[GitHub] [lucene-solr] interma opened a new pull request #2289: Title: add timestamp in default gc_log name
interma opened a new pull request #2289: URL: https://github.com/apache/lucene-solr/pull/2289 # Description https://issues.apache.org/jira/browse/SOLR-15104 When restarting Solr, it will overwrite the gc log, this behavior is not friendly for debugging OOM issues. # Solution Add timestamp in default gc_log name, so it doesn't overwrite the previous one. # Tests Please describe the tests you've developed or run to confirm this patch implements the feature or solves the problem. # Checklist Please review the following and check all that apply: - [ ] I have reviewed the guidelines for [How to Contribute](https://wiki.apache.org/solr/HowToContribute) and my code conforms to the standards described there to the best of my ability. - [ ] I have created a Jira issue and added the issue ID to my pull request title. - [ ] I have given Solr maintainers [access](https://help.github.com/en/articles/allowing-changes-to-a-pull-request-branch-created-from-a-fork) to contribute to my PR branch. (optional but recommended) - [ ] I have developed this patch against the `master` branch. - [ ] I have run `./gradlew check`. - [ ] I have added tests for my changes. - [ ] I have added documentation for the [Ref Guide](https://github.com/apache/lucene-solr/tree/master/solr/solr-ref-guide) (for Solr changes only). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] sbeniwal12 commented on a change in pull request #2282: LUCENE-9615: Expose HnswGraphBuilder index-time hyperparameters as FieldType attributes
sbeniwal12 commented on a change in pull request #2282:
URL: https://github.com/apache/lucene-solr/pull/2282#discussion_r568327126
##
File path:
lucene/core/src/java/org/apache/lucene/codecs/lucene90/Lucene90VectorWriter.java
##
@@ -188,9 +190,29 @@ private void writeGraph(
RandomAccessVectorValuesProducer vectorValues,
long graphDataOffset,
long[] offsets,
- int count)
+ int count,
+ String maxConnStr,
+ String beamWidthStr)
throws IOException {
-HnswGraphBuilder hnswGraphBuilder = new HnswGraphBuilder(vectorValues);
+int maxConn, beamWidth;
+if (maxConnStr == null) {
+ maxConn = HnswGraphBuilder.DEFAULT_MAX_CONN;
+} else if (!maxConnStr.matches("[0-9]+")) {
Review comment:
Thanks for pointing out, threw `NumberFormatException` with message
describing which attribute caused the exception.
##
File path: lucene/core/src/java/org/apache/lucene/document/VectorField.java
##
@@ -53,6 +54,44 @@ private static FieldType getType(float[] v,
VectorValues.SearchStrategy searchSt
return type;
}
+ /**
+ * Public method to create HNSW field type with the given max-connections
and beam-width
+ * parameters that would be used by HnswGraphBuilder while constructing HNSW
graph.
+ *
+ * @param dimension dimension of vectors
+ * @param searchStrategy a function defining vector proximity.
+ * @param maxConn max-connections at each HNSW graph node
+ * @param beamWidth size of list to be used while constructing HNSW graph
+ * @throws IllegalArgumentException if any parameter is null, or has
dimension 1024.
+ */
+ public static FieldType createHnswType(
+ int dimension, VectorValues.SearchStrategy searchStrategy, int maxConn,
int beamWidth) {
+if (dimension == 0) {
+ throw new IllegalArgumentException("cannot index an empty vector");
+}
+if (dimension > VectorValues.MAX_DIMENSIONS) {
+ throw new IllegalArgumentException(
+ "cannot index vectors with dimension greater than " +
VectorValues.MAX_DIMENSIONS);
+}
+if (searchStrategy == null) {
+ throw new IllegalArgumentException("search strategy must not be null");
Review comment:
Added this check and also added a unit test for this check.
##
File path: lucene/core/src/test/org/apache/lucene/util/hnsw/KnnGraphTester.java
##
@@ -132,13 +135,13 @@ private void run(String... args) throws Exception {
if (iarg == args.length - 1) {
throw new IllegalArgumentException("-beamWidthIndex requires a
following number");
}
- HnswGraphBuilder.DEFAULT_BEAM_WIDTH = Integer.parseInt(args[++iarg]);
Review comment:
Made them final and also made changes to `TestKnnGraph.java` to
accommodate this change.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] zacharymorn commented on pull request #2258: LUCENE-9686: Fix read past EOF handling in DirectIODirectory
zacharymorn commented on pull request #2258: URL: https://github.com/apache/lucene-solr/pull/2258#issuecomment-771322610 > Hi Zach. Sorry for belated reply. Please take a look at my comments attached to the context. I have some doubts whether EOF should leave the channel undrained. Maybe I'm paranoid here though. Hi Dawid, no worry and thanks for the review! I've replied to the comment and added some tests to verify, please let me know if they look good to you. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] zacharymorn commented on a change in pull request #2258: LUCENE-9686: Fix read past EOF handling in DirectIODirectory
zacharymorn commented on a change in pull request #2258:
URL: https://github.com/apache/lucene-solr/pull/2258#discussion_r568294041
##
File path:
lucene/misc/src/java/org/apache/lucene/misc/store/DirectIODirectory.java
##
@@ -381,17 +377,18 @@ public long length() {
@Override
public byte readByte() throws IOException {
if (!buffer.hasRemaining()) {
-refill();
+refill(1);
}
+
return buffer.get();
}
-private void refill() throws IOException {
+private void refill(int byteToRead) throws IOException {
filePos += buffer.capacity();
// BaseDirectoryTestCase#testSeekPastEOF test for consecutive read past
EOF,
// hence throwing EOFException early to maintain buffer state (position
in particular)
- if (filePos > channel.size()) {
+ if (filePos > channel.size() || (channel.size() - filePos < byteToRead))
{
Review comment:
If I understand your comment correctly, your concern is about the
consistency of directory's internal state after EOF is raised right? I think
DirectIODirectory already handles that actually (by manipulating `filePos`, but
not `channel.position` per se), and I have added some more tests to confirm
that to be the case in the latest commit.
Please note that for the additional tests, I was originally adding them into
`BaseDirectoryTestCase#testSeekPastEOF`, but that would fail some existing
tests for other directory implementations, as read immediately after seek past
EOF doesn't raise EOFException for them:
* TestHardLinkCopyDirectoryWrapper
* TestMmapDirectory
* TestByteBuffersDirectory
* TestMultiMMap
However, according to java doc here
https://github.com/apache/lucene-solr/blob/15aaec60d9bfa96f2837c38b7ca83e2c87c66d8d/lucene/core/src/java/org/apache/lucene/store/IndexInput.java#L66-L73,
this seems to be an unspecified state in general.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] zacharymorn commented on a change in pull request #2258: LUCENE-9686: Fix read past EOF handling in DirectIODirectory
zacharymorn commented on a change in pull request #2258:
URL: https://github.com/apache/lucene-solr/pull/2258#discussion_r568293170
##
File path:
lucene/misc/src/java/org/apache/lucene/misc/store/DirectIODirectory.java
##
@@ -381,17 +377,18 @@ public long length() {
@Override
public byte readByte() throws IOException {
if (!buffer.hasRemaining()) {
-refill();
+refill(1);
}
+
return buffer.get();
}
-private void refill() throws IOException {
+private void refill(int byteToRead) throws IOException {
Review comment:
Updated.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Commented] (LUCENE-9718) REGEX Pattern Search, character classes with quantifiers do not work
[
https://issues.apache.org/jira/browse/LUCENE-9718?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276798#comment-17276798
]
Michael Sokolov commented on LUCENE-9718:
-
Thanks Brian, contributions in those areas would be welcome!
> REGEX Pattern Search, character classes with quantifiers do not work
>
>
> Key: LUCENE-9718
> URL: https://issues.apache.org/jira/browse/LUCENE-9718
> Project: Lucene - Core
> Issue Type: Bug
> Components: core/search
>Affects Versions: 7.7.3, 8.6.3
>Reporter: Brian Feldman
>Priority: Minor
> Labels: Documentation, RegEx
>
> Character classes with a quantifier do not work, no error is given and no
> results are returned. For example \d\{2} or \d\{2,3} as is commonly written
> in most languages supporting regular expressions, simply and quietly does not
> work. A user work around is to write them fully out such as \d\d or
> [0-9][0-9] or as [0-9]\{2,3} .
>
> This inconsistency or limitation is not documented, wasting the time of users
> as they have to figure this out themselves. I believe this inconsistency
> should be clearly documented and an effort to fixing the inconsistency would
> improve pattern searching.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Updated] (LUCENE-9718) REGEX Pattern Search, character classes with quantifiers do not work
[
https://issues.apache.org/jira/browse/LUCENE-9718?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Michael Sokolov updated LUCENE-9718:
Issue Type: Improvement (was: Bug)
> REGEX Pattern Search, character classes with quantifiers do not work
>
>
> Key: LUCENE-9718
> URL: https://issues.apache.org/jira/browse/LUCENE-9718
> Project: Lucene - Core
> Issue Type: Improvement
> Components: core/search
>Affects Versions: 7.7.3, 8.6.3
>Reporter: Brian Feldman
>Priority: Minor
> Labels: Documentation, RegEx
>
> Character classes with a quantifier do not work, no error is given and no
> results are returned. For example \d\{2} or \d\{2,3} as is commonly written
> in most languages supporting regular expressions, simply and quietly does not
> work. A user work around is to write them fully out such as \d\d or
> [0-9][0-9] or as [0-9]\{2,3} .
>
> This inconsistency or limitation is not documented, wasting the time of users
> as they have to figure this out themselves. I believe this inconsistency
> should be clearly documented and an effort to fixing the inconsistency would
> improve pattern searching.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] jaisonbi edited a comment on pull request #2213: LUCENE-9663: Adding compression to terms dict from SortedSet/Sorted DocValues
jaisonbi edited a comment on pull request #2213:
URL: https://github.com/apache/lucene-solr/pull/2213#issuecomment-771296030
If I understood correctly, the route via PerFieldDocValuesFormat need to
change the usage of SortedSetDocValues.
The idea is adding another constructor for enabling terms dict compression,
as below:
```
public SortedSetDocValuesField(String name, BytesRef bytes, boolean
compression) {
super(name, compression ? COMPRESSION_TYPE: TYPE);
fieldsData = bytes;
}
```
And below is the definition of COMPRESSION_TYPE:
```
public static final FieldType COMPRESSION_TYPE = new FieldType();
static {
COMPRESSION_TYPE.setDocValuesType(DocValuesType.SORTED_SET);
// add one new attribute for telling PerFieldDocValuesFormat that terms
dict compression is enabled for this field
COMPRESSION_TYPE.putAttribute("docvalue.sortedset.compression", "true");
COMPRESSION_TYPE.freeze();
}
```
Not sure if I've got it right :)
@msokolov @bruno-roustant
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] jaisonbi commented on pull request #2213: LUCENE-9663: Adding compression to terms dict from SortedSet/Sorted DocValues
jaisonbi commented on pull request #2213:
URL: https://github.com/apache/lucene-solr/pull/2213#issuecomment-771296030
If I understood correctly, the route via PerFieldDocValuesFormat need to
change the usage of SortedSetDocValues.
The idea is adding another constructor for enabling terms dict compression,
as below:
```
public SortedSetDocValuesField(String name, BytesRef bytes, boolean
compression) {
super(name, compression ? COMPRESSION_TYPE: TYPE);
fieldsData = bytes;
}
```
In COMPRESSION_TYPE, add one new attribute for telling
PerFieldDocValuesFormat that terms dict compression is enabled for this field.
Not sure if I've got it right :)
@msokolov @bruno-roustant
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Commented] (SOLR-15124) Remove node/container level admin handlers from ImplicitPlugins.json (core level).
[
https://issues.apache.org/jira/browse/SOLR-15124?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276789#comment-17276789
]
David Smiley commented on SOLR-15124:
-
{quote}Should we consider setting up redirect paths for the old handlers? Or a
better error message with a hint that they have moved?
{quote}
No; this is 9.0 and the fact that these are registered here is an obscure
oddity. Let's not make removal of tech-debt too hard please, or we will
increasingly won't bother because it's too much of a PITA, and then we're left
with an even worse tech-debt problem in the years to come (from my experience
here, looking back 10+ years).
{quote}Also, will need to update SolrCoreTest.testImplicitPlugins, which I
don't think the existing PR did.
{quote}
[~nazerke] did you run tests?
> Remove node/container level admin handlers from ImplicitPlugins.json (core
> level).
> --
>
> Key: SOLR-15124
> URL: https://issues.apache.org/jira/browse/SOLR-15124
> Project: Solr
> Issue Type: Task
> Security Level: Public(Default Security Level. Issues are Public)
>Reporter: David Smiley
>Priority: Blocker
> Labels: newdev
> Fix For: master (9.0)
>
> Time Spent: 50m
> Remaining Estimate: 0h
>
> There are many very old administrative RequestHandlers registered in a
> SolrCore that are actually JVM / node / CoreContainer level in nature. These
> pre-dated CoreContainer level handlers. We should (1) remove them from
> ImplictPlugins.json, and (2) make simplifying tweaks to them to remove that
> they work at the core level. For example LoggingHandler has two constructors
> and a non-final Watcher because it works in these two modalities. It need
> only have the one that takes a CoreContainer, and Watcher will then be final.
> /admin/threads
> /admin/properties
> /admin/logging
> Should stay because has core-level stuff:
> /admin/plugins
> /admin/mbeans
> This one:
> /admin/system -- SystemInfoHandler
> returns "core" level information, and also node level stuff. I propose
> splitting this one to a CoreInfoHandler to split the logic. Maybe a separate
> issue.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Updated] (LUCENE-9722) Aborted merge can leak readers if the output is empty
[ https://issues.apache.org/jira/browse/LUCENE-9722?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Nhat Nguyen updated LUCENE-9722: Description: We fail to close the merged readers of an aborted merge if its output segment contains no document. This bug was discovered by a test in Elasticsearch ([elastic/elasticsearch#67884|https://github.com/elastic/elasticsearch/issues/67884]). was:We fail to close merged readers if the output segment contains no document. > Aborted merge can leak readers if the output is empty > - > > Key: LUCENE-9722 > URL: https://issues.apache.org/jira/browse/LUCENE-9722 > Project: Lucene - Core > Issue Type: Bug > Components: core/index >Affects Versions: master (9.0), 8.7 >Reporter: Nhat Nguyen >Assignee: Nhat Nguyen >Priority: Major > Time Spent: 10m > Remaining Estimate: 0h > > We fail to close the merged readers of an aborted merge if its output segment > contains no document. > This bug was discovered by a test in Elasticsearch > ([elastic/elasticsearch#67884|https://github.com/elastic/elasticsearch/issues/67884]). -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Updated] (LUCENE-9722) Aborted merge can leak readers if the output is empty
[ https://issues.apache.org/jira/browse/LUCENE-9722?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Nhat Nguyen updated LUCENE-9722: Status: Patch Available (was: Open) > Aborted merge can leak readers if the output is empty > - > > Key: LUCENE-9722 > URL: https://issues.apache.org/jira/browse/LUCENE-9722 > Project: Lucene - Core > Issue Type: Bug > Components: core/index >Affects Versions: master (9.0), 8.7 >Reporter: Nhat Nguyen >Assignee: Nhat Nguyen >Priority: Major > Time Spent: 10m > Remaining Estimate: 0h > > We fail to close merged readers if the output segment contains no document. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] dnhatn opened a new pull request #2288: LUCENE-9722: Close merged readers on abort
dnhatn opened a new pull request #2288: URL: https://github.com/apache/lucene-solr/pull/2288 We fail to close merged readers if the output segment contains no document. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Created] (LUCENE-9722) Aborted merge can leak readers if the output is empty
Nhat Nguyen created LUCENE-9722: --- Summary: Aborted merge can leak readers if the output is empty Key: LUCENE-9722 URL: https://issues.apache.org/jira/browse/LUCENE-9722 Project: Lucene - Core Issue Type: Bug Components: core/index Affects Versions: 8.7, master (9.0) Reporter: Nhat Nguyen Assignee: Nhat Nguyen We fail to close merged readers if the output segment contains no document. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] zhaih commented on a change in pull request #2213: LUCENE-9663: Adding compression to terms dict from SortedSet/Sorted DocValues
zhaih commented on a change in pull request #2213:
URL: https://github.com/apache/lucene-solr/pull/2213#discussion_r568246420
##
File path:
lucene/core/src/java/org/apache/lucene/codecs/lucene80/Lucene80DocValuesConsumer.java
##
@@ -736,49 +736,92 @@ private void doAddSortedField(FieldInfo field,
DocValuesProducer valuesProducer)
private void addTermsDict(SortedSetDocValues values) throws IOException {
final long size = values.getValueCount();
meta.writeVLong(size);
-meta.writeInt(Lucene80DocValuesFormat.TERMS_DICT_BLOCK_SHIFT);
+boolean compress =
+Lucene80DocValuesFormat.Mode.BEST_COMPRESSION == mode
Review comment:
Sorry for late response. I agree we could solve it in a follow-up issue.
And I could still test this via a customized PerFieldDocValuesFormat, thank you!
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] zhaih commented on pull request #2213: LUCENE-9663: Adding compression to terms dict from SortedSet/Sorted DocValues
zhaih commented on pull request #2213: URL: https://github.com/apache/lucene-solr/pull/2213#issuecomment-771265310 I see, so I think for now I could test it via a customized PerFieldDocValuesFormat, I'll give PerFieldDocValuesFormat route a try then. Tho IMO I would prefer a simpler configuration (as proposed by @jaisonbi) rather than customize using PerFieldDocValuesFormat in the future, if these 2 compression are showing different performance characteristic. Since if my understand is correct, to enable only TermDictCompression using PerFieldDOcValuesFormat we need to enumerate all SSDV field names in that class? Which sounds not quite maintainable if there's regularly field addition/deletion. Please correct me if I'm wrong as I'm not quite familiar with codec part... This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Commented] (SOLR-14330) Return docs with null value in expand for field when collapse has nullPolicy=collapse
[
https://issues.apache.org/jira/browse/SOLR-14330?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276749#comment-17276749
]
ASF subversion and git services commented on SOLR-14330:
Commit 4a21f594c203fb219942dcbaebbd872dcb2cfd4d in lucene-solr's branch
refs/heads/branch_8x from Chris M. Hostetter
[ https://gitbox.apache.org/repos/asf?p=lucene-solr.git;h=4a21f59 ]
SOLR-14330: ExpandComponent now supports an expand.nullGroup=true option
(cherry picked from commit 15aaec60d9bfa96f2837c38b7ca83e2c87c66d8d)
> Return docs with null value in expand for field when collapse has
> nullPolicy=collapse
> -
>
> Key: SOLR-14330
> URL: https://issues.apache.org/jira/browse/SOLR-14330
> Project: Solr
> Issue Type: Wish
>Reporter: Munendra S N
>Assignee: Chris M. Hostetter
>Priority: Major
> Attachments: SOLR-14330.patch, SOLR-14330.patch
>
>
> When documents doesn't contain value for field then, with collapse either
> those documents could be either ignored(default), collapsed(one document is
> chosen) or expanded(all are returned). This is controlled by {{nullPolicy}}
> When {{nullPolicy}} is {{collapse}}, it would be nice to return all documents
> with {{null}} value in expand block if {{expand=true}}
> Also, when used with {{expand.field}}, even then we should return such
> documents
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Resolved] (SOLR-14330) Return docs with null value in expand for field when collapse has nullPolicy=collapse
[
https://issues.apache.org/jira/browse/SOLR-14330?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Chris M. Hostetter resolved SOLR-14330.
