateFormat")
+ val TIMESTAMP_FORMAT = newOption("timestampFormat")
+ val TIMESTAMP_NTZ_FORMAT = newOption("timestampNTZFormat")
+ val ENABLE_DATETIME_PARSING_FALLBACK =
newOption("enableDateTimeParsingFallback")
+ val MULTI_LINE = newOption("multiLine")
+ val SAMPLING_RATIO = newOption("samplingRatio")
+ val EMPTY_VALUE = newOption("emptynewOption")
+ val LINE_SEP = newOption("lineSep")
+ val INPUT_BUFFER_SIZE = newOption("inputBufferSize")
+ val COLUMN_NAME_OF_CORRUPT_RECORD = newOption("columnNameOfCorruptRecord")
+ val NULL_VALUE = newOption("nullValue")
+ val NAN_VALUE = newOption("nanValue")
+ val POSITIVE_INF = newOption("positiveInf")
+ val NEGATIVE_INF = newOption("negativeInf")
+ val TIME_ZONE = newOption("timeZone")
+ val UNESCAPED_QUOTE_HANDLING = newOption("unescapedQuoteHandling")
+ // Options with alternative
+ val CHARSET = newOption("charset")
+ val ENCODING = newOption("encoding", Some(CHARSET))
+ val CODEC = newOption("codec")
+ val COMPRESSION = newOption("compression", Some(CODEC))
+ val DELIMITER = newOption("delimiter")
+ val SEP = newOption("sep", Some(DELIMITER))
Review Comment:
Looks a good idea
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] brkyvz commented on a diff in pull request #38113: [SPARK-40667][SQL] Refactor File Data Source Options
brkyvz commented on code in PR #38113:
URL: https://github.com/apache/spark/pull/38113#discussion_r990303182
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JSONOptions.scala:
##
@@ -230,3 +232,35 @@ private[sql] object JSONOptionsInRead {
Charset.forName("UTF-32")
)
}
+
+object JSONOptions extends DataSourceOptions {
+ val SAMPLING_RATIO = newOption("samplingRatio")
+ val PRIMITIVES_AS_STRING = newOption("primitivesAsString")
+ val PREFERS_DECIMAL = newOption("prefersDecimal")
+ val ALLOW_COMMENTS = newOption("allowComments")
+ val ALLOW_UNQUOTED_FIELD_NAMES = newOption("allowUnquotedFieldNames")
+ val ALLOW_SINGLE_QUOTES = newOption("allowSingleQuotes")
+ val ALLOW_NUMERIC_LEADING_ZEROS = newOption("allowNumericLeadingZeros")
+ val ALLOW_NON_NUMERIC_NUMBERS = newOption("allowNonNumericNumbers")
+ val ALLOW_BACKSLASH_ESCAPING_ANY_CHARACTER =
newOption("allowBackslashEscapingAnyCharacter")
+ val ALLOW_UNQUOTED_CONTROL_CHARS = newOption("allowUnquotedControlChars")
+ val COMPRESSION = newOption("compression")
+ val MODE = newOption("mode")
+ val DROP_FIELD_IF_ALL_NULL = newOption("dropFieldIfAllNull")
+ val IGNORE_NULL_FIELDS = newOption("ignoreNullFields")
+ val LOCALE = newOption("locale")
+ val DATE_FORMAT = newOption("dateFormat")
+ val TIMESTAMP_FORMAT = newOption("timestampFormat")
+ val TIMESTAMP_NTZ_FORMAT = newOption("timestampNTZFormat")
+ val ENABLE_DATETIME_PARSING_FALLBACK =
newOption("enableDateTimeParsingFallback")
+ val MULTILINE = newOption("multiLine")
+ val LINE_SEP = newOption("lineSep")
+ val PRETTY = newOption("pretty")
+ val INFER_TIMESTAMP = newOption("inferTimestamp")
+ val COLUMN_NAME_OF_CORRUPTED_RECORD = newOption("columnNameOfCorruptRecord")
+ val TIME_ZONE = newOption("timeZone")
+ val WRITE_NON_ASCII_CHARACTER_AS_CODEPOINT =
newOption("writeNonAsciiCharacterAsCodePoint")
+ // Options with alternative
+ val ENCODING = newOption("encoding", Some("charset"))
+ val CHARSET = newOption("charset", Some("encoding"))
Review Comment:
agree, I think we need two methods
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] brkyvz commented on a diff in pull request #38113: [SPARK-40667][SQL] Refactor File Data Source Options
brkyvz commented on code in PR #38113:
URL: https://github.com/apache/spark/pull/38113#discussion_r990302545
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JSONOptions.scala:
##
@@ -230,3 +232,35 @@ private[sql] object JSONOptionsInRead {
Charset.forName("UTF-32")
)
}
+
+object JSONOptions extends DataSourceOptions {
+ val SAMPLING_RATIO = newOption("samplingRatio")
+ val PRIMITIVES_AS_STRING = newOption("primitivesAsString")
+ val PREFERS_DECIMAL = newOption("prefersDecimal")
+ val ALLOW_COMMENTS = newOption("allowComments")
+ val ALLOW_UNQUOTED_FIELD_NAMES = newOption("allowUnquotedFieldNames")
+ val ALLOW_SINGLE_QUOTES = newOption("allowSingleQuotes")
+ val ALLOW_NUMERIC_LEADING_ZEROS = newOption("allowNumericLeadingZeros")
+ val ALLOW_NON_NUMERIC_NUMBERS = newOption("allowNonNumericNumbers")
+ val ALLOW_BACKSLASH_ESCAPING_ANY_CHARACTER =
newOption("allowBackslashEscapingAnyCharacter")
+ val ALLOW_UNQUOTED_CONTROL_CHARS = newOption("allowUnquotedControlChars")
+ val COMPRESSION = newOption("compression")
+ val MODE = newOption("mode")
+ val DROP_FIELD_IF_ALL_NULL = newOption("dropFieldIfAllNull")
+ val IGNORE_NULL_FIELDS = newOption("ignoreNullFields")
+ val LOCALE = newOption("locale")
+ val DATE_FORMAT = newOption("dateFormat")
+ val TIMESTAMP_FORMAT = newOption("timestampFormat")
+ val TIMESTAMP_NTZ_FORMAT = newOption("timestampNTZFormat")
+ val ENABLE_DATETIME_PARSING_FALLBACK =
newOption("enableDateTimeParsingFallback")
+ val MULTILINE = newOption("multiLine")
+ val LINE_SEP = newOption("lineSep")
Review Comment:
ok
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] brkyvz commented on a diff in pull request #38113: [SPARK-40667][SQL] Refactor File Data Source Options
brkyvz commented on code in PR #38113:
URL: https://github.com/apache/spark/pull/38113#discussion_r990302208
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/DataSourceOptions.scala:
##
@@ -0,0 +1,59 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst
+
+/**
+ * Interface defines the following methods for a data source:
+ * - register a new option name
+ * - retrieve all registered option names
+ * - valid a given option name
+ * - get alternative option name if any
+ */
+trait DataSourceOptions {
+ // Option -> Alternative Option if any
+ private val validOptions = collection.mutable.Map[String, Option[String]]()
+
+ /**
+ * Register a new Option.
