[GitHub] [spark] HyukjinKwon commented on pull request #28106: [SPARK-31335][SQL] Add try function support
HyukjinKwon commented on pull request #28106: URL: https://github.com/apache/spark/pull/28106#issuecomment-624456778 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #27473: [SPARK-30699][WIP][ML][PYSPARK] GMM blockify input vectors
AmplabJenkins removed a comment on pull request #27473: URL: https://github.com/apache/spark/pull/27473#issuecomment-624455787 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/122341/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #27473: [SPARK-30699][WIP][ML][PYSPARK] GMM blockify input vectors
AmplabJenkins removed a comment on pull request #27473: URL: https://github.com/apache/spark/pull/27473#issuecomment-624455782 Build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #27473: [SPARK-30699][WIP][ML][PYSPARK] GMM blockify input vectors
SparkQA removed a comment on pull request #27473: URL: https://github.com/apache/spark/pull/27473#issuecomment-624448823 **[Test build #122341 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122341/testReport)** for PR 27473 at commit [`448ed80`](https://github.com/apache/spark/commit/448ed80bf72c56cfa7b25f5174f9e674ab22ddcf). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #27473: [SPARK-30699][WIP][ML][PYSPARK] GMM blockify input vectors
SparkQA commented on pull request #27473: URL: https://github.com/apache/spark/pull/27473#issuecomment-624455749 **[Test build #122341 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122341/testReport)** for PR 27473 at commit [`448ed80`](https://github.com/apache/spark/commit/448ed80bf72c56cfa7b25f5174f9e674ab22ddcf). * This patch **fails MiMa tests**. * This patch **does not merge cleanly**. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #27473: [SPARK-30699][WIP][ML][PYSPARK] GMM blockify input vectors
AmplabJenkins commented on pull request #27473: URL: https://github.com/apache/spark/pull/27473#issuecomment-624455782 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon edited a comment on pull request #28445: [SPARK-31212][SQL][2.4] Fix Failure of casting the '1000-02-29' string to the date type
HyukjinKwon edited a comment on pull request #28445: URL: https://github.com/apache/spark/pull/28445#issuecomment-624455200 Okay, I had some time to investigate the related items here. I think there are some more places to fix, e.g. [here](https://github.com/apache/spark/blob/branch-2.4/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/DateTimeUtils.scala#L610). Let's don't fix these in branch-2.4 only because: - These were "fixed" in the master branch by switching the calendar. I think we should take this fix was superseded by it in the master. We can't backport it to branch-2.4 because it's too much breaking change, though. - It's pretty risky. Given the history of fixing it in the master, fixing one caused a bunch of other related issues. These new issues have been fixed and found over one year, and it's still in progress. I would like to avoid to keep fixing by completely different approaches in 2.4 compared to 3.0. - It will causes a bunch of behaviour changes. Yes, these will be bug fixes but I tend to be more conservative. See also [Bug compatibility](https://en.wikipedia.org/wiki/Bug_compatibility). Considering these risks, let's don't land these fixes. We can more conservatively just document these in Spark 2.4 specifically given the potential maintenance overhead and technical difficulty, if we should. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon edited a comment on pull request #28445: [SPARK-31212][SQL][2.4] Fix Failure of casting the '1000-02-29' string to the date type
HyukjinKwon edited a comment on pull request #28445: URL: https://github.com/apache/spark/pull/28445#issuecomment-624455200 Okay, I had some time to investigate the related items here. I think there are some more places to fix, e.g. [here](https://github.com/apache/spark/blob/branch-2.4/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/DateTimeUtils.scala#L610). Let's don't fix these in branch-2.4 only because: - These were "fixed" in the master branch by switching the calendar. I think we should take this fix was superseded by it in the master. We can't backport it to branch-2.4 because it's too much breaking change, though. - It's pretty risky. Given the history of fixing it in the master, fixing one caused a bunch of other related issues. These new issues have been fixed and found over one year, and it's still in progress. I would like to avoid to keep fixing by completely different approaches in 2.4 compared to 3.0. - It will causes a bunch of behaviour changes. Yes, these will be bug fixes but I tend to be more conservative. See also [Bug compatibility](https://en.wikipedia.org/wiki/Bug_compatibility). Considering these risks, let's don't land these fixes. We can more conservatively just document these in Spark 2.4 specifically given the potential maintenance overhead and technical difficulty. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #28445: [SPARK-31212][SQL][2.4] Fix Failure of casting the '1000-02-29' string to the date type
HyukjinKwon commented on pull request #28445: URL: https://github.com/apache/spark/pull/28445#issuecomment-624455200 Okay, I had some time to investigate the related items here. I think there are some more places to fix, e.g. [here](https://github.com/apache/spark/blob/branch-2.4/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/DateTimeUtils.scala#L610). Let's don't fix these in branch-2.4 only because: - These were "fixed" in the master branch by switching the calendar. I think we should take this fix was superseded by it in the master. We can't backport it to branch-2.4 because it's too much breaking change, though. - It's pretty risky. Given the history of fixing it in the master, fixing one caused a bunch of other related issues. These new issues have been fixed and found over one year, and it's still in progress. I would like to avoid to keep fixing by completely different approaches in 2.4 and 3.0. - It will causes a bunch of behaviour changes. Yes, these will be bug fixes but I tend to be more conservative. See also [Bug compatibility](https://en.wikipedia.org/wiki/Bug_compatibility). Considering these risks, let's don't land these fixes. We can more conservatively just document these in Spark 2.4 specifically given the potential maintenance overhead and technical difficulty. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
AmplabJenkins removed a comment on pull request #28458: URL: https://github.com/apache/spark/pull/28458#issuecomment-624454747 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/122338/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
AmplabJenkins removed a comment on pull request #28458: URL: https://github.com/apache/spark/pull/28458#issuecomment-624454742 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
AmplabJenkins commented on pull request #28458: URL: https://github.com/apache/spark/pull/28458#issuecomment-624454742 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
SparkQA removed a comment on pull request #28458: URL: https://github.com/apache/spark/pull/28458#issuecomment-624436741 **[Test build #122338 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122338/testReport)** for PR 28458 at commit [`0577bb2`](https://github.com/apache/spark/commit/0577bb2c4c94b61ec9e09ab40b8dceca4e02584c). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
SparkQA commented on pull request #28458: URL: https://github.com/apache/spark/pull/28458#issuecomment-624454509 **[Test build #122338 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122338/testReport)** for PR 28458 at commit [`0577bb2`](https://github.com/apache/spark/commit/0577bb2c4c94b61ec9e09ab40b8dceca4e02584c). * This patch **fails PySpark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #26624: [SPARK-8981][CORE][test-hadoop3.2][test-java11] Add MDC support in Executor
cloud-fan commented on a change in pull request #26624:
URL: https://github.com/apache/spark/pull/26624#discussion_r420557946
##
File path: core/src/main/scala/org/apache/spark/util/ThreadUtils.scala
##
@@ -157,23 +259,23 @@ private[spark] object ThreadUtils {
*/
def newDaemonFixedThreadPool(nThreads: Int, prefix: String):
ThreadPoolExecutor = {
val threadFactory = namedThreadFactory(prefix)
-Executors.newFixedThreadPool(nThreads,
threadFactory).asInstanceOf[ThreadPoolExecutor]
+MDCAwareThreadPoolExecutor.newFixedThreadPool(nThreads, threadFactory)
Review comment:
After a second thought, I'm wondering what's the use case for this
change.