---
Fix Version/s: 8.9
master (9.0)
Resolution: Fixed
> Return docs with null value in expand for field when collapse has
> nullPolicy=collapse
> -
>
> Key: SOLR-14330
> URL: https://issues.apache.org/jira/browse/SOLR-14330
> Project: Solr
> Issue Type: Wish
>Reporter: Munendra S N
>Assignee: Chris M. Hostetter
>Priority: Major
> Fix For: master (9.0), 8.9
>
> Attachments: SOLR-14330.patch, SOLR-14330.patch
>
>
> When documents doesn't contain value for field then, with collapse either
> those documents could be either ignored(default), collapsed(one document is
> chosen) or expanded(all are returned). This is controlled by {{nullPolicy}}
> When {{nullPolicy}} is {{collapse}}, it would be nice to return all documents
> with {{null}} value in expand block if {{expand=true}}
> Also, when used with {{expand.field}}, even then we should return such
> documents
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Commented] (SOLR-14330) Return docs with null value in expand for field when collapse has nullPolicy=collapse
[
https://issues.apache.org/jira/browse/SOLR-14330?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276725#comment-17276725
]
ASF subversion and git services commented on SOLR-14330:
Commit 15aaec60d9bfa96f2837c38b7ca83e2c87c66d8d in lucene-solr's branch
refs/heads/master from Chris M. Hostetter
[ https://gitbox.apache.org/repos/asf?p=lucene-solr.git;h=15aaec6 ]
SOLR-14330: ExpandComponent now supports an expand.nullGroup=true option
> Return docs with null value in expand for field when collapse has
> nullPolicy=collapse
> -
>
> Key: SOLR-14330
> URL: https://issues.apache.org/jira/browse/SOLR-14330
> Project: Solr
> Issue Type: Wish
>Reporter: Munendra S N
>Assignee: Chris M. Hostetter
>Priority: Major
> Attachments: SOLR-14330.patch, SOLR-14330.patch
>
>
> When documents doesn't contain value for field then, with collapse either
> those documents could be either ignored(default), collapsed(one document is
> chosen) or expanded(all are returned). This is controlled by {{nullPolicy}}
> When {{nullPolicy}} is {{collapse}}, it would be nice to return all documents
> with {{null}} value in expand block if {{expand=true}}
> Also, when used with {{expand.field}}, even then we should return such
> documents
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] dsmiley commented on a change in pull request #2230: SOLR-15011: /admin/logging handler is configured logs to all nodes
dsmiley commented on a change in pull request #2230: URL: https://github.com/apache/lucene-solr/pull/2230#discussion_r568204361 ## File path: solr/CHANGES.txt ## @@ -69,6 +69,8 @@ Improvements * SOLR-14949: Docker: Ability to customize the FROM image when building. (Houston Putman) +* SOLR-15011: /admin/logging handler should be able to configure logs on all nodes (Nazerke Seidan, David Smiley) Review comment: ```suggestion * SOLR-15011: /admin/logging handler will now propagate setLevel (log threshold) to all nodes when told to. The admin UI now tells it to. (Nazerke Seidan, David Smiley) ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Comment Edited] (LUCENE-9705) Move all codec formats to the o.a.l.codecs.Lucene90 package
[
https://issues.apache.org/jira/browse/LUCENE-9705?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276599#comment-17276599
]
Julie Tibshirani edited comment on LUCENE-9705 at 2/1/21, 11:02 PM:
{quote}It's especially clear here where we must copy a lot of classes with no
change at all, merely to clearly and consistently document the index version
change.
{quote}
I’ll try to add some context since I suspect there might be misunderstanding.
In general when there is a new version like 9.1, we *do not* plan to create all
new index format classes. We only copy a class and move it to backwards-codecs
when there is a change to that specific format, for example {{PointsFormat}}.
This proposal applies only to the 9.0 release, and its main purpose is to
support the work in LUCENE-9047 to move all formats to little endian. My
understanding is that moving to little endian impacts all the formats and will
be much cleaner if we used these fresh {{Lucene90*Format}}.
{quote}I wonder if we (eventually) should consider shifting to a versioning
system that doesn't require new classes. Is this somehow a feature of the
service discovery API that we use?
{quote}
We indeed load codecs (with their formats) through service discovery. If a user
wants to read indices from a previous version, they can depend on
backwards-codecs so Lucene loads the correct older codec. As of LUCENE-9669, we
allow reading indices back to major version N-2.
I personally really like the current "copy-on-write" system for formats.
There’s code duplication, but it has advantages over combining different
version logic in the same file:
* It’s really clear how each version behaves. Having a direct copy like
{{Lucene70Codec}} is almost as if we were pulling in jars from Lucene 7.0.
* It decreases risk of introducing bugs or accidental changes. If you’re
making an enhancement to a new format, there’s little chance of changing the
logic for an old format (since it lives in a separate class). This is
especially important since older formats are not tested as thoroughly.
I started to appreciate it after experiencing the alternative in Elasticsearch,
where we’re constantly bumping into if/ else version checks when making changes.
was (Author: julietibs):
{quote}It's especially clear here where we must copy a lot of classes with no
change at all, merely to clearly and consistently document the index version
change.
{quote}
I’ll try to add some context since I suspect there might be misunderstanding.
In general when there is a new major version, we *do not* plan to create all
new index format classes. We only copy a class and move it to backwards-codecs
when there is a change to that specific format, for example {{PointsFormat}}.
This proposal applies only to the 9.0 release, and its main purpose is to
support the work in LUCENE-9047 to move all formats to little endian. My
understanding is that moving to little endian impacts all the formats and will
be much cleaner if we used these fresh {{Lucene90*Format}}.
{quote}I wonder if we (eventually) should consider shifting to a versioning
system that doesn't require new classes. Is this somehow a feature of the
service discovery API that we use?
{quote}
We indeed load codecs (with their formats) through service discovery. If a user
wants to read indices from a previous version, they can depend on
backwards-codecs so Lucene loads the correct older codec. As of LUCENE-9669, we
allow reading indices back to major version N-2.
I personally really like the current "copy-on-write" system for formats.
There’s code duplication, but it has advantages over combining different
version logic in the same file:
* It’s really clear how each version behaves. Having a direct copy like
{{Lucene70Codec}} is almost as if we were pulling in jars from Lucene 7.0.
* It decreases risk of introducing bugs or accidental changes. If you’re
making an enhancement to a new format, there’s little chance of changing the
logic for an old format (since it lives in a separate class). This is
especially important since older formats are not tested as thoroughly.
I started to appreciate it after experiencing the alternative in Elasticsearch,
where we’re constantly bumping into if/ else version checks when making changes.
> Move all codec formats to the o.a.l.codecs.Lucene90 package
> ---
>
> Key: LUCENE-9705
> URL: https://issues.apache.org/jira/browse/LUCENE-9705
> Project: Lucene - Core
> Issue Type: Wish
>Reporter: Ignacio Vera
>Priority: Major
> Time Spent: 50m
> Remaining Estimate: 0h
>
> Current formats are distributed in different packages, prefixed with the
> Lucene version they were created. With the upcoming release of Lucene 9.0, it
> would be nice
[jira] [Commented] (SOLR-8393) Component for Solr resource usage planning
[ https://issues.apache.org/jira/browse/SOLR-8393?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276715#comment-17276715 ] Isabelle Giguere commented on SOLR-8393: New patch, off current master Parameter 'sizeUnit' is supported for both the SizeComponent, and ClusterSizing. If parameter 'sizeUnit' is present, values will be output as 'double', according to the chosen size unit. Value of 'estimated-num-docs' remains a 'long'. Default behavior, if 'sizeUnit' is not present is the human-readable format. Valid values for 'sizeUnit' are : GB, MB, KB, bytes ** Note about the implementation : ClusterSizing calls the SizeComponent via HTTP. So the returned results per collection are already formatted according to 'sizeUnit' (or lack of it). As a consequence, ClusterSizing needs to toggle back and forth between human-readable values, and raw long values, to support the requested 'sizeUnit'. I don't know how we could intercept the SizeComponent response, and receive just the long values, to make the conversion to some 'sizeUnit' just once in ClusterSizing, while keeping the formatting in SizeComponent, for use cases that would call it directly. A response transformer ? Would that be the right approach ? > Component for Solr resource usage planning > -- > > Key: SOLR-8393 > URL: https://issues.apache.org/jira/browse/SOLR-8393 > Project: Solr > Issue Type: Improvement >Reporter: Steve Molloy >Priority: Major > Attachments: SOLR-8393.patch, SOLR-8393.patch, SOLR-8393.patch, > SOLR-8393.patch, SOLR-8393.patch, SOLR-8393.patch, SOLR-8393.patch, > SOLR-8393.patch, SOLR-8393.patch, SOLR-8393_tag_7.5.0.patch > > > One question that keeps coming back is how much disk and RAM do I need to run > Solr. The most common response is that it highly depends on your data. While > true, it makes for frustrated users trying to plan their deployments. > The idea I'm bringing is to create a new component that will attempt to > extrapolate resources needed in the future by looking at resources currently > used. By adding a parameter for the target number of documents, current > resources are adapted by a ratio relative to current number of documents. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Updated] (SOLR-8393) Component for Solr resource usage planning
[ https://issues.apache.org/jira/browse/SOLR-8393?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Isabelle Giguere updated SOLR-8393: --- Attachment: SOLR-8393.patch > Component for Solr resource usage planning > -- > > Key: SOLR-8393 > URL: https://issues.apache.org/jira/browse/SOLR-8393 > Project: Solr > Issue Type: Improvement >Reporter: Steve Molloy >Priority: Major > Attachments: SOLR-8393.patch, SOLR-8393.patch, SOLR-8393.patch, > SOLR-8393.patch, SOLR-8393.patch, SOLR-8393.patch, SOLR-8393.patch, > SOLR-8393.patch, SOLR-8393.patch, SOLR-8393_tag_7.5.0.patch > > > One question that keeps coming back is how much disk and RAM do I need to run > Solr. The most common response is that it highly depends on your data. While > true, it makes for frustrated users trying to plan their deployments. > The idea I'm bringing is to create a new component that will attempt to > extrapolate resources needed in the future by looking at resources currently > used. By adding a parameter for the target number of documents, current > resources are adapted by a ratio relative to current number of documents. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] dweiss commented on a change in pull request #2267: LUCENE-9707: Hunspell: check Lucene's implementation against Hunspel's test data
dweiss commented on a change in pull request #2267:
URL: https://github.com/apache/lucene-solr/pull/2267#discussion_r568187636
##
File path:
lucene/analysis/common/src/test/org/apache/lucene/analysis/hunspell/SpellCheckerTest.java
##
@@ -61,59 +61,74 @@ public void needAffixOnAffixes() throws Exception {
doTest("needaffix5");
}
+ @Test
public void testBreak() throws Exception {
doTest("break");
}
- public void testBreakDefault() throws Exception {
+ @Test
+ public void breakDefault() throws Exception {
doTest("breakdefault");
}
- public void testBreakOff() throws Exception {
+ @Test
+ public void breakOff() throws Exception {
doTest("breakoff");
}
- public void testCompoundrule() throws Exception {
+ @Test
+ public void compoundrule() throws Exception {
doTest("compoundrule");
}
- public void testCompoundrule2() throws Exception {
+ @Test
+ public void compoundrule2() throws Exception {
doTest("compoundrule2");
}
- public void testCompoundrule3() throws Exception {
+ @Test
+ public void compoundrule3() throws Exception {
doTest("compoundrule3");
}
- public void testCompoundrule4() throws Exception {
+ @Test
+ public void compoundrule4() throws Exception {
doTest("compoundrule4");
}
- public void testCompoundrule5() throws Exception {
+ @Test
+ public void compoundrule5() throws Exception {
doTest("compoundrule5");
}
- public void testCompoundrule6() throws Exception {
+ @Test
+ public void compoundrule6() throws Exception {
doTest("compoundrule6");
}
- public void testCompoundrule7() throws Exception {
+ @Test
+ public void compoundrule7() throws Exception {
doTest("compoundrule7");
}
- public void testCompoundrule8() throws Exception {
+ @Test
+ public void compoundrule8() throws Exception {
doTest("compoundrule8");
}
- public void testGermanCompounding() throws Exception {
+ @Test
+ public void germanCompounding() throws Exception {
doTest("germancompounding");
}
protected void doTest(String name) throws Exception {
-InputStream affixStream =
-Objects.requireNonNull(getClass().getResourceAsStream(name + ".aff"),
name);
-InputStream dictStream =
-Objects.requireNonNull(getClass().getResourceAsStream(name + ".dic"),
name);
+checkSpellCheckerExpectations(
Review comment:
Ah... can't push to your repo (there is a checkbox to enable committers
to do so - please use it, makes edits easier :). Here is the commit:
https://github.com/dweiss/lucene-solr/commit/618a2d3b5bb51eb0e35322a9c56b97bdce7d728b
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] dweiss commented on a change in pull request #2267: LUCENE-9707: Hunspell: check Lucene's implementation against Hunspel's test data
dweiss commented on a change in pull request #2267:
URL: https://github.com/apache/lucene-solr/pull/2267#discussion_r568186778
##
File path:
lucene/analysis/common/src/test/org/apache/lucene/analysis/hunspell/SpellCheckerTest.java
##
@@ -61,59 +61,74 @@ public void needAffixOnAffixes() throws Exception {
doTest("needaffix5");
}
+ @Test
public void testBreak() throws Exception {
doTest("break");
}
- public void testBreakDefault() throws Exception {
+ @Test
+ public void breakDefault() throws Exception {
doTest("breakdefault");
}
- public void testBreakOff() throws Exception {
+ @Test
+ public void breakOff() throws Exception {
doTest("breakoff");
}
- public void testCompoundrule() throws Exception {
+ @Test
+ public void compoundrule() throws Exception {
doTest("compoundrule");
}
- public void testCompoundrule2() throws Exception {
+ @Test
+ public void compoundrule2() throws Exception {
doTest("compoundrule2");
}
- public void testCompoundrule3() throws Exception {
+ @Test
+ public void compoundrule3() throws Exception {
doTest("compoundrule3");
}
- public void testCompoundrule4() throws Exception {
+ @Test
+ public void compoundrule4() throws Exception {
doTest("compoundrule4");
}
- public void testCompoundrule5() throws Exception {
+ @Test
+ public void compoundrule5() throws Exception {
doTest("compoundrule5");
}
- public void testCompoundrule6() throws Exception {
+ @Test
+ public void compoundrule6() throws Exception {
doTest("compoundrule6");
}
- public void testCompoundrule7() throws Exception {
+ @Test
+ public void compoundrule7() throws Exception {
doTest("compoundrule7");
}
- public void testCompoundrule8() throws Exception {
+ @Test
+ public void compoundrule8() throws Exception {
doTest("compoundrule8");
}
- public void testGermanCompounding() throws Exception {
+ @Test
+ public void germanCompounding() throws Exception {
doTest("germancompounding");
}
protected void doTest(String name) throws Exception {
-InputStream affixStream =
-Objects.requireNonNull(getClass().getResourceAsStream(name + ".aff"),
name);
-InputStream dictStream =
-Objects.requireNonNull(getClass().getResourceAsStream(name + ".dic"),
name);
+checkSpellCheckerExpectations(
Review comment:
You can't really convert resource URLs to paths with url.getPath. This
breaks, as I suspected. On Windows you get:
```
java.nio.file.InvalidPathException: Illegal char <:> at index 2:
/C:/Work/apache/lucene/lucene.master/lucene/analysis/common/build/classes/java/test/org/apache/lucene/analysis/hunspell/i53643.aff
> at
__randomizedtesting.SeedInfo.seed([FE61D482FAEDBB53:CE18D8B46A2785A8]:0)
> at
java.base/sun.nio.fs.WindowsPathParser.normalize(WindowsPathParser.java:182)
> at
java.base/sun.nio.fs.WindowsPathParser.parse(WindowsPathParser.java:153)
> at
java.base/sun.nio.fs.WindowsPathParser.parse(WindowsPathParser.java:77)
> at java.base/sun.nio.fs.WindowsPath.parse(WindowsPath.java:92)
> at
java.base/sun.nio.fs.WindowsFileSystem.getPath(WindowsFileSystem.java:229)
> at java.base/java.nio.file.Path.of(Path.java:147)
```
A better method is to go through the URI - Path.of(url.toUri()). I've
modified the code slightly, please take a look.
Also, can you rename tests to follow TestXXX convention? This may be
enforced in the future and will spare somebody some work to rename.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Updated] (SOLR-15127) All-In-One Dockerfile for building local images as well as reproducible release builds directly from (remote) git tags
[
https://issues.apache.org/jira/browse/SOLR-15127?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Chris M. Hostetter updated SOLR-15127:
--
Attachment: SOLR-15127.patch
Status: Open (was: Open)
The attached patch implements this idea, and seems to work well -- there are
some nocommits, but they aren't neccessarily problems that need "fixed", so
much as comments to draw attention to some specific changes for discussion.
Basic usage is spelled out in the Dockerfile comments...
{noformat}
# This Dockerfile can be used in 2 distinct ways:
# 1) For Solr developers with a java/gradle development env, this file is used
by gradle to build docker images
#from your local builds (with or w/o local modifications). When doing
this, gradle will use a docker build context
#containing pre-built artifacts from previous gradle targets
# EX: ./gradlew -p solr/docker dockerBuild
#
# 2) Solr users, with or w/o a local java/gradle development env, can pass this
Dockerfile directly to docker build,
#using the root level checkout of the the project -- or a remote git URL --
as the docker build context. When doing
#this, docker will invoke gradle to build all neccessary artifacts
# EX: docker build --file solr/docker/Dockerfile .
# docker build --file solr/docker/Dockerfile
https://gitbox.apache.org/repos/asf/lucene-solr.git
# docker build --file solr/docker/Dockerfile
https://gitbox.apache.org/repos/asf/lucene-solr.git#branch_9x
#
# This last format is the method used by Solr Release Managers to build the
official apache/solr images uploaded to hub.docker.com
#
# EX: docker build --build-arg SOLR_VERSION=9.0.0 \
# --tag apache/solr:9.0.0 \
# --file solr/docker/Dockerfile \
#
https://gitbox.apache.org/repos/asf/lucene-solr.git#releases/lucene-solr/9.0.0
{noformat}
...allthough the direct "docker build" usage could be drastically simplified
once solr has it's own TLP/git repo if we're willing to keep the Dockerfile in
the root of the repo.
[~houstonputman] / [~dsmiley] / [~janhoy]: what do you guys think of this
overall approach?
> All-In-One Dockerfile for building local images as well as reproducible
> release builds directly from (remote) git tags
> --
>
> Key: SOLR-15127
> URL: https://issues.apache.org/jira/browse/SOLR-15127
> Project: Solr
> Issue Type: Sub-task
> Security Level: Public(Default Security Level. Issues are Public)
>Reporter: Chris M. Hostetter
>Priority: Major
> Attachments: SOLR-15127.patch
>
>
> There was a recent dev@lucene discussion about the future of the
> github/docker-solr repo and (Apache) "official" solr docker images and using
> the "apache/solr" nameing vs (docker-library official) "_/solr" names...
> http://mail-archives.apache.org/mod_mbox/lucene-dev/202101.mbox/%3CCAD4GwrNCPEnAJAjy4tY%3DpMeX5vWvnFyLe9ZDaXmF4J8XchA98Q%40mail.gmail.com%3E
> In that disussion, mak pointed out that docker-library evidently allows for
> some more flexibility in the way "official" docker-library packages can be
> built (compared to the rules that were evidnlty in place when the mak setup
> the current docker-solr image building process/tooling), pointing out how the
> "docker official" elasticsearch images are current built from the "elastic
> official" elasticsearch images...
> http://mail-archives.apache.org/mod_mbox/lucene-dev/202101.mbox/%3C3CED9683-1DD2-4F08-97F9-4FC549EDE47D%40greenhills.co.uk%3E
> Based on this, I proposed that we could probably restructure the Solr
> Dockerfile so that it could be useful for both "local development" -- using
> the current repo checkout -- as well as for "apache official" apache/solr
> images that could be reproducibly built directly from pristine git tags using
> the remote git URL syntax supported by "docker build" (and then -- evidently
> -- extended by trivial one line Dockerfiles for the "docker-library official"
> _/solr images)...