+ * @param name The primary option name
+ * @param alternative Alternative option name if any
+ */
+ protected def newOption(name: String, alternative: Option[String] = None):
String = {
+// Register both of the options
+validOptions += (name -> alternative)
+validOptions ++ alternative.map(alterName => alterName -> Some(name))
+name
+ }
+
+ /**
+ * @return All valid file source options
+ */
+ def getAllValidOptionNames: scala.collection.Set[String] =
validOptions.keySet
+
+ /**
+ * @param name Option name to be validated
+ * @return if the given Option name is valid
+ */
+ def isValidOptionName(name: String): Boolean = validOptions.contains(name)
+
+ /**
+ * @param name Option name
+ * @return Alternative option name if any
+ */
+ def getAlternativeOptionName(name: String): Option[String] =
validOptions.getOrElse(name, None)
Review Comment:
`.get(...).flatten` then
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a diff in pull request #38147: [SPARK-40585][SQL] Double-quoted identifiers should be available only in ANSI mode
gengliangwang commented on code in PR #38147: URL: https://github.com/apache/spark/pull/38147#discussion_r990299771 ## sql/core/src/test/resources/sql-tests/results/double-quoted-identifiers.sql.out: ## @@ -277,74 +277,110 @@ SELECT 1 FROM "not_exist" -- !query schema struct<> -- !query output -org.apache.spark.sql.AnalysisException -Table or view not found: not_exist; line 1 pos 14 +org.apache.spark.sql.catalyst.parser.ParseException Review Comment: I intend to ensure it won't work when ANSI mode is off. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xiaonanyang-db commented on a diff in pull request #38113: [SPARK-40667][SQL] Refactor File Data Source Options
xiaonanyang-db commented on code in PR #38113:
URL: https://github.com/apache/spark/pull/38113#discussion_r990294081
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/DataSourceOptions.scala:
##
@@ -0,0 +1,59 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst
+
+/**
+ * Interface defines the following methods for a data source:
+ * - register a new option name
+ * - retrieve all registered option names
+ * - valid a given option name
+ * - get alternative option name if any
+ */
+trait DataSourceOptions {
+ // Option -> Alternative Option if any
+ private val validOptions = collection.mutable.Map[String, Option[String]]()
+
+ /**
+ * Register a new Option.
+ * @param name The primary option name
+ * @param alternative Alternative option name if any
+ */
+ protected def newOption(name: String, alternative: Option[String] = None):
String = {
+// Register both of the options
+validOptions += (name -> alternative)
+validOptions ++ alternative.map(alterName => alterName -> Some(name))
+name
+ }
+
+ /**
+ * @return All valid file source options
+ */
+ def getAllValidOptionNames: scala.collection.Set[String] =
validOptions.keySet
+
+ /**
+ * @param name Option name to be validated
+ * @return if the given Option name is valid
+ */
+ def isValidOptionName(name: String): Boolean = validOptions.contains(name)
+
+ /**
+ * @param name Option name
+ * @return Alternative option name if any
+ */
+ def getAlternativeOptionName(name: String): Option[String] =
validOptions.getOrElse(name, None)
Review Comment:
let me know if this looks better:
```
if (isValidOption(name)) {
validOptions(name)
} else {
None
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xiaonanyang-db commented on a diff in pull request #38113: [SPARK-40667][SQL] Refactor File Data Source Options
xiaonanyang-db commented on code in PR #38113:
URL: https://github.com/apache/spark/pull/38113#discussion_r990292792
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/DataSourceOptions.scala:
##
@@ -0,0 +1,59 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst
+
+/**
+ * Interface defines the following methods for a data source:
+ * - register a new option name
+ * - retrieve all registered option names
+ * - valid a given option name
+ * - get alternative option name if any
+ */
+trait DataSourceOptions {
+ // Option -> Alternative Option if any
+ private val validOptions = collection.mutable.Map[String, Option[String]]()
+
+ /**
+ * Register a new Option.
+ * @param name The primary option name
+ * @param alternative Alternative option name if any
+ */
+ protected def newOption(name: String, alternative: Option[String] = None):
String = {
+// Register both of the options
+validOptions += (name -> alternative)
+validOptions ++ alternative.map(alterName => alterName -> Some(name))
+name
+ }
+
+ /**
+ * @return All valid file source options
+ */
+ def getAllValidOptionNames: scala.collection.Set[String] =
validOptions.keySet
+
+ /**
+ * @param name Option name to be validated
+ * @return if the given Option name is valid
+ */
+ def isValidOptionName(name: String): Boolean = validOptions.contains(name)
+
+ /**
+ * @param name Option name
+ * @return Alternative option name if any
+ */
+ def getAlternativeOptionName(name: String): Option[String] =
validOptions.getOrElse(name, None)
Review Comment:
`validOptions ` is of type `Map[String, Option[String]]`, thus `get` will
return `Option[Option[String]]`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srielau commented on a diff in pull request #37887: [SPARK-40360] ALREADY_EXISTS and NOT_FOUND exceptions
srielau commented on code in PR #37887: URL: https://github.com/apache/spark/pull/37887#discussion_r990251570 ## core/src/test/scala/org/apache/spark/SparkFunSuite.scala: ## @@ -374,6 +382,19 @@ abstract class SparkFunSuite checkError(exception, errorClass, sqlState, parameters, matchPVals = true, Array(context)) + protected def checkErrorTableNotFound( Review Comment: @MaxGekk OK, where can I put it instead? This little function eliminates dozens of more complicated checkError invocations across many test files. I added it because it's so pervasive -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk closed pull request #38152: [SPARK-40702][SQL] Fix partition specs in `PartitionsAlreadyExistException`
MaxGekk closed pull request #38152: [SPARK-40702][SQL] Fix partition specs in `PartitionsAlreadyExistException` URL: https://github.com/apache/spark/pull/38152 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on pull request #38152: [SPARK-40702][SQL] Fix partition specs in `PartitionsAlreadyExistException`
MaxGekk commented on PR #38152: URL: https://github.com/apache/spark/pull/38152#issuecomment-1271780964 Merging to master. Thank you, @cloud-fan and @singhpk234 for review. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srielau commented on a diff in pull request #37887: [SPARK-40360] ALREADY_EXISTS and NOT_FOUND exceptions
srielau commented on code in PR #37887:
URL: https://github.com/apache/spark/pull/37887#discussion_r990248776
##
core/src/test/scala/org/apache/spark/SparkFunSuite.scala:
##
@@ -316,14 +316,22 @@ abstract class SparkFunSuite
} else {
assert(expectedParameters === parameters)
}
-val actualQueryContext = exception.getQueryContext()
-assert(actualQueryContext.length === queryContext.length, "Invalid length
of the query context")
-actualQueryContext.zip(queryContext).foreach { case (actual, expected) =>
- assert(actual.objectType() === expected.objectType(), "Invalid
objectType of a query context")
- assert(actual.objectName() === expected.objectName(), "Invalid
objectName of a query context")
- assert(actual.startIndex() === expected.startIndex(), "Invalid
startIndex of a query context")
- assert(actual.stopIndex() === expected.stopIndex(), "Invalid stopIndex
of a query context")
- assert(actual.fragment() === expected.fragment(), "Invalid fragment of a
query context")
+if (!queryContext.isEmpty) {
Review Comment:
Hmm, there was a reason for this.. I'll refresh my memory.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srielau commented on a diff in pull request #37887: [SPARK-40360] ALREADY_EXISTS and NOT_FOUND exceptions
srielau commented on code in PR #37887:
URL: https://github.com/apache/spark/pull/37887#discussion_r990245513
##
core/src/main/resources/error/error-classes.json:
##
@@ -346,6 +346,18 @@
}
}
},
+ "INDEX_ALREADY_EXISTS" : {
Review Comment:
It's in the JDBC API. That's all I know. :-(
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srielau commented on a diff in pull request #37887: [SPARK-40360] ALREADY_EXISTS and NOT_FOUND exceptions
srielau commented on code in PR #37887:
URL: https://github.com/apache/spark/pull/37887#discussion_r990244457
##
core/src/main/resources/error/error-classes.json:
##
@@ -346,6 +346,18 @@
}
}
},
+ "INDEX_ALREADY_EXISTS" : {
+"message" : [
+ "Cannot create the index because it already exists. ."