For example, `newDaemonFixedThreadPool` is used in `TaskResultGetter`. I
don't think we can get MDC properties there. In fact, we only set the MDC
properties in `Executor.run`, and these thread pools are mostly created by the
driver.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #27473: [SPARK-30699][WIP][ML][PYSPARK] GMM blockify input vectors
AmplabJenkins removed a comment on pull request #27473: URL: https://github.com/apache/spark/pull/27473#issuecomment-624450968 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #27473: [SPARK-30699][WIP][ML][PYSPARK] GMM blockify input vectors
AmplabJenkins commented on pull request #27473: URL: https://github.com/apache/spark/pull/27473#issuecomment-624450975 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/27009/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #27473: [SPARK-30699][WIP][ML][PYSPARK] GMM blockify input vectors
SparkQA commented on pull request #27473: URL: https://github.com/apache/spark/pull/27473#issuecomment-624450647 **[Test build #122342 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122342/testReport)** for PR 27473 at commit [`473e5a2`](https://github.com/apache/spark/commit/473e5a20d23555cf2b22fb6da51175efb891538b). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #27473: [SPARK-30699][WIP][ML][PYSPARK] GMM blockify input vectors
AmplabJenkins removed a comment on pull request #27473: URL: https://github.com/apache/spark/pull/27473#issuecomment-624449141 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28459: [SPARK-31647][SQL] Deprecate 'spark.sql.optimizer.metadataOnly' configuration
AmplabJenkins removed a comment on pull request #28459: URL: https://github.com/apache/spark/pull/28459#issuecomment-624449133 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28425: [SPARK-31480][SQL] Improve the EXPLAIN FORMATTED's output for DSV2's Scan Node
AmplabJenkins removed a comment on pull request #28425: URL: https://github.com/apache/spark/pull/28425#issuecomment-624449089 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28425: [SPARK-31480][SQL] Improve the EXPLAIN FORMATTED's output for DSV2's Scan Node
AmplabJenkins commented on pull request #28425: URL: https://github.com/apache/spark/pull/28425#issuecomment-624449089 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng removed a comment on pull request #27473: [SPARK-30699][WIP][ML][PYSPARK] GMM blockify input vectors
zhengruifeng removed a comment on pull request #27473:
URL: https://github.com/apache/spark/pull/27473#issuecomment-582765435
data: `a9a`: numFeatures=123, numInstances=32,561
testCode:
```scala
import org.apache.spark.ml.clustering._
import org.apache.spark.storage.StorageLevel
import org.apache.spark.ml.linalg._
val df = spark.read.format("libsvm").load("/data1/Datasets/a9a/a9a")
df.persist(StorageLevel.MEMORY_AND_DISK)
df.count
new GaussianMixture().fit(df)
val results = Seq(2, 8, 32).map { k => val start = System.currentTimeMillis;
val model = new
GaussianMixture().setK(k).setSeed(0).setTol(0).setMaxIter(20).fit(df); val dur
= System.currentTimeMillis - start; (model, dur) }
results.map(_._2)
results.map(_._1.summary.numIter)
results.map(_._1.summary.logLikelihood)
results.map(t => t._2.toDouble / t._1.summary.numIter)
```
result:
|Impl| This PR(k=2) | This PR(k=8) | This PR(k=32) | Master(k=2) |
Master(k=8) | Master(k=32) |
|--|--||--||--|--|
|numIter|3|3|5|3|8|4|
|logLikelihood|2814835.470027733|2817523.6371536762|2820228.372200876|2814835.4700277536|2817523.6371535994|2820228.3722007386|
|dur per iteration| 950.0 | 2744.5 | 9780.6 | 1192.7
| 3446.375| 15724.75 |
With NativeBLAS with OPENBLAS_NUM_THREADS=1:
|Impl| This PR(k=2) | This PR(k=8) | This PR(k=32) | Master(k=2) |
Master(k=8) | Master(k=32) |
|--|--||--||--|--|
|numIter|3|3|20|3|20|8|
|logLikelihood|2814835.4700277243 | 2817523.6371536693 |
2820228.372200879|2814835.4700277452|2817523.6371535957|2820228.372200736|
|dur per iteration| 780.0| 2356.5 | 8192.95 | 1183.0 | 3022.1 |
13073.75 |
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #27473: [SPARK-30699][WIP][ML][PYSPARK] GMM blockify input vectors
AmplabJenkins commented on pull request #27473: URL: https://github.com/apache/spark/pull/27473#issuecomment-624449141 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28459: [SPARK-31647][SQL] Deprecate 'spark.sql.optimizer.metadataOnly' configuration
AmplabJenkins commented on pull request #28459: URL: https://github.com/apache/spark/pull/28459#issuecomment-624449133 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28425: [SPARK-31480][SQL] Improve the EXPLAIN FORMATTED's output for DSV2's Scan Node
SparkQA commented on pull request #28425: URL: https://github.com/apache/spark/pull/28425#issuecomment-624448806 **[Test build #122340 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122340/testReport)** for PR 28425 at commit [`7468251`](https://github.com/apache/spark/commit/746825139c345192086492e8e256752c30d3e101). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #27473: [SPARK-30699][WIP][ML][PYSPARK] GMM blockify input vectors
SparkQA commented on pull request #27473: URL: https://github.com/apache/spark/pull/27473#issuecomment-624448823 **[Test build #122341 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122341/testReport)** for PR 27473 at commit [`448ed80`](https://github.com/apache/spark/commit/448ed80bf72c56cfa7b25f5174f9e674ab22ddcf). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28459: [SPARK-31647][SQL] Deprecate 'spark.sql.optimizer.metadataOnly' configuration
SparkQA commented on pull request #28459: URL: https://github.com/apache/spark/pull/28459#issuecomment-624448813 **[Test build #122339 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122339/testReport)** for PR 28459 at commit [`34420fb`](https://github.com/apache/spark/commit/34420fb12fcfd64e345c8487beef9c05d39b10bc). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng opened a new pull request #27473: [SPARK-30699][WIP][ML][PYSPARK] GMM blockify input vectors