> http://mail-archives.apache.org/mod_mbox/lucene-dev/202101.mbox/%3Calpine.DEB.2.21.2101221423340.16298%40slate%3E
> This jira tracks this idea.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] dweiss commented on a change in pull request #2267: LUCENE-9707: Hunspell: check Lucene's implementation against Hunspel's test data
dweiss commented on a change in pull request #2267:
URL: https://github.com/apache/lucene-solr/pull/2267#discussion_r568176360
##
File path:
lucene/analysis/common/src/test/org/apache/lucene/analysis/hunspell/TestsFromOriginalHunspellRepository.java
##
@@ -0,0 +1,71 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.lucene.analysis.hunspell;
+
+import java.io.IOException;
+import java.nio.file.DirectoryStream;
+import java.nio.file.Files;
+import java.nio.file.Path;
+import java.text.ParseException;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.Set;
+import java.util.TreeSet;
+import java.util.stream.Collectors;
+import org.junit.Test;
+import org.junit.runner.RunWith;
+import org.junit.runners.Parameterized;
+
+/**
+ * Same as {@link SpellCheckerTest}, but checks all Hunspell's test data. The
path to the checked
+ * out Hunspell repository should be in {@code -Dhunspell.repo.path=...}
system property.
+ */
+@RunWith(Parameterized.class)
Review comment:
Filed an issue for myself here:
https://github.com/randomizedtesting/randomizedtesting/issues/295.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Created] (SOLR-15127) All-In-One Dockerfile for building local images as well as reproducible release builds directly from (remote) git tags
Chris M. Hostetter created SOLR-15127: - Summary: All-In-One Dockerfile for building local images as well as reproducible release builds directly from (remote) git tags Key: SOLR-15127 URL: https://issues.apache.org/jira/browse/SOLR-15127 Project: Solr Issue Type: Sub-task Security Level: Public (Default Security Level. Issues are Public) Reporter: Chris M. Hostetter There was a recent dev@lucene discussion about the future of the github/docker-solr repo and (Apache) "official" solr docker images and using the "apache/solr" nameing vs (docker-library official) "_/solr" names... http://mail-archives.apache.org/mod_mbox/lucene-dev/202101.mbox/%3CCAD4GwrNCPEnAJAjy4tY%3DpMeX5vWvnFyLe9ZDaXmF4J8XchA98Q%40mail.gmail.com%3E In that disussion, mak pointed out that docker-library evidently allows for some more flexibility in the way "official" docker-library packages can be built (compared to the rules that were evidnlty in place when the mak setup the current docker-solr image building process/tooling), pointing out how the "docker official" elasticsearch images are current built from the "elastic official" elasticsearch images... http://mail-archives.apache.org/mod_mbox/lucene-dev/202101.mbox/%3C3CED9683-1DD2-4F08-97F9-4FC549EDE47D%40greenhills.co.uk%3E Based on this, I proposed that we could probably restructure the Solr Dockerfile so that it could be useful for both "local development" -- using the current repo checkout -- as well as for "apache official" apache/solr images that could be reproducibly built directly from pristine git tags using the remote git URL syntax supported by "docker build" (and then -- evidently -- extended by trivial one line Dockerfiles for the "docker-library official" _/solr images)... http://mail-archives.apache.org/mod_mbox/lucene-dev/202101.mbox/%3Calpine.DEB.2.21.2101221423340.16298%40slate%3E This jira tracks this idea. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] dweiss commented on a change in pull request #2267: LUCENE-9707: Hunspell: check Lucene's implementation against Hunspel's test data
dweiss commented on a change in pull request #2267:
URL: https://github.com/apache/lucene-solr/pull/2267#discussion_r568175124
##
File path:
lucene/analysis/common/src/test/org/apache/lucene/analysis/hunspell/TestsFromOriginalHunspellRepository.java
##
@@ -0,0 +1,71 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.lucene.analysis.hunspell;
+
+import java.io.IOException;
+import java.nio.file.DirectoryStream;
+import java.nio.file.Files;
+import java.nio.file.Path;
+import java.text.ParseException;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.Set;
+import java.util.TreeSet;
+import java.util.stream.Collectors;
+import org.junit.Test;
+import org.junit.runner.RunWith;
+import org.junit.runners.Parameterized;
+
+/**
+ * Same as {@link SpellCheckerTest}, but checks all Hunspell's test data. The
path to the checked
+ * out Hunspell repository should be in {@code -Dhunspell.repo.path=...}
system property.
+ */
+@RunWith(Parameterized.class)
Review comment:
I checked intellij and parameterized tests tonight. It's what I was
afraid of - test descriptions are emitted correctly (in my opinion) but they're
*interepreted* differently depending on the tool (and time when you check...).
The reason why you see the class name and test method before each actual
test is because these supposedly "hidden" elements allowed tools to go back to
the source code of a test with an arbitrary name (if you double-click on a test
in IntelliJ it will take you back to the test method). Relaunching of a single
test must have changed at some point because it used to be an exact name
filter... but now I it just reruns all tests under a test method (all parameter
variations).
It's worth mentioning that this isn't consistent even in IntelliJ itself -
if I run a simple(r) parameterized test via IntelliJ launcher, I get this test
suite tree:
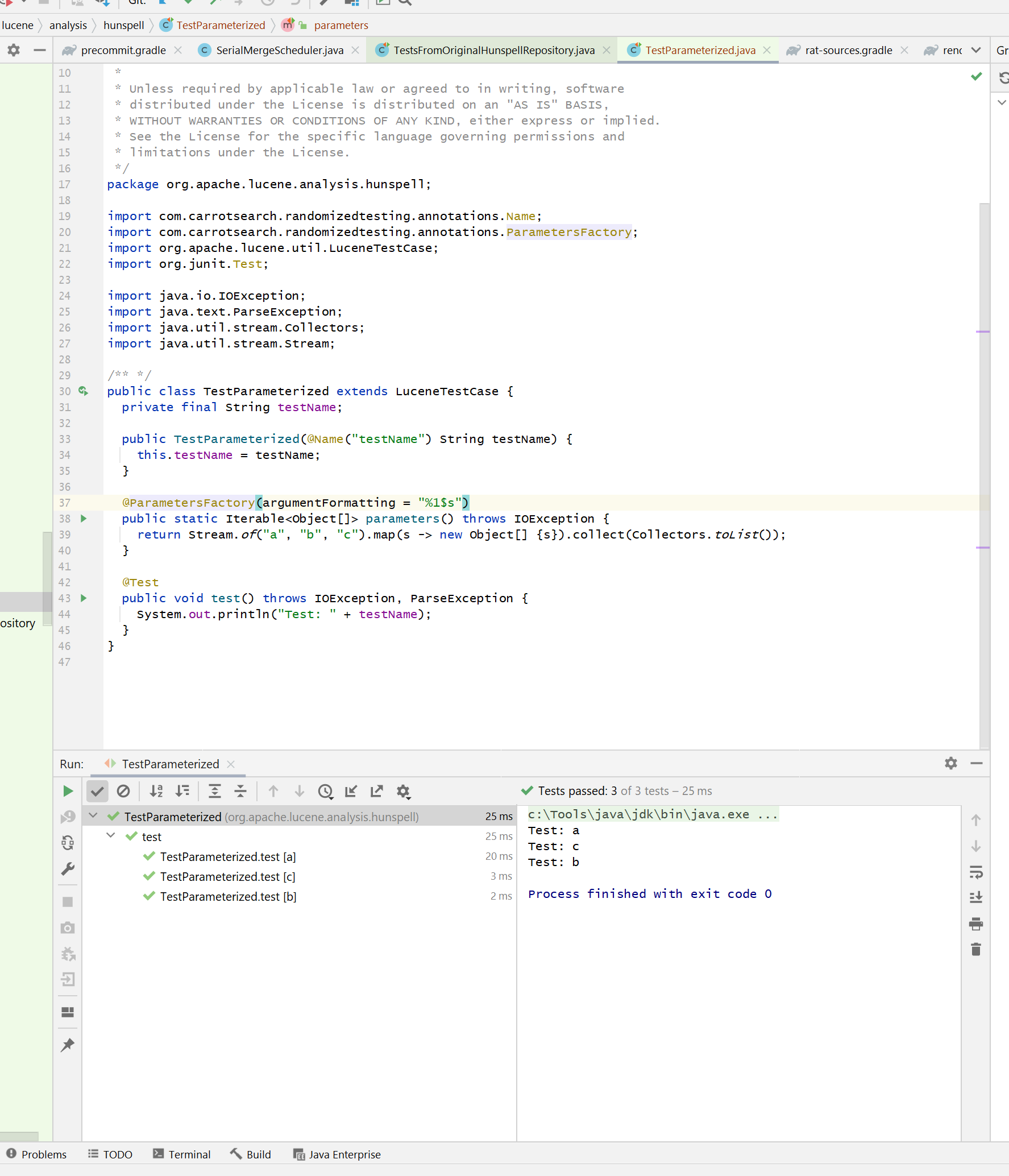
But when I run the same test via gradle launcher (from within the IDE), I
get this tree:
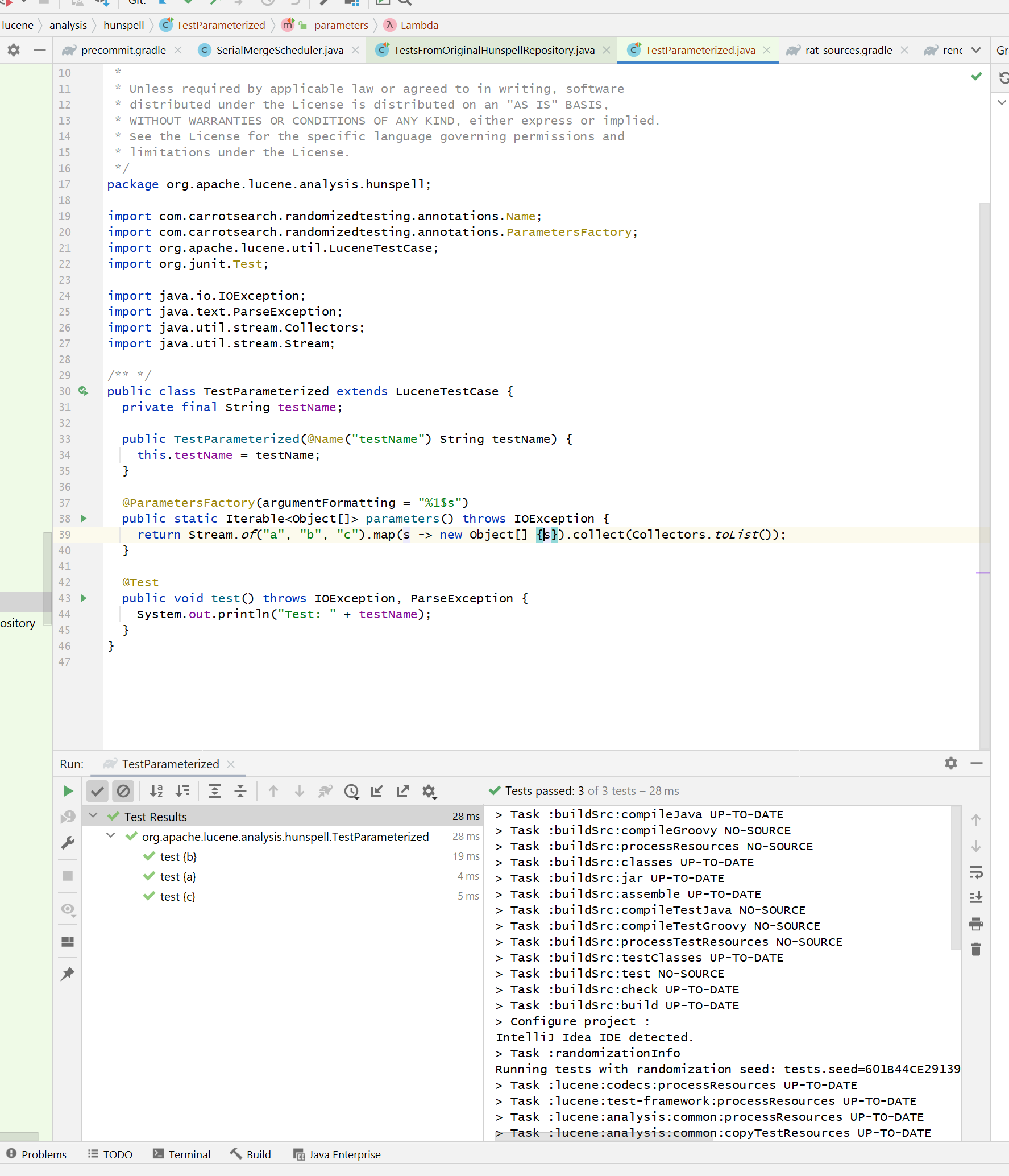
I don't know if there is a way to make all the tools happy; test
descriptions and nesting is broken in JUnit 4.x itself.
Given the above, please feel free to revert back to what works for you. I'd
name the test class TestHunspellRepositoryTestCases for clarity. Also, this
test will not run under Lucene test framework because the security manager
won't let you access arbitrary paths outside the build location. You'd need to
add this to tests.policy:
```
permission java.io.FilePermission "${hunspell.repo.path}${/}-", "read";
```
Don't know whether it's worth it at the moment though.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Resolved] (SOLR-15125) Link to docs is brroken
[ https://issues.apache.org/jira/browse/SOLR-15125?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Cassandra Targett resolved SOLR-15125. -- Resolution: Fixed The problem has been fixed and the docs are available again. > Link to docs is brroken > --- > > Key: SOLR-15125 > URL: https://issues.apache.org/jira/browse/SOLR-15125 > Project: Solr > Issue Type: Bug > Security Level: Public(Default Security Level. Issues are Public) > Components: website >Reporter: Thomas Güttler >Priority: Minor > > [On this page: > https://lucene.apache.org/solr/guide/|https://lucene.apache.org/solr/guide/] > the link to [https://lucene.apache.org/solr/guide/8_8/] > is broken. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Commented] (LUCENE-9718) REGEX Pattern Search, character classes with quantifiers do not work
[
https://issues.apache.org/jira/browse/LUCENE-9718?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276685#comment-17276685
]
Brian Feldman commented on LUCENE-9718:
---
1) User level documentation upstream in Solr or ElasticSearch there is limited
documentation. Receiving no error or results back from a search system, some
users might simply believe no matches exist, and not that their syntax is not
supported. I did not realize it was an issue until playing around with it.
2) Besides being documented, the code can be improved, only the initial parsing
code would need updating. It does not affect logic for the running of the
automaton. And since there is already code to support the character classes,
logically the parsing code should be completed to support the trailing
quantifiers, in order to finish the implementation for character classes.
> REGEX Pattern Search, character classes with quantifiers do not work
>
>
> Key: LUCENE-9718
> URL: https://issues.apache.org/jira/browse/LUCENE-9718
> Project: Lucene - Core
> Issue Type: Bug
> Components: core/search
>Affects Versions: 7.7.3, 8.6.3
>Reporter: Brian Feldman
>Priority: Minor
> Labels: Documentation, RegEx
>
> Character classes with a quantifier do not work, no error is given and no
> results are returned. For example \d\{2} or \d\{2,3} as is commonly written
> in most languages supporting regular expressions, simply and quietly does not
> work. A user work around is to write them fully out such as \d\d or
> [0-9][0-9] or as [0-9]\{2,3} .
>
> This inconsistency or limitation is not documented, wasting the time of users
> as they have to figure this out themselves. I believe this inconsistency
> should be clearly documented and an effort to fixing the inconsistency would
> improve pattern searching.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr-operator] thelabdude commented on a change in pull request #151: Integrate with cert-manager to issue TLS certs for Solr
thelabdude commented on a change in pull request #151:
URL:
https://github.com/apache/lucene-solr-operator/pull/151#discussion_r568152014
##
File path: main.go
##
@@ -65,6 +69,7 @@ func init() {
_ = solrv1beta1.AddToScheme(scheme)
_ = zkv1beta1.AddToScheme(scheme)
+ _ = certv1.AddToScheme(scheme)
// +kubebuilder:scaffold:scheme
flag.BoolVar(, "zk-operator", true, "The operator will
not use the zk operator & crd when this flag is set to false.")
Review comment:
From a reconcile perspective, we really only care about the TLS secret
that cert-manager creates once the Certificate is issued. The "watching" of the
Certificate to come online is really for status reporting while the cert is
issuing as it can take several minutes for the cert to be issued. Notice the
`isCertificateReady` is mostly about checking for the TLS secret.
The operator does create a Certificate for `autoCreate` mode but in that
case, the cert definition should come from the SolrCloud CRD and we don't want
to let users edit the Certificate externally; this is similar to the default
`solr.xml` ConfigMap and any direct edits to that cm are lost, same with
`autoCreate` certs.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] mrsoong closed pull request #1589: SOLR-13195: added check for missing shards param in SearchHandler
mrsoong closed pull request #1589: URL: https://github.com/apache/lucene-solr/pull/1589 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] mrsoong closed pull request #1472: SOLR-13184: Added some input validation in ValueSourceParser
mrsoong closed pull request #1472: URL: https://github.com/apache/lucene-solr/pull/1472 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr-operator] HoustonPutman commented on a change in pull request #151: Integrate with cert-manager to issue TLS certs for Solr
HoustonPutman commented on a change in pull request #151:
URL:
https://github.com/apache/lucene-solr-operator/pull/151#discussion_r568148914
##
File path: main.go
##
@@ -65,6 +69,7 @@ func init() {
_ = solrv1beta1.AddToScheme(scheme)
_ = zkv1beta1.AddToScheme(scheme)
+ _ = certv1.AddToScheme(scheme)
// +kubebuilder:scaffold:scheme
flag.BoolVar(, "zk-operator", true, "The operator will
not use the zk operator & crd when this flag is set to false.")
Review comment:
Ahh sorry for the confusion.
Yeah, it looks like Solr Operator is creating its own Secrets as well as
finding secrets created by CertManager. If that's the case, then I think we
will need both "Owns" and "Watches" with similar logic to the ConfigMaps. But I
may be wrong there, this is uncharted territory.
Are we sure we don't need to own Certificates? We wait for them to come
online, so we want to be notified when they have condition changes, right?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr-operator] thelabdude commented on a change in pull request #151: Integrate with cert-manager to issue TLS certs for Solr
thelabdude commented on a change in pull request #151:
URL:
https://github.com/apache/lucene-solr-operator/pull/151#discussion_r568141856
##
File path: main.go
##
@@ -65,6 +69,7 @@ func init() {
_ = solrv1beta1.AddToScheme(scheme)
_ = zkv1beta1.AddToScheme(scheme)
+ _ = certv1.AddToScheme(scheme)
// +kubebuilder:scaffold:scheme
flag.BoolVar(, "zk-operator", true, "The operator will
not use the zk operator & crd when this flag is set to false.")
Review comment:
Ok I see, I was confused because you put the comment on the
`AddToScheme` line so thought the problem was about that line of code.
I don't think the Solr operator needs to own `Certificate` objects ... all
it cares about is the TLS secret that gets created by the cert-manager in
response to a change to the `Certificate`. It seems like the secret changing
does trigger a reconcile in my testing but maybe we need to add a specific
watch for that secret changing like you did for user-provided ConfigMaps?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] dweiss commented on a change in pull request #2258: LUCENE-9686: Fix read past EOF handling in DirectIODirectory
dweiss commented on a change in pull request #2258:
URL: https://github.com/apache/lucene-solr/pull/2258#discussion_r568136570
##
File path:
lucene/misc/src/java/org/apache/lucene/misc/store/DirectIODirectory.java
##
@@ -381,17 +377,18 @@ public long length() {
@Override
public byte readByte() throws IOException {
if (!buffer.hasRemaining()) {
-refill();
+refill(1);
}
+
return buffer.get();
}
-private void refill() throws IOException {
+private void refill(int byteToRead) throws IOException {
Review comment:
Should it be plural (bytesToRead)?
##
File path:
lucene/misc/src/java/org/apache/lucene/misc/store/DirectIODirectory.java
##
@@ -381,17 +377,18 @@ public long length() {
@Override
public byte readByte() throws IOException {
if (!buffer.hasRemaining()) {
-refill();
+refill(1);
}
+
return buffer.get();
}
-private void refill() throws IOException {
+private void refill(int byteToRead) throws IOException {
filePos += buffer.capacity();
// BaseDirectoryTestCase#testSeekPastEOF test for consecutive read past
EOF,
// hence throwing EOFException early to maintain buffer state (position
in particular)
- if (filePos > channel.size()) {
+ if (filePos > channel.size() || (channel.size() - filePos < byteToRead))
{
Review comment:
I wonder if we should move the channel's position to actually point
after the last byte, then throw EOFException... so that not only we indicate an
EOF but also leave the channel pointing at the end. I have a scenario in my
mind when somebody tries to read a bulk of bytes, hits an eof but then a
single-byte read() succeeds. That would be awkward, wouldn't it?