+],
+"sqlState" : "42000"
+ },
+ "INDEX_NOT_FOUND" : {
+"message" : [
+ "Cannot find the index. ."
Review Comment:
@MaxGekk I would love to. However this one is a wrapper for JDBC. The
message can be anything depending on the data source.
We will need a strategy on how to deal with these cases.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srielau commented on a diff in pull request #37887: [SPARK-40360] ALREADY_EXISTS and NOT_FOUND exceptions
srielau commented on code in PR #37887:
URL: https://github.com/apache/spark/pull/37887#discussion_r990241574
##
core/src/main/resources/error/error-classes.json:
##
@@ -536,12 +563,71 @@
"Failed to set original permission back to the created
path: . Exception: "
]
},
+ "ROUTINE_ALREADY_EXISTS" : {
+"message" : [
+ "Cannot create the function because it already exists.",
+ "Choose a different name, drop or replace the existing function, or add
the IF NOT EXISTS clause to tolerate a pre-existing function."
+],
+"sqlState" : "42000"
+ },
+ "ROUTINE_NOT_FOUND" : {
+"message" : [
+ "The function cannot be found. Verify the spelling and
correctness of the schema and catalog.",
+ "If you did not qualify the name with a schema and catalog, verify the
current_schema() output, or qualify the name with the correct schema and
catalog.",
+ "To tolerate the error on drop use DROP FUNCTION IF EXISTS."
+],
+"sqlState" : "42000"
+ },
+ "SCHEMA_ALREADY_EXISTS" : {
Review Comment:
I list this as a concern in the description of the PR. IIUC @cloud-fan PR
to push errors into the catalog will enable us context specific errors.
The SQL Standard naming is: catalog.schema.(relation|type|..).
I was not able to discern when we go into the namespace codepath vs schema
codepath.
CREATE SCHEMA gave a namespace error.
Ideally I'd say we add NAMEPACE_NOT_FOUND. NAMESPACE_ALREADY_EXISTS and
raise the appropriate code. This should be a follow on PR.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srielau commented on a diff in pull request #37887: [SPARK-40360] ALREADY_EXISTS and NOT_FOUND exceptions
srielau commented on code in PR #37887:
URL: https://github.com/apache/spark/pull/37887#discussion_r990235446
##
core/src/main/resources/error/error-classes.json:
##
@@ -536,12 +563,71 @@
"Failed to set original permission back to the created
path: . Exception: "
]
},
+ "ROUTINE_ALREADY_EXISTS" : {
+"message" : [
+ "Cannot create the function because it already exists.",
+ "Choose a different name, drop or replace the existing function, or add
the IF NOT EXISTS clause to tolerate a pre-existing function."
+],
+"sqlState" : "42000"
+ },
+ "ROUTINE_NOT_FOUND" : {
+"message" : [
+ "The function cannot be found. Verify the spelling and
correctness of the schema and catalog.",
+ "If you did not qualify the name with a schema and catalog, verify the
current_schema() output, or qualify the name with the correct schema and
catalog.",
+ "To tolerate the error on drop use DROP FUNCTION IF EXISTS."
+],
+"sqlState" : "42000"
+ },
+ "SCHEMA_ALREADY_EXISTS" : {
+"message" : [
+ "Cannot create schema because it already exists.",
+ "Choose a different name, drop the existing schema, or add the IF NOT
EXISTS clause to tolerate pre-existing schema."
+],
+"sqlState" : "42000"
+ },
+ "SCHEMA_NOT_EMPTY" : {
+"message" : [
+ "Cannot drop a schema because it contains objects.",
+ "Use DROP SCHEMA ... CASCADE to drop the schema and all its objects."
+],
+"sqlState" : "42000"
+ },
+ "SCHEMA_NOT_FOUND" : {
+"message" : [
+ "The schema cannot be found. Verify the spelling and
correctness of the schema and catalog.",
+ "If you did not qualify the name with a catalog, verify the
current_schema() output, or qualify the name with the correct catalog.",
+ "To tolerate the error on drop use DROP SCHEMA IF EXISTS."
+],
+"sqlState" : "42000"
+ },
"SECOND_FUNCTION_ARGUMENT_NOT_INTEGER" : {
"message" : [
"The second argument of function needs to be an integer."
],
"sqlState" : "22023"
},
+ "TABLE_OR_VIEW_ALREADY_EXISTS" : {
+"message" : [
+ "Cannot create table or view because it already exists.",
Review Comment:
Not sure what you mean by old name. I don't think the local variables of the
code are terribly relevant.
That being said relation is the generic name for table or views. The
alternative is to call it tableOrViewName.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srielau commented on a diff in pull request #37887: [SPARK-40360] ALREADY_EXISTS and NOT_FOUND exceptions
srielau commented on code in PR #37887:
URL: https://github.com/apache/spark/pull/37887#discussion_r990233377
##
core/src/main/resources/error/error-classes.json:
##
@@ -536,12 +563,71 @@
"Failed to set original permission back to the created
path: . Exception: "
]
},
+ "ROUTINE_ALREADY_EXISTS" : {
+"message" : [
+ "Cannot create the function because it already exists.",
+ "Choose a different name, drop or replace the existing function, or add
the IF NOT EXISTS clause to tolerate a pre-existing function."
+],
+"sqlState" : "42000"
+ },
+ "ROUTINE_NOT_FOUND" : {
Review Comment:
Future proofing: Eventually we will add procedures. The shared name for
both is routine. This is also the name in the SQL Standard information schema.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srielau commented on a diff in pull request #37887: [SPARK-40360] ALREADY_EXISTS and NOT_FOUND exceptions
srielau commented on code in PR #37887:
URL: https://github.com/apache/spark/pull/37887#discussion_r990231052
##
core/src/main/resources/error/error-classes.json:
##
@@ -536,12 +563,71 @@
"Failed to set original permission back to the created
path: . Exception: "
]
},
+ "ROUTINE_ALREADY_EXISTS" : {
+"message" : [
+ "Cannot create the function because it already exists.",
+ "Choose a different name, drop or replace the existing function, or add
the IF NOT EXISTS clause to tolerate a pre-existing function."