zhengruifeng opened a new pull request #27473: URL: https://github.com/apache/spark/pull/27473 ### What changes were proposed in this pull request? 1, add Level-2 BLAS routine `ger`; 2, stack input vectors to blocks to use Level-3 BLAS routine in training ### Why are the changes needed? for performance: 1, save about 40% RAM; 2, 25% ~ 60% faster; 30% ~ 60% faster with openBLAS ### Does this PR introduce any user-facing change? add a new expert param `blockSize` ### How was this patch tested? added testsuites This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng edited a comment on pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
zhengruifeng edited a comment on pull request #28458:
URL: https://github.com/apache/spark/pull/28458#issuecomment-624427337
performace test on **sparse dataset**: the first 10,000 instances of
`webspam_wc_normalized_trigram`
code:
```scala
val df = spark.read.option("numFeatures",
"8289919").format("libsvm").load("/data1/Datasets/webspam/webspam_wc_normalized_trigram.svm.10k").withColumn("label",
(col("label")+1)/2)
df.persist(StorageLevel.MEMORY_AND_DISK)
df.count
val lr = new LogisticRegression().setBlockSize(1).setMaxIter(10)
lr.fit(df)
val results = Seq(1, 4, 16, 64, 256, 1024, 4096).map { size => val start =
System.currentTimeMillis; val model = lr.setBlockSize(size).fit(df); val end =
System.currentTimeMillis; (size, model.coefficients, end - start) }
```
results:
```
scala> results.map(_._3)
res17: Seq[Long] = List(33948, 425923, 129811, 56288, 47587, 42816, 39809)
scala> results.map(_._2).foreach(coef => println(coef.toString.take(100)))
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
scala> results.map(_._2).foreach(coef =>
println(coef.toString.takeRight(100)))
87,-1188.1053920127556,335.5565308836645,-135.79302172669907,849.0515530033497,-27.040836637047736])
91,-1188.105392012755,335.55653088366444,-135.79302172669907,849.0515530033497,-27.040836637047736])
9,-1188.1053920127551,335.55653088366444,-135.79302172669904,849.0515530033495,-27.040836637047725])
94,-1188.1053920127556,335.55653088366444,-135.79302172669904,849.0515530033495,-27.04083663704773])
1,-1188.1053920127551,335.55653088366444,-135.79302172669904,849.0515530033493,-27.040836637047722])
5,-1188.1053920127556,335.55653088366444,-135.79302172669904,849.0515530033495,-27.040836637047736])
29,-1188.105392012756,335.55653088366444,-135.79302172669904,849.0515530033495,-27.040836637047736])
```
**blockSize==1**
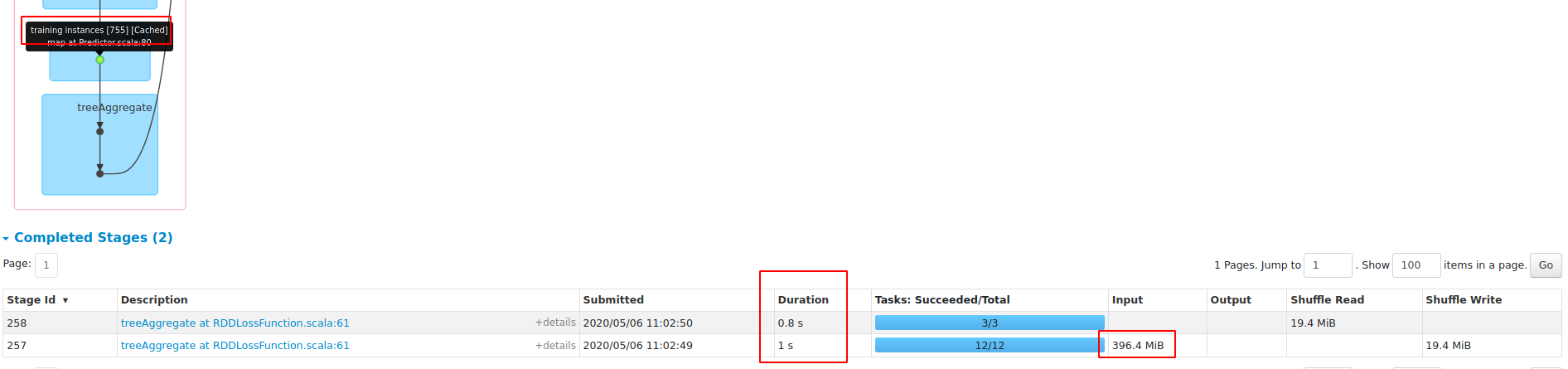
**blockSize=16**
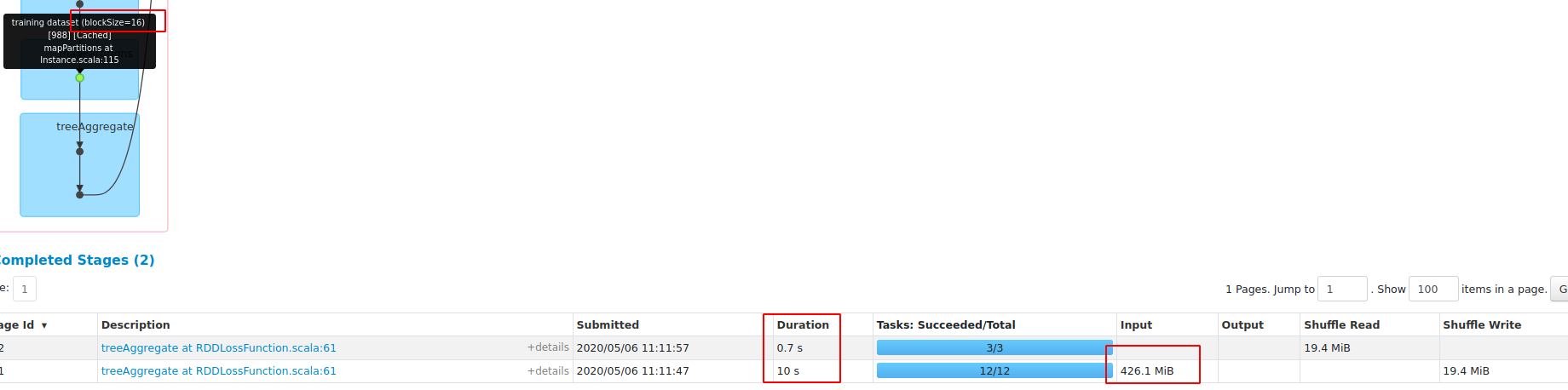
test with **Master**:
```
import org.apache.spark.ml.classification._
import org.apache.spark.storage.StorageLevel
val df = spark.read.option("numFeatures",
"8289919").format("libsvm").load("/data1/Datasets/webspam/webspam_wc_normalized_trigram.svm.10k").withColumn("label",
(col("label")+1)/2)
df.persist(StorageLevel.MEMORY_AND_DISK)
df.count
val lr = new LogisticRegression().setMaxIter(10)
lr.fit(df)
val start = System.currentTimeMillis; val model = lr.setMaxIter(10).fit(df);
val end = System.currentTimeMillis; end - start
scala> val start = System.currentTimeMillis; val model =
lr.setMaxIter(10).fit(df); val end = System.currentTimeMillis; end - start
start: Long = 1588735447883
model: org.apache.spark.ml.classification.LogisticRegressionModel =
LogisticRegressionModel: uid=logreg_99d29a0ecc13, numClasses=2,
numFeatures=8289919
end: Long = 1588735483170
res3: Long = 35287
```
In this PR, when blockSize==1, the duration is 33948, so there will be no
performance regression on sparse datasets.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dilipbiswal commented on a change in pull request #28425: [SPARK-31480][SQL] Improve the EXPLAIN FORMATTED's output for DSV2's Scan Node
dilipbiswal commented on a change in pull request #28425:
URL: https://github.com/apache/spark/pull/28425#discussion_r420550918
##
File path: sql/core/src/test/scala/org/apache/spark/sql/ExplainSuite.scala
##
@@ -343,6 +343,54 @@ class ExplainSuite extends ExplainSuiteHelper with
DisableAdaptiveExecutionSuite
assert(getNormalizedExplain(df1, FormattedMode) ===
getNormalizedExplain(df2, FormattedMode))
}
}
+
+ test("Explain formatted output for scan operator for datasource V2") {
Review comment:
+1. Thank you.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] baohe-zhang commented on pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
baohe-zhang commented on pull request #28412: URL: https://github.com/apache/spark/pull/28412#issuecomment-624445143 Another way is to keep a thread-safe variable called availableMemory in FsHistoryProvider. The initial value can be set as a percentage of Xmx. When we parse a file via hybrid kvstore, we subtract an approximate memory usage from availableMemory, and when the hybrid store switches to leveldb, we add back this approximate memory usage. When availableMemory is below a threshold, we can disable hybridKVstore. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a change in pull request #28459: [SPARK-31647][SQL] Deprecate 'spark.sql.optimizer.metadataOnly' configuration
gengliangwang commented on a change in pull request #28459:
URL: https://github.com/apache/spark/pull/28459#discussion_r420545275
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##
@@ -845,8 +845,9 @@ object SQLConf {
.doc("When true, enable the metadata-only query optimization that use the
table's metadata " +
"to produce the partition columns instead of table scans. It applies
when all the columns " +
"scanned are partition columns and the query has an aggregate operator
that satisfies " +
- "distinct semantics. By default the optimization is disabled, since it
may return " +
- "incorrect results when the files are empty.")