A refill should try to read as many bytes as it can (min(channel.size()
-filePos, bytesToRead)), then potentially fail if bytesToRead is still >0 and
channel is at EOF. Or is my thinking flawed somewhere?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Commented] (SOLR-8319) NPE when creating pivot
[ https://issues.apache.org/jira/browse/SOLR-8319?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276653#comment-17276653 ] Houston Putman commented on SOLR-8319: -- The query isn't coming from QParser.parse. Instead QueryBuilder.createFieldQuery is explicitly returning a null Query in a few code paths, such as when there are no tokens contained within a field search value. This is hit when a stopword is provided as a value. > NPE when creating pivot > --- > > Key: SOLR-8319 > URL: https://issues.apache.org/jira/browse/SOLR-8319 > Project: Solr > Issue Type: Bug >Reporter: Neil Ireson >Priority: Major > Attachments: SOLR-8319.patch > > Time Spent: 10m > Remaining Estimate: 0h > > I get a NPE, the trace is shown at the end. > The problem seems to be this line in the getSubset method: > Query query = ft.getFieldQuery(null, field, pivotValue); > Which takes a value from the index and then analyses it to create a query. I > believe the problem is that when my analysis process is applied twice it > results in a null query. OK this might be seen as my issue because of dodgy > analysis, I thought it might be because I have the wrong order with > LengthFilterFactory before EnglishPossessiveFilterFactory and > KStemFilterFactory, i.e.: > > > > So that "cat's" -> "cat" -> "", however any filter order I tried still > resulted in a NPE, and perhaps there is a viable case where parsing a term > twice results in a null query. > The thing is I don't see why when the query term comes from the index it has > to undergo any analysis. If the term is from the index can it not simply be > created using a TermQuery, which I would imagine would also be faster. I > altered the "getFieldQuery" line above to the following and that has fixed my > NPE issue. > Query query = new TermQuery(new Term(field.getName(), pivotValue)); > So far this hasn't caused any other issues but perhaps that is due to my use > of Solr, rather than actually fixing an issue. > o.a.s.c.SolrCore java.lang.NullPointerException > at > java.util.concurrent.ConcurrentHashMap.get(ConcurrentHashMap.java:936) > at > org.apache.solr.util.ConcurrentLRUCache.get(ConcurrentLRUCache.java:91) > at org.apache.solr.search.FastLRUCache.get(FastLRUCache.java:130) > at > org.apache.solr.search.SolrIndexSearcher.getDocSet(SolrIndexSearcher.java:1296) > at > org.apache.solr.handler.component.PivotFacetProcessor.getSubset(PivotFacetProcessor.java:375) > at > org.apache.solr.handler.component.PivotFacetProcessor.doPivots(PivotFacetProcessor.java:305) > at > org.apache.solr.handler.component.PivotFacetProcessor.processSingle(PivotFacetProcessor.java:228) > at > org.apache.solr.handler.component.PivotFacetProcessor.process(PivotFacetProcessor.java:170) > at > org.apache.solr.handler.component.FacetComponent.process(FacetComponent.java:262) > at > org.apache.solr.handler.component.SearchHandler.handleRequestBody(SearchHandler.java:277) > at > org.apache.solr.handler.RequestHandlerBase.handleRequest(RequestHandlerBase.java:143) > at org.apache.solr.core.SolrCore.execute(SolrCore.java:2068) > at org.apache.solr.servlet.HttpSolrCall.execute(HttpSolrCall.java:669) > at org.apache.solr.servlet.HttpSolrCall.call(HttpSolrCall.java:462) > at > org.apache.solr.servlet.SolrDispatchFilter.doFilter(SolrDispatchFilter.java:214) > at > org.apache.solr.servlet.SolrDispatchFilter.doFilter(SolrDispatchFilter.java:179) > at > org.eclipse.jetty.servlet.ServletHandler$CachedChain.doFilter(ServletHandler.java:1652) > at > org.eclipse.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:585) > at > org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:143) > at > org.eclipse.jetty.security.SecurityHandler.handle(SecurityHandler.java:577) > at > org.eclipse.jetty.server.session.SessionHandler.doHandle(SessionHandler.java:223) > at > org.eclipse.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1127) > at > org.eclipse.jetty.servlet.ServletHandler.doScope(ServletHandler.java:515) > at > org.eclipse.jetty.server.session.SessionHandler.doScope(SessionHandler.java:185) > at > org.eclipse.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1061) > at > org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:141) > at > org.eclipse.jetty.server.handler.ContextHandlerCollection.handle(ContextHandlerCollection.java:215) > at > org.eclipse.jetty.server.handler.HandlerCollection.handle(HandlerCollection.java:110) > at >
[jira] [Commented] (SOLR-13209) NullPointerException from call in org.apache.solr.search.SolrIndexSearcher.getDocSet
[
https://issues.apache.org/jira/browse/SOLR-13209?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276644#comment-17276644
]
Isabelle Giguere commented on SOLR-13209:
-
[~cader.hancock] : Nothing to worry about. I get lost in Solr every time I get
back to it.
Grouping.java looks like a good place to start. It seems the request from the
description can go through the execute() method without error. Maybe that's
wanted. But if Grouping.CommandQuery expects to work with a valid "query",
then I think Grouping.CommandQuery.prepare() should throw an exception if
"query" is null ?
That's just from looking at the code, so, it needs testing.
> NullPointerException from call in
> org.apache.solr.search.SolrIndexSearcher.getDocSet
>
>
> Key: SOLR-13209
> URL: https://issues.apache.org/jira/browse/SOLR-13209
> Project: Solr
> Issue Type: Bug
>Affects Versions: master (9.0)
> Environment: h1. Steps to reproduce
> * Use a Linux machine.
> * Build commit {{ea2c8ba}} of Solr as described in the section below.
> * Build the films collection as described below.
> * Start the server using the command {{./bin/solr start -f -p 8983 -s
> /tmp/home}}
> * Request the URL given in the bug description.
> h1. Compiling the server
> {noformat}
> git clone https://github.com/apache/lucene-solr
> cd lucene-solr
> git checkout ea2c8ba
> ant compile
> cd solr
> ant server
> {noformat}
> h1. Building the collection and reproducing the bug
> We followed [Exercise
> 2|http://lucene.apache.org/solr/guide/7_5/solr-tutorial.html#exercise-2] from
> the [Solr
> Tutorial|http://lucene.apache.org/solr/guide/7_5/solr-tutorial.html].
> {noformat}
> mkdir -p /tmp/home
> echo '' >
> /tmp/home/solr.xml
> {noformat}
> In one terminal start a Solr instance in foreground:
> {noformat}
> ./bin/solr start -f -p 8983 -s /tmp/home
> {noformat}
> In another terminal, create a collection of movies, with no shards and no
> replication, and initialize it:
> {noformat}
> bin/solr create -c films
> curl -X POST -H 'Content-type:application/json' --data-binary '{"add-field":
> {"name":"name", "type":"text_general", "multiValued":false, "stored":true}}'
> http://localhost:8983/solr/films/schema
> curl -X POST -H 'Content-type:application/json' --data-binary
> '{"add-copy-field" : {"source":"*","dest":"_text_"}}'
> http://localhost:8983/solr/films/schema
> ./bin/post -c films example/films/films.json
> curl -v “URL_BUG”
> {noformat}
> Please check the issue description below to find the “URL_BUG” that will
> allow you to reproduce the issue reported.
>Reporter: Cesar Rodriguez
>Priority: Minor
> Labels: diffblue, newdev
> Time Spent: 40m
> Remaining Estimate: 0h
>
> Requesting the following URL causes Solr to return an HTTP 500 error response:
> {noformat}
> http://localhost:8983/solr/films/select?group=true
> {noformat}
> The error response seems to be caused by the following uncaught exception:
> {noformat}
> java.lang.NullPointerException
> at
> java.util.concurrent.ConcurrentHashMap.get(ConcurrentHashMap.java:936)
> at
> org.apache.solr.util.ConcurrentLRUCache.get(ConcurrentLRUCache.java:124)
> at org.apache.solr.search.FastLRUCache.get(FastLRUCache.java:163)
> at
> org.apache.solr.search.SolrIndexSearcher.getDocSet(SolrIndexSearcher.java:792)
> at
> org.apache.solr.search.Grouping$CommandQuery.createFirstPassCollector(Grouping.java:860)
> at org.apache.solr.search.Grouping.execute(Grouping.java:327)
> at
> org.apache.solr.handler.component.QueryComponent.doProcessGroupedSearch(QueryComponent.java:1408)
> at
> org.apache.solr.handler.component.QueryComponent.process(QueryComponent.java:365)
> at
> org.apache.solr.handler.component.SearchHandler.handleRequestBody(SearchHandler.java:298)
> at
> org.apache.solr.handler.RequestHandlerBase.handleRequest(RequestHandlerBase.java:199)
> at org.apache.solr.core.SolrCore.execute(SolrCore.java:2559)
> [...]
> {noformat}
> Method {{org.apache.solr.search.SolrIndexSearcher.getDocSet()}}, at line 792
> calls {{filterCache.get(absQ)}} where {{absQ}} is a null pointer. I think
> this null pointer comes in fact from the caller, but I don't fully follow the
> logic of the code.
> To set up an environment to reproduce this bug, follow the description in the
> ‘Environment’ field.
> We automatically found this issue and ~70 more like this using [Diffblue
> Microservices Testing|https://www.diffblue.com/labs/?utm_source=solr-br].
> Find more information on this [fuzz testing
> campaign|https://www.diffblue.com/blog/2018/12/19/diffblue-microservice-testing-a-sneak-peek-at-our-early-product-and-results?utm_source=solr-br].
--
This message was sent by Atlassian
[GitHub] [lucene-solr-operator] thelabdude commented on a change in pull request #151: Integrate with cert-manager to issue TLS certs for Solr
thelabdude commented on a change in pull request #151:
URL:
https://github.com/apache/lucene-solr-operator/pull/151#discussion_r568133031
##
File path: controllers/solrcloud_controller.go
##
@@ -772,3 +848,188 @@ func (r *SolrCloudReconciler)
indexAndWatchForProvidedConfigMaps(mgr ctrl.Manage
},
builder.WithPredicates(predicate.ResourceVersionChangedPredicate{})), nil
}
+
+// Reconciles the TLS cert, returns either a bool to indicate if the cert is
ready or an error
+func (r *SolrCloudReconciler) reconcileAutoCreateTLS(ctx context.Context,
instance *solr.SolrCloud) (bool, error) {
+
+ // short circuit this method with a quick check if the cert exists and
is ready
+ // this is useful b/c it may take many minutes for a cert to be issued,
so we avoid
+ // all the other checking that happens below while we're waiting for
the cert
+ foundCert := {}
+ if err := r.Get(ctx, types.NamespacedName{Name:
instance.Spec.SolrTLS.AutoCreate.Name, Namespace: instance.Namespace},
foundCert); err == nil {
+ // cert exists, but is it ready? need to wait until we see the
TLS secret
+ if foundTLSSecret := r.isCertificateReady(ctx, foundCert,
instance.Spec.SolrTLS); foundTLSSecret != nil {
+ cert := util.GenerateCertificate(instance)
+ return r.afterCertificateReady(ctx, instance, ,
foundCert, foundTLSSecret)
+ }
+ }
+
+ r.Log.Info("Reconciling TLS config", "tls", instance.Spec.SolrTLS)
+
+ // cert not found, do full reconcile for TLS ...
+ var err error
+ var tlsReady bool
+
+ // First, create the keystore password secret if needed
+ keystoreSecret := util.GenerateKeystoreSecret(instance)
+ foundSecret := {}
+ err = r.Get(ctx, types.NamespacedName{Name: keystoreSecret.Name,
Namespace: keystoreSecret.Namespace}, foundSecret)
+ if err != nil && errors.IsNotFound(err) {
+ r.Log.Info("Creating keystore secret", "namespace",
keystoreSecret.Namespace, "name", keystoreSecret.Name)
+ if err := controllerutil.SetControllerReference(instance,
, r.scheme); err != nil {
+ return false, err
+ }
+ err = r.Create(ctx, )
+ }
+ if err != nil {
+ return false, err
+ }
+
+ // Create a self-signed cert issuer if no issuerRef provided
+ if instance.Spec.SolrTLS.AutoCreate.IssuerRef == nil {
+ issuerName := fmt.Sprintf("%s-selfsigned-issuer", instance.Name)
+ foundIssuer := {}
+ err = r.Get(ctx, types.NamespacedName{Name: issuerName,
Namespace: instance.Namespace}, foundIssuer)
+ if err != nil && errors.IsNotFound(err) {
+ // specified Issuer not found, let's go create a
self-signed for this
+ issuer := util.GenerateSelfSignedIssuer(instance,
issuerName)
+ if err :=
controllerutil.SetControllerReference(instance, , r.scheme); err != nil {
+ return false, err
+ }
+ r.Log.Info("Creating Self-signed Certificate Issuer",
"issuer", issuer)
+ err = r.Create(ctx, )
+ } else if err == nil {
+ r.Log.Info("Found Self-signed Certificate Issuer",
"issuer", issuerName)
+ }
+ if err != nil {
+ return false, err
+ }
+ } else {
+ // real problems arise if we create the Certificate and the
Issuer doesn't exist so make we have a good config here
+ if instance.Spec.SolrTLS.AutoCreate.IssuerRef.Kind == "Issuer" {
+ foundIssuer := {}
+ err = r.Get(ctx, types.NamespacedName{Name:
instance.Spec.SolrTLS.AutoCreate.IssuerRef.Name, Namespace:
instance.Namespace}, foundIssuer)
+ if err != nil {
+ if errors.IsNotFound(err) {
+ r.Log.Info("cert-manager Issuer not
found in namespace, cannot create a TLS certificate without an Issuer",
+ "issuer",
instance.Spec.SolrTLS.AutoCreate.IssuerRef.Name, "ns", instance.Namespace)
+ }
+ return false, err
+ }
+ } // else assume ClusterIssuer and good luck
+ }
+
+ // Reconcile the Certificate to use for TLS ... A Certificate is a
request to Issue the cert, the
+ // actual cert lives in a TLS secret created by the Issuer
+ cert := util.GenerateCertificate(instance)
+ err = r.Get(ctx, types.NamespacedName{Name: cert.Name, Namespace:
cert.Namespace}, foundCert)
+ if err != nil && errors.IsNotFound(err) {
+
[GitHub] [lucene-solr-operator] thelabdude commented on a change in pull request #151: Integrate with cert-manager to issue TLS certs for Solr
thelabdude commented on a change in pull request #151:
URL:
https://github.com/apache/lucene-solr-operator/pull/151#discussion_r568132449
##
File path: controllers/solrcloud_controller.go
##
@@ -772,3 +848,188 @@ func (r *SolrCloudReconciler)
indexAndWatchForProvidedConfigMaps(mgr ctrl.Manage
},
builder.WithPredicates(predicate.ResourceVersionChangedPredicate{})), nil
}
+
+// Reconciles the TLS cert, returns either a bool to indicate if the cert is
ready or an error
+func (r *SolrCloudReconciler) reconcileAutoCreateTLS(ctx context.Context,
instance *solr.SolrCloud) (bool, error) {
+
+ // short circuit this method with a quick check if the cert exists and
is ready
+ // this is useful b/c it may take many minutes for a cert to be issued,
so we avoid
+ // all the other checking that happens below while we're waiting for
the cert
+ foundCert := {}
+ if err := r.Get(ctx, types.NamespacedName{Name:
instance.Spec.SolrTLS.AutoCreate.Name, Namespace: instance.Namespace},
foundCert); err == nil {
+ // cert exists, but is it ready? need to wait until we see the
TLS secret
+ if foundTLSSecret := r.isCertificateReady(ctx, foundCert,
instance.Spec.SolrTLS); foundTLSSecret != nil {
+ cert := util.GenerateCertificate(instance)
+ return r.afterCertificateReady(ctx, instance, ,
foundCert, foundTLSSecret)
+ }
+ }
+
+ r.Log.Info("Reconciling TLS config", "tls", instance.Spec.SolrTLS)
+
+ // cert not found, do full reconcile for TLS ...
+ var err error
+ var tlsReady bool
+
+ // First, create the keystore password secret if needed
+ keystoreSecret := util.GenerateKeystoreSecret(instance)
+ foundSecret := {}
+ err = r.Get(ctx, types.NamespacedName{Name: keystoreSecret.Name,
Namespace: keystoreSecret.Namespace}, foundSecret)
+ if err != nil && errors.IsNotFound(err) {
+ r.Log.Info("Creating keystore secret", "namespace",
keystoreSecret.Namespace, "name", keystoreSecret.Name)
+ if err := controllerutil.SetControllerReference(instance,
, r.scheme); err != nil {
+ return false, err
+ }
+ err = r.Create(ctx, )
+ }
+ if err != nil {
+ return false, err
+ }
+
+ // Create a self-signed cert issuer if no issuerRef provided
+ if instance.Spec.SolrTLS.AutoCreate.IssuerRef == nil {
+ issuerName := fmt.Sprintf("%s-selfsigned-issuer", instance.Name)
+ foundIssuer := {}
+ err = r.Get(ctx, types.NamespacedName{Name: issuerName,
Namespace: instance.Namespace}, foundIssuer)
+ if err != nil && errors.IsNotFound(err) {
+ // specified Issuer not found, let's go create a
self-signed for this
+ issuer := util.GenerateSelfSignedIssuer(instance,
issuerName)
+ if err :=
controllerutil.SetControllerReference(instance, , r.scheme); err != nil {
+ return false, err
+ }
+ r.Log.Info("Creating Self-signed Certificate Issuer",
"issuer", issuer)
+ err = r.Create(ctx, )
+ } else if err == nil {
+ r.Log.Info("Found Self-signed Certificate Issuer",
"issuer", issuerName)
+ }
+ if err != nil {
+ return false, err
+ }
+ } else {
+ // real problems arise if we create the Certificate and the
Issuer doesn't exist so make we have a good config here
+ if instance.Spec.SolrTLS.AutoCreate.IssuerRef.Kind == "Issuer" {
+ foundIssuer := {}
+ err = r.Get(ctx, types.NamespacedName{Name:
instance.Spec.SolrTLS.AutoCreate.IssuerRef.Name, Namespace:
instance.Namespace}, foundIssuer)
+ if err != nil {
+ if errors.IsNotFound(err) {
+ r.Log.Info("cert-manager Issuer not
found in namespace, cannot create a TLS certificate without an Issuer",
+ "issuer",
instance.Spec.SolrTLS.AutoCreate.IssuerRef.Name, "ns", instance.Namespace)
+ }
+ return false, err
+ }
+ } // else assume ClusterIssuer and good luck
+ }
+
+ // Reconcile the Certificate to use for TLS ... A Certificate is a
request to Issue the cert, the
+ // actual cert lives in a TLS secret created by the Issuer
+ cert := util.GenerateCertificate(instance)
+ err = r.Get(ctx, types.NamespacedName{Name: cert.Name, Namespace:
cert.Namespace}, foundCert)
+ if err != nil && errors.IsNotFound(err) {
+
[GitHub] [lucene-solr-operator] thelabdude commented on a change in pull request #151: Integrate with cert-manager to issue TLS certs for Solr
thelabdude commented on a change in pull request #151:
URL:
https://github.com/apache/lucene-solr-operator/pull/151#discussion_r568131545
##
File path: controllers/util/common.go
##
@@ -248,6 +248,11 @@ func CopyIngressFields(from, to *extv1.Ingress, logger
logr.Logger) bool {
}
}
+ if !requireUpdate && !DeepEqualWithNils(to.Spec.TLS, from.Spec.TLS) {
Review comment:
just a mistake
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr-operator] HoustonPutman commented on a change in pull request #151: Integrate with cert-manager to issue TLS certs for Solr
HoustonPutman commented on a change in pull request #151:
URL:
https://github.com/apache/lucene-solr-operator/pull/151#discussion_r568129098
##
File path: main.go
##
@@ -65,6 +69,7 @@ func init() {
_ = solrv1beta1.AddToScheme(scheme)
_ = zkv1beta1.AddToScheme(scheme)
+ _ = certv1.AddToScheme(scheme)
// +kubebuilder:scaffold:scheme
flag.BoolVar(, "zk-operator", true, "The operator will
not use the zk operator & crd when this flag is set to false.")