+],
+"sqlState" : "42000"
+ },
+ "ROUTINE_NOT_FOUND" : {
+"message" : [
+ "The function cannot be found. Verify the spelling and
correctness of the schema and catalog.",
+ "If you did not qualify the name with a schema and catalog, verify the
current_schema() output, or qualify the name with the correct schema and
catalog.",
+ "To tolerate the error on drop use DROP FUNCTION IF EXISTS."
+],
+"sqlState" : "42000"
+ },
+ "SCHEMA_ALREADY_EXISTS" : {
+"message" : [
+ "Cannot create schema because it already exists.",
+ "Choose a different name, drop the existing schema, or add the IF NOT
EXISTS clause to tolerate pre-existing schema."
+],
+"sqlState" : "42000"
+ },
+ "SCHEMA_NOT_EMPTY" : {
+"message" : [
+ "Cannot drop a schema because it contains objects.",
+ "Use DROP SCHEMA ... CASCADE to drop the schema and all its objects."
+],
+"sqlState" : "42000"
+ },
+ "SCHEMA_NOT_FOUND" : {
+"message" : [
+ "The schema cannot be found. Verify the spelling and
correctness of the schema and catalog.",
+ "If you did not qualify the name with a catalog, verify the
current_schema() output, or qualify the name with the correct catalog.",
+ "To tolerate the error on drop use DROP SCHEMA IF EXISTS."
+],
+"sqlState" : "42000"
+ },
"SECOND_FUNCTION_ARGUMENT_NOT_INTEGER" : {
"message" : [
"The second argument of function needs to be an integer."
],
"sqlState" : "22023"
},
+ "TABLE_OR_VIEW_ALREADY_EXISTS" : {
+"message" : [
+ "Cannot create table or view because it already exists.",
+ "Choose a different name, drop or replace the existing object, or add
the IF NOT EXISTS clause to tolerate pre-existing objects."
+],
+"sqlState" : "42000"
+ },
+ "TABLE_OR_VIEW_NOT_FOUND" : {
+"message" : [
+ "The table or view cannot be found. Verify the spelling
and correctness of the schema and catalog.",
+ "If you did not qualify the name with a schema, verify the
current_schema() output, or qualify the name with the correct schema and
catalog.",
+ "To tolerate the error on drop use DROP VIEW IF EXISTS or DROP TABLE IF
EXISTS."
+],
+"sqlState" : "42000"
+ },
+ "TEMP_TABLE_OR_VIEW_ALREADY_EXISTS" : {
+"message" : [
+ "Cannot create the temporary view because it already
exists.",
Review Comment:
@MaxGekk Because we do not have temp tables today, correct? The error class
must be future proof. The text can evolve when we add the feature
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srielau commented on a diff in pull request #37887: [SPARK-40360] ALREADY_EXISTS and NOT_FOUND exceptions
srielau commented on code in PR #37887:
URL: https://github.com/apache/spark/pull/37887#discussion_r990229253
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/AlreadyExistException.scala:
##
@@ -20,72 +20,105 @@ package org.apache.spark.sql.catalyst.analysis
import org.apache.spark.sql.AnalysisException
import org.apache.spark.sql.catalyst.InternalRow
import org.apache.spark.sql.catalyst.catalog.CatalogTypes.TablePartitionSpec
-import org.apache.spark.sql.connector.catalog.CatalogV2Implicits._
-import org.apache.spark.sql.connector.catalog.Identifier
+import org.apache.spark.sql.catalyst.util.{quoteIdentifier, quoteNameParts }
import org.apache.spark.sql.types.StructType
/**
* Thrown by a catalog when an item already exists. The analyzer will rethrow
the exception
* as an [[org.apache.spark.sql.AnalysisException]] with the correct position
information.
*/
class DatabaseAlreadyExistsException(db: String)
- extends NamespaceAlreadyExistsException(s"Database '$db' already exists")
+ extends NamespaceAlreadyExistsException(Array(db))
-class NamespaceAlreadyExistsException(message: String)
- extends AnalysisException(
-message,
-errorClass = Some("_LEGACY_ERROR_TEMP_1118"),
-messageParameters = Map("msg" -> message)) {
+
+class NamespaceAlreadyExistsException(errorClass: String, messageParameters:
Map[String, String])
+ extends AnalysisException(errorClass, messageParameters) {
def this(namespace: Array[String]) = {
-this(s"Namespace '${namespace.quoted}' already exists")
+this(errorClass = "SCHEMA_ALREADY_EXISTS",
+ Map("schemaName" -> quoteNameParts(namespace)))
}
}
-class TableAlreadyExistsException(message: String, cause: Option[Throwable] =
None)
- extends AnalysisException(
-message,
-errorClass = Some("_LEGACY_ERROR_TEMP_1116"),
-messageParameters = Map("msg" -> message),
-cause = cause) {
+
+class TableAlreadyExistsException(errorClass: String, messageParameters:
Map[String, String],
+ cause: Option[Throwable] = None)
+ extends AnalysisException(errorClass, messageParameters, cause = cause) {
def this(db: String, table: String) = {
-this(s"Table or view '$table' already exists in database '$db'")
+this(errorClass = "TABLE_OR_VIEW_ALREADY_EXISTS",
+ messageParameters = Map("relationName" ->
+(quoteIdentifier(db) + "." + quoteIdentifier(table
Review Comment:
I'm not aware of one. If you point me I can use it. At a minimum I'd have to
build a sequence first. Just to unravel it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] bersprockets commented on pull request #37825: [WIP][SPARK-40382][SQL] Group distinct aggregate expressions by semantically equivalent children in `RewriteDistinctAggregates`
bersprockets commented on PR #37825: URL: https://github.com/apache/spark/pull/37825#issuecomment-1271731067 @cloud-fan I rebased and hopefully the tests will now run. Also I put [WIP] in the correct place in the title, which I will remove once I finished looking at the impact of using those attributes (as I mentioned above). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] bersprockets commented on pull request #37825: [SPARK-40382][SQL][WIP] Group distinct aggregate expressions by semantically equivalent children in `RewriteDistinctAggregates`
bersprockets commented on PR #37825: URL: https://github.com/apache/spark/pull/37825#issuecomment-1271702293 > LGTM. Can you rebase to the latest master branch to retrigger github action jobs? Will do. I still have this as WIP because I don't understand the impact, if any, of passing attributes created from the non-rewritten distinct aggregate expressions to the xxxAggregateExec constructor as `aggregateAttributes` ([here](https://github.com/apache/spark/blob/e19b16f68c5114f97335273da57f833f051af6cc/sql/core/src/main/scala/org/apache/spark/sql/execution/aggregate/AggUtils.scala#L263)). So I was going to review that. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38050: [SPARK-40615][SQL] Check unsupported data types when decorrelating subqueries
cloud-fan commented on code in PR #38050:
URL: https://github.com/apache/spark/pull/38050#discussion_r990171074
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/DecorrelateInnerQuery.scala:
##
@@ -360,7 +360,20 @@ object DecorrelateInnerQuery extends PredicateHelper {
//+- Aggregate [a1] [a1 AS a']
// +- OuterQuery
val conditions = outerReferenceMap.map {
-case (o, a) => EqualNullSafe(a, OuterReference(o))
+case (o, a) =>
+ val cond = EqualNullSafe(a, OuterReference(o))
+ // SPARK-40615: Certain data types (e.g. MapType) do not support
ordering, so
+ // the EqualNullSafe join condition can become unresolved.