+ "distinct semantics. By default the optimization is disabled, and
deprecated as of Spark " +
Review comment:
nit: could you add this note in the comment of the rule as well?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
HeartSaVioR commented on pull request #28412: URL: https://github.com/apache/spark/pull/28412#issuecomment-624441325 I'm not sure that's fairly simple to do. Concurrent load of applications can be happening in SHS, right? The default value of `spark.history.retainedApplications` is 50, which means maximum 50 apps can be loaded into cache at the same time. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #28366: [SPARK-31365][SQL] Enable nested predicate pushdown per data sources
cloud-fan commented on pull request #28366: URL: https://github.com/apache/spark/pull/28366#issuecomment-624439850 thanks, merging to master/3.0! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] baohe-zhang commented on pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
baohe-zhang commented on pull request #28412: URL: https://github.com/apache/spark/pull/28412#issuecomment-624439430 @HeartSaVioR One way in my mind is that we can monitor the memory usage of SHS. If the memory usage or event log size exceeds a threshold (e.g, over 50% of Xmx), we can use leveldb to parse event log, instead of hybrid kvstore. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #28425: [SPARK-31480][SQL] Improve the EXPLAIN FORMATTED's output for DSV2's Scan Node
cloud-fan commented on a change in pull request #28425:
URL: https://github.com/apache/spark/pull/28425#discussion_r420540911
##
File path: sql/core/src/test/scala/org/apache/spark/sql/ExplainSuite.scala
##
@@ -343,6 +343,54 @@ class ExplainSuite extends ExplainSuiteHelper with
DisableAdaptiveExecutionSuite
assert(getNormalizedExplain(df1, FormattedMode) ===
getNormalizedExplain(df2, FormattedMode))
}
}
+
+ test("Explain formatted output for scan operator for datasource V2") {
Review comment:
Oh I see. Currently DS v2 scan is enabled only in `DataFrameReader`, so
we can't get it through pure SQL. Then this is fine.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28456: [SPARK-31235][YARN] Fix test "specify a more specific type for the ap…
AmplabJenkins removed a comment on pull request #28456: URL: https://github.com/apache/spark/pull/28456#issuecomment-624437356 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28456: [SPARK-31235][YARN] Fix test "specify a more specific type for the ap…
AmplabJenkins commented on pull request #28456: URL: https://github.com/apache/spark/pull/28456#issuecomment-624437356 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28456: [SPARK-31235][YARN] Fix test "specify a more specific type for the ap…
SparkQA removed a comment on pull request #28456: URL: https://github.com/apache/spark/pull/28456#issuecomment-624431979 **[Test build #122337 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122337/testReport)** for PR 28456 at commit [`fd08a7a`](https://github.com/apache/spark/commit/fd08a7a8bfd98a916bda4cc4d60d74a3c02f4e26). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28456: [SPARK-31235][YARN] Fix test "specify a more specific type for the ap…
SparkQA commented on pull request #28456: URL: https://github.com/apache/spark/pull/28456#issuecomment-624437271 **[Test build #122337 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122337/testReport)** for PR 28456 at commit [`fd08a7a`](https://github.com/apache/spark/commit/fd08a7a8bfd98a916bda4cc4d60d74a3c02f4e26). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
AmplabJenkins removed a comment on pull request #28458: URL: https://github.com/apache/spark/pull/28458#issuecomment-624437029 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
AmplabJenkins commented on pull request #28458: URL: https://github.com/apache/spark/pull/28458#issuecomment-624437029 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #28393: [SPARK-31595][SQL] Spark sql should allow unescaped quote mark in quoted string
cloud-fan commented on pull request #28393: URL: https://github.com/apache/spark/pull/28393#issuecomment-624436648 thanks, merging to master/3.0! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
SparkQA commented on pull request #28458: URL: https://github.com/apache/spark/pull/28458#issuecomment-624436741 **[Test build #122338 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122338/testReport)** for PR 28458 at commit [`0577bb2`](https://github.com/apache/spark/commit/0577bb2c4c94b61ec9e09ab40b8dceca4e02584c). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #28393: [SPARK-31595][SQL] Spark sql should allow unescaped quote mark in quoted string
cloud-fan commented on pull request #28393: URL: https://github.com/apache/spark/pull/28393#issuecomment-624436428 cc @juliuszsompolski as well This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] erenavsarogullari edited a comment on pull request #28208: [SPARK-31440][SQL] Improve SQL Rest API
erenavsarogullari edited a comment on pull request #28208: URL: https://github.com/apache/spark/pull/28208#issuecomment-624435102 @gengliangwang There is optional Http parameter: `details` (default: `false`). It needs to be set in order to fetch `node`, `edge` and `planDescription` details as well: `http://localhost:4040/api/v1/applications//sql/0?details=true` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] erenavsarogullari commented on pull request #28208: [SPARK-31440][SQL] Improve SQL Rest API
erenavsarogullari commented on pull request #28208: URL: https://github.com/apache/spark/pull/28208#issuecomment-624435102 @gengliangwang There is optional http parameter: `details` (default: `false`). It needs to be set in order to fetch `node`, `edge` and `planDescription` details as well: `http://localhost:4040/api/v1/applications//sql/0?details=true` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
HeartSaVioR commented on pull request #28412: URL: https://github.com/apache/spark/pull/28412#issuecomment-624434103 Let's discuss first with the plan how to address the major concerns in comments, especially how to restrict the overall memory usage. I think that's a blocker for the production use. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #28442: [SPARK-31631][TESTS] Fix test flakiness caused by MiniKdc which throws 'address in use' BindException with retry
HyukjinKwon commented on a change in pull request #28442:
URL: https://github.com/apache/spark/pull/28442#discussion_r420536516
##
File path:
external/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/KafkaTestUtils.scala
##
@@ -131,11 +130,7 @@ class KafkaTestUtils(
}
private def setUpMiniKdc(): Unit = {
-val kdcDir = Utils.createTempDir()
Review comment:
Yeah, can we just use `eventually` instead of having another class? This
is in the guide, see also
https://github.com/databricks/scala-style-guide#misc_well_tested_method
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28456: [SPARK-31235][YARN] Fix test "specify a more specific type for the ap…
SparkQA commented on pull request #28456: URL: https://github.com/apache/spark/pull/28456#issuecomment-624431979 **[Test build #122337 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122337/testReport)** for PR 28456 at commit [`fd08a7a`](https://github.com/apache/spark/commit/fd08a7a8bfd98a916bda4cc4d60d74a3c02f4e26). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28459: [SPARK-31647][SQL] Deprecate 'spark.sql.optimizer.metadataOnly' configuration