Review comment:
Add to scheme is fine, the boolean is used when setting up the
controller and determining whether to set "Owns" for that resource.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr-operator] thelabdude commented on a change in pull request #151: Integrate with cert-manager to issue TLS certs for Solr
thelabdude commented on a change in pull request #151:
URL:
https://github.com/apache/lucene-solr-operator/pull/151#discussion_r568127921
##
File path: main.go
##
@@ -65,6 +69,7 @@ func init() {
_ = solrv1beta1.AddToScheme(scheme)
_ = zkv1beta1.AddToScheme(scheme)
+ _ = certv1.AddToScheme(scheme)
// +kubebuilder:scaffold:scheme
flag.BoolVar(, "zk-operator", true, "The operator will
not use the zk operator & crd when this flag is set to false.")
Review comment:
As far as I've seen, calling `AddToScheme` works even if the
Cert-manager CRDs are not installed so not sure a flag is technically needed
but doesn't hurt to add one.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Comment Edited] (LUCENE-9705) Move all codec formats to the o.a.l.codecs.Lucene90 package
[
https://issues.apache.org/jira/browse/LUCENE-9705?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276599#comment-17276599
]
Julie Tibshirani edited comment on LUCENE-9705 at 2/1/21, 8:44 PM:
---
{quote}It's especially clear here where we must copy a lot of classes with no
change at all, merely to clearly and consistently document the index version
change.
{quote}
I’ll try to add some context since I suspect there might be misunderstanding.
In general when there is a new major version, we *do not* plan to create all
new index format classes. We only copy a class and move it to backwards-codecs
when there is a change to that specific format, for example {{PointsFormat}}.
This proposal applies only to the 9.0 release, and its main purpose is to
support the work in LUCENE-9047 to move all formats to little endian. My
understanding is that moving to little endian impacts all the formats and will
be much cleaner if we used these fresh {{Lucene90*Format}}.
{quote}I wonder if we (eventually) should consider shifting to a versioning
system that doesn't require new classes. Is this somehow a feature of the
service discovery API that we use?
{quote}
We indeed load codecs (with their formats) through service discovery. If a user
wants to read indices from a previous version, they can depend on
backwards-codecs so Lucene loads the correct older codec. As of LUCENE-9669, we
allow reading indices back to major version N-2.
I personally really like the current "copy-on-write" system for formats.
There’s code duplication, but it has advantages over combining different
version logic in the same file:
* It’s really clear how each version behaves. Having a direct copy like
{{Lucene70Codec}} is almost as if we were pulling in jars from Lucene 7.0.
* It decreases risk of introducing bugs or accidental changes. If you’re
making an enhancement to a new format, there’s little chance of changing the
logic for an old format (since it lives in a separate class). This is
especially important since older formats are not tested as thoroughly.
I started to appreciate it after experiencing the alternative in Elasticsearch,
where we’re constantly bumping into if/ else version checks when making changes.
was (Author: julietibs):
{quote}It's especially clear here where we must copy a lot of classes with no
change at all, merely to clearly and consistently document the index version
change.
{quote}
I’ll try to add some context since I suspect there might be misunderstanding.
In general when there is a new major version, we *do not* plan to create all
new index format classes. We only copy a class and move it to backwards-codecs
when there is a change to that specific format, for example {{PointsFormat}}.
This proposal applies only to the 9.0 release, and its main purpose is to
support the work in LUCENE-9047 to move all formats to little endian. My
understanding is that moving to little endian impacts all the formats and will
be much cleaner if we used these fresh {{Lucene90*Format}}.
{quote}I wonder if we (eventually) should consider shifting to a versioning
system that doesn't require new classes. Is this somehow a feature of the
service discovery API that we use?
{quote}
We indeed load codecs (with their formats) through a service discovery API. If
a user wants to read indices from a previous version, they can depend on
backwards-codecs so Lucene loads the correct older codec. As of LUCENE-9669, we
allow reading indices back to major version N-2.
I personally really like the current "copy-on-write" system for formats.
There’s code duplication, but it has advantages over combining different
version logic in the same file:
* It’s really clear how each version behaves. Having a direct copy like
{{Lucene70Codec}} is almost as if we were pulling in the codec jars from Lucene
7.0.
* It decreases risk of introducing bugs or accidental changes. If you’re
making an enhancement to a new format, there’s little chance of changing the
logic for an old format (since it lives in a separate class). This is
especially important since older formats are not tested as thoroughly.
I started to appreciate it after experiencing the alternative in Elasticsearch,
where we’re constantly bumping into if/ else version checks when making changes.
> Move all codec formats to the o.a.l.codecs.Lucene90 package
> ---
>
> Key: LUCENE-9705
> URL: https://issues.apache.org/jira/browse/LUCENE-9705
> Project: Lucene - Core
> Issue Type: Wish
>Reporter: Ignacio Vera
>Priority: Major
> Time Spent: 50m
> Remaining Estimate: 0h
>
> Current formats are distributed in different packages, prefixed with the
> Lucene version they were created. With the upcoming release of Lucene 9.0, it
>
[GitHub] [lucene-solr-operator] thelabdude commented on a change in pull request #151: Integrate with cert-manager to issue TLS certs for Solr
thelabdude commented on a change in pull request #151:
URL:
https://github.com/apache/lucene-solr-operator/pull/151#discussion_r568114059
##
File path: controllers/solrcloud_controller.go
##
@@ -261,12 +268,77 @@ func (r *SolrCloudReconciler) Reconcile(req ctrl.Request)
(ctrl.Result, error) {
blockReconciliationOfStatefulSet = true
}
+ tlsCertMd5 := ""
+ needsPkcs12InitContainer := false // flag if the StatefulSet needs an
additional initCont to create PKCS12 keystore
+ // don't start reconciling TLS until we have ZK connectivity, avoids
TLS code having to check for ZK
+ if !blockReconciliationOfStatefulSet && instance.Spec.SolrTLS != nil {
+ ctx := context.TODO()
+ // Create the autogenerated TLS Cert and wait for it to be
issued
+ if instance.Spec.SolrTLS.AutoCreate != nil {
+ tlsReady, err := r.reconcileAutoCreateTLS(ctx, instance)
+ // don't create the StatefulSet until we have a cert,
which can take a while for a Let's Encrypt Issuer
+ if !tlsReady || err != nil {
+ if err != nil {
+ r.Log.Error(err, "Reconcile TLS
Certificate failed")
+ } else {
+ wait := 30 * time.Second
+ if
instance.Spec.SolrTLS.AutoCreate.IssuerRef == nil {
+ // this is a self-signed cert,
so no need to wait very long for it to issue
+ wait = 2 * time.Second
+ }
+ requeueOrNot.RequeueAfter = wait
+ }
+ return requeueOrNot, err
Review comment:
Certs can take several minutes to issue, so I think we want to return
here with the extended wait period otherwise you get a ton of noise in the logs
until the cert issues ...
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] msokolov commented on a change in pull request #2256: LUCENE-9507 Custom order for leaves in IndexReader and IndexWriter
msokolov commented on a change in pull request #2256:
URL: https://github.com/apache/lucene-solr/pull/2256#discussion_r568113101
##
File path: lucene/core/src/java/org/apache/lucene/index/IndexWriter.java
##
@@ -941,6 +969,11 @@ public IndexWriter(Directory d, IndexWriterConfig conf)
throws IOException {
// obtain the write.lock. If the user configured a timeout,
// we wrap with a sleeper and this might take some time.
writeLock = d.obtainLock(WRITE_LOCK_NAME);
+if (config.getIndexSort() != null && leafSorter != null) {
+ throw new IllegalArgumentException(
+ "[IndexWriter] can't use index sort and leaf sorter at the same
time!");
Review comment:
Hmm I do see where you said we want to use `leafSorter` to sort
documents. I guess I might challenge that design in favor of building on the
`indexSort` we already have? But perhaps this is better sorted out in the
context of a later PR, as you suggested.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] msokolov commented on a change in pull request #2256: LUCENE-9507 Custom order for leaves in IndexReader and IndexWriter
msokolov commented on a change in pull request #2256:
URL: https://github.com/apache/lucene-solr/pull/2256#discussion_r568110673
##
File path: lucene/core/src/java/org/apache/lucene/index/IndexWriter.java
##
@@ -941,6 +969,11 @@ public IndexWriter(Directory d, IndexWriterConfig conf)
throws IOException {
// obtain the write.lock. If the user configured a timeout,
// we wrap with a sleeper and this might take some time.
writeLock = d.obtainLock(WRITE_LOCK_NAME);
+if (config.getIndexSort() != null && leafSorter != null) {
+ throw new IllegalArgumentException(
+ "[IndexWriter] can't use index sort and leaf sorter at the same
time!");
Review comment:
OK, maybe I misunderstood the intent. Perhaps an example would clarify.
Say that we have three segments, A, B , C containing documents `A={0, 3, 6};
B={1, 4, 7}; C={2, 5, 8}`, where the documents are understood to have a single
field with the value shown, and the index sort is ordered in the natural way.
Without this change, if we merged A and B, we'd get a new segment `A+B={0, 1,
3, 4, 6, 7}`. Now suppose there is no index sort (and the documents just
"happen" to be in the index in the order given above, for the sake of the
example), and we apply a `leafSorter` that sorts by the minimum value of any
document in the segment (I guess it could be any sort of aggregate over the
segment?), then we would get `A+B={0, 3, 6, 1, 4, 7}`. Now if we apply both
sorts, we would get the same result as in the first case, right? I'm still
unclear how the conflict arises.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] msokolov commented on a change in pull request #2231: LUCENE-9680 - Re-add IndexWriter::getFieldNames
msokolov commented on a change in pull request #2231:
URL: https://github.com/apache/lucene-solr/pull/2231#discussion_r568105107
##
File path: lucene/core/src/test/org/apache/lucene/index/TestIndexWriter.java
##
@@ -4600,4 +4600,49 @@ public void testIndexWriterBlocksOnStall() throws
IOException, InterruptedExcept
}
}
}
+
+ public void testGetFieldNames() throws IOException {
+Directory dir = newDirectory();
+
+IndexWriter writer = new IndexWriter(dir, newIndexWriterConfig(new
MockAnalyzer(random(;
+
+assertEquals(Set.of(), writer.getFieldNames());
+
+addDocWithField(writer, "f1");
+assertEquals(Set.of("f1"), writer.getFieldNames());
+
+// should be unmodifiable:
+final Set fieldSet = writer.getFieldNames();
+assertThrows(UnsupportedOperationException.class, () ->
fieldSet.add("cannot modify"));
+assertThrows(UnsupportedOperationException.class, () ->
fieldSet.remove("f1"));
+
+addDocWithField(writer, "f2");
+assertEquals(Set.of("f1", "f2"), writer.getFieldNames());
Review comment:
Let's also assert that the original `fieldSet` has not been modified -
it was a true copy and not some kind of alias over an underlying modifiable Set?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Commented] (LUCENE-9718) REGEX Pattern Search, character classes with quantifiers do not work
[
https://issues.apache.org/jira/browse/LUCENE-9718?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276618#comment-17276618
]
Michael Sokolov commented on LUCENE-9718:
-
I guess we come to expect PCRE in every implementation, but this is not that.
By the way, not even Java is totally compatible with Perl I think. So it's not
expected that numeric quantifiers in curly braces should work - this is not a
PCRE implementation.
Further, the supported syntax is clearly documented in `RegExp`'s javadocs, and
there is a pointer there from `RegExpQuery`:
{{ * The supported syntax is documented in the {@link RegExp} class. Note
this might be different
* than other regular expression implementations. For some alternatives with
different syntax, look
* under the sandbox.}}
Did you try raising the issue on one of the mailing lists before opening this
issue? That's usually best.
> REGEX Pattern Search, character classes with quantifiers do not work
>
>
> Key: LUCENE-9718
> URL: https://issues.apache.org/jira/browse/LUCENE-9718
> Project: Lucene - Core
> Issue Type: Bug
> Components: core/search
>Affects Versions: 7.7.3, 8.6.3
>Reporter: Brian Feldman
>Priority: Minor
>
> Character classes with a quantifier do not work, no error is given and no
> results are returned. For example \d\{2} or \d\{2,3} as is commonly written
> in most languages supporting regular expressions, simply and quietly does not
> work. A user work around is to write them fully out such as \d\d or
> [0-9][0-9] or as [0-9]\{2,3} .
>
> This inconsistency or limitation is not documented, wasting the time of users
> as they have to figure this out themselves. I believe this inconsistency
> should be clearly documented and an effort to fixing the inconsistency would
> improve pattern searching.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] mayya-sharipova commented on a change in pull request #2256: LUCENE-9507 Custom order for leaves in IndexReader and IndexWriter
mayya-sharipova commented on a change in pull request #2256:
URL: https://github.com/apache/lucene-solr/pull/2256#discussion_r568095366
##
File path: lucene/core/src/java/org/apache/lucene/index/IndexWriter.java
##
@@ -933,6 +936,31 @@ protected final void ensureOpen() throws
AlreadyClosedException {
* low-level IO error
*/
public IndexWriter(Directory d, IndexWriterConfig conf) throws IOException {
+this(d, conf, null);
+ }
+
+ /**
+ * Constructs a new IndexWriter per the settings given in conf.
If you want to make
+ * "live" changes to this writer instance, use {@link #getConfig()}.
+ *
+ * NOTE: after ths writer is created, the given configuration
instance cannot be passed
+ * to another writer.
+ *
+ * @param d the index directory. The index is either created or appended
according
+ * conf.getOpenMode().
+ * @param conf the configuration settings according to which IndexWriter
should be initialized.
+ * @param leafSorter a comparator for sorting leaf readers. Providing
leafSorter is useful for
+ * indices on which it is expected to run many queries with particular
sort criteria (e.g. for
+ * time-based indices this is usually a descending sort on timestamp).
In this case {@code
+ * leafSorter} should sort leaves according to this sort criteria.
Providing leafSorter allows
+ * to speed up this particular type of sort queries by early terminating
while iterating
+ * though segments and segments' documents.
+ * @throws IOException if the directory cannot be read/written to, or if it
does not exist and
+ * conf.getOpenMode() is OpenMode.APPEND or if
there is any other
+ * low-level IO error
+ */
+ public IndexWriter(Directory d, IndexWriterConfig conf,
Comparator leafSorter)
Review comment:
Addressed in 7ddff67
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] mayya-sharipova commented on a change in pull request #2256: LUCENE-9507 Custom order for leaves in IndexReader and IndexWriter
mayya-sharipova commented on a change in pull request #2256:
URL: https://github.com/apache/lucene-solr/pull/2256#discussion_r568095174
##
File path: lucene/core/src/java/org/apache/lucene/index/IndexWriter.java
##
@@ -941,6 +969,11 @@ public IndexWriter(Directory d, IndexWriterConfig conf)
throws IOException {
// obtain the write.lock. If the user configured a timeout,
// we wrap with a sleeper and this might take some time.
writeLock = d.obtainLock(WRITE_LOCK_NAME);
+if (config.getIndexSort() != null && leafSorter != null) {
+ throw new IllegalArgumentException(
+ "[IndexWriter] can't use index sort and leaf sorter at the same
time!");
Review comment:
@msokolov Thank you for your feedback and explanation. Sorry, I am still
not super clear about this point. It seems to me as `indexSorter` maps each
leaf's documents into the merged segment according to its sort, the same way
`leafSorter` will map each leaf's documents into the merged segment according
to its sort (given several merging segments, in the merged segment the first
docs should be docs from a segment with highest sort values..)
But I am ok to remove this check in this PR, as this PR is not concerned
with merging, and follow up on this point in the following PR.
Addressed in 7ddff6775c8
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] epugh commented on a change in pull request #2275: SOLR-15123: Make all Tool option descriptions follow the same general pattern.
epugh commented on a change in pull request #2275:
URL: https://github.com/apache/lucene-solr/pull/2275#discussion_r568092337
##
File path: solr/core/src/java/org/apache/solr/util/ExportTool.java
##
@@ -216,32 +216,32 @@ void end() throws IOException {
Option.builder("url")
.hasArg()
.required()
- .desc("Address of the collection, example
http://localhost:8983/solr/gettingstarted;)
+ .desc("Address of the collection, example
http://localhost:8983/solr/gettingstarted.;)
Review comment:
also, we do this a lot for the ZooKeeper host:
```
.desc("Address of the ZooKeeper ensemble; defaults to: " + ZK_HOST + '.')
```
Maybe convert those to
```
.desc("Address of the ZooKeeper ensemble; defaults to: '" + ZK_HOST + "'.")
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Comment Edited] (LUCENE-9705) Move all codec formats to the o.a.l.codecs.Lucene90 package
[
https://issues.apache.org/jira/browse/LUCENE-9705?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276599#comment-17276599
]
Julie Tibshirani edited comment on LUCENE-9705 at 2/1/21, 7:44 PM:
---
{quote}It's especially clear here where we must copy a lot of classes with no
change at all, merely to clearly and consistently document the index version
change.
{quote}
I’ll try to add some context since I suspect there might be misunderstanding.
In general when there is a new major version, we *do not* plan to create all
new index format classes. We only copy a class and move it to backwards-codecs
when there is a change to that specific format, for example {{PointsFormat}}.
This proposal applies only to the 9.0 release, and its main purpose is to
support the work in LUCENE-9047 to move all formats to little endian. My
understanding is that moving to little endian impacts all the formats and will
be much cleaner if we used these fresh {{Lucene90*Format}}.
{quote}I wonder if we (eventually) should consider shifting to a versioning
system that doesn't require new classes. Is this somehow a feature of the
service discovery API that we use?
{quote}
We indeed load codecs (with their formats) through a service discovery API. If
a user wants to read indices from a previous version, they can depend on
backwards-codecs so Lucene loads the correct older codec. As of LUCENE-9669, we
allow reading indices back to major version N-2.
I personally really like the current "copy-on-write" system for formats.
There’s code duplication, but it has advantages over combining different
version logic in the same file:
* It’s really clear how each version behaves. Having a direct copy like
{{Lucene70Codec}} is almost as if we were pulling in the codec jars from Lucene
7.0.
* It decreases risk of introducing bugs or accidental changes. If you’re
making an enhancement to a new format, there’s little chance of changing the
logic for an old format (since it lives in a separate class). This is
especially important since older formats are not tested as thoroughly.
I started to appreciate it after experiencing the alternative in Elasticsearch,
where we’re constantly bumping into if/ else version checks when making changes.
was (Author: julietibs):
{quote}It's especially clear here where we must copy a lot of classes with no
change at all, merely to clearly and consistently document the index version
change.
{quote}
I’ll try to add some context since I suspect there might be misunderstanding.
In general when there is a new major version, we *do not* plan to create all
new index format classes. We only copy a class and move it to backwards-codecs
when there is a change to that specific format, for example {{PointsFormat}}.
This proposal applies only to the 9.0 release, and its main purpose is to
support the work in LUCENE-9047 to move all formats to little endian. My
understanding is that moving to little endian impacts all the formats and will
be much cleaner if we used these fresh {{Lucene90*Format}}.
{quote}I wonder if we (eventually) should consider shifting to a versioning
system that doesn't require new classes. Is this somehow a feature of the
service discovery API that we use?
{quote}
We indeed load codecs (with their formats) through a service discovery API. If
a user wants to read indices from a previous major version, they can depend on
backwards-codecs so Lucene loads the correct older codec. As of LUCENE-9669, we
allow reading indices back to version N-2.
I personally really like the current "copy-on-write" system for formats.