+ if (!cond.resolved) {
+if (!RowOrdering.isOrderable(a.dataType)) {
+ throw
QueryCompilationErrors.unsupportedCorrelatedReferenceDataTypeError(
+o, a.dataType, plan.origin)
+} else {
+ throw new IllegalStateException(s"Unable to decorrelate
subquery: " +
Review Comment:
if this should never happen, let's use `SparkException.internalError`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #37819: [SPARK-40377][SQL] Allow customize maxBroadcastTableBytes and maxBroadcastRows
cloud-fan commented on code in PR #37819: URL: https://github.com/apache/spark/pull/37819#discussion_r990166936 ## sql/core/src/main/scala/org/apache/spark/sql/execution/exchange/BroadcastExchangeExec.scala: ## @@ -121,7 +120,7 @@ case class BroadcastExchangeExec( // and only 70% of the slots can be used before growing in UnsafeHashedRelation, // here the limitation should not be over 341 million. (BytesToBytesMap.MAX_CAPACITY / 1.5).toLong -case _ => 51200 Review Comment: This hardcoded value is probably the physical limitation. If we want fine-grained control over broadcast join decisions, we can probably add a config that is similar to `spark.sql.autoBroadcastJoinThreshold` and is based on number of rows. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38147: [SPARK-40585][SQL] Double-quoted identifiers should be available only in ANSI mode
cloud-fan commented on code in PR #38147: URL: https://github.com/apache/spark/pull/38147#discussion_r990137107 ## sql/core/src/test/resources/sql-tests/results/double-quoted-identifiers.sql.out: ## @@ -277,74 +277,110 @@ SELECT 1 FROM "not_exist" -- !query schema struct<> -- !query output -org.apache.spark.sql.AnalysisException -Table or view not found: not_exist; line 1 pos 14 +org.apache.spark.sql.catalyst.parser.ParseException Review Comment: hmm, do we really need to run this SQL gold file in non-ansi mode? We will just see a bunch of parser errors. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38113: [SPARK-40667][SQL] Refactor File Data Source Options
cloud-fan commented on code in PR #38113:
URL: https://github.com/apache/spark/pull/38113#discussion_r990131954
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala:
##
@@ -327,3 +329,45 @@ class CSVOptions(
settings
}
}
+
+object CSVOptions extends DataSourceOptions {
+ val HEADER = newOption("header")
+ val INFER_SCHEMA = newOption("inferSchema")
+ val IGNORE_LEADING_WHITESPACE = newOption("ignoreLeadingWhiteSpace")
+ val IGNORE_TRAILING_WHITESPACE = newOption("ignoreTrailingWhiteSpace")
+ val PREFERS_DATE = newOption("prefersDate")
+ val ESCAPE_QUOTES = newOption("escapeQuotes")
+ val QUOTE_ALL = newOption("quoteAll")
+ val ENFORCE_SCHEMA = newOption("enforceSchema")
+ val QUOTE = newOption("quote")
+ val ESCAPE = newOption("escape")
+ val COMMENT = newOption("comment")
+ val MAX_COLUMNS = newOption("maxColumns")
+ val MAX_CHARS_PER_COLUMN = newOption("maxCharsPerColumn")
+ val MODE = newOption("mode")
+ val CHAR_TO_ESCAPE_QUOTE_ESCAPING = newOption("charToEscapeQuoteEscaping")
+ val LOCALE = newOption("locale")
+ val DATE_FORMAT = newOption("dateFormat")
+ val TIMESTAMP_FORMAT = newOption("timestampFormat")
+ val TIMESTAMP_NTZ_FORMAT = newOption("timestampNTZFormat")
+ val ENABLE_DATETIME_PARSING_FALLBACK =
newOption("enableDateTimeParsingFallback")
+ val MULTI_LINE = newOption("multiLine")
+ val SAMPLING_RATIO = newOption("samplingRatio")
+ val EMPTY_VALUE = newOption("emptynewOption")
+ val LINE_SEP = newOption("lineSep")
+ val INPUT_BUFFER_SIZE = newOption("inputBufferSize")
+ val COLUMN_NAME_OF_CORRUPT_RECORD = newOption("columnNameOfCorruptRecord")
+ val NULL_VALUE = newOption("nullValue")
+ val NAN_VALUE = newOption("nanValue")
+ val POSITIVE_INF = newOption("positiveInf")
+ val NEGATIVE_INF = newOption("negativeInf")
+ val TIME_ZONE = newOption("timeZone")
+ val UNESCAPED_QUOTE_HANDLING = newOption("unescapedQuoteHandling")
+ // Options with alternative
+ val CHARSET = newOption("charset")
+ val ENCODING = newOption("encoding", Some(CHARSET))
+ val CODEC = newOption("codec")
+ val COMPRESSION = newOption("compression", Some(CODEC))
Review Comment:
this looks confusing. why do we need to register an option twice if it has
an alternaive? I thought we only need to do it once as the register API allows
you to specify an alternative.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38113: [SPARK-40667][SQL] Refactor File Data Source Options
cloud-fan commented on code in PR #38113:
URL: https://github.com/apache/spark/pull/38113#discussion_r990129326
##
connector/avro/src/test/scala/org/apache/spark/sql/avro/AvroSuite.scala:
##
@@ -2272,6 +2272,10 @@ abstract class AvroSuite
checkAnswer(df2, df.collect().toSeq)
}
}
+
+ test("SPARK-40667: Check the number of valid Avro options") {
+assert(AvroOptions.getAllValidOptionNames.size == 9)
Review Comment:
what's the point of having this test?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38113: [SPARK-40667][SQL] Refactor File Data Source Options
cloud-fan commented on code in PR #38113:
URL: https://github.com/apache/spark/pull/38113#discussion_r990126894
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/DataSourceOptions.scala:
##
@@ -0,0 +1,59 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst
+
+/**
+ * Interface defines the following methods for a data source:
+ * - register a new option name
+ * - retrieve all registered option names
+ * - valid a given option name
+ * - get alternative option name if any
+ */
+trait DataSourceOptions {
+ // Option -> Alternative Option if any
+ private val validOptions = collection.mutable.Map[String, Option[String]]()
+
+ /**
+ * Register a new Option.
+ * @param name The primary option name
+ * @param alternative Alternative option name if any
+ */
+ protected def newOption(name: String, alternative: Option[String] = None):
String = {
+// Register both of the options
+validOptions += (name -> alternative)
+validOptions ++ alternative.map(alterName => alterName -> Some(name))
+name
+ }
+
+ /**
+ * @return All valid file source options
+ */
+ def getAllValidOptionNames: scala.collection.Set[String] =
validOptions.keySet
Review Comment:
+1
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38113: [SPARK-40667][SQL] Refactor File Data Source Options
cloud-fan commented on code in PR #38113:
URL: https://github.com/apache/spark/pull/38113#discussion_r990126694
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/DataSourceOptions.scala:
##
@@ -0,0 +1,59 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst
+
+/**
+ * Interface defines the following methods for a data source:
+ * - register a new option name
+ * - retrieve all registered option names
+ * - valid a given option name
+ * - get alternative option name if any
+ */
+trait DataSourceOptions {
+ // Option -> Alternative Option if any
+ private val validOptions = collection.mutable.Map[String, Option[String]]()
+
+ /**
+ * Register a new Option.