AmplabJenkins removed a comment on pull request #28459: URL: https://github.com/apache/spark/pull/28459#issuecomment-624430843 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28459: [SPARK-31647][SQL] Deprecate 'spark.sql.optimizer.metadataOnly' configuration
AmplabJenkins commented on pull request #28459: URL: https://github.com/apache/spark/pull/28459#issuecomment-624430843 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28459: [SPARK-31647][SQL] Deprecate 'spark.sql.optimizer.metadataOnly' configuration
SparkQA commented on pull request #28459: URL: https://github.com/apache/spark/pull/28459#issuecomment-624430556 **[Test build #122336 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122336/testReport)** for PR 28459 at commit [`39c1b3c`](https://github.com/apache/spark/commit/39c1b3c22e2e00b96e0cef6efed46070b833917b). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #28459: [SPARK-31647][SQL] Deprecate 'spark.sql.optimizer.metadataOnly' configuration
HyukjinKwon commented on a change in pull request #28459:
URL: https://github.com/apache/spark/pull/28459#discussion_r420533700
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##
@@ -2605,7 +2606,10 @@ object SQLConf {
DeprecatedConfig(ARROW_FALLBACK_ENABLED.key, "3.0",
s"Use '${ARROW_PYSPARK_FALLBACK_ENABLED.key}' instead of it."),
DeprecatedConfig(SHUFFLE_TARGET_POSTSHUFFLE_INPUT_SIZE.key, "3.0",
-s"Use '${ADVISORY_PARTITION_SIZE_IN_BYTES.key}' instead of it.")
+s"Use '${ADVISORY_PARTITION_SIZE_IN_BYTES.key}' instead of it."),
+ DeprecatedConfig(OPTIMIZER_METADATA_ONLY.key, "3.0",
Review comment:
Technically we shouldn't necessarily go through deprecation to remove as
it's an internal configuration but let me stay conservative here by deprecating
first.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #28459: [SPARK-31647][SQL] Deprecate 'spark.sql.optimizer.metadataOnly' configuration
HyukjinKwon commented on a change in pull request #28459:
URL: https://github.com/apache/spark/pull/28459#discussion_r420533700
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##
@@ -2605,7 +2606,10 @@ object SQLConf {
DeprecatedConfig(ARROW_FALLBACK_ENABLED.key, "3.0",
s"Use '${ARROW_PYSPARK_FALLBACK_ENABLED.key}' instead of it."),
DeprecatedConfig(SHUFFLE_TARGET_POSTSHUFFLE_INPUT_SIZE.key, "3.0",
-s"Use '${ADVISORY_PARTITION_SIZE_IN_BYTES.key}' instead of it.")
+s"Use '${ADVISORY_PARTITION_SIZE_IN_BYTES.key}' instead of it."),
+ DeprecatedConfig(OPTIMIZER_METADATA_ONLY.key, "3.0",
Review comment:
Technically we shouldn't go through deprecation to remove as it's an
internal configuration but let me stay conservative here by deprecating first.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon opened a new pull request #28459: [SPARK-31647][SQL] Deprecate 'spark.sql.optimizer.metadataOnly' configuration
HyukjinKwon opened a new pull request #28459:
URL: https://github.com/apache/spark/pull/28459
### What changes were proposed in this pull request?
This PR proposes to deprecate 'spark.sql.optimizer.metadataOnly'
configuration and remove it in the future release.
### Why are the changes needed?
This optimization can cause a potential correctness issue, see also
SPARK-26709.
Also, it seems difficult to extend the optimization. Basically you should
whitelist all available functions. It costs some maintenance overhead, see also
SPARK-31590.
Looks we should just better let users use `SparkSessionExtensions` instead
if they must use, and remove it in Spark side.
### Does this PR introduce _any_ user-facing change?
Yes, setting `spark.sql.optimizer.metadataOnly` will shod a deprecation
warning:
```scala
scala> spark.conf.unset("spark.sql.optimizer.metadataOnly")
```
```
20/05/06 12:57:23 WARN SQLConf: The SQL config
'spark.sql.optimizer.metadataOnly' has been
deprecated in Spark v3.0 and may be removed in the future. Avoid to depend
on this optimization
to prevent a potential correctness issue. If you must use, use
'SparkSessionExtensions' instead to
inject it as a custom rule.
```
```scala
scala> spark.conf.set("spark.sql.optimizer.metadataOnly", "true")
```
```
20/05/06 12:57:44 WARN SQLConf: The SQL config
'spark.sql.optimizer.metadataOnly' has been
deprecated in Spark v3.0 and may be removed in the future. Avoid to depend
on this optimization
to prevent a potential correctness issue.If you must use, use
'SparkSessionExtensions' instead to
inject it as a custom rule.
```
### How was this patch tested?
Manually tested.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
AmplabJenkins removed a comment on pull request #28458: URL: https://github.com/apache/spark/pull/28458#issuecomment-624428995 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/122334/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
SparkQA commented on pull request #28412: URL: https://github.com/apache/spark/pull/28412#issuecomment-624429091 **[Test build #122335 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122335/testReport)** for PR 28412 at commit [`141feed`](https://github.com/apache/spark/commit/141feed4a2537ff0481e4d03abad858df3540777). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
AmplabJenkins removed a comment on pull request #28458: URL: https://github.com/apache/spark/pull/28458#issuecomment-624428988 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
SparkQA removed a comment on pull request #28458: URL: https://github.com/apache/spark/pull/28458#issuecomment-624426364 **[Test build #122334 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122334/testReport)** for PR 28458 at commit [`563cee9`](https://github.com/apache/spark/commit/563cee9e8a2edd2a0f1025de531002488de1e63a). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
SparkQA commented on pull request #28458: URL: https://github.com/apache/spark/pull/28458#issuecomment-624428969 **[Test build #122334 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122334/testReport)** for PR 28458 at commit [`563cee9`](https://github.com/apache/spark/commit/563cee9e8a2edd2a0f1025de531002488de1e63a). * This patch **fails to generate documentation**. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * ` instr.logWarning(s\"All labels belong to a single class and fitIntercept=false. It's a \" +` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
AmplabJenkins commented on pull request #28458: URL: https://github.com/apache/spark/pull/28458#issuecomment-624428988 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
AmplabJenkins removed a comment on pull request #28412: URL: https://github.com/apache/spark/pull/28412#issuecomment-624428013 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] baohe-zhang commented on a change in pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
baohe-zhang commented on a change in pull request #28412:
URL: https://github.com/apache/spark/pull/28412#discussion_r420531106
##
File path:
core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala
##
@@ -1167,6 +1168,58 @@ private[history] class FsHistoryProvider(conf:
SparkConf, clock: Clock)
// At this point the disk data either does not exist or was deleted
because it failed to
// load, so the event log needs to be replayed.