There’s code duplication, but it has advantages over combining different
version logic in the same file:
* It’s really clear how each version behaves. Having a direct copy like
{{Lucene70Codec}} is almost as if we were pulling in the codec jars from Lucene
7.0.
* It decreases risk of introducing bugs or accidental changes. If you’re
making an enhancement to a new format, there’s little chance of changing the
logic for an old format (since it lives in a separate class). This is
especially important since older formats are not tested as thoroughly.
I started to appreciate it after experiencing the alternative in Elasticsearch,
where we’re constantly bumping into if/ else version checks when making changes.
> Move all codec formats to the o.a.l.codecs.Lucene90 package
> ---
>
> Key: LUCENE-9705
> URL: https://issues.apache.org/jira/browse/LUCENE-9705
> Project: Lucene - Core
> Issue Type: Wish
>Reporter: Ignacio Vera
>Priority: Major
> Time Spent: 50m
> Remaining Estimate: 0h
>
> Current formats are distributed in different packages, prefixed with the
> Lucene version they were created. With the upcoming release of
[GitHub] [lucene-solr] epugh commented on a change in pull request #2275: SOLR-15123: Make all Tool option descriptions follow the same general pattern.
epugh commented on a change in pull request #2275:
URL: https://github.com/apache/lucene-solr/pull/2275#discussion_r568092337
##
File path: solr/core/src/java/org/apache/solr/util/ExportTool.java
##
@@ -216,32 +216,32 @@ void end() throws IOException {
Option.builder("url")
.hasArg()
.required()
- .desc("Address of the collection, example
http://localhost:8983/solr/gettingstarted;)
+ .desc("Address of the collection, example
http://localhost:8983/solr/gettingstarted.;)
Review comment:
also, we do this a lot for the ZooKeeper host:
```
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] epugh commented on a change in pull request #2275: SOLR-15123: Make all Tool option descriptions follow the same general pattern.
epugh commented on a change in pull request #2275:
URL: https://github.com/apache/lucene-solr/pull/2275#discussion_r568090848
##
File path: solr/core/src/java/org/apache/solr/util/SolrCLI.java
##
@@ -1795,25 +1795,25 @@ public ConfigSetUploadTool(PrintStream stdout) {
.argName("confname") // Comes out in help message
.hasArg() // Has one sub-argument
.required(true) // confname argument must be present
- .desc("Configset name on Zookeeper")
+ .desc("Configset name on Zookeeper.")
Review comment:
"several" is right.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] jtibshirani opened a new pull request #2287: Remove write logic from Lucene70NormsFormat.
jtibshirani opened a new pull request #2287: URL: https://github.com/apache/lucene-solr/pull/2287 Our policy is to not maintain write logic for old formats that can't be written to. The write logic is moved to the test folder to support unit testing. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Comment Edited] (LUCENE-9705) Move all codec formats to the o.a.l.codecs.Lucene90 package
[
https://issues.apache.org/jira/browse/LUCENE-9705?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276599#comment-17276599
]
Julie Tibshirani edited comment on LUCENE-9705 at 2/1/21, 7:37 PM:
---
{quote}It's especially clear here where we must copy a lot of classes with no
change at all, merely to clearly and consistently document the index version
change.
{quote}
I’ll try to add some context since I suspect there might be misunderstanding.
In general when there is a new major version, we *do not* plan to create all
new index format classes. We only copy a class and move it to backwards-codecs
when there is a change to that specific format, for example {{PointsFormat}}.
This proposal applies only to the 9.0 release, and its main purpose is to
support the work in LUCENE-9047 to move all formats to little endian. My
understanding is that moving to little endian impacts all the formats and will
be much cleaner if we used these fresh {{Lucene90*Format}}.
{quote}I wonder if we (eventually) should consider shifting to a versioning
system that doesn't require new classes. Is this somehow a feature of the
service discovery API that we use?
{quote}
We indeed load codecs (with their formats) through a service discovery API. If
a user wants to read indices from a previous major version, they can depend on
backwards-codecs so Lucene loads the correct older codec. As of LUCENE-9669, we
allow reading indices back to version N-2.
I personally really like the current "copy-on-write" system for formats.
There’s code duplication, but it has advantages over combining different
version logic in the same file:
* It’s really clear how each version behaves. Having a direct copy like
{{Lucene70Codec}} is almost as if we were pulling in the codec jars from Lucene
7.0.
* It decreases risk of introducing bugs or accidental changes. If you’re
making an enhancement to a new format, there’s little chance of changing the
logic for an old format (since it lives in a separate class). This is
especially important since older formats are not tested as thoroughly.
I started to appreciate it after experiencing the alternative in Elasticsearch,
where we’re constantly bumping into if/ else version checks when making changes.
was (Author: julietibs):
{quote}It's especially clear here where we must copy a lot of classes with no
change at all, merely to clearly and consistently document the index version
change.
{quote}
I’ll try to add some context since I suspect there might be misunderstanding.
In general when there is a new major version, we *do not* plan to create all
new index format classes. We only copy a class and move it to backwards-codecs
when there is a change to that specific format, for example {{PointsFormat}}.
This proposal applies only to the 9.0 release, and its main purpose is to
support the work in LUCENE-9047 to move all formats to little endian. My
understanding is that moving to little endian impacts all the formats and will
be much cleaner if we used these fresh {{Lucene90*Format}}.
{quote}I wonder if we (eventually) should consider shifting to a versioning
system that doesn't require new classes. Is this somehow a feature of the
service discovery API that we use?
{quote}
We indeed load codecs (with their formats) through a service discovery API. If
a user wants to read indices from a previous major version, they can depend on
backwards-codecs so Lucene loads the correct older codec. As of LUCENE-9669, we
allow reading indices back to version N-2.
I personally really like the current "copy-on-write" system for formats.
There’s code duplication, but it has advantages over combining different
version logic in the same file:
* It’s really clear how each version behaves. Having a direct copy like
\{{Lucene70Codec} is almost as if we were pulling in the codec jars from Lucene
7.0.
* It decreases risk of introducing bugs or accidental changes. If you’re
making an enhancement to a new format, there’s little chance of changing the
logic for an old format (since it lives in a separate class). This is
especially important since older formats are not tested as thoroughly.
I started to appreciate it after experiencing the alternative in Elasticsearch,
where we’re constantly bumping into if/ else version checks when making changes.
> Move all codec formats to the o.a.l.codecs.Lucene90 package
> ---
>
> Key: LUCENE-9705
> URL: https://issues.apache.org/jira/browse/LUCENE-9705
> Project: Lucene - Core
> Issue Type: Wish
>Reporter: Ignacio Vera
>Priority: Major
> Time Spent: 50m
> Remaining Estimate: 0h
>
> Current formats are distributed in different packages, prefixed with the
> Lucene version they were created. With the upcoming release of
[GitHub] [lucene-solr] epugh commented on a change in pull request #2275: SOLR-15123: Make all Tool option descriptions follow the same general pattern.
epugh commented on a change in pull request #2275:
URL: https://github.com/apache/lucene-solr/pull/2275#discussion_r568087950
##
File path: solr/core/src/java/org/apache/solr/util/PackageTool.java
##
@@ -261,44 +261,44 @@ protected void runImpl(CommandLine cli) throws Exception {
.argName("URL")
.hasArg()
.required(true)
-.desc("Address of the Solr Web application, defaults to: " +
SolrCLI.DEFAULT_SOLR_URL)
+.desc("Address of the Solr Web application, defaults to: " +
SolrCLI.DEFAULT_SOLR_URL + '.')
.build(),
Option.builder("collections")
.argName("COLLECTIONS")
.hasArg()
.required(false)
-.desc("List of collections. Run './solr package help' for more
details.")
+.desc("List of collections.")
.build(),
Option.builder("cluster")
.required(false)
-.desc("Needed to install cluster level plugins in a package. Run
'./solr package help' for more details.")
+.desc("Needed to install cluster level plugins in a package.")
Review comment:
Take a look at what I put in now.Also, now I see we sometimes say
"package" and other times "plugin", I wonder wha tthe right term is? I *think*
it's "package".
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Commented] (LUCENE-9705) Move all codec formats to the o.a.l.codecs.Lucene90 package
[
https://issues.apache.org/jira/browse/LUCENE-9705?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276599#comment-17276599
]
Julie Tibshirani commented on LUCENE-9705:
--
{quote}It's especially clear here where we must copy a lot of classes with no
change at all, merely to clearly and consistently document the index version
change.
{quote}
I’ll try to add some context since I suspect there might be misunderstanding.
In general when there is a new major version, we *do not* plan to create all
new index format classes. We only copy a class and move it to backwards-codecs
when there is a change to that specific format, for example {{PointsFormat}}.
This proposal applies only to the 9.0 release, and its main purpose is to
support the work in LUCENE-9047 to move all formats to little endian. My
understanding is that moving to little endian impacts all the formats and will
be much cleaner if we used these fresh {{Lucene90*Format}}.
{quote}I wonder if we (eventually) should consider shifting to a versioning
system that doesn't require new classes. Is this somehow a feature of the
service discovery API that we use?
{quote}
We indeed load codecs (with their formats) through a service discovery API. If
a user wants to read indices from a previous major version, they can depend on
backwards-codecs so Lucene loads the correct older codec. As of LUCENE-9669, we
allow reading indices back to version N-2.
I personally really like the current "copy-on-write" system for formats.
There’s code duplication, but it has advantages over combining different
version logic in the same file:
* It’s really clear how each version behaves. Having a direct copy like
\{{Lucene70Codec} is almost as if we were pulling in the codec jars from Lucene
7.0.
* It decreases risk of introducing bugs or accidental changes. If you’re
making an enhancement to a new format, there’s little chance of changing the
logic for an old format (since it lives in a separate class). This is
especially important since older formats are not tested as thoroughly.
I started to appreciate it after experiencing the alternative in Elasticsearch,
where we’re constantly bumping into if/ else version checks when making changes.
> Move all codec formats to the o.a.l.codecs.Lucene90 package
> ---
>
> Key: LUCENE-9705
> URL: https://issues.apache.org/jira/browse/LUCENE-9705
> Project: Lucene - Core
> Issue Type: Wish
>Reporter: Ignacio Vera
>Priority: Major
> Time Spent: 50m
> Remaining Estimate: 0h
>
> Current formats are distributed in different packages, prefixed with the
> Lucene version they were created. With the upcoming release of Lucene 9.0, it
> would be nice to move all those formats to just the o.a.l.codecs.Lucene90
> package (and of course moving the current ones to the backwards-codecs).
> This issue would actually facilitate moving the directory API to little
> endian (LUCENE-9047) as the only codecs that would need to handle backwards
> compatibility will be the codecs in backwards codecs.
> In addition, it can help formalising the use of internal versions vs format
> versioning ( LUCENE-9616)
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] epugh commented on a change in pull request #2275: SOLR-15123: Make all Tool option descriptions follow the same general pattern.
epugh commented on a change in pull request #2275:
URL: https://github.com/apache/lucene-solr/pull/2275#discussion_r568087125
##
File path: solr/core/src/java/org/apache/solr/util/ExportTool.java
##
@@ -216,32 +216,32 @@ void end() throws IOException {
Option.builder("url")
.hasArg()
.required()
- .desc("Address of the collection, example
http://localhost:8983/solr/gettingstarted;)
+ .desc("Address of the collection, example
http://localhost:8983/solr/gettingstarted.;)
Review comment:
what would you say to wrapping it in single quotes? Some other places
that appears to be the pattern.
Address of the collection, example
'http://localhost:8983/solr/gettingstarted'.
Or maybe, I'm just being pedantic about my periods and should skip it!
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] madrob commented on a change in pull request #2284: SOLR-11233: Add optional JAVA8_GC_LOG_FILE_OPTS for bin/solr.
madrob commented on a change in pull request #2284:
URL: https://github.com/apache/lucene-solr/pull/2284#discussion_r568085426
##
File path: solr/bin/solr
##
@@ -2026,7 +2026,11 @@ if [ "$GC_LOG_OPTS" != "" ]; then
if [ "$JAVA_VENDOR" == "IBM J9" ]; then
gc_log_flag="-Xverbosegclog"
fi
-GC_LOG_OPTS+=("$gc_log_flag:$SOLR_LOGS_DIR/solr_gc.log"
'-XX:+UseGCLogFileRotation' '-XX:NumberOfGCLogFiles=9' '-XX:GCLogFileSize=20M')
+if [ -z ${JAVA8_GC_LOG_FILE_OPTS+x} ]; then
Review comment:
should be `:+`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Resolved] (SOLR-14253) Remove Sleeps from OverseerCollectionMessageHandler
[ https://issues.apache.org/jira/browse/SOLR-14253?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Mike Drob resolved SOLR-14253. -- Fix Version/s: master (9.0) Assignee: Mike Drob Resolution: Fixed > Remove Sleeps from OverseerCollectionMessageHandler > --- > > Key: SOLR-14253 > URL: https://issues.apache.org/jira/browse/SOLR-14253 > Project: Solr > Issue Type: Bug > Components: Server >Reporter: Mike Drob >Assignee: Mike Drob >Priority: Major > Fix For: master (9.0) > > Time Spent: 3.5h > Remaining Estimate: 0h > > From the conversations with Mark Miller a few months back - there are a lot > of places in the server code where we have hard sleeps instead of relying on > notifications and watchers to handle state. > I will begin to tackle these one at a time, starting with > OverseerCollectionMessageHandler. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Commented] (SOLR-14253) Remove Sleeps from OverseerCollectionMessageHandler
[ https://issues.apache.org/jira/browse/SOLR-14253?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276594#comment-17276594 ] ASF subversion and git services commented on SOLR-14253: Commit 99748384cfb16cdef2c5a116243cddc23cedf11c in lucene-solr's branch refs/heads/master from Mike Drob [ https://gitbox.apache.org/repos/asf?p=lucene-solr.git;h=9974838 ] SOLR-14253 Replace sleep calls with ZK waits (#1297) Co-Authored-By: markrmiller > Remove Sleeps from OverseerCollectionMessageHandler > --- > > Key: SOLR-14253 > URL: https://issues.apache.org/jira/browse/SOLR-14253 > Project: Solr > Issue Type: Bug > Components: Server >Reporter: Mike Drob >Priority: Major > Time Spent: 3.5h > Remaining Estimate: 0h > > From the conversations with Mark Miller a few months back - there are a lot > of places in the server code where we have hard sleeps instead of relying on > notifications and watchers to handle state. > I will begin to tackle these one at a time, starting with > OverseerCollectionMessageHandler. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] madrob merged pull request #1297: SOLR-14253 Replace various sleep calls with ZK waits
madrob merged pull request #1297: URL: https://github.com/apache/lucene-solr/pull/1297 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] msokolov commented on a change in pull request #2282: LUCENE-9615: Expose HnswGraphBuilder index-time hyperparameters as FieldType attributes
msokolov commented on a change in pull request #2282:
URL: https://github.com/apache/lucene-solr/pull/2282#discussion_r568075607
##
File path:
lucene/core/src/java/org/apache/lucene/codecs/lucene90/Lucene90VectorWriter.java
##
@@ -188,9 +190,29 @@ private void writeGraph(
RandomAccessVectorValuesProducer vectorValues,
long graphDataOffset,
long[] offsets,
- int count)
+ int count,
+ String maxConnStr,
+ String beamWidthStr)
throws IOException {
-HnswGraphBuilder hnswGraphBuilder = new HnswGraphBuilder(vectorValues);
+int maxConn, beamWidth;
+if (maxConnStr == null) {
+ maxConn = HnswGraphBuilder.DEFAULT_MAX_CONN;
+} else if (!maxConnStr.matches("[0-9]+")) {
Review comment:
I don't think we need this - we can allow parseInt to throw an
exception. Let's catch `NumberFormatException` and rethrow with more context
(which attribute caused the exception). Also HnswGraphBuilder tests for `<= 0`,
so we don't need to check that here.
##
File path: lucene/core/src/java/org/apache/lucene/document/VectorField.java
##
@@ -53,6 +54,44 @@ private static FieldType getType(float[] v,
VectorValues.SearchStrategy searchSt
return type;
}
+ /**
+ * Public method to create HNSW field type with the given max-connections
and beam-width
+ * parameters that would be used by HnswGraphBuilder while constructing HNSW
graph.
+ *
+ * @param dimension dimension of vectors
+ * @param searchStrategy a function defining vector proximity.
+ * @param maxConn max-connections at each HNSW graph node
+ * @param beamWidth size of list to be used while constructing HNSW graph
+ * @throws IllegalArgumentException if any parameter is null, or has
dimension 1024.
+ */
+ public static FieldType createHnswType(
+ int dimension, VectorValues.SearchStrategy searchStrategy, int maxConn,
int beamWidth) {
+if (dimension == 0) {
+ throw new IllegalArgumentException("cannot index an empty vector");
+}
+if (dimension > VectorValues.MAX_DIMENSIONS) {
+ throw new IllegalArgumentException(
+ "cannot index vectors with dimension greater than " +
VectorValues.MAX_DIMENSIONS);
+}
+if (searchStrategy == null) {
+ throw new IllegalArgumentException("search strategy must not be null");
Review comment:
Let's also assert `searchStrategy.isHnsw()` to catch attempts to use
`NONE` or some other unsupported future strategy.
##
File path: lucene/core/src/test/org/apache/lucene/util/hnsw/KnnGraphTester.java
##
@@ -132,13 +135,13 @@ private void run(String... args) throws Exception {
if (iarg == args.length - 1) {
throw new IllegalArgumentException("-beamWidthIndex requires a
following number");
}
- HnswGraphBuilder.DEFAULT_BEAM_WIDTH = Integer.parseInt(args[++iarg]);
Review comment:
With this change, we no longer have any need to make these static
variables writable - let's change them to `final` in `HnswGraphBuilder`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] muse-dev[bot] commented on a change in pull request #2285: SOLR-14928: introduce distributed cluster state updates
muse-dev[bot] commented on a change in pull request #2285:
URL: https://github.com/apache/lucene-solr/pull/2285#discussion_r568077584
##
File path: solr/core/src/java/org/apache/solr/cloud/Overseer.java
##
@@ -1058,10 +1056,29 @@ public ZkStateReader getZkStateReader() {
}
public void offerStateUpdate(byte[] data) throws KeeperException,
InterruptedException {
+// When cluster state change is distributed, the Overseer cluster state
update queue should only ever receive only QUIT messages.
+// These go to sendQuitToOverseer for execution path clarity.
+if (distributedClusterChangeUpdater.isDistributedStateChange()) {
+ final ZkNodeProps message = ZkNodeProps.load(data);
Review comment:
*THREAD_SAFETY_VIOLATION:* Unprotected write. Non-private method
`Overseer.offerStateUpdate(...)` indirectly writes to field
`noggit.JSONParser.devNull.buf` outside of synchronization.
Reporting because another access to the same memory occurs on a background
thread, although this access may not.
##
File path: solr/core/src/java/org/apache/solr/cloud/ZkController.java
##
@@ -463,7 +468,11 @@ public boolean isClosed() {
init();
Review comment:
*THREAD_SAFETY_VIOLATION:* Read/Write race. Non-private method
`ZkController(...)` indirectly reads with synchronization from
`noggit.JSONParser.devNull.buf`. Potentially races with unsynchronized write in
method `ZkController.preClose()`.
Reporting because another access to the same memory occurs on a background
thread, although this access may not.
##
File path: solr/core/src/java/org/apache/solr/cloud/ZkController.java
##
@@ -2660,17 +2679,26 @@ public boolean
checkIfCoreNodeNameAlreadyExists(CoreDescriptor dcore) {
*/
public void publishNodeAsDown(String nodeName) {
log.info("Publish node={} as DOWN", nodeName);
-ZkNodeProps m = new ZkNodeProps(Overseer.QUEUE_OPERATION,
OverseerAction.DOWNNODE.toLower(),
-ZkStateReader.NODE_NAME_PROP, nodeName);
-try {
- overseer.getStateUpdateQueue().offer(Utils.toJSON(m));
-} catch (AlreadyClosedException e) {
- log.info("Not publishing node as DOWN because a resource required to do
so is already closed.");
-} catch (InterruptedException e) {
- Thread.currentThread().interrupt();
- log.debug("Publish node as down was interrupted.");
-} catch (KeeperException e) {
- log.warn("Could not publish node as down: ", e);
+if (distributedClusterChangeUpdater.isDistributedStateChange()) {
+ // Note that with the current implementation, when distributed cluster
state updates are enabled, we mark the node
+ // down synchronously from this thread, whereas the Overseer cluster
state update frees this thread right away and
+ // the Overseer will async mark the node down but updating all affected
collections.