+ * @param name The primary option name
+ * @param alternative Alternative option name if any
+ */
+ protected def newOption(name: String, alternative: Option[String] = None):
String = {
+// Register both of the options
+validOptions += (name -> alternative)
+validOptions ++ alternative.map(alterName => alterName -> Some(name))
Review Comment:
how about `alternative.foreach(alterName => validOptions += (alterName ->
Some(name)))`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a diff in pull request #38134: [SPARK-40521][SQL] Return only exists partitions in `PartitionsAlreadyExistException` from Hive's create partition
MaxGekk commented on code in PR #38134:
URL: https://github.com/apache/spark/pull/38134#discussion_r990125592
##
sql/core/src/test/scala/org/apache/spark/sql/execution/command/v2/AlterTableAddPartitionSuite.scala:
##
@@ -99,4 +100,22 @@ class AlterTableAddPartitionSuite
}
}
}
+
+ // TODO: Move this test to the common trait as soon as it is migrated on
checkError()
+ test("partition already exists") {
+withNamespaceAndTable("ns", "tbl") { t =>
+ sql(s"CREATE TABLE $t (id bigint, data string) $defaultUsing PARTITIONED
BY (id)")
+ sql(s"ALTER TABLE $t ADD PARTITION (id=2) LOCATION 'loc1'")
+
+ val errMsg = intercept[PartitionsAlreadyExistException] {
+sql(s"ALTER TABLE $t ADD PARTITION (id=1) LOCATION 'loc'" +
+ " PARTITION (id=2) LOCATION 'loc1'")
+ }.getMessage
+ assert(errMsg === s"The following partitions already exists in table
$t:2 -> id")
Review Comment:
Here is the fix: https://github.com/apache/spark/pull/38152
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk opened a new pull request, #38152: [WIP][SQL] Fix partition specs in `PartitionsAlreadyExistException`
MaxGekk opened a new pull request, #38152: URL: https://github.com/apache/spark/pull/38152 ### What changes were proposed in this pull request? In the PR, I propose to change formatting of partition specs in `PartitionsAlreadyExistException`. ### Why are the changes needed? To be consistent w/ V1 catalogs, and to not confuse Spark SQL users. ### Does this PR introduce _any_ user-facing change? Yes, it changes user-facing error message. ### How was this patch tested? By running the modified test suite: ``` $ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly *.AlterTableAddPartitionSuite" ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a diff in pull request #37834: [SPARK-40400][SQL] Pass error message parameters to exceptions as maps
MaxGekk commented on code in PR #37834:
URL: https://github.com/apache/spark/pull/37834#discussion_r990073683
##
sql/core/src/test/scala/org/apache/spark/sql/sources/InsertSuite.scala:
##
@@ -2092,19 +2092,30 @@ class InsertSuite extends DataSourceTest with
SharedSparkSession {
test("SPARK-33294: Add query resolved check before analyze InsertIntoDir") {
withTempPath { path =>
- val ex = intercept[AnalysisException] {
-sql(
- s"""
-|INSERT OVERWRITE DIRECTORY '${path.getAbsolutePath}' USING PARQUET
-|SELECT * FROM (
-| SELECT c3 FROM (
-| SELECT c1, c2 from values(1,2) t(c1, c2)
-| )
-|)
- """.stripMargin)
- }
- assert(ex.getErrorClass == "UNRESOLVED_COLUMN")
- assert(ex.messageParameters.head == "`c3`")
+ val insert = s"INSERT OVERWRITE DIRECTORY '${path.getAbsolutePath}'
USING PARQUET"
+ checkError(
+exception = intercept[AnalysisException] {
+ sql(
+s"""
+ |$insert
+ |SELECT * FROM (
+ | SELECT c3 FROM (
+ | SELECT c1, c2 from values(1,2) t(c1, c2)
+ | )
+ |)
+""".stripMargin)
+},
+errorClass = "UNRESOLVED_COLUMN",
+errorSubClass = "WITH_SUGGESTION",
+sqlState = "42000",
+parameters = Map(
+ "objectName" -> "`c3`",
+ "proposal" ->
+"`__auto_generated_subquery_name`.`c1`,
`__auto_generated_subquery_name`.`c2`"),
+context = ExpectedContext(
+ fragment = insert,
Review Comment:
Yes, it should be `c3`. The PR https://github.com/apache/spark/pull/37861
changes this in OSS.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk closed pull request #38134: [SPARK-40521][SQL] Return only exists partitions in `PartitionsAlreadyExistException` from Hive's create partition
MaxGekk closed pull request #38134: [SPARK-40521][SQL] Return only exists partitions in `PartitionsAlreadyExistException` from Hive's create partition URL: https://github.com/apache/spark/pull/38134 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on pull request #38134: [SPARK-40521][SQL] Return only exists partitions in `PartitionsAlreadyExistException` from Hive's create partition
MaxGekk commented on PR #38134: URL: https://github.com/apache/spark/pull/38134#issuecomment-1271539831 Merging to master. Thank you, @cloud-fan for review. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #37407: [SPARK-39876][SQL] Add UNPIVOT to SQL syntax
cloud-fan closed pull request #37407: [SPARK-39876][SQL] Add UNPIVOT to SQL syntax URL: https://github.com/apache/spark/pull/37407 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #37407: [SPARK-39876][SQL] Add UNPIVOT to SQL syntax
cloud-fan commented on PR #37407: URL: https://github.com/apache/spark/pull/37407#issuecomment-1271538063 thanks, merging to master! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] steveloughran commented on a diff in pull request #38084: [SPARK-40640][CORE] SparkHadoopUtil to set origin of hadoop/hive config options
steveloughran commented on code in PR #38084:
URL: https://github.com/apache/spark/pull/38084#discussion_r989981209
##
core/src/test/scala/org/apache/spark/deploy/SparkHadoopUtilSuite.scala:
##
@@ -93,4 +139,41 @@ class SparkHadoopUtilSuite extends SparkFunSuite {
assert(hadoopConf.get(key) === expected,
s"Mismatch in expected value of $key")
}
+
+ /**
+ * Assert that a hadoop configuration option has the expected value
+ * and has the expected source.
+ *
+ * @param hadoopConf configuration to query
+ * @param keykey to look up
+ * @param expected expected value.