+// TODO: Maybe need to do other check to see if there's enough memory to
+// use inMemoryStore.
+if (hybridKVStoreEnabled) {
+ logInfo("Using HybridKVStore as KVStore")
+ var retried = false
+ var store: HybridKVStore = null
+ while(store == null) {
+val reader = EventLogFileReader(fs, new Path(logDir, attempt.logPath),
+ attempt.lastIndex)
+val isCompressed = reader.compressionCodec.isDefined
+logInfo(s"Leasing disk manager space for app $appId /
${attempt.info.attemptId}...")
+val lease = dm.lease(reader.totalSize, isCompressed)
+try {
+ val s = new HybridKVStore()
+ val levelDB = KVUtils.open(lease.tmpPath, metadata)
+ s.setLevelDB(levelDB)
+
+ s.startBackgroundThreadToWriteToDB(new
HybridKVStore.SwitchingToLevelDBListener {
+override def onSwitchingToLevelDBSuccess: Unit = {
+ levelDB.close()
+ val newStorePath = lease.commit(appId, attempt.info.attemptId)
+ s.setLevelDB(KVUtils.open(newStorePath, metadata))
+ logInfo(s"Completely switched to use leveldb for app" +
+ s" $appId / ${attempt.info.attemptId}")
+}
+
+override def onSwitchingToLevelDBFail(e: Exception): Unit = {
+ logWarning(s"Failed to switch to use LevelDb for app" +
+ s" $appId / ${attempt.info.attemptId}")
+ levelDB.close()
+ throw e
Review comment:
1 is addressed.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
AmplabJenkins commented on pull request #28412: URL: https://github.com/apache/spark/pull/28412#issuecomment-624428013 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] baohe-zhang commented on a change in pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
baohe-zhang commented on a change in pull request #28412:
URL: https://github.com/apache/spark/pull/28412#discussion_r420530840
##
File path: core/src/main/scala/org/apache/spark/internal/config/History.scala
##
@@ -195,4 +195,9 @@ private[spark] object History {
.version("3.0.0")
.booleanConf
.createWithDefault(true)
+
+ val HYBRID_KVSTORE_ENABLED =
ConfigBuilder("spark.history.store.hybridKVStore.enabled")
+.version("3.0.1")
Review comment:
Addressed.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
zhengruifeng commented on pull request #28458:
URL: https://github.com/apache/spark/pull/28458#issuecomment-624427337
performace test on the first 10,000 instances of
`webspam_wc_normalized_trigram`
code:
```scala
val df = spark.read.option("numFeatures",
"8289919").format("libsvm").load("/data1/Datasets/webspam/webspam_wc_normalized_trigram.svm.10k").withColumn("label",
(col("label")+1)/2)
df.persist(StorageLevel.MEMORY_AND_DISK)
df.count
val lr = new LogisticRegression().setBlockSize(1).setMaxIter(10)
lr.fit(df)
val results = Seq(1, 4, 16, 64, 256, 1024, 4096).map { size => val start =
System.currentTimeMillis; val model = lr.setBlockSize(size).fit(df); val end =
System.currentTimeMillis; (size, model.coefficients, end - start) }
```
results:
```
scala> results.map(_._3)
res17: Seq[Long] = List(33948, 425923, 129811, 56288, 47587, 42816, 39809)
scala> results.map(_._2).foreach(coef => println(coef.toString.take(100)))
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
scala> results.map(_._2).foreach(coef =>
println(coef.toString.takeRight(100)))
87,-1188.1053920127556,335.5565308836645,-135.79302172669907,849.0515530033497,-27.040836637047736])
91,-1188.105392012755,335.55653088366444,-135.79302172669907,849.0515530033497,-27.040836637047736])
9,-1188.1053920127551,335.55653088366444,-135.79302172669904,849.0515530033495,-27.040836637047725])
94,-1188.1053920127556,335.55653088366444,-135.79302172669904,849.0515530033495,-27.04083663704773])
1,-1188.1053920127551,335.55653088366444,-135.79302172669904,849.0515530033493,-27.040836637047722])
5,-1188.1053920127556,335.55653088366444,-135.79302172669904,849.0515530033495,-27.040836637047736])
29,-1188.105392012756,335.55653088366444,-135.79302172669904,849.0515530033495,-27.040836637047736])
```
**blockSize==1**

**blockSize=16**

test with **Master**:
```
import org.apache.spark.ml.classification._
import org.apache.spark.storage.StorageLevel
val df = spark.read.option("numFeatures",
"8289919").format("libsvm").load("/data1/Datasets/webspam/webspam_wc_normalized_trigram.svm.10k").withColumn("label",
(col("label")+1)/2)
df.persist(StorageLevel.MEMORY_AND_DISK)
df.count
val lr = new LogisticRegression().setMaxIter(10)
lr.fit(df)
val start = System.currentTimeMillis; val model = lr.setMaxIter(10).fit(df);
val end = System.currentTimeMillis; end - start
scala> val start = System.currentTimeMillis; val model =
lr.setMaxIter(10).fit(df); val end = System.currentTimeMillis; end - start
start: Long = 1588735447883
model: org.apache.spark.ml.classification.LogisticRegressionModel =
LogisticRegressionModel: uid=logreg_99d29a0ecc13, numClasses=2,
numFeatures=8289919
end: Long = 1588735483170
res3: Long = 35287
```
In this PR, when blockSize==1, the duration is 33948, so there will be no
performance regression on sparse datasets.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
AmplabJenkins removed a comment on pull request #28458: URL: https://github.com/apache/spark/pull/28458#issuecomment-624426569 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
AmplabJenkins commented on pull request #28458: URL: https://github.com/apache/spark/pull/28458#issuecomment-624426569 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
SparkQA commented on pull request #28458: URL: https://github.com/apache/spark/pull/28458#issuecomment-624426364 **[Test build #122334 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122334/testReport)** for PR 28458 at commit [`563cee9`](https://github.com/apache/spark/commit/563cee9e8a2edd2a0f1025de531002488de1e63a). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
zhengruifeng commented on pull request #28458:
URL: https://github.com/apache/spark/pull/28458#issuecomment-624426340
performace test on
[`epsilon_normalized.t`](https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary.html)
code:
```scala
import org.apache.spark.ml.classification._
import org.apache.spark.storage.StorageLevel
val df = spark.read.option("numFeatures",
"2000").format("libsvm").load("/data1/Datasets/epsilon/epsilon_normalized.t").withColumn("label",
(col("label")+1)/2)
df.persist(StorageLevel.MEMORY_AND_DISK)
df.count
val lr = new LogisticRegression().setBlockSize(1).setMaxIter(10)
lr.fit(df)
val results = Seq(1, 4, 16, 64, 256, 1024, 4096).map { size => val start =
System.currentTimeMillis; val model = lr.setBlockSize(size).fit(df); val end =
System.currentTimeMillis; (size, model.coefficients, end - start) }
```
results:
```
scala> results.map(_._3)
res3: Seq[Long] = List(31076, 6771, 6732, 7590, 7186, 7094, 7276)