+ // If this is an issue (i.e. takes too long), then the call below should
be executed from another thread so that
+ // the calling thread can immediately return.
+ distributedClusterChangeUpdater.executeNodeDownStateChange(nodeName,
zkStateReader);
Review comment:
*THREAD_SAFETY_VIOLATION:* Unprotected write. Non-private method
`ZkController.publishNodeAsDown(...)` indirectly writes to field
`noggit.JSONParser.devNull.buf` outside of synchronization.
Reporting because another access to the same memory occurs on a background
thread, although this access may not.
##
File path: solr/core/src/java/org/apache/solr/cloud/ZkController.java
##
@@ -1662,22 +1680,20 @@ public void unregister(String coreName, CoreDescriptor
cd, boolean removeCoreFro
}
CloudDescriptor cloudDescriptor = cd.getCloudDescriptor();
if (removeCoreFromZk) {
- ZkNodeProps m = new ZkNodeProps(Overseer.QUEUE_OPERATION,
- OverseerAction.DELETECORE.toLower(), ZkStateReader.CORE_NAME_PROP,
coreName,
+ ZkNodeProps m = new ZkNodeProps(Overseer.QUEUE_OPERATION,
OverseerAction.DELETECORE.toLower(),
+ ZkStateReader.CORE_NAME_PROP, coreName,
ZkStateReader.NODE_NAME_PROP, getNodeName(),
ZkStateReader.COLLECTION_PROP, cloudDescriptor.getCollectionName(),
ZkStateReader.CORE_NODE_NAME_PROP, coreNodeName);
- overseerJobQueue.offer(Utils.toJSON(m));
+ if (distributedClusterChangeUpdater.isDistributedStateChange()) {
+
distributedClusterChangeUpdater.doSingleStateUpdate(DistributedClusterChangeUpdater.MutatingCommand.SliceRemoveReplica,
m,
+getSolrCloudManager(), zkStateReader);
Review comment:
*THREAD_SAFETY_VIOLATION:* Read/Write race. Non-private method
`ZkController.unregister(...)` indirectly reads without synchronization from
`this.cloudManager`. Potentially races with write in method
`ZkController.getSolrCloudManager()`.
Reporting because another access to the same memory occurs on a background
thread, although this access
[GitHub] [lucene-solr-operator] HoustonPutman commented on a change in pull request #151: Integrate with cert-manager to issue TLS certs for Solr
HoustonPutman commented on a change in pull request #151:
URL:
https://github.com/apache/lucene-solr-operator/pull/151#discussion_r568020961
##
File path: api/v1beta1/solrcloud_types.go
##
@@ -758,8 +770,12 @@ func (sc *SolrCloud) CommonServiceName() string {
}
// InternalURLForCloud returns the name of the common service for the cloud
-func InternalURLForCloud(cloudName string, namespace string) string {
- return fmt.Sprintf("http://%s-solrcloud-common.%s;, cloudName,
namespace)
+func InternalURLForCloud(sc *SolrCloud) string {
+ urlScheme := "http"
Review comment:
this should probably use `sc.urlScheme()`
##
File path: controllers/solrcloud_controller.go
##
@@ -261,12 +268,77 @@ func (r *SolrCloudReconciler) Reconcile(req ctrl.Request)
(ctrl.Result, error) {
blockReconciliationOfStatefulSet = true
}
+ tlsCertMd5 := ""
+ needsPkcs12InitContainer := false // flag if the StatefulSet needs an
additional initCont to create PKCS12 keystore
+ // don't start reconciling TLS until we have ZK connectivity, avoids
TLS code having to check for ZK
+ if !blockReconciliationOfStatefulSet && instance.Spec.SolrTLS != nil {
+ ctx := context.TODO()
+ // Create the autogenerated TLS Cert and wait for it to be
issued
+ if instance.Spec.SolrTLS.AutoCreate != nil {
+ tlsReady, err := r.reconcileAutoCreateTLS(ctx, instance)
+ // don't create the StatefulSet until we have a cert,
which can take a while for a Let's Encrypt Issuer
+ if !tlsReady || err != nil {
+ if err != nil {
+ r.Log.Error(err, "Reconcile TLS
Certificate failed")
+ } else {
+ wait := 30 * time.Second
+ if
instance.Spec.SolrTLS.AutoCreate.IssuerRef == nil {
+ // this is a self-signed cert,
so no need to wait very long for it to issue
+ wait = 2 * time.Second
+ }
+ requeueOrNot.RequeueAfter = wait
+ }
+ return requeueOrNot, err
Review comment:
Instead of returning here, you can use
`blockReconciliationOfStatefulSet=true`, to make sure that only the creation of
the statefulSet is blocked until the Certs are issued.
##
File path: main.go
##
@@ -65,6 +69,7 @@ func init() {
_ = solrv1beta1.AddToScheme(scheme)
_ = zkv1beta1.AddToScheme(scheme)
+ _ = certv1.AddToScheme(scheme)
// +kubebuilder:scaffold:scheme
flag.BoolVar(, "zk-operator", true, "The operator will
not use the zk operator & crd when this flag is set to false.")
Review comment:
Do we need a flag for the Cert Manager CRDs? Or are we going to assume
that all users have these installed in their cluster?
##
File path: controllers/solrcloud_controller.go
##
@@ -422,9 +494,9 @@ func reconcileCloudStatus(r *SolrCloudReconciler, solrCloud
*solr.SolrCloud, new
nodeStatus := solr.SolrNodeStatus{}
nodeStatus.Name = p.Name
nodeStatus.NodeName = p.Spec.NodeName
- nodeStatus.InternalAddress = "http://; +
solrCloud.InternalNodeUrl(nodeStatus.Name, true)
Review comment:
maybe these methods should just include an option to `includeScheme`,
just like `includePort`. But we could do this separately.
##
File path: controllers/solrcloud_controller.go
##
@@ -716,7 +785,10 @@ func (r *SolrCloudReconciler)
SetupWithManagerAndReconciler(mgr ctrl.Manager, re
Owns({}).
Owns({}).
Owns({}).
- Owns({})
+ Owns({}).
+ Owns({}).
Review comment:
Did the deployment get left over from a merge with master?
Also do any of the Cert manager things need to be here?
##
File path: controllers/solrcloud_controller.go
##
@@ -772,3 +848,188 @@ func (r *SolrCloudReconciler)
indexAndWatchForProvidedConfigMaps(mgr ctrl.Manage
},
builder.WithPredicates(predicate.ResourceVersionChangedPredicate{})), nil
}
+
+// Reconciles the TLS cert, returns either a bool to indicate if the cert is
ready or an error
+func (r *SolrCloudReconciler) reconcileAutoCreateTLS(ctx context.Context,
instance *solr.SolrCloud) (bool, error) {
+
+ // short circuit this method with a quick check if the cert exists and
is ready
+ // this is useful b/c it may take many minutes for a cert to be issued,
so we avoid
+ // all the other checking that happens below while we're waiting for
the cert
+
[jira] [Created] (LUCENE-9721) Hunspell: disallow ONLYINCOMPOUND suffixes at the very end of compound words
Peter Gromov created LUCENE-9721: Summary: Hunspell: disallow ONLYINCOMPOUND suffixes at the very end of compound words Key: LUCENE-9721 URL: https://issues.apache.org/jira/browse/LUCENE-9721 Project: Lucene - Core Issue Type: Sub-task Reporter: Peter Gromov -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] donnerpeter opened a new pull request #2286: LUCENE-9720: Hunspell: more ways to vary misspelled word variations f…
donnerpeter opened a new pull request #2286: URL: https://github.com/apache/lucene-solr/pull/2286 …or suggestions # Description Work on Hunspell suggestions in progress. # Solution Reimplement most of Hunspell's `suggest` logic, without ngrams so far. # Tests Several tests from Hunspell repo. # Checklist Please review the following and check all that apply: - [x] I have reviewed the guidelines for [How to Contribute](https://wiki.apache.org/solr/HowToContribute) and my code conforms to the standards described there to the best of my ability. - [x] I have created a Jira issue and added the issue ID to my pull request title. - [x] I have given Solr maintainers [access](https://help.github.com/en/articles/allowing-changes-to-a-pull-request-branch-created-from-a-fork) to contribute to my PR branch. (optional but recommended) - [x] I have developed this patch against the `master` branch. - [x] I have run `./gradlew check`. - [x] I have added tests for my changes. - [ ] I have added documentation for the [Ref Guide](https://github.com/apache/lucene-solr/tree/master/solr/solr-ref-guide) (for Solr changes only). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Created] (LUCENE-9720) Hunspell: more ways to vary misspelled word variations for suggestions
Peter Gromov created LUCENE-9720: Summary: Hunspell: more ways to vary misspelled word variations for suggestions Key: LUCENE-9720 URL: https://issues.apache.org/jira/browse/LUCENE-9720 Project: Lucene - Core Issue Type: Sub-task Reporter: Peter Gromov -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] NazerkeBS commented on a change in pull request #2230: SOLR-15011: /admin/logging handler is configured logs to all nodes
NazerkeBS commented on a change in pull request #2230:
URL: https://github.com/apache/lucene-solr/pull/2230#discussion_r568061888
##
File path: solr/webapp/web/js/angular/services.js
##
@@ -58,10 +58,10 @@ solrAdminServices.factory('System',
}])
.factory('Logging',
['$resource', function($resource) {
-return $resource('admin/info/logging', {'wt':'json', 'nodes': 'all',
'_':Date.now()}, {
+return $resource('admin/info/logging', {'wt':'json', '_':Date.now()}, {
"events": {params: {since:'0'}},
"levels": {},
- "setLevel": {}
+ "setLevel": {'nodes': 'all'}
Review comment:
I debugged it on Admin UI and it works without `params`. But I updated
my PR to use `params` as other handlers also use `params` in this file .
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] msokolov commented on a change in pull request #2256: LUCENE-9507 Custom order for leaves in IndexReader and IndexWriter
msokolov commented on a change in pull request #2256:
URL: https://github.com/apache/lucene-solr/pull/2256#discussion_r568058172
##
File path: lucene/core/src/java/org/apache/lucene/index/IndexWriter.java
##
@@ -941,6 +969,11 @@ public IndexWriter(Directory d, IndexWriterConfig conf)
throws IOException {
// obtain the write.lock. If the user configured a timeout,
// we wrap with a sleeper and this might take some time.
writeLock = d.obtainLock(WRITE_LOCK_NAME);
+if (config.getIndexSort() != null && leafSorter != null) {
+ throw new IllegalArgumentException(
+ "[IndexWriter] can't use index sort and leaf sorter at the same
time!");
Review comment:
I think it's OK - that MultiSorter is sorting (by index sort) documents
in several segments being merged; it will control the order of the documents
within the new segment, but shouldn't have any influence on or conflict with
the order of the segments being merged
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Commented] (LUCENE-9705) Move all codec formats to the o.a.l.codecs.Lucene90 package
[ https://issues.apache.org/jira/browse/LUCENE-9705?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276575#comment-17276575 ] Michael Sokolov commented on LUCENE-9705: - Just throwing this out there; I have no real proposal, just a feeling, but it seems very heavyweight that we create a new package and new java classes every time we change our index format. It's especially clear here where we must copy a lot of classes with no change at all, merely to clearly and consistently document the index version change. I noticed that we also have to copy (and slightly change) the package-level javadocs when we do this, and this has been done pretty inconsistently over time. I wonder if we (eventually) should consider shifting to a versioning system that doesn't require new classes. Is this somehow a feature of the service discovery API that we use? > Move all codec formats to the o.a.l.codecs.Lucene90 package > --- > > Key: LUCENE-9705 > URL: https://issues.apache.org/jira/browse/LUCENE-9705 > Project: Lucene - Core > Issue Type: Wish >Reporter: Ignacio Vera >Priority: Major > Time Spent: 50m > Remaining Estimate: 0h > > Current formats are distributed in different packages, prefixed with the > Lucene version they were created. With the upcoming release of Lucene 9.0, it > would be nice to move all those formats to just the o.a.l.codecs.Lucene90 > package (and of course moving the current ones to the backwards-codecs). > This issue would actually facilitate moving the directory API to little > endian (LUCENE-9047) as the only codecs that would need to handle backwards > compatibility will be the codecs in backwards codecs. > In addition, it can help formalising the use of internal versions vs format > versioning ( LUCENE-9616) > -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Resolved] (SOLR-15115) Remove unused methods from TestRerankBase
[ https://issues.apache.org/jira/browse/SOLR-15115?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Christine Poerschke resolved SOLR-15115. Fix Version/s: 8.9 master (9.0) Resolution: Fixed Thanks [~asalamon74]! > Remove unused methods from TestRerankBase > - > > Key: SOLR-15115 > URL: https://issues.apache.org/jira/browse/SOLR-15115 > Project: Solr > Issue Type: Task > Security Level: Public(Default Security Level. Issues are Public) >Reporter: Andras Salamon >Assignee: Christine Poerschke >Priority: Trivial > Fix For: master (9.0), 8.9 > > Time Spent: 20m > Remaining Estimate: 0h > > There are two unused methods in TestRerankBase: buildIndexUsingAdoc, > loadModelAndFeatures which can be removed. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Commented] (SOLR-15115) Remove unused methods from TestRerankBase
[ https://issues.apache.org/jira/browse/SOLR-15115?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276565#comment-17276565 ] ASF subversion and git services commented on SOLR-15115: Commit 95c3a3f87f653b1ba0f22d9e1b662e649845ad2a in lucene-solr's branch refs/heads/branch_8x from András Salamon [ https://gitbox.apache.org/repos/asf?p=lucene-solr.git;h=95c3a3f ] SOLR-15115: Remove unused methods from TestRerankBase (#2261) > Remove unused methods from TestRerankBase > - > > Key: SOLR-15115 > URL: https://issues.apache.org/jira/browse/SOLR-15115 > Project: Solr > Issue Type: Task > Security Level: Public(Default Security Level. Issues are Public) >Reporter: Andras Salamon >Assignee: Christine Poerschke >Priority: Trivial > Time Spent: 20m > Remaining Estimate: 0h > > There are two unused methods in TestRerankBase: buildIndexUsingAdoc, > loadModelAndFeatures which can be removed. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Commented] (SOLR-14920) Format code automatically and enforce it in Solr
[
https://issues.apache.org/jira/browse/SOLR-14920?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276559#comment-17276559
]
Jason Gerlowski commented on SOLR-14920:
bq. I'm reluctant to do this to the Solr code base until ... we have some
Solr-specific consensus
LUCENE-9564 where this was originally proposed had a healthy number of Solr
guys (AB, Erick, David, Varun, Houston) voicing support. (You can add my name
to that list, though this is my first time chiming in.) And neither
LUCENE-9564 nor this ticket have brought out any detractors after 3-4 months.
It seems safe to say we've reached [lazy] consensus on this?
bq. we have some clue what this means for the reference impl.
The concern about {{tidy}} making life harder for the reference_impl branch (or
any other large feature branch) is well taken. How much should we avoid
changes on master out of fear for the merge conflicts they'll cause on the
reference_impl branch? I'm of two mind's here: I don't want to make anyone's
development difficult, but I also worry generally about the prudence of
skipping improvements to master because of ref_impl conflicts. Leaving
improvements off of master looks a bit like throwing away the bird in the hand
in favor of the two in the bush. But I don't have strong convictions there.
In any case, I agree we need some consensus on that point particularly before
inconveniencing the ref_impl branch.
But it's worth pointing out there's tons of code that the reference_impl
_doesn't_ touch that we could start with. There's a lot of safe places to
start with this that don't require a consensus on the "ref_impl" discussion.
> Format code automatically and enforce it in Solr
>
>
> Key: SOLR-14920
> URL: https://issues.apache.org/jira/browse/SOLR-14920
> Project: Solr
> Issue Type: Improvement
>Reporter: Erick Erickson
>Priority: Major
> Labels: codestyle, formatting
>
> See the discussion at: LUCENE-9564.
> This is a placeholder for the present, I'm reluctant to do this to the Solr
> code base until after:
> * we have some Solr-specific consensus
> * we have some clue what this means for the reference impl.
> Reconciling the reference impl will be difficult enough without a zillion
> format changes to add to the confusion.
> So my proposal is
> 1> do this.
> 2> Postpone this until after the reference impl is merged.
> 3> do this in one single commit for reasons like being able to conveniently
> have this separated out from git blame.
> Assigning to myself so it doesn't get lost, but anyone who wants to take it
> over please feel free.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] gus-asf commented on pull request #2185: LUCENE-9659 inequality support in payload check query
gus-asf commented on pull request #2185: URL: https://github.com/apache/lucene-solr/pull/2185#issuecomment-771044438 > BTW I saw your relationship Gus but sometimes I enjoy reviewing some code too :-). :) always very welcome of course. I'm slightly irritated with myself for not wrangling the tools correctly to get the notifications, but more review is always excellent. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Commented] (SOLR-15125) Link to docs is brroken
[ https://issues.apache.org/jira/browse/SOLR-15125?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276537#comment-17276537 ] Gus Heck commented on SOLR-15125: - There has been some difficulty with deploying the docs for the recent release, several of the latest versions are presently not available on the web, this is being worked on urgently by several folks. > Link to docs is brroken > --- > > Key: SOLR-15125 > URL: https://issues.apache.org/jira/browse/SOLR-15125 > Project: Solr > Issue Type: Bug > Security Level: Public(Default Security Level. Issues are Public) > Components: website >Reporter: Thomas Güttler >Priority: Minor > > [On this page: > https://lucene.apache.org/solr/guide/|https://lucene.apache.org/solr/guide/] > the link to [https://lucene.apache.org/solr/guide/8_8/] > is broken. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] jpountz commented on pull request #2186: LUCENE-9334 Consistency of field data structures
jpountz commented on pull request #2186: URL: https://github.com/apache/lucene-solr/pull/2186#issuecomment-771029358 @mayya-sharipova Yes, if the field has been added previously without doc values, then it should be illegal to add it later with doc values indeed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] murblanc opened a new pull request #2285: SOLR-14928: introduce distributed cluster state updates
murblanc opened a new pull request #2285: URL: https://github.com/apache/lucene-solr/pull/2285 SOLR-14928: introduce distributed cluster state updates (i.e. not having to go through a ZK queue and Overseer) The motivation behind this PR is to simplify SolrCloud and be the first step to (eventually) a significant scale increase: handle orders of magnitude more collections than currently and manage cluster state caching in a more flexible way. Changes introduced by this PR: - Support of distributed state updates for collections through Compare and Swap for updating state.json Zookeeper files. - Cluster wide configuration in `solr.xml` to pick the way cluster state updates are handled (default remains Overseer based updates) - Randomization based on test seed of the cluster update strategy (Distributed vs Overseer) in tests using `MiniSolrCloudCluster`, so both execution paths get continuously tested. A good entry point to explore this PR is class `DistributedClusterChangeUpdater`. Performance wise, small (low replica count) collection creation is faster with the distributed strategy than with Overseer, and significantly faster when multiple collections are created in parallel (10 parallel threads continuously creating 4 replicas collections show a 30% reduction in collection creation time on my laptop). High replica count (~40 and more) collection creation is slower. This will be addressed by using Per Replica States that limit contention on access to a single state.json file and/or a future splitting of state.json into finer grain elements. Next step after this one is distributing the execution of the Collection API commands to all nodes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Commented] (SOLR-15115) Remove unused methods from TestRerankBase
[ https://issues.apache.org/jira/browse/SOLR-15115?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276516#comment-17276516 ] ASF subversion and git services commented on SOLR-15115: Commit e8bc758144fa0cd77f817f57a8ae20f12868d845 in lucene-solr's branch refs/heads/master from András Salamon [ https://gitbox.apache.org/repos/asf?p=lucene-solr.git;h=e8bc758 ] SOLR-15115: Remove unused methods from TestRerankBase (#2261) > Remove unused methods from TestRerankBase > - > > Key: SOLR-15115 > URL: https://issues.apache.org/jira/browse/SOLR-15115 > Project: Solr > Issue Type: Task > Security Level: Public(Default Security Level. Issues are Public) >Reporter: Andras Salamon >Priority: Trivial > Time Spent: 20m > Remaining Estimate: 0h > > There are two unused methods in TestRerankBase: buildIndexUsingAdoc, > loadModelAndFeatures which can be removed. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Assigned] (SOLR-15115) Remove unused methods from TestRerankBase
[ https://issues.apache.org/jira/browse/SOLR-15115?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Christine Poerschke reassigned SOLR-15115: -- Assignee: Christine Poerschke > Remove unused methods from TestRerankBase > - > > Key: SOLR-15115 > URL: https://issues.apache.org/jira/browse/SOLR-15115 > Project: Solr > Issue Type: Task > Security Level: Public(Default Security Level. Issues are Public) >Reporter: Andras Salamon >Assignee: Christine Poerschke >Priority: Trivial > Time Spent: 20m > Remaining Estimate: 0h > > There are two unused methods in TestRerankBase: buildIndexUsingAdoc, > loadModelAndFeatures which can be removed. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] cpoerschke merged pull request #2261: SOLR-15115: Remove unused methods from TestRerankBase
cpoerschke merged pull request #2261: URL: https://github.com/apache/lucene-solr/pull/2261 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] janhoy commented on a change in pull request #2230: SOLR-15011: /admin/logging handler is configured logs to all nodes
janhoy commented on a change in pull request #2230:
URL: https://github.com/apache/lucene-solr/pull/2230#discussion_r568007698
##
File path: solr/webapp/web/js/angular/services.js
##
@@ -58,10 +58,10 @@ solrAdminServices.factory('System',
}])
.factory('Logging',
['$resource', function($resource) {
-return $resource('admin/info/logging', {'wt':'json', 'nodes': 'all',
'_':Date.now()}, {
+return $resource('admin/info/logging', {'wt':'json', '_':Date.now()}, {
"events": {params: {since:'0'}},
"levels": {},
- "setLevel": {}
+ "setLevel": {'nodes': 'all'}
Review comment:
It’s Angular 1. Looks right but I’m not sure if there should be a
`params: ` there as well. Testing will tell..