+ * @param expectedSource string required to be in the property source string
+ */
+ private def assertConfigMatches(
+hadoopConf: Configuration,
+key: String,
+expected: String,
+expectedSource: String): Unit = {
Review Comment:
will need to tweak my scala ide rules, i see
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] steveloughran commented on a diff in pull request #38084: [SPARK-40640][CORE] SparkHadoopUtil to set origin of hadoop/hive config options
steveloughran commented on code in PR #38084:
URL: https://github.com/apache/spark/pull/38084#discussion_r989980702
##
core/src/main/scala/org/apache/spark/deploy/SparkHadoopUtil.scala:
##
@@ -474,40 +498,79 @@ private[spark] object SparkHadoopUtil extends Logging {
private def appendHiveConfigs(hadoopConf: Configuration): Unit = {
hiveConfKeys.foreach { kv =>
- hadoopConf.set(kv.getKey, kv.getValue)
+ hadoopConf.set(kv.getKey, kv.getValue, "Set by Spark from hive-site.xml")
}
}
private def appendSparkHadoopConfigs(conf: SparkConf, hadoopConf:
Configuration): Unit = {
// Copy any "spark.hadoop.foo=bar" spark properties into conf as "foo=bar"
for ((key, value) <- conf.getAll if key.startsWith("spark.hadoop.")) {
- hadoopConf.set(key.substring("spark.hadoop.".length), value)
+ hadoopConf.set(key.substring("spark.hadoop.".length), value,
+"Set by Spark from keys starting with 'spark.hadoop'")
}
+val setBySpark = "Set by Spark to default values"
Review Comment:
happy to
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] steveloughran commented on a diff in pull request #38084: [SPARK-40640][CORE] SparkHadoopUtil to set origin of hadoop/hive config options
steveloughran commented on code in PR #38084:
URL: https://github.com/apache/spark/pull/38084#discussion_r989980574
##
core/src/main/scala/org/apache/spark/deploy/SparkHadoopUtil.scala:
##
@@ -438,26 +440,48 @@ private[spark] object SparkHadoopUtil extends Logging {
// the behavior of the old implementation of this code, for backwards
compatibility.
if (conf != null) {
// Explicitly check for S3 environment variables
- val keyId = System.getenv("AWS_ACCESS_KEY_ID")
- val accessKey = System.getenv("AWS_SECRET_ACCESS_KEY")
- if (keyId != null && accessKey != null) {
-hadoopConf.set("fs.s3.awsAccessKeyId", keyId)
-hadoopConf.set("fs.s3n.awsAccessKeyId", keyId)
-hadoopConf.set("fs.s3a.access.key", keyId)
-hadoopConf.set("fs.s3.awsSecretAccessKey", accessKey)
-hadoopConf.set("fs.s3n.awsSecretAccessKey", accessKey)
-hadoopConf.set("fs.s3a.secret.key", accessKey)
-
-val sessionToken = System.getenv("AWS_SESSION_TOKEN")
-if (sessionToken != null) {
- hadoopConf.set("fs.s3a.session.token", sessionToken)
-}
- }
+ val env: util.Map[String, String] = System.getenv
+ appendS3CredentialsFromEnvironment(hadoopConf, env)
Review Comment:
i want it isolated for testing; we can't set env vars in a unit test, but we
can instead build up a map and verify propagation there.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #38132: [SPARK-40677][CONNECT][BUILD] Shade more dependency to be able to run separately
LuciferYang commented on code in PR #38132:
URL: https://github.com/apache/spark/pull/38132#discussion_r989958977
##
connector/connect/pom.xml:
##
@@ -271,6 +282,31 @@
io.grpc
${spark.shade.packageName}.connect.grpc
+
+
+ com.google.android
Review Comment:
OK~ Maybe do this tomorrow, a little tired today
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #38132: [SPARK-40677][CONNECT][BUILD] Shade more dependency to be able to run separately
HyukjinKwon commented on code in PR #38132:
URL: https://github.com/apache/spark/pull/38132#discussion_r989938384
##
connector/connect/pom.xml:
##
@@ -271,6 +282,31 @@
io.grpc
${spark.shade.packageName}.connect.grpc
+
+
+ com.google.android
Review Comment:
Hey sure, please go ahead with a followup. I just rushed to merge to fix up
the broken tests with Maven :-).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #38132: [SPARK-40677][CONNECT][BUILD] Shade more dependency to be able to run separately
LuciferYang commented on code in PR #38132:
URL: https://github.com/apache/spark/pull/38132#discussion_r989909422
##
connector/connect/pom.xml:
##
@@ -271,6 +282,31 @@
io.grpc
${spark.shade.packageName}.connect.grpc
+
+
+ com.google.android
Review Comment:
@HyukjinKwon Sorry for the late reply
The relocation rule may be incorrect
I think it should be
```
android.annotation
${spark.shade.packageName}.connect.android.annotation
```
and unzip the `assembly` jar, the contents are as follows:
```
ls
META-INF android com google grpc
org spark
```
Not all contents are placed in `${spark.shade.packageName}.connect`, which
may require further check
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a diff in pull request #37887: [SPARK-40360] ALREADY_EXISTS and NOT_FOUND exceptions
MaxGekk commented on code in PR #37887:
URL: https://github.com/apache/spark/pull/37887#discussion_r989885531
##
core/src/main/resources/error/error-classes.json:
##
@@ -536,12 +563,71 @@
"Failed to set original permission back to the created
path: . Exception: "
]
},
+ "ROUTINE_ALREADY_EXISTS" : {
+"message" : [
+ "Cannot create the function because it already exists.",
+ "Choose a different name, drop or replace the existing function, or add
the IF NOT EXISTS clause to tolerate a pre-existing function."
+],
+"sqlState" : "42000"
+ },
+ "ROUTINE_NOT_FOUND" : {
Review Comment:
Why do you name it `ROUTINE...` if SQL key word is `FUNCTION...`. The last
one is even used in the error message. Could you rename to `FUNCTION...` for
consistency, otherwise, please, explain the difference.
##
core/src/main/resources/error/error-classes.json:
##
@@ -346,6 +346,18 @@
}
}
},
+ "INDEX_ALREADY_EXISTS" : {
Review Comment:
Where is it used?
##
core/src/main/resources/error/error-classes.json:
##
@@ -536,12 +563,71 @@
"Failed to set original permission back to the created
path: . Exception: "
]
},
+ "ROUTINE_ALREADY_EXISTS" : {
+"message" : [
+ "Cannot create the function because it already exists.",
+ "Choose a different name, drop or replace the existing function, or add
the IF NOT EXISTS clause to tolerate a pre-existing function."
+],
+"sqlState" : "42000"
+ },
+ "ROUTINE_NOT_FOUND" : {
+"message" : [
+ "The function cannot be found. Verify the spelling and
correctness of the schema and catalog.",
+ "If you did not qualify the name with a schema and catalog, verify the
current_schema() output, or qualify the name with the correct schema and
catalog.",
+ "To tolerate the error on drop use DROP FUNCTION IF EXISTS."
+],
+"sqlState" : "42000"
+ },
+ "SCHEMA_ALREADY_EXISTS" : {
+"message" : [
+ "Cannot create schema because it already exists.",
+ "Choose a different name, drop the existing schema, or add the IF NOT
EXISTS clause to tolerate pre-existing schema."
+],
+"sqlState" : "42000"
+ },
+ "SCHEMA_NOT_EMPTY" : {
+"message" : [
+ "Cannot drop a schema because it contains objects.",
+ "Use DROP SCHEMA ... CASCADE to drop the schema and all its objects."