scala> results.map(_._2).foreach(coef => println(coef.toString.take(100)))
[2.1557250220880024,-0.22767392418436572,4.569220246330072,0.04739667339597046,0.14605181933865558,-
[2.1557250220880064,-0.22767392418436597,4.56922024633007,0.04739667339596951,0.14605181933865646,-0
[2.1557250220880064,-0.2276739241843657,4.569220246330077,0.04739667339597028,0.14605181933865646,-0
[2.155725022088007,-0.2276739241843664,4.569220246330073,0.047396673395969764,0.14605181933865688,-0
[2.1557250220880038,-0.22767392418436605,4.569220246330073,0.04739667339597022,0.14605181933865458,-
[2.1557250220880033,-0.22767392418436683,4.569220246330072,0.047396673395970035,0.14605181933865727,
[2.1557250220880033,-0.22767392418436613,4.56922024633007,0.0473966733959703,0.1460518193386559,-0.0
```
**blockSize==1**
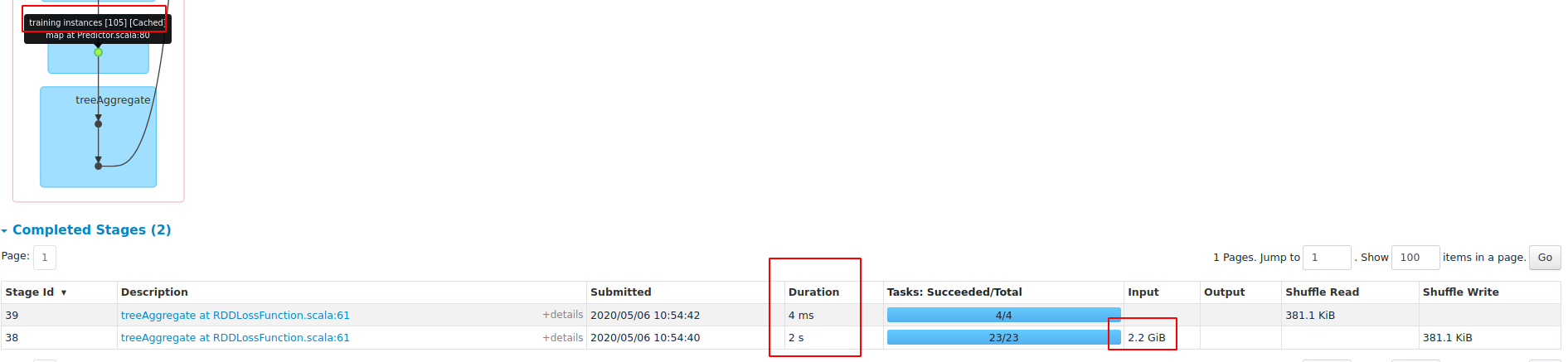
**blockSize==256**

This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng opened a new pull request #28458: [SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors
zhengruifeng opened a new pull request #28458: URL: https://github.com/apache/spark/pull/28458 ### What changes were proposed in this pull request? 1, reorg the `fit` method in LR to several blocks (`createModel`, `createBounds`, `createOptimizer`, `createInitCoefWithInterceptMatrix`); 2, add new param blockSize; 3, if blockSize==1, keep original behavior, code path `trainOnRows`; 4, if blockSize>1, standardize and stack input vectors to blocks (like ALS/MLP), code path `trainOnBlocks` ### Why are the changes needed? On dense dataset `epsilon_normalized.t`: 1, reduce RAM to persist traing dataset; (save about 40% RAM) 2, use Level-2 BLAS routines; (4x ~ 5x faster) ### Does this PR introduce _any_ user-facing change? Yes, a new param is added ### How was this patch tested? existing and added testsuites This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28456: [SPARK-31235][YARN] Fix test "specify a more specific type for the ap…
AmplabJenkins removed a comment on pull request #28456: URL: https://github.com/apache/spark/pull/28456#issuecomment-624425092 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28456: [SPARK-31235][YARN] Fix test "specify a more specific type for the ap…
SparkQA removed a comment on pull request #28456: URL: https://github.com/apache/spark/pull/28456#issuecomment-624419881 **[Test build #122331 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122331/testReport)** for PR 28456 at commit [`42f090c`](https://github.com/apache/spark/commit/42f090cb386dc2e95641ce991e3911b0a60e6f55). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
AmplabJenkins removed a comment on pull request #28412: URL: https://github.com/apache/spark/pull/28412#issuecomment-624425131 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
AmplabJenkins commented on pull request #28412: URL: https://github.com/apache/spark/pull/28412#issuecomment-624425131 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28456: [SPARK-31235][YARN] Fix test "specify a more specific type for the ap…
AmplabJenkins commented on pull request #28456: URL: https://github.com/apache/spark/pull/28456#issuecomment-624425092 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28456: [SPARK-31235][YARN] Fix test "specify a more specific type for the ap…
SparkQA commented on pull request #28456: URL: https://github.com/apache/spark/pull/28456#issuecomment-624425018 **[Test build #122331 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122331/testReport)** for PR 28456 at commit [`42f090c`](https://github.com/apache/spark/commit/42f090cb386dc2e95641ce991e3911b0a60e6f55). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
SparkQA commented on pull request #28412: URL: https://github.com/apache/spark/pull/28412#issuecomment-624424796 **[Test build #122333 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122333/testReport)** for PR 28412 at commit [`34e4564`](https://github.com/apache/spark/commit/34e4564bcf17b1e9875b61445fb4af963af89449). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
AmplabJenkins removed a comment on pull request #28412: URL: https://github.com/apache/spark/pull/28412#issuecomment-624423684 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/122332/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
AmplabJenkins removed a comment on pull request #28412: URL: https://github.com/apache/spark/pull/28412#issuecomment-624423679 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
SparkQA removed a comment on pull request #28412: URL: https://github.com/apache/spark/pull/28412#issuecomment-624423178 **[Test build #122332 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122332/testReport)** for PR 28412 at commit [`e6707bd`](https://github.com/apache/spark/commit/e6707bd61e747131b118b8326d01cba159df614a). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
SparkQA commented on pull request #28412: URL: https://github.com/apache/spark/pull/28412#issuecomment-624423673 **[Test build #122332 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122332/testReport)** for PR 28412 at commit [`e6707bd`](https://github.com/apache/spark/commit/e6707bd61e747131b118b8326d01cba159df614a). * This patch **fails Scala style tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
AmplabJenkins commented on pull request #28412: URL: https://github.com/apache/spark/pull/28412#issuecomment-624423679 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
AmplabJenkins removed a comment on pull request #28412: URL: https://github.com/apache/spark/pull/28412#issuecomment-624423497 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
AmplabJenkins commented on pull request #28412: URL: https://github.com/apache/spark/pull/28412#issuecomment-624423497 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
SparkQA commented on pull request #28412: URL: https://github.com/apache/spark/pull/28412#issuecomment-624423178 **[Test build #122332 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122332/testReport)** for PR 28412 at commit [`e6707bd`](https://github.com/apache/spark/commit/e6707bd61e747131b118b8326d01cba159df614a). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] baohe-zhang commented on a change in pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
baohe-zhang commented on a change in pull request #28412:
URL: https://github.com/apache/spark/pull/28412#discussion_r420525489
##
File path:
core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala
##
@@ -1167,6 +1168,58 @@ private[history] class FsHistoryProvider(conf:
SparkConf, clock: Clock)
// At this point the disk data either does not exist or was deleted
because it failed to
// load, so the event log needs to be replayed.