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Commented] (SOLR-11233) GC_LOG_OPTS customisation is a little confusing
[
https://issues.apache.org/jira/browse/SOLR-11233?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276513#comment-17276513
]
Christine Poerschke commented on SOLR-11233:
{quote}... a new {{GC_LOG_FILE_OPTS}} option ...
{quote}
[https://github.com/apache/lucene-solr/pull/2284] proposes to name the new
option {{JAVA8_GC_LOG_FILE_OPTS}} to make it clear that it's Java8 specific
only (and the option would go away in Solr 9 which does not support Java8).
Help with making and testing the equivalent Windows i.e. {{solr.cmd}} changes
would be appreciated.
Here's what I used for local testing:
{code:java}
export JAVA_HOME=$JAVA8_HOME
ant clean
cd solr ; ant server
export JAVA8_GC_LOG_FILE_OPTS='-Xloggc:./solr_gc.log -XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=9 -XX:GCLogFileSize=10K'
bin/solr start -e techproducts
ps -ef | grep java | less
ls -ltrh `find . -name "*solr_gc.log*"`
bin/post -c techproducts ../solr/example/exampledocs
ls -ltrh `find . -name "*solr_gc.log*"`
bin/solr stop
{code}
> GC_LOG_OPTS customisation is a little confusing
> ---
>
> Key: SOLR-11233
> URL: https://issues.apache.org/jira/browse/SOLR-11233
> Project: Solr
> Issue Type: Task
>Reporter: Christine Poerschke
>Assignee: Christine Poerschke
>Priority: Minor
> Attachments: SOLR-11233.patch
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> {{GC_LOG_OPTS}} customisation is currently supported but (pre Java 9) the
> customised settings are supplemented e.g.
> https://github.com/apache/lucene-solr/blob/releases/lucene-solr/6.6.0/solr/bin/solr#L1713
> {code}
> GC_LOG_OPTS+=("$gc_log_flag:$SOLR_LOGS_DIR/solr_gc.log"
> '-XX:+UseGCLogFileRotation' '-XX:NumberOfGCLogFiles=9'
> '-XX:GCLogFileSize=20M')
> {code}
> This seems unexpected and confusing. Some ideas for making it less confusing:
> * a new {{GC_LOG_FILE_OPTS}} option
> ** the new option can be customised but if unset it would default to existing
> behaviour
> * use customised GC_LOG_OPTS 'as is'
> ** this would be a change to existing behaviour i.e. the
> [solr#L1713|https://github.com/apache/lucene-solr/blob/releases/lucene-solr/6.6.0/solr/bin/solr#L1713]
> settings mentioned above would no longer be appended
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] cpoerschke opened a new pull request #2284: SOLR-11233: Add optional JAVA8_GC_LOG_FILE_OPTS for bin/solr.
cpoerschke opened a new pull request #2284:
URL: https://github.com/apache/lucene-solr/pull/2284
https://issues.apache.org/jira/browse/SOLR-11233
* {{bin/solr}} change -- ready for review
* {{bin/solr.cmd}} change -- to do (help needed)
Since `master` branch does not support Java8 this change is best tested on
`branch_8x` but could then potentially still be cherry-picked to `master`
branch if we want to keep the `bin/solr*` code on both branches similar.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] mayya-sharipova commented on a change in pull request #2256: LUCENE-9507 Custom order for leaves in IndexReader and IndexWriter
mayya-sharipova commented on a change in pull request #2256:
URL: https://github.com/apache/lucene-solr/pull/2256#discussion_r567994551
##
File path: lucene/core/src/java/org/apache/lucene/index/IndexWriter.java
##
@@ -933,6 +936,31 @@ protected final void ensureOpen() throws
AlreadyClosedException {
* low-level IO error
*/
public IndexWriter(Directory d, IndexWriterConfig conf) throws IOException {
+this(d, conf, null);
+ }
+
+ /**
+ * Constructs a new IndexWriter per the settings given in conf.
If you want to make
+ * "live" changes to this writer instance, use {@link #getConfig()}.
+ *
+ * NOTE: after ths writer is created, the given configuration
instance cannot be passed
+ * to another writer.
+ *
+ * @param d the index directory. The index is either created or appended
according
+ * conf.getOpenMode().
+ * @param conf the configuration settings according to which IndexWriter
should be initialized.
+ * @param leafSorter a comparator for sorting leaf readers. Providing
leafSorter is useful for
+ * indices on which it is expected to run many queries with particular
sort criteria (e.g. for
+ * time-based indices this is usually a descending sort on timestamp).
In this case {@code
+ * leafSorter} should sort leaves according to this sort criteria.
Providing leafSorter allows
+ * to speed up this particular type of sort queries by early terminating
while iterating
+ * though segments and segments' documents.
+ * @throws IOException if the directory cannot be read/written to, or if it
does not exist and
+ * conf.getOpenMode() is OpenMode.APPEND or if
there is any other
+ * low-level IO error
+ */
+ public IndexWriter(Directory d, IndexWriterConfig conf,
Comparator leafSorter)
Review comment:
Thank you for your suggestion, I will explore this.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] mayya-sharipova commented on a change in pull request #2256: LUCENE-9507 Custom order for leaves in IndexReader and IndexWriter
mayya-sharipova commented on a change in pull request #2256:
URL: https://github.com/apache/lucene-solr/pull/2256#discussion_r567994353
##
File path: lucene/core/src/java/org/apache/lucene/index/IndexWriter.java
##
@@ -941,6 +969,11 @@ public IndexWriter(Directory d, IndexWriterConfig conf)
throws IOException {
// obtain the write.lock. If the user configured a timeout,
// we wrap with a sleeper and this might take some time.
writeLock = d.obtainLock(WRITE_LOCK_NAME);
+if (config.getIndexSort() != null && leafSorter != null) {
+ throw new IllegalArgumentException(
+ "[IndexWriter] can't use index sort and leaf sorter at the same
time!");
Review comment:
@mikemccand Thank you for your review! From the discussion on the Jira
ticket, we also wanted to use writer's `leafSorter` during merging for
arranging docs in a merged segment (by putting first docs from a segment with
highest sort values according to `leafSorter`).
This will be in conflict with `indexSorter`, as if provided [it will arrange
merged docs according to its
sort](https://github.com/apache/lucene-solr/blob/master/lucene/core/src/java/org/apache/lucene/index/MergeState.java#L211).
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] donnerpeter opened a new pull request #2283: LUCENE-9719: Resource files aren't deleted from build directory after…
donnerpeter opened a new pull request #2283: URL: https://github.com/apache/lucene-solr/pull/2283 … being deleted in source # Description e.g. *.sug files used in Hunspell # Solution Make Gradle `Sync` them instead of `Copy` # Tests No # Checklist Please review the following and check all that apply: - [x] I have reviewed the guidelines for [How to Contribute](https://wiki.apache.org/solr/HowToContribute) and my code conforms to the standards described there to the best of my ability. - [x] I have created a Jira issue and added the issue ID to my pull request title. - [x] I have given Solr maintainers [access](https://help.github.com/en/articles/allowing-changes-to-a-pull-request-branch-created-from-a-fork) to contribute to my PR branch. (optional but recommended) - [x] I have developed this patch against the `master` branch. - [x] I have run `./gradlew check`. - [ ] I have added tests for my changes. - [ ] I have added documentation for the [Ref Guide](https://github.com/apache/lucene-solr/tree/master/solr/solr-ref-guide) (for Solr changes only). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Created] (LUCENE-9719) Resource files aren't deleted from build directory after being deleted in source
Peter Gromov created LUCENE-9719: Summary: Resource files aren't deleted from build directory after being deleted in source Key: LUCENE-9719 URL: https://issues.apache.org/jira/browse/LUCENE-9719 Project: Lucene - Core Issue Type: Bug Reporter: Peter Gromov e.g. *.sug files used in Hunspell -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] ctargett commented on a change in pull request #2275: SOLR-15123: Make all Tool option descriptions follow the same general pattern.
ctargett commented on a change in pull request #2275:
URL: https://github.com/apache/lucene-solr/pull/2275#discussion_r567970635
##
File path: solr/core/src/java/org/apache/solr/util/SolrCLI.java
##
@@ -1795,25 +1795,25 @@ public ConfigSetUploadTool(PrintStream stdout) {
.argName("confname") // Comes out in help message
.hasArg() // Has one sub-argument
.required(true) // confname argument must be present
- .desc("Configset name on Zookeeper")
+ .desc("Configset name on Zookeeper.")
Review comment:
Also, 'ZooKeeper'. I'll stop marking them, but there are several others
to fix.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] ctargett commented on a change in pull request #2275: SOLR-15123: Make all Tool option descriptions follow the same general pattern.
ctargett commented on a change in pull request #2275:
URL: https://github.com/apache/lucene-solr/pull/2275#discussion_r567970635
##
File path: solr/core/src/java/org/apache/solr/util/SolrCLI.java
##
@@ -1795,25 +1795,25 @@ public ConfigSetUploadTool(PrintStream stdout) {
.argName("confname") // Comes out in help message
.hasArg() // Has one sub-argument
.required(true) // confname argument must be present
- .desc("Configset name on Zookeeper")
+ .desc("Configset name on Zookeeper.")
Review comment:
Also, 'ZooKeeper'.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] ctargett commented on a change in pull request #2275: SOLR-15123: Make all Tool option descriptions follow the same general pattern.
ctargett commented on a change in pull request #2275:
URL: https://github.com/apache/lucene-solr/pull/2275#discussion_r567970209
##
File path: solr/core/src/java/org/apache/solr/util/SolrCLI.java
##
@@ -1311,13 +1311,13 @@ protected void runCloudTool(CloudSolrClient
cloudSolrClient, CommandLine cli) th
.argName("HOST")
.hasArg()
.required(false)
- .desc("Address of the Zookeeper ensemble; defaults to: " + ZK_HOST)
+ .desc("Address of the Zookeeper ensemble; defaults to: " + ZK_HOST +
'.')
Review comment:
Should be 'ZooKeeper'
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] ctargett commented on a change in pull request #2275: SOLR-15123: Make all Tool option descriptions follow the same general pattern.
ctargett commented on a change in pull request #2275:
URL: https://github.com/apache/lucene-solr/pull/2275#discussion_r567969883
##
File path: solr/core/src/java/org/apache/solr/util/SolrCLI.java
##
@@ -236,13 +236,13 @@ protected abstract void runCloudTool(CloudSolrClient
cloudSolrClient, CommandLin
.argName("HOST")
.hasArg()
.required(false)
- .desc("Address of the Zookeeper ensemble; defaults to: "+ZK_HOST)
+ .desc("Address of the Zookeeper ensemble; defaults to: "+ ZK_HOST +
'.')
Review comment:
ZK is properly spelled 'ZooKeeper' (capital 'K').
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Resolved] (SOLR-15126) gc log file rotation broken (when using Java8)
[
https://issues.apache.org/jira/browse/SOLR-15126?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Christine Poerschke resolved SOLR-15126.
Resolution: Cannot Reproduce
Never mind, apologies for the noise, I must have mixed up and confused
something and can no longer reproduce the issue. And experimentation confirms
that array appending to array is possible in shell script e.g.
{code}
$ FOO="aaa bbb ccc"
$ BAR=($FOO)
$ for i in "${!BAR[@]}"; do echo $i; echo ${BAR[$i]}; done
0
aaa
1
bbb
2
ccc
$ BAR+=("xxx" 'yyy' 'zzz')
$ for i in "${!BAR[@]}"; do echo $i; echo ${BAR[$i]}; done
0
aaa
1
bbb
2
ccc
3
xxx
4
yyy
5
zzz
{code}
> gc log file rotation broken (when using Java8)
> --
>
> Key: SOLR-15126
> URL: https://issues.apache.org/jira/browse/SOLR-15126
> Project: Solr
> Issue Type: Bug
>Reporter: Christine Poerschke
>Assignee: Christine Poerschke
>Priority: Minor
>
> Noticed when investigating SOLR-11233 which concerns Java8 use. Based on the
> shell script content we intend to use log rotation but from observation in
> practice that does not happen (details to follow).
> SOLR-15104 is related but potentially wider in scope (non-Java8 and rotation
> not just within the same JVM but across successive JVMs).
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] madrob commented on a change in pull request #2275: SOLR-15123: Make all Tool option descriptions follow the same general pattern.
madrob commented on a change in pull request #2275:
URL: https://github.com/apache/lucene-solr/pull/2275#discussion_r567953137
##
File path: solr/core/src/java/org/apache/solr/util/ExportTool.java
##
@@ -216,32 +216,32 @@ void end() throws IOException {
Option.builder("url")
.hasArg()
.required()
- .desc("Address of the collection, example
http://localhost:8983/solr/gettingstarted;)
+ .desc("Address of the collection, example
http://localhost:8983/solr/gettingstarted.;)
Review comment:
I think this will be confusing to people if the period is part of the
URL or not (if they are copy pasting from a tutorial perhaps.
##
File path: solr/core/src/java/org/apache/solr/util/PackageTool.java
##
@@ -261,44 +261,44 @@ protected void runImpl(CommandLine cli) throws Exception {
.argName("URL")
.hasArg()
.required(true)
-.desc("Address of the Solr Web application, defaults to: " +
SolrCLI.DEFAULT_SOLR_URL)
+.desc("Address of the Solr Web application, defaults to: " +
SolrCLI.DEFAULT_SOLR_URL + '.')
.build(),
Option.builder("collections")
.argName("COLLECTIONS")
.hasArg()
.required(false)
-.desc("List of collections. Run './solr package help' for more
details.")
+.desc("List of collections.")
.build(),
Option.builder("cluster")
.required(false)
-.desc("Needed to install cluster level plugins in a package. Run
'./solr package help' for more details.")
+.desc("Needed to install cluster level plugins in a package.")
Review comment:
I'm not sure what this description means. There is no verb?
##
File path: solr/core/src/java/org/apache/solr/util/SolrCLI.java
##
@@ -1795,25 +1795,25 @@ public ConfigSetUploadTool(PrintStream stdout) {
.argName("confname") // Comes out in help message
.hasArg() // Has one sub-argument
.required(true) // confname argument must be present
- .desc("Configset name on Zookeeper")
+ .desc("Configset name on Zookeeper.")
Review comment:
s/on/in maybe?
##
File path: solr/core/src/java/org/apache/solr/util/SolrCLI.java
##
@@ -1942,19 +1942,19 @@ public ZkRmTool(PrintStream stdout) {
.argName("path")
.hasArg()
.required(true)
- .desc("Path to remove")
+ .desc("Path to remove.")
.build(),
Option.builder("recurse")
.argName("recurse")
.hasArg()
.required(false)
- .desc("Recurse (true|false, default is false)")
+ .desc("Recurse (true|false), default is false.")
Review comment:
These parentheses are inconsistent with the other tools
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org
For additional commands, e-mail: issues-h...@lucene.apache.org
[jira] [Commented] (SOLR-15124) Remove node/container level admin handlers from ImplicitPlugins.json (core level).
[ https://issues.apache.org/jira/browse/SOLR-15124?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17276436#comment-17276436 ] Mike Drob commented on SOLR-15124: -- Should we consider setting up redirect paths for the old handlers? Or a better error message with a hint that they have moved? Also, will need to update SolrCoreTest.testImplicitPlugins, which I don't think the existing PR did. > Remove node/container level admin handlers from ImplicitPlugins.json (core > level). > -- > > Key: SOLR-15124 > URL: https://issues.apache.org/jira/browse/SOLR-15124 > Project: Solr > Issue Type: Task > Security Level: Public(Default Security Level. Issues are Public) >Reporter: David Smiley >Priority: Blocker > Labels: newdev > Fix For: master (9.0) > > Time Spent: 50m > Remaining Estimate: 0h > > There are many very old administrative RequestHandlers registered in a > SolrCore that are actually JVM / node / CoreContainer level in nature. These > pre-dated CoreContainer level handlers. We should (1) remove them from > ImplictPlugins.json, and (2) make simplifying tweaks to them to remove that > they work at the core level. For example LoggingHandler has two constructors > and a non-final Watcher because it works in these two modalities. It need > only have the one that takes a CoreContainer, and Watcher will then be final. > /admin/threads > /admin/properties > /admin/logging > Should stay because has core-level stuff: > /admin/plugins > /admin/mbeans > This one: > /admin/system -- SystemInfoHandler > returns "core" level information, and also node level stuff. I propose > splitting this one to a CoreInfoHandler to split the logic. Maybe a separate > issue. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org
[GitHub] [lucene-solr] madrob commented on a change in pull request #2265: SOLR-15119 Add logs and make default splitMethod to be LINK
madrob commented on a change in pull request #2265: URL: https://github.com/apache/lucene-solr/pull/2265#discussion_r567947008 ## File path: solr/core/src/java/org/apache/solr/cloud/api/collections/SplitShardCmd.java ## @@ -580,6 +597,10 @@ public boolean split(ClusterState clusterState, ZkNodeProps message, NamedList
[jira] [Created] (SOLR-15126) gc log file rotation broken (when using Java8)
Christine Poerschke created SOLR-15126: -- Summary: gc log file rotation broken (when using Java8) Key: SOLR-15126 URL: https://issues.apache.org/jira/browse/SOLR-15126 Project: Solr Issue Type: Bug Reporter: Christine Poerschke Assignee: Christine Poerschke Noticed when investigating SOLR-11233 which concerns Java8 use. Based on the shell script content we intend to use log rotation but from observation in practice that does not happen (details to follow). SOLR-15104 is related but potentially wider in scope (non-Java8 and rotation not just within the same JVM but across successive JVMs). -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: issues-unsubscr...@lucene.apache.org For additional commands, e-mail: issues-h...@lucene.apache.org