+],
+"sqlState" : "42000"
+ },
+ "SCHEMA_NOT_FOUND" : {
+"message" : [
+ "The schema cannot be found. Verify the spelling and
correctness of the schema and catalog.",
+ "If you did not qualify the name with a catalog, verify the
current_schema() output, or qualify the name with the correct catalog.",
+ "To tolerate the error on drop use DROP SCHEMA IF EXISTS."
+],
+"sqlState" : "42000"
+ },
"SECOND_FUNCTION_ARGUMENT_NOT_INTEGER" : {
"message" : [
"The second argument of function needs to be an integer."
],
"sqlState" : "22023"
},
+ "TABLE_OR_VIEW_ALREADY_EXISTS" : {
+"message" : [
+ "Cannot create table or view because it already exists.",
+ "Choose a different name, drop or replace the existing object, or add
the IF NOT EXISTS clause to tolerate pre-existing objects."
+],
+"sqlState" : "42000"
+ },
+ "TABLE_OR_VIEW_NOT_FOUND" : {
+"message" : [
+ "The table or view cannot be found. Verify the spelling
and correctness of the schema and catalog.",
+ "If you did not qualify the name with a schema, verify the
current_schema() output, or qualify the name with the correct schema and
catalog.",
+ "To tolerate the error on drop use DROP VIEW IF EXISTS or DROP TABLE IF
EXISTS."
+],
+"sqlState" : "42000"
+ },
+ "TEMP_TABLE_OR_VIEW_ALREADY_EXISTS" : {
+"message" : [
+ "Cannot create the temporary view because it already
exists.",
Review Comment:
The name is about temp **table** or view, but the error message says only
about view.
##
core/src/test/scala/org/apache/spark/SparkFunSuite.scala:
##
@@ -374,6 +382,19 @@ abstract class SparkFunSuite
checkError(exception, errorClass, sqlState, parameters,
matchPVals = true, Array(context))
+ protected def checkErrorTableNotFound(
Review Comment:
Here is the core, right? which is not aware of any tables. Please, move it
from here.
##
core/src/main/resources/error/error-classes.json:
##
@@ -536,12 +563,71 @@
"Failed to set original permission back to the created
path: . Exception: "
]
},
+ "ROUTINE_ALREADY_EXISTS" : {
+"message" : [
+ "Cannot create the function because it already exists.",
+ "Choose a different name, drop or replace the existing function, or add
the IF NOT EXISTS clause to tolerate a pre-existing function."
+],
+"sqlState" : "42000"
+ },
+ "ROUTINE_NOT_FOUND" : {
+"message" : [
+ "The function cannot be found. Verify the spelling
[GitHub] [spark] cloud-fan closed pull request #37994: [SPARK-40454][CONNECT] Initial DSL framework for protobuf testing
cloud-fan closed pull request #37994: [SPARK-40454][CONNECT] Initial DSL framework for protobuf testing URL: https://github.com/apache/spark/pull/37994 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #37994: [SPARK-40454][CONNECT] Initial DSL framework for protobuf testing
cloud-fan commented on PR #37994: URL: https://github.com/apache/spark/pull/37994#issuecomment-1271358433 thanks, merging to master! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #38151: [SPARK-40697][SQL] Add read-side char padding to cover external data files
cloud-fan commented on PR #38151: URL: https://github.com/apache/spark/pull/38151#issuecomment-1271342839 cc @yaooqinn @gengliangwang -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan opened a new pull request, #38151: [SPARK-40697][SQL] Add read-side char padding to cover external data files
cloud-fan opened a new pull request, #38151: URL: https://github.com/apache/spark/pull/38151 ### What changes were proposed in this pull request? The current char/varchar feature relies on the data source to take care of all the write paths and ensure the char/varchar semantic (length check, string padding). This is good for the read performance, but has problems if some write paths did not follow the char/varchar semantic. e.g. a parquet table can be written by old Spark versions that do not have char/varchar type, or by other systems that do not recognize Spark char/varchar type. This PR adds read-side string padding for the char type, so that we can still guarantee the char type semantic if the underlying data is valid (not over length). Char type is rarely used for legacy reasons and the perf doesn't matter that much, correctness is more important here. Note, we don't add read-side length check as varchar type is widely used and we don't want to introduce perf regression for the common case. Another reason is it's better to avoid invalid data at the write side, and read-side check won't help much. ### Why are the changes needed? to better enforce char type semantic ### Does this PR introduce _any_ user-facing change? Yes. Now Spark can still return padding char type values correctly even if the data source writer wrote the char type value without padding. ### How was this patch tested? updated tests -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #38086: [SPARK-40539][CONNECT] Initial DataFrame Read API parity for Spark Connect
zhengruifeng commented on code in PR #38086:
URL: https://github.com/apache/spark/pull/38086#discussion_r989876847
##
python/pyspark/sql/connect/readwriter.py:
##
@@ -31,6 +39,104 @@ class DataFrameReader:
def __init__(self, client: "RemoteSparkSession") -> None:
self._client = client
+self._path = []
+self._format = None
+self._schema = None
+self._options = {}
+
+def format(self, source: str) -> "DataFrameReader":
+"""
+Specifies the input data source format.
+
+.. versionadded:: 3.4.0
+
+Parameters
+--
+source : str
+string, name of the data source, e.g. 'json', 'parquet'.
+
+"""
+self._format = source
+return self
+
+# TODO(SPARK-40539): support StructType in python client and support
schema as StructType.
+def schema(self, schema: str) -> "DataFrameReader":
+"""
+Specifies the input schema.
+
+Some data sources (e.g. JSON) can infer the input schema automatically
from data.
+By specifying the schema here, the underlying data source can skip the
schema
+inference step, and thus speed up data loading.
+
+.. versionadded:: 3.4.0
+
+Parameters
+--
+schema : str
+a DDL-formatted string
+(For example ``col0 INT, col1 DOUBLE``).
+
+"""
+self._schema = schema
+return self
+
+def option(self, key: str, value: "OptionalPrimitiveType") ->
"DataFrameReader":
+"""
+Adds an input option for the underlying data source.
+
+.. versionadded:: 3.4.0
+
+Parameters
+--
+key : str
+The key for the option to set. key string is case-insensitive.
+value
+The value for the option to set.
+
+"""
+self._options[key] = str(value)
+return self
+
+def load(
+self,
+path: Optional[PathOrPaths] = None,
+format: Optional[str] = None,
+schema: Optional[str] = None,
+**options: "OptionalPrimitiveType",
+) -> "DataFrame":
+"""
+Loads data from a data source and returns it as a :class:`DataFrame`.
+
+.. versionadded:: 3.4.0
+
+Parameters
+--
+path : str or list, optional
+optional string or a list of string for file-system backed data
sources.
+format : str, optional
+optional string for format of the data source.
+schema : str, optional
+optional DDL-formatted string (For example ``col0 INT, col1
DOUBLE``).
+**options : dict
+all other string options
+"""
+if format is not None:
+self.format(format)
+if schema is not None:
+self.schema(schema)
+for k in options.keys():
+self.option(k, options.get(k))
+if isinstance(path, str):
+self._path.append(path)
+elif path is not None:
+if type(path) != list:
Review Comment:
```suggestion
if not isinstance(path, list):
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org