+// TODO: Maybe need to do other check to see if there's enough memory to
+// use inMemoryStore.
+if (hybridKVStoreEnabled) {
+ logInfo("Using HybridKVStore as KVStore")
+ var retried = false
+ var store: HybridKVStore = null
+ while(store == null) {
+val reader = EventLogFileReader(fs, new Path(logDir, attempt.logPath),
+ attempt.lastIndex)
+val isCompressed = reader.compressionCodec.isDefined
+logInfo(s"Leasing disk manager space for app $appId /
${attempt.info.attemptId}...")
+val lease = dm.lease(reader.totalSize, isCompressed)
+try {
+ val s = new HybridKVStore()
+ val levelDB = KVUtils.open(lease.tmpPath, metadata)
+ s.setLevelDB(levelDB)
+
+ s.startBackgroundThreadToWriteToDB(new
HybridKVStore.SwitchingToLevelDBListener {
+override def onSwitchingToLevelDBSuccess: Unit = {
+ levelDB.close()
+ val newStorePath = lease.commit(appId, attempt.info.attemptId)
+ s.setLevelDB(KVUtils.open(newStorePath, metadata))
+ logInfo(s"Completely switched to use leveldb for app" +
+ s" $appId / ${attempt.info.attemptId}")
+}
+
+override def onSwitchingToLevelDBFail(e: Exception): Unit = {
+ logWarning(s"Failed to switch to use LevelDb for app" +
+ s" $appId / ${attempt.info.attemptId}")
+ levelDB.close()
+ throw e
+}
+ })
+
+ rebuildAppStore(s, reader, attempt.info.lastUpdated.getTime())
+ s.stopBackgroundThreadAndSwitchToLevelDB()
+ store = s
+} catch {
+ case _: IOException if !retried =>
+// compaction may touch the file(s) which app rebuild wants to read
+// compaction wouldn't run in short interval, so try again...
+logWarning(s"Exception occurred while rebuilding app $appId -
trying again...")
+lease.rollback()
Review comment:
Hybrid kvstore is now cleaned up explicitly.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] baohe-zhang commented on a change in pull request #28412: [SPARK-31608][CORE][WEBUI] Add a new type of KVStore to make loading UI faster
baohe-zhang commented on a change in pull request #28412:
URL: https://github.com/apache/spark/pull/28412#discussion_r420524061
##
File path:
core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala
##
@@ -1167,6 +1168,58 @@ private[history] class FsHistoryProvider(conf:
SparkConf, clock: Clock)
// At this point the disk data either does not exist or was deleted
because it failed to
// load, so the event log needs to be replayed.
+// TODO: Maybe need to do other check to see if there's enough memory to
+// use inMemoryStore.
+if (hybridKVStoreEnabled) {
Review comment:
I found it's difficult to pass Lease to hybrid kvstore, since Lease
class is only visible within the History package.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28393: [SPARK-31595][SQL] Spark sql should allow unescaped quote mark in quoted string
AmplabJenkins commented on pull request #28393: URL: https://github.com/apache/spark/pull/28393#issuecomment-624420189 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28393: [SPARK-31595][SQL] Spark sql should allow unescaped quote mark in quoted string
AmplabJenkins removed a comment on pull request #28393: URL: https://github.com/apache/spark/pull/28393#issuecomment-624420189 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28393: [SPARK-31595][SQL] Spark sql should allow unescaped quote mark in quoted string
SparkQA removed a comment on pull request #28393: URL: https://github.com/apache/spark/pull/28393#issuecomment-624410522 **[Test build #122329 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122329/testReport)** for PR 28393 at commit [`d185264`](https://github.com/apache/spark/commit/d185264ae4acc585855b70b2ec3caa0e63c83043). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28393: [SPARK-31595][SQL] Spark sql should allow unescaped quote mark in quoted string
SparkQA commented on pull request #28393: URL: https://github.com/apache/spark/pull/28393#issuecomment-624420070 **[Test build #122329 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122329/testReport)** for PR 28393 at commit [`d185264`](https://github.com/apache/spark/commit/d185264ae4acc585855b70b2ec3caa0e63c83043). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28456: [SPARK-31235][YARN] Fix test "specify a more specific type for the ap…
SparkQA commented on pull request #28456: URL: https://github.com/apache/spark/pull/28456#issuecomment-624419881 **[Test build #122331 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122331/testReport)** for PR 28456 at commit [`42f090c`](https://github.com/apache/spark/commit/42f090cb386dc2e95641ce991e3911b0a60e6f55). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28456: [SPARK-31235][YARN] Fix test "specify a more specific type for the ap…
AmplabJenkins removed a comment on pull request #28456: URL: https://github.com/apache/spark/pull/28456#issuecomment-624419421 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28456: [SPARK-31235][YARN] Fix test "specify a more specific type for the ap…
SparkQA commented on pull request #28456: URL: https://github.com/apache/spark/pull/28456#issuecomment-624419352 **[Test build #122330 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122330/testReport)** for PR 28456 at commit [`1e415a9`](https://github.com/apache/spark/commit/1e415a903e07b4ff8d0eb9d5296f8208d7a22a3b). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28456: [SPARK-31235][YARN] Fix test "specify a more specific type for the ap…
SparkQA removed a comment on pull request #28456: URL: https://github.com/apache/spark/pull/28456#issuecomment-624413848 **[Test build #122330 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/122330/testReport)** for PR 28456 at commit [`1e415a9`](https://github.com/apache/spark/commit/1e415a903e07b4ff8d0eb9d5296f8208d7a22a3b). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28456: [SPARK-31235][YARN] Fix test "specify a more specific type for the ap…
AmplabJenkins commented on pull request #28456: URL: https://github.com/apache/spark/pull/28456#issuecomment-624419421 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #28164: [SPARK-31393][SQL] Show the correct alias in schema for expression
beliefer commented on pull request #28164: URL: https://github.com/apache/spark/pull/28164#issuecomment-624418126 cc @HyukjinKwon This